









磊哥哥讲Sql
一、what who defined
1.数据库whatever
- 数据库(Database):按照数据结构来组织、存储和管理数据的仓库 。
- 常见后端的servlet命令调用 MVC开发模式 例如与常见的java项目 ,c类项目,将进行大量的数据操作,所以将数据管理分配逻辑清晰,以及一些复杂操作的语法和联合在方法构写方面掌握清楚至关重要
- SQL(Structured Query Language) sql的官方translation
SQL 是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和整花活,同时给结合java或者c类项目中数据操作,sql语句的基础需要我们打扎实。简单理解就是对我们数据库和数据库中的表进行”增删改查“操作的编程语言。
2.引言导入
- 这篇博客将 数据库的部分划分为了 table和view两种模式,但其实他们之间的区别也不是很明显,可以理解为一个是在患者身上动刀子,另一个是保留的数据的完整性,建立一个别样的视图view进行操作,可以直观表达数据直接的联合性。
- 结合之后提到的 inner join,left join ,right join、view的出现是在不破坏原有table的基础上的create,一种新的执行模式和展示,在后面涉及的show full view和table是同样的意义和理解方式。
下面就进入sql的奇妙世界 (玛卡巴卡)
二、database and tables guy
1.Basic element project definition
- CREATE TABLE:用于创建给定名称的表,必须拥有表CREATE的权限。
- <表名>:指定要创建表的名称,在 CREATE TABLE 之后给出,必须符合标识符命名规则。表名称被指定为 db_name.tbl_name,以便在特定的数据库中创建表。如果使用加引号的识别名,则应对数据库和表名称分别加引号。例如,‘mydb’.‘mytbl’ 是合法的,但 ‘mydb.mytbl’ 不合法。
- <表定义选项>:表创建定义,由列名(col_name)、列的定义(column_definition)以及可能的空值说明、完整性约束或表索引组成。
- 默认的情况是,表被创建到当前的数据库中。若表已存在、没有当前数据库或者数据库不存在,则会出现错误。
2. template data(讲解模型)
数据库中,有两张表——课程表 courses 和教师表 teachers :
courses 表中存放着课程的信息 ,包括:课程名称 name 、学生总数 student_count 、开课时间 created_at 以及讲师 ID teacher_id ;
teachers 表中存放着教师的信息,包括:讲师姓名 name 、讲师邮箱 email 、讲师年龄 age 以及讲师国籍 country ;
课程表 courses
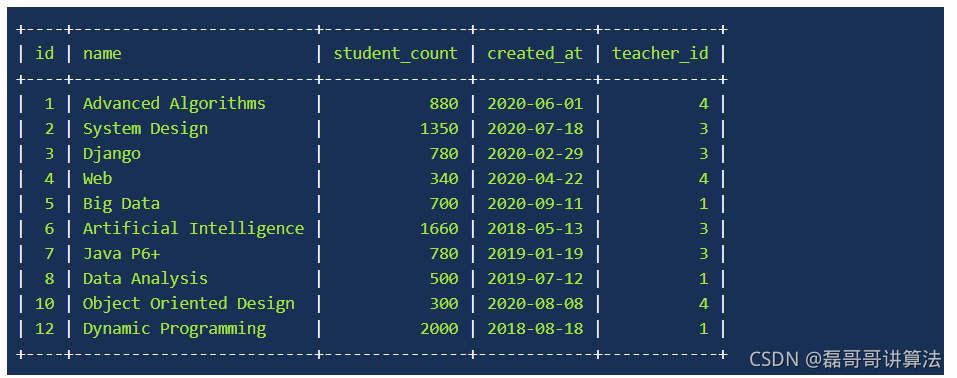
教师表 teachers

-
数据库:数据库是一些关联表的集合。LintCode 就是我们用来存放课程表 courses 和教师表 teachers 的数据库。
-
数据表:数据表是数据的矩阵。课程表 courses 和 教师表 teachers 就是数据表,看起来像一个简单的 Excel 表格。
-
列: 一列(数据元素)包含了相同类型的数据。例如教师表 teachers 中的姓名 name 就是一个列,这一列中的教师姓名都是用字符方式存储。
-
行: 一行数据(可以元组,或记录)是一组相关的数据。例如教师表 teachers 每一行都对应一位教师信息
-
id,这个名为 id 的列,是我们用来唯一标识每行数据的,称为主键。实际上,教师的姓名是不能唯一标识一条记录的(因为教师姓名可能会有相同),所以我们使用额外的一列来唯一标识每行。这个列我们一般取名为 id,即 identification 的缩写,当然,我们也可以取别的名称。但需要注意的是,一个数据表只能有一个主键。
此外,在教师表 courses 中,我们发现有一列数据 teacher_id 和教师表 teachers 中的 id 相关联,即每个 teacher_id 都指向教师表中的某一个教师记录,这种用于关联其它表某一列的列,我们称为外键(foreign key)。同时外和主键在之后关联表格中有着重要的作用。
3. SELECT “Hello SQL!”;
这句话是执行 ,也可以另类的理解为输出
三、【增删改查 】grammar and operation
sql里面大小写不分,看个人心情
1.select
在使用 SELECT 语句检索表数据时,至少需要给出两条信息——想检索的列名(column_name)和被检索内容的表名(table_name)。
SELECT `column_name`
FROM `table_name`;// 单列操作
SELECT `column_name_1`, `column_name_2`
FROM `table_name`;
SELECT * FROM `table_name`;//*代表全部
SELECT DISTINCT `column_name`
FROM `table_name` //distinct表示的是不重复
//多行列 也就是select可以查更多,记得用”,“分开就行 *就是全部
反引号的出现,从初学者角度是用来区分 列表和命名,熟练后可以区分
比如从表里查老师姓名 select name from teachers;
(飞飞鱼)
2. where (my destiny)
在大多数情况下,我们只希望留下感兴趣的行而过滤掉不感兴趣的行,这时我们可以使用 WHERE 子句来帮助我们。
SELECT WHERE 语句是筛选查询很重要的操作,WHERE 关键字后面加上条件可以过滤掉我们不需要信息,对查询效率有着很大的提高。
在使用 SELECT WHERE 语句检索表数据时,需要给出检索的表名 (table_name)、
检索的列名 (column_name) 和操作符 (operator) 。
SELECT `column_name1`,`column_name2`…
FROM `table_name`
WHERE `column_name` operator `value`;
其中:
- column_name 对应指定列的名称,或者是多列,用逗号( , )分隔开
- table_name 对应查询表的名称
- operator 为操作符,常用的有等于 = 、小于 < 、大于 > 、不等于<> 或 !=,我们会在后续课程中更加深入地学习它。
3. update
在我们平时的使用中 UPDATE 语句,也是一种较常用的 SQL 语句,它可以用来更新表中已存在的记录。日新月异嘛
我们在查询教师表 teachers 的时候发现,教师姓名 name 为 “Linghu Chong” 的老师邮箱 email 信息为 NULL,即没有该部分信息,我们现在希望更新邮箱信息,这时候就需要用到 UPDATE 语句。
通常搭配是 update set
UPDATE `table_name`
SET `column1`=value1,`column2`=value2,...
WHERE `some_column`=some_value;
4.delete
删除一些记忆,对所有人都好
DELETE FROM `table_name`
WHERE `some_column` = `some_value`;
- table_name 代表表名称
- some_column 代表列名称,如 id
- some_value 可以为任意值。some_column 和 some_value 构成 WHERE 子句中的搜索条件
5.operate
其中 operator 是比较运算符,用于对 A 和 B 进行比较运算。
常用的比较运算符有 =(等于) 、!=(不等于)、 <>(不等于)、<(小于)、<=(小于等于)、>(大于)、>=(大于等于),其中 != 和 <> 在特殊情况下用法是不同的,这里暂时不提。
比较运算符常常与 WHERE 在一起使用。WHERE 用于逻辑判断,WHERE 后面写判断的条件,满足条件的语句会被筛选出来。
可以理解为是一种操作类型 where A operate B
6. and or多连接 not 一个大否定 in一起选not in排除
- and是取交集 or是并集 not就是!反向。
- in是在一群里面选择,当我们需要查询单个表条件过多时,就会用多个 ‘OR’ 连接或者嵌套,这会比较麻烦,现在我们有 ‘IN’ 能更方便的解决这一问题。
- operate就是通常在where之后的执行操作。not in就是反向操作,排除这些元素。
- 综上所述,一个好看的语法结构和好的语法习惯,在写完检查也有好处
select 是目的
from 来源
where 怎么做 (依古比古)
7. between A and B
BETWEEN AND 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
请注意,在不同的数据库中,BETWEEN 操作符会产生不同的结果!
在某些数据库中,BETWEEN 选取介于两个值之间但不包括两个测试值的字段。
在某些数据库中,BETWEEN 选取介于两个值之间且包括两个测试值的字段。
在某些数据库中,BETWEEN 选取介于两个值之间且包括第一个测试值但不包括最后一个测试值的字段。
因此,请检查您的数据库是如何处理 BETWEEN 操作符!
我们这里选用的是 MySQL 的支持,BETWEEN 选取介于两个值之间且包括两个测试值的字段,即
BETWEEN 200 AND 250 选取结果会包括 200 和 250
between的效果根据所选的语言类型体现
SELECT *
FROM `table_name`
WHERE `column_name` BETWEEN `value` AND `value`;
8. isnull()
NULL 值代表遗漏的未知数据。默认的,表的列可以存放 NULL 值。
如果表中的某个列是可选的,那么我们可以在不向该列添加值的情况下插入新记录或更新已有的记录。这意味着该字段将以 NULL 值保存。
NULL 用作未知的或不适用的值的占位符。
注释:无法比较 NULL 和 0;它们是不等价的。
无法使用比较运算符来测试 NULL 值,比如 =、!= 或 <>。
我们必须使用 IS NULL 和 IS NOT NULL操作符。
SELECT *
FROM `table_name`
WHERE `column_name` IS NULL;
9. like % and As
使用 LIKE 更准确规范得解决文本比较问题。
LIKE 比较类似我们平时用到的搜索。给一个模糊值,他自己找比对返回
SELECT *
FROM `table_name`
WHERE `column_name` LIKE `value`;
其中 ‘D%’ 表示以 D 开头的所有单词,% 表示为通配符,可以替代 0 个或多个字符,对于SQL 中的通配符有以下类型:

AS 关键字的作用是赋予长复杂的新名字计算结果列显示在列表中的别名。
何为别名?
别名是一个字段或值的替换名,由关键字 AS 赋予。别名还有其他用途,常见的用途包括在实际的表列名包含不符合规定的字符(如空格)时重新命名它,在原来的表列名含糊或者容易误解时扩充它等。
别名常与函数联用,给使用函数之后的新计算列一个名字,方便我们查看和使用。我们会在后续的学习中经常见到它。
通常也会出现只是 teachers t,意思是teachers表格 as t 能省就省
10.order by
在前面的学习中,我们学习了如何对表中的数据进行简单的查询,仔细观察后可以发现,检索出的数据并不是以纯粹的随机顺序显示的,在没有对其进行排序时,数据以它在表中出现的顺序显示,一般为数据最初添加到表中的顺序。
当我们想要查询具有明确排序的数据时,ORDER BY 关键字就可以帮助到我们。
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序,其具有 ASC(升序)和 DESC(降序)两个关键字,且默认按照升序排列。
ASC :按升序排列,ORDER BY 默认按照升序对记录进行排序,因此升序的关键字 ASC 可以省去不写。
DESC:按降序排列,如果需要按照降序对记录进行排序,可以使用 DESC 关键字。
单行数据排列
SELECT `column_name`, `column_name`
FROM `table_name`
ORDER BY `column_name`, `column_name` ASC|DESC;
多行排列
SELECT `name`,`teacher_id`,`created_at`
FROM `courses`
WHERE `teacher_id` in (1,2,3)
ORDER BY `teacher_id`,`created_at`;
这里 ORDER BY 关键字要写在 WHERE 关键字后面,先条件后排序,不然会报错 order by 排序方法 根据命名的优先集+默认或者写出来排序要求。
11.limit限制行数输出
在前面的学习中我们知道 SELECT 语句返回所有匹配的行。可是当我们数据非常多时,如果只希望返回有限个数的数据的时候我们该怎么办呢?这时候 LIMIT 子句就能帮助到我们。
LIMIT 子句用于 SELECT 中,对输出结果集的行数进行约束,LIMIT 接收2个参数 offset 和 count,两个参数都是整型数字,但通常只用一个。
SELECT `column_name`, `column_name`
FROM `table_name`
LIMIT `offset` , `count`;
offset :是返回集的初始标注,起始点是0,不是1哦
count :制定返回的数量
且limit要跟在order by后面
四、the comment of algorithm
1.AVG ~求和/n
平均函数 AVG() 是平均数 AVERAGE 的缩写,它用于求数值列的平均值。它可以用来返回所有列的平均值,也可以用来返回特定列和行的平均值。
具体的计算过程为:其通过对表中行数计数并计算特定数值列的列值之和,求得该列的平均值。
但是当参数 column_name 列中的数据均为空时,结果会返回 NULL。
SELECT AVG(`column_name`)
FROM `table_name`;
2. max min sum
基础的最大最小求和的计算公式罢了
SELECT MAX(`column_name`)
FROM `table_name`;
SELECT MIN(`column_name`)
FROM `table_name`;
SELECT SUM(`column_name`)
FROM `table_name`;
3. round()四舍五入
ROUND() 函数用于把数值字段舍入为指定的小数位数。
SELECT ROUND(`column_name`, `decimals`)
FROM `table_name`;
-
column_name 为要舍入的字段
-
decimals 规定要返回的小数位数
-
ROUND() 函数始终返回一个值。当 decimals 为正数时,column_name 四舍五入为 decimals 所指定的小数位数。当 decimals 为负数时,column_name 则按 decimals 所指定的在小数点的左边四舍五入。
-
特别的,如果 length 是负数且大于小数点前的数字个数,ROUND() 函数将返回 0
-
ROUND(X, D): 返回参数 X 四舍五入且保留 D 位小数后的一个数字。如果 D 为 0,结果将没有小数点或小数部分。
4. null() 可对比 isnull
在介绍判断空值函数 NULL() 之前,我们先来了解一下在之前的学习中遇到了多次的 NULL ,即我们常说的空值。但是这种叫法并不准确,因为 NULL 并不是值,它表示数值未知或者不确定。因此,NULL 无法和 0 或空格字符串 “” 进行比较,甚至 NULL 与 NULL 之间也无法比较。默认地,表的列可以存放 NULL 。
ISNULL() 函数 VS IFNULL() 函数
ISNULL() 函数用于判断字段是否为 NULL,它只有一个参数 column_name 为列名,根据column_name 列中的字段是否为 NULL 值返回 0 或 1。
SELECT ISNULL(`column_name`)
FROM `table_name`;
IFNULL() 函数也用于判断字段是否为NULL,但是与 ISNULL() 不同的是它接收两个参数,第一个参数 column_name 为列名,第二个参数 value 相当于备用值。 ifnull相当于是isnull 然后准备一个二手准备
SELECT IFNULL(`column_name`, `value`)
FROM `table_name`;
isnull作用于where
null和ifnull 作用于select 对比一下
5. count()
COUNT()在sql里面极其重要,作用 计算行数
COUNT() 函数用于计数,可利用其确定表中行的数目或者符合特定条件的行的数目。当COUNT() 中的参数不同时,其的用途也是有明显的不同的,主要可分为以下三种情况:COUNT(column_name) 、COUNT( * ) 和 COUNT(DISTINCT column_name) 。
SELECT COUNT(`column_name`)
FROM `table_name`;
COUNT() 函数会对表中行的数目进行计数,包括值为 NULL 所在行和重复项所在行。该函数主要用于查看表中的记录数。
COUNT() 函数会对表中行的数目进行计数,包括值为 NULL 所在行和重复项所在行。该函数主要用于查看表中的记录数。
6. Time Management Bureau(时间管理)
1.使用 NOW() 、 CURDATE()、CURTIME() 获取当前时间
在 SQL 中,我们可以通过使用 NOW()、CURDATE()、CURTIME() 来获取当前的时间
- NOW() 可以用来返回当前日期和时间 格式:YYYY-MM-DD hh:mm:ss
- CURDATE() 可以用来返回当前日期 格式:YYYY-MM-DD
- CURTIME() 可以用来返回当前时间 格式:hh:mm:ss
在使用 NOW() 和 CURTIME() 时,如果要精确的秒以后的时间的话,可以在()中加数字,加多少,就表示精确到秒后多少位
2021-03-31 15:27:20.645
在一些习题匹配中 %Y-%M-%D %H:%I:%T
这些属于即刻返回values的执行语句
2.使用 DATE()、TIME() 函数提取日期和时间
使用 DATE()、TIME() 函数分别将 ‘2021-03-25 16:16:30’ 这组数据中的日期于时间提取出来,并用 date 、time 作为结果集列名。
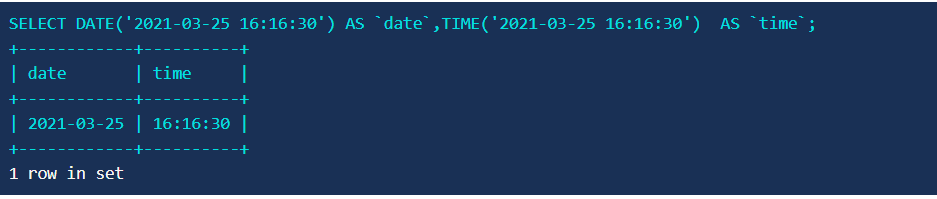
3.对于时间定向抽取 extract date format
EXTRACT() 函数用于返回日期/时间的单独部分,如 YEAR (年)、MONTH (月)、DAY (日)、HOUR (小时)、MINUTE (分钟)、 SECOND (秒)。
SELECT EXTRACT(unit FROM date)
FROM `table`
table 是表格名
date 参数是合法的日期表达式。
unit 参数是需要返回的时间部分,如 YEAR 、MONTH 、 DAY 、 HOUR 、MINUTE 、SECOND 等。
在一般情况下,EXTRACT(unit FROM date) 与 unit() 的结果相同。
我们在 SQL 中使用 DATE_FORMAT() 方法来格式化输出 date/time。
需要注意的是 DATE_FORMAT() 函数返回的是字符串格式。
SELECT DATE_FORMAT(date,format);
4.Modification of time
date add()
在使用 mysql 查询数据的过程中,有时我们需要修改数据表中的时间,对日期进行计算,如:对某个日期加上几天、几个小时等操作。在使用 mysql 查询数据的过程中,有时我们需要修改数据表中的时间,对日期进行计算,如:对某个日期加上几天、几个小时等操作。
SELECT DATE_ADD(date, INTERVAL expr type)
FROM table_name
其中:date 指代希望被操作的有效日期,为起始日期
expr 是希望添加的时间间隔的数值(expr 是一个字符串,对于负值的间隔,可以以 ”-“ 开头)
type 是具体的数据类型,表示加上时间间隔的单位(可以是 MICROSECOND , SECOND , MINUTE , HOUR , DAY , WEEK , MONTH , QUARTER , YEAR 等)
date sub()
DATE_SUB() 函数是常用的时间函数之一,用于从日期减去指定的时间间隔。它与 DATE_ADD() 函数具有相似的用法。
SELECT DATE_SUB(date, INTERVAL expr type)
FROM table_name
其中:date 指代希望被操作的有效日期
expr 是希望添加的时间间隔
type 是具体的数据类型(可以是 MICROSECOND , SECOND , MINUTE , HOUR , DAY , WEEK , MONTH , QUARTER , YEAR 等)
7. timediff
使用时间函数 DATEDIFF() 和 TIMESTAMPDIFF() 计算日期差
DATEDIFF() 常用的日期差,在 MySQL 中默认只能计算天数差。
SELECT DATEDIFF(时间1,时间2) AS date_diff FROM courses;
DATEDIFF() 差值计算规则:时间 1 - 时间 2
date_diff 为返回结果列名称
五、constraint
1.Reach a little consensus
- 约束,在某种理解程度上是将select的执行结果放置的更加具体
在前面的学习中我们知道了什么是主键约束和外键约束以及它们的应用,今天的我们来学习默认约束。 - 默认值(Default)”的完整称呼是“默认值约束(Default Constraint)”。MySQL 默认值约束用来指定某列的默认值。
在应用的时候可以理解为 DEFAULT 约束用于向列中插入默认值。
如果没有规定其他的值,那么会将默认值添加到所有的新记录。
使用 DEFAULT 关键字设置默认值约束,具体的语法规则如下所示:
<字段名> <数据类型> DEFAULT <默认值>
下面的 SQL 在 Persons表创建时在 City 列上创建 DEFAULT 约束:
MYSQL / SQL Server / Oracle / MS Access
CREATE TABLE `Persons`
(
`P_Id` int NOT NULL,
`LastName` varchar(255) NOT NULL,
`FirstName` varchar(255),
`Address` varchar(255),
`City` varchar(255) DEFAULT 'Sandnes'
)
通过使用类似 GETDATE() 这样的函数, DEFAULT 约束也可以用于插入系统值:
CREATE TABLE `Orders`
(
`O_Id` int NOT NULL,
`OrderNo` int NOT NULL,
`P_Id` int,
`OrderDate` date DEFAULT GETDATE()
)
select 和create 的default
之后是未学习的alter 作为一个表或者view 的修改
如果表已被创建时,想要在 City 列创建 DEFAULT 约束,请使用下面的 SQL:
MYSQL
ALTER TABLE `Persons`
ALTER `City` SET DEFAULT 'SANDNES'
SQL Server / MS Access:
ALTER TABLE `Persons`
ADD CONSTRAINT ab_c DEFAULT 'SANDNES' for `City`
default的撤销
如需撤销 Persons表的 DEFAULT 约束 :
MYSQL
ALTER TABLE `Persons`
ALTER `City` DROP DEFAULT
SQL Server / Oracle / MS Access:
ALTER TABLE `Persons`
ALTER COLUMN `City` DROP DEFAULT
2. all kinds of constraint
1.非空约束 not null
在建表或者插入一个新列的时候 对于属性数据的约束
NOT NULL 约束强制列不接受 NULL 值,强制字段始终包含值,这意味着,如果不向字段添加值,就无法插入新纪录或者更新记录。
2. 独一无二 unique
UNIQUE 约束唯一标识数据库表中的每条记录
UNIQUE 和 主键约束均为列或列集合提供了唯一性的保证
主键约束会自动定义一个 UNIQUE 约束,或者说主键约束是一种特殊的 UNIQUE 约束。但是二者有明显的区别:每个表可以有多个 UNIQUE 约束,但只能有一个主键约束。
在建表的时候加入unique的约束就是 设定属性的时候后面加一个unique
附加 unique的 约束
ALTER TABLE `Persons`
ADD CONSTRAINT uc_PersonID UNIQUE (`P_Id`,`LastName`)
撤销
ALTER TABLE `Persons`
DROP CONSTRAINT uc_PersonID
3. 外交小天才 key
内外同控,兼收并蓄
1.主键约束 primary
在前面的学习中我们学会了 NOT NULL 约束和
UNIQUE 约束的使用,今天带大家来认识主键约束,也叫 PRIMARY KEY 约束。
PRIMARY KEY 约束唯一标识数据库表中的每条记录 ,简单的说,PRIMARY KEY = UNIQUE + NOT NULL ,从技术的角度来看,PRIMARY KEY 和 UNIQUE 有很多相似之处。但还是有以下区别:
NOT NULL UNIQUE 可以将表的一列或多列定义为唯一性属性,而 PRIMARY KEY 设为多列时,仅能保证多列之和是唯一的,具体到某一列可能会重复。
PRIMARY KEY 可以与外键配合,从而形成主从表的关系,而 NOT NULL UNIQUE 则做不到这一点
如:
表一:用户 id (主键),用户名
表二: 银行卡号 id (主键),用户 id (外键)
则表一为主表,表二为从表。
更大的区别在逻辑设计上。 PRIMARY KEY 一般在逻辑设计中用作记录标识,这也是设置 PRIMARY KEY 的本来用意,而 UNIQUE 只是为了保证域/域组的唯一性。
一个样例sql语句
CREATE TABLE `Persons`
(
`P_Id` int NOT NULL,
`LastName` varchar(255) NOT NULL,
`FirstName` varchar(255),
`Address` varchar(255),
`City` varchar(255),
CONSTRAINT pk_PersonID PRIMARY KEY (`P_Id`,`LastName`)
)
上面是定义环节,之后加上额外补充主键和删除主键
ALTER TABLE `Persons`
ADD PRIMARY KEY (`P_Id`)
ALTER TABLE `Persons`
ADD CONSTRAINT pk_PersonID PRIMARY KEY (`P_Id`,`LastName`)`
alter table `courses`
drop primary key;``
2.外键约束 foreign
首先在学习外键约束之前我们先来认识一下什么是外键。一个表中的 FOREIGN KEY 指向另一个表中的 UNIQUE KEY 。
让我们看了例子,如果一个字段 X 在一张表(表 1 )中是关键字,而在另一张表(表 2 )中不是关键字,则称字段 X 为表 2 的外键。
外键最根本的作用:保证数据的完整性和一致性。这么说可能有些同学无法理解,接下来通过一个例子来深入理解一下。
现在有两张表——学生表和院系表,这里的院系就是学生表的外键,外键表是学生表,主键表是院系表。假如院系表中的某个院系被删除了,那么在学生表中要想查询这个被删除的院系号所对应的院信息就会报错,因为已经不存在这个系了,所以,删除院系表(主键表)时必须删除其他与之关联的表,这里就说明了外键的作用,保持数据的一致性、完整性。当然反过来讲,你删除学生表中的记录,并不影响院系表中的数据,你查询院系号也能正确查询。所以删除外键表中的数据并不影响主键表。
之后我们来同步学习建表和插入及其删除
CREATE TABLE `Orders`
(
`O_Id` int NOT NULL,
`OrderNo` int NOT NULL,
`P_Id` int,
PRIMARY KEY (O_Id),
FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
)
reference 一个接口 可以理解为
NOT NULL 表示该字段不为空
REFERENCES 表示 引用一个表
ALTER TABLE `Orders`
ADD FOREIGN KEY (P_Id)
REFERENCES Persons(P_Id)``
ALTER TABLE `Orders`
DROP FOREIGN KEY fk_PerOrders`
3. 规则监控户 check
CHECK 约束用于限制列中的值的范围,评估插入或修改后的值。满足条件的值将会插入表中,否则将放弃插入操作。 可以为同一列指定多个 CHECK 约束。
CHECK 约束既可以用于某一列也可以用于某张表:
如果对单个列定义 CHECK 约束,那么该列只允许特定的值。
如果对一个表定义 CHECK 约束,那么此约束会基于行中其他列的值在特定的列中对值进行限制。
定义 CHECK 约束条件在某种程度上类似于编写查询的 WHERE 子句,使用不同的比较运算符(例如 AND、OR、BETWEEN、IN、LIKE 和 IS NULL)编写其布尔表达式,该布尔表达式将返回 TRUE、FALSE 或 UNKNOWN 。 当条件中存在 NULL 值时,CHECK约束将返回 UNKNOWN 值。
CHECK 约束主要用于通过将插入的值限制为遵循定义的值、范围或格式规则的值来强制域完整性。
CREATE DATABASE IF NOT EXISTS hardy_db default character set utf8mb4 collate utf8mb4_0900_ai_ci;
USE hardy_db;
DROP TABLE IF EXISTS lesson;
六、 connection
表的连接是一个重难点,所以划分出来重点讲述
联结是一种机制,用于在一条 SELECT 语句中关联多个表,返回一组输出。
这个时候就要说一下联结中的两大主角——主键(PRIMARY KEY)和外键(FOREIGN KEY)。就是将刚才提及的外交小天才作为桥梁,把两个有一部分共同数据连接成新的表,有时候as命名 也有时候直接作为新的view保存起来保证以后的操作。
语法如下:
JOIN 连接子句
SQL JOIN 连接子句用于将数据库中两个或者两个以上表中的记录组合起来。其类型主要分为 INNER JOIN(内连接)、OUTER JOIN(外连接)、全连接(FULL JOIN)和交叉连接(CROSS JOIN),其中 OUTER JOIN 又可以细分为 LEFT JOIN(左连接)和 RIGHT JOIN(右连接)。
因此,我们主要使用的 JOIN 连接类型如下:
( xxx join ~on 语法)
`table1`.`common_field` = `table2`.`common_field`
INNER JOIN:如果表中有至少一个匹配,则返回行
LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
FULL JOIN:只要其中一个表中存在匹配,则返回行
CROSS JOIN:又称笛卡尔积,两个表数据一一对应,返回结果的行数等于两个表行数的乘积
1.inner join
最常用也最重要的多表联结类型就是 INNER JOIN(内连接),有时候也被称作 EQUIJOIN(等值连接)。
内连接根据联结条件来组合两个表中的字段,以创建一个新的结果表。假如我们想将表 1 和表 2 进行内连接,SQL 查询会逐个比较表 1 和表 2 中的每一条记录,来寻找满足联结条件的所有记录对。当联结条件得以满足时,所有满足条件的记录对的字段将会结合在一起构成结果表。
简单的说,内连接就是取两个表的交集,返回的结果就是连接的两张表中都满足条件的部分。
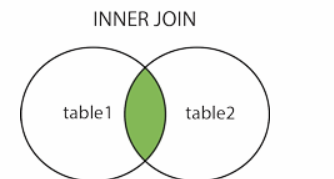
SELECT `table1`.`column1`, `table2`.`column2`...
FROM `table1`
INNER JOIN `table2`
ON `table1`.`common_field` = `table2`.`common_field`;
之后比较难的突发结构和理解,会使用几个样例供给学习
SELECT `c`.`id`, `c`.`name` AS `course_name`, `t`.`name` AS `teacher_email`
FROM `courses` `c`
INNER JOIN `teachers` `t` ON `c`.`teacher_id` = `t`.`id`;
courses c 等同于 courses AS c ,给courses 表取别名为 c
teachers t 等同于 teachers AS t ,给 teachers 表取别名为 t
INNER JOIN 也可写作 JOIN
join不可省,而join也默认是inner join
之前提及的便宜行事的 as
2.outer join
外连接在生活中是经常用到的,外连接也是针对于两张表格之间,比如我们实际应用过程会发现,会有一些新任职的教师,还在实习期,并无对应课程安排,那若是按照上一节使用内连接的话,这些教师的课程信息将无法导出来,我们应该如何操作呢?这个就要用到我们的外连接,外连接可以将某个表格中,在另外一张表格中无对应关系,但是也能将数据匹配出来。
在MySQL中,外连接查询会返回所操作的表中至少一个表的所有数据记录。在MySQL中,数据查询通过SQL语句 “OUTER JOIN…ON” 来实现,外连接查询可以分为以下三类:
左外连接
右外连接
全外连接
外连接数据查询语法如下:
SELECT column_name 1,column_name 2 ... column_name n
FROM table1
LEFT | RIGHT | FULL (OUTER) JOIN table2
ON CONDITION;
outer 可以省略,只要前面的left or right or full
下面重点讲一下 它的执行结果 left join
外连接查询中的左外连接就是指新关系中执行匹配条件时,以关键字 LEFT JOIN 左边的表为参考表。左外连接的结果包括 LEFT OUTER 子句中指定的左表的所有行,而不仅仅是连接列所匹配的行,这就意味着,左连接会返回左表中的所有记录,加上右表中匹配到的记录。如果左表的某行在右表中没有匹配行,那么在相关联的结果行中,右表的所有选择列表均为空值。
重心是左边的表
对比一下 right join
外连接查询中的右外连接是指新关系中执行匹配条件时,以关键字 RIGHT JOIN 右边的表为参考表,如果右表的某行在左表中没有匹配行,左表就返回空值。
SELECT column_name 1,column_name 2 ... column_name n
FROM table1
RIGHT JOIN table2
ON CONDITION ;
类比集合
记得集合吗?比如画两个圆,一左一右,中间有一部分是相重叠(相交)的。
内连接,两个集合相交的那部分数据。
左连接,左边的部分,以及中间相交的部分。
右连接,和左的相反理解。
全连接,左边的,右边的,还有中间重叠的。

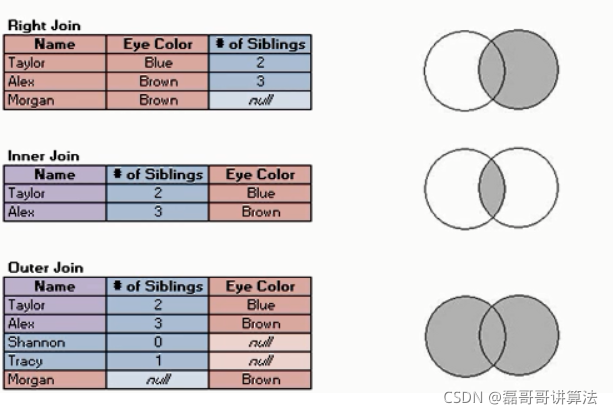
这样图像的解释是不是就变得更加清晰了呢
然后通过几个习题来解决一下这个问题
查询来自中国的教师名称,邮箱以及所教课程名称
select t2.name as course_name,
t1.name as teacher_name,
t1.email as teacher_email
from teachers as t1 left join courses as t2 on t1.id = t2.teacher_id
where t1.country = 'CN';
查询所有课程名称以及与其相互对应的教师名称和国籍
select c.name course_name, t.name teacher_name, t.country teacher_country
from courses c left join teachers t
on c.teacher_id = t.id
union
select c.name course_name, t.name teacher_name, t.country teacher_country
from courses c right join teachers t
on c.teacher_id = t.id;
这个题目比较难,所以结合了左连接union了右连接 teachers 和 courses的表格信息
3. cross join
与内连接和外连接相比,交叉连接非常简单,因为它不存在 ON 子句,那怎么理解交叉连接呢?
交叉连接:返回左表中的所有行,左表中的每一行与右表中的所有行组合。即将两个表的数据一一对应,其查询结果的行数为左表中的行数乘以右表中的行数。
CROSS JOIN(交叉连接)的结果也称作笛卡尔积,我们来简单了解一下什么是笛卡尔积:
笛卡尔乘积是指在数学中,两个集合 X 和 Y 的笛卡尓积(Cartesian product),又称直积,表示为X × Y,第一个对象是 X 的成员而第二个对象是 Y 的所有可能有序对的其中一个成员。
隐式交叉连接:不需要使用 CROSS JOIN 关键字,只要在 SELECT 语句的 FROM 语句后将要进行交叉连接的表名列出即可,这种方式基本上可以被任意数据库系统支持。
SELECT `table1`.`column1`, `table2`.`column2`...
FROM `table1`,`table2`;
显式交叉连接:与隐式交叉连接的区别就是它使用 CROSS JOIN 关键字,用法与 INNER JOIN 相似。
基本语法如下:
SELECT `courses`.`name` AS `course_name`, `teachers`.`name` AS `teacher_name`
FROM `courses`
CROSS JOIN `teachers`;
笛卡尔积就是将两个表一起乘积,在上面的图表中我们可以加强理解。
七、Q&A
对于甲方的花样查询的实现
1.having & group by
group by
GROUP BY 函数就是 SQL 中用来实现分组的函数,其用于结合聚合函数,能根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表。
SELECT `column_name`, aggregate_function(`column_name`)
FROM `table_name`
WHERE `column_name` operator value
GROUP BY `column_name`;
group by 并不是构建一个新的表,而是在输出阶段将数据作为一个新的整体,后面多跟 order by 排序之类的操作
可以看到我们教师表中的教师来自不同的国家,现需要统计不同国家教师的人数,
并将结果按照不同国籍教师人数从小到大排列,请编写相应的 SQL 语句实现。
SELECT `country`, COUNT(`country`) AS `teacher_count`
FROM `teachers`
GROUP BY `country`
ORDER BY `country`,`teacher_count`;
加入一个结合union表格以及之前一些信息的题目
请编写 SQL 语句,查询教师表 teachers 和课程表 courses,
统计每个老师教授课程的数量,并将结果按课程数量从大到小排列,
如果相同课程数量则按照教师姓名排列,
返回列名老师姓名列名显示为 teacher_name ,课程数量列名显示为 course_count。
select `t`.`name` as teacher_name ,count(`c`.`teacher_id`)as `course_count`
from `teachers` as t
left join `courses` as c
on t.id=c.teacher_id
group by teacher_name
order by course_count desc,teacher_name asc;
having
我们在使用 WHERE 条件子句时会发现其不能与聚合函数联合使用,为解决这一点,SQL 中提供了 HAVING 子句。在使用时, HAVING 子句经常与 GROUP BY 联合使用,HAVING 子句就是对分组统计函数进行过滤的子句。
HAVING 子句对于 GROUP BY 子句设置条件的方式其实与 WHERE 子句与 SELECT 的方式类似,语法也相近,但 WHERE 子句搜索条件是在分组操作之前,而 HAVING 则是在之后。
可以理解为将where +group by 之后 进行的新的非嵌套where 我们将它命名为having
SELECT `column_name`, aggregate_function(`column_name`)
FROM `table_name`
WHERE `column_name` operator value
GROUP BY `column_name`
HAVING aggregate_function(`column_name`) operator value;
实践题目
现需要结合教师表与课程表,统计不同教师所开课程的学生总数,对于没有任课的老师,学生总数计为 0 ,最后查询学生总数少于 3000 的教师姓名及学生总数 (别名为 student_count ),结果按照学生总数升序排列,如果学生总数相同,则按照教师姓名升序排列。
SELECT `T`.`name`, IFNULL(SUM(`C`.`student_count`),0) AS `student_count`
FROM `courses` `C`
RIGHT JOIN `teachers` `T` ON `C`.`teacher_id` = `T`.`id`
GROUP BY `T`.`id`
HAVING `student_count` < 3000
ORDER BY `student_count`, `name`;
2.子查询 套娃行为
当一个查询是另一个查询的条件时,称之为子查询。
即在查询语句中的 WHERE 条件子句中,又嵌套了另一个查询语句。
因此,子查询本质上就是一个完整的 SELECT 语句,它可以使一个 SELECT、INSERT INTO 语句、DELETE 语句或 UPDATE 语句嵌套在另一子查询中。子查询的输出可以包括一个单独的值(单行子查询)、几行值(多行子查询)、或者多列数据(多列子查询)。
SELECT `column_name(s)`
FROM `table_name`
WHERE `column_name` OPERATOR (
SELECT `column_name(s)`
FROM `table_name`
);
而之后的 insert into delete update set 都是一样的,在原有的基础上进行了套娃,同样,如果出现了大量的套娃,联合表也就是各种join的效果和执行速率往往更便捷一些
3.内联视图
介绍的内联视图子查询,是将子查询插入到表名 table_name 的位置。
并不是created view,而是简单的把提取出来的“table”作为一个新的执行平台进行select
举一个 栗子(唔西迪西)
SELECT *
FROM (
SELECT *
FROM `teachers`
WHERE `country` = 'USA'
) `T`
WHERE `age` = (
SELECT MAX(`age`)
FROM `teachers`
);
4. in any all
使用 IN 操作符进行子查询,其实是将子查询返回的集合和外层查询得到的集合进行交集运算,这个结果可以是零个值,也可以是多个值。由此,最后可以查询出与列表中任意一个值匹配的行。
SELECT `column_name`
FROM `table_name`
WHERE `column_name` IN(
SELECT `column_name`
FROM `table_name`
WHERE `column_name` = VALUE
);
操作符 ANY 属于逻辑运算符的一种,与 IN 运算符不同,ANY 必须和其它的比较运算符共同使用,其表示查询结果中的任意一个。
在子查询中使用 ANY ,表示与子查询返回的任何值比较为真,则返回真。
SELECT `column_name(s)`
FROM `table_name`
WHERE `column_name` OPERATOR
ANY(SELECT column_name
FROM table_name)
个人认为 any的存在是一个双保险,对于operate后的加强确认或者其他附加条件,比如下面的这个例子
现需要查询学生上课人数超过
“Eastern Heretic” 的任意一门课的
学生人数的课程信息,
请使用 ANY 操作符实现多行子查询。
SELECT *
FROM `courses`
WHERE `student_count` > ANY (
SELECT `student_count`
FROM `courses`
WHERE `teacher_id` = (
SELECT `id`
FROM `teachers`
WHERE `name` = 'Eastern Heretic'
)
)
AND `teacher_id` <> (
SELECT `id`
FROM `teachers`
WHERE `name` = 'Eastern Heretic'
);
在子查询中使用 ALL ,表示与子查询返回的所有值比较为真,则返回真。
any 和all对比记忆它们之间的功能差异
SELECT `column_name(s)`
FROM `table_name`
WHERE `column_name` OPERATOR
ALL(SELECT column_name
FROM table_name)
现需要查询学生人数超过 ”Western Venom“
所有课程学生人数的课程信息,
请使用 ALL 操作符实现多行子查询。
SELECT *
FROM `courses`
WHERE `student_count` > ALL(
SELECT `student_count`
FROM `courses`
WHERE `teacher_id` = (
SELECT `id`
FROM `teachers`
WHERE `name` = 'Western Venom'
)
);
5.多子列查询
在嵌套中不仅仅只要一个数据,上级也要对进行操作的话,多子列查询就有使用的必要性,并且也一种简单的外延而已,比如这道例题
查询每个教师授课学生人数最高的课程名称和上课人数
select name,student_count from courses
where (teacher_id,student_count) in(
select teacher_id,max(student_count)
from courses
group by teacher_id
)
当子查询出现在 HAVING 子句中时,像 HAVING 子句中的任何表达式一样,表示要进行分组过滤,它被用作行组选择的一部分,一般返回单行单列的数据。having的进阶教程
看题
现需要计算每位教师所开课程的平均学生人数与全部课程的平均学生人数,
比较其大小,最后返回超过全部课程平均学生人数的教师姓名,
请编写相应的 SQL 语句实现。
SELECT `name`
FROM `teachers`
WHERE `id` IN (
SELECT `teacher_id`
FROM `courses`
GROUP BY `teacher_id`
HAVING AVG(`student_count`) > (
SELECT AVG(`student_count`)
FROM `courses`
)
);
查询 'U' 字开头且
学生总数在 2000 到 5000 之间的
教师国籍和该国籍的学生总数 (包含了近来的所有语法 很nice)
select
t.country,
sum(c.student_count) as student_count
from courses c
join teachers t
on
t.id=c.teacher_id
where country like 'U%'
group by
country
having
student_count between 2000 and 5000
order by
student_count desc,country
;
八、sql transaction
sql事务,本章后就在语法的基础上,开始讲逻辑和概念啦(汤姆卜利卜)
1.MySQL 事务
为了理解什么是 MySQL 中的事务,让我们看一下在我们的样本数据库中添加一个新的销售订单的例子。添加一个销售订单的步骤如下所述:
首先,从 orders 表中查询最新的销售订单号,并使用下一个销售订单号作为新的销售订单号。
接下来,在 orders 表中插入一个新的销售订单。
然后,获得新插入的销售订单号
之后,将新的销售订单项目与销售订单号一起插入到 orderdetails 表中
最后,从 orders 和 orderdetails 表中选择数据,以确认这些变化。
现在,想象一下,如果上述一个或多个步骤由于某些原因(如表锁定)而失败,销售订单数据会发生什么?例如,如果将订单的项目添加到 orderdetails 表中的步骤失败,你将会有一个空的销售订单。
这就是为什么事务处理要来拯救你。MySQL 事务允许你执行一组 MySQL 操作,以确保数据库从不包含部分操作的结果。在一组操作中,如果其中一个操作失败,就会发生回滚,将数据库恢复到其原始状态。如果没有发生错误,整个语句集就会提交到数据库中。
从一个整体的流程进行介绍
为了启动一个事务,你使用 START TRANSACTION 语句
BEGIN 或 BEGIN WORK 是 START TRANSACTION 的别名。
比如
begin;(但也要记得end;收尾)
要提交当前事务并使其变化永久化,你要使用 COMMIT 语句。
要回滚当前事务并取消其变化,你可以使用 ROLLBACK 语句
要禁用或启用当前事务的自动提交模式,你可以使用 SET autocommit 语句。
默认情况下,MySQL 自动将更改永久性地提交给数据库。
要强迫 MySQL 不自动提交更改,你可以使用以下语句:
SET autocommit = 0;
-- OR --
SET autocommit = OFF
自动提交模式
SET autocommit = 1;
-- OR --
SET autocommit = ON;
模拟一个事务流程,事务流程图如图所示

-- 1. start a new transaction
START TRANSACTION;
-- 2. Get the latest order number
SELECT
@orderNumber:=MAX(orderNUmber)+1
FROM
orders;
-- 3. insert a new order for customer 145
INSERT INTO orders(orderNumber,
orderDate,
requiredDate,
shippedDate,
status,
customerNumber)
VALUES(@orderNumber,
'2005-05-31',
'2005-06-10',
'2005-06-11',
'In Process',
145);
-- 4. Insert order line items
INSERT INTO orderdetails(orderNumber,
productCode,
quantityOrdered,
priceEach,
orderLineNumber)
VALUES(@orderNumber,'S18_1749', 30, '136', 1),
(@orderNumber,'S18_2248', 50, '55.09', 2);
-- 5. commit changes
COMMIT;
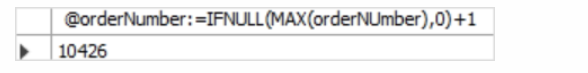
查询一个销货订单
SELECT
a.orderNumber,
orderDate,
requiredDate,
shippedDate,
status,
comments,
customerNumber,
orderLineNumber,
productCode,
quantityOrdered,
priceEach
FROM
orders a
INNER JOIN
orderdetails b USING (orderNumber)
WHERE
a.ordernumber = 10426;

2.lock 宫锁心玉了解一下
锁的解释
锁:计算机协调多个进程或线程并发访问某一资源的机制。
锁的重要性
在数据库中,除了传统的计算资源(CPU、RAM、I\O等)的争抢,数据也是一种供多用户共享的资源。
因此,如何保证数据并发访问的一致性,有效性,是所有数据库必须要解决的问题。
锁冲突也是影响数据库并发访问性能的一个重要因素,因此锁对数据库尤其重要。
锁的缺点
加锁是消耗资源的,锁的各种操作,包括:获得锁、检测锁是否已经解除、释放锁等,都会增加系统的开销。
锁就是保险箱,虽然提高了安全系数,但你也变得不方便了
查看当前数据库的事务隔离级别的语句 core
SHOW VARIABLES like '%isolation%';
1. Auto-inc Locks
自增锁(Auto-inc Locks; table-level lock)
查询当前数据库的自增锁模式:
show variables like '%innodb_autoinc_lock_mode%';
0:traditonal 每次 insert 语句执行都会产生表锁
1:consecutive simple insert 会获得批量的锁,保证一批插入自增序列的连续性,插入之前提前释放锁,在这个模式下你会发现当你 insert 多条数据回滚的时候虽然 DB 没有插入数据,但是自增 ID 已经增长了,也是数据库默认的级别
2:interleaved 不会锁表,实时插入,并发最高,但是基于主从的复制是不安全的,感兴趣可以去查询 RBR 和 SBR 的优缺点
3.直观的转述一下就是
自增锁是一种特殊的表级别锁(table-level lock),专门针对事务插入 AUTO_INCREMENT 类型的列。最简单的情况,如果一个事务正在往表中插入记录,所有其他事务的插入必须等待,以便第一个事务插入的行,是连续的主键值。
innodb_autoinc_lock_mode = 0
在这一模式下,所有的 insert 语句都要在语句开始的时候得到一个表级的 auto_inc 锁,在语句结束的时候才释放,这种模式下 auto_inc 锁一直要保持到语句的结束,所以这个就影响到了并发的插入,但是主从同步时候是安全的。
innodb_autoinc_lock_mode = 1
这一模式下去 simple insert 做了优化,由于 simple insert 一次性插入值的个数可以立马得到确定,所以 MySQL 可以一次生成几个连续的值,用于这个 insert 语句,也保证主从同步基于语句的复制安全。这一模式也是 MySQL 的默认模式,这个模式的好处是 auto_inc 锁不要一直保持到语句的结束,只要语句得到了相应的值后就可以提前释放锁
innodb_autoinc_lock_mode = 2
无自增锁,会导致上面案例的问题,同一批 insert 提交自增不连续。
2.Shared and Exclusive Locks
瓶颈期:并发控制
提到共享锁和排它锁就不得不提并发控制(Concurrency Control),并发控制可以解决临界资源操作时不一致的情况产生,保证数据一致性常见的手段就是锁和数据多版本(Multi Version)。同时存在直接加锁的解决方法,但这种方式会导致被加锁的资源都被锁住,读取任务也无法执行直到锁释放,所有执行的任务相当于串行化方式,简单粗暴,不能并发。
共享锁(Shared Locks)简称为 S 锁
读取数据时候可以加 S 锁。
共享 (S) 锁允许并发事务读取 (SELECT) 一个资源。资源上存在共享 (S) 锁时,任何其它事务都不能修改数据。一旦已经读取数据,便立即释放资源上的共享 (S) 锁,除非将事务隔离级别设置为可重复读或更高级别,或者在事务生存周期内用锁定提示保留共享 (S) 锁。
排它锁 (Exclusive Locks)简称为 X 锁
修改数据时候加 X 锁。
排它 (X) 锁可以防止并发事务对资源进行访问。其它事务不能读取或修改排它 (X) 锁锁定的数据。
共享锁之间可以并行,排它锁和共享锁之间互斥,也就是说只要共享锁开启没有释放掉的时候,更新锁是不能抢占的,此时其他读取同资源的操作可以进行读取不受限制;同理排它锁开启时候只要没有释放其他不管是排它锁还是共享锁都不可以抢占资源直到锁释放。
3. locks 操作
1.表锁
隐式上锁(默认,自动加锁、自动释放)
MyISAM 在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT等)前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此用户一般不需要直接用 LOCK TABLE; 命令给 MyISAM 表显式加锁。 相当于自带的,不需要另外操作。
显式上锁
上共享锁(读锁)的写法:lock in share mode
select column_name from table_name where lock in share mode;
上排它锁(写锁)的写法:for update
select column_name from table_name where conditions for update;
解锁
UNLOCK TABLES;
查看表锁
SHOW OPEN TABLES;
2.行锁
行锁是 MySQL 中粒度最细的一种锁机制,只对当前所操作的行进行加锁,行锁发生冲突的概率很低,其粒度最小,但加锁的代价最大。行锁有分为共享锁(S 锁)和排他锁(X 锁)。
隐式上锁(默认,自动加锁、自动释放) 也就是增删改查,基础操作
显示上锁(手动)LOCK IN SHARE MODE 与 FOR UPDATE 只能在事务内其作用,以保证当前会话事务锁定的行不会被其他会话修改。
-- 读锁 --
SELECT *
FROM table_name
LOCK IN SHARE MODE;
-- 写锁 --
SELECT *
FROM table_name
FOR UPDATE;
查看行锁
SHOW STATUS LIKE 'innodb_row_lock%'
解锁(手动)
提交事务(commit)
回滚事务(rollback)
阻塞进程(kill)
对于上锁有好处也有坏处,如何让收益最大化是这个的关键,所以应该做到
尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
合理设计索引,尽量缩小锁的范围
尽可能较少检索条件,避免间隙锁
尽量控制事务大小,减少锁定资源量和时间长度
尽可能低级别事务隔离
4.trigger 触发器
在 MySQL 中,触发器是一个存储程序,它对相关表中发生的插入、更新或删除等事件自动调用。
例如,你可以定义一个触发器,在向表中插入新行之前自动调用。
MySQL 支持响应 INSERT、UPDATE 或 DELETE 事件而调用的触发器。
SQL 标准定义了两种类型的触发器:行级触发器和语句级触发器。
触发器类似编程里的日志记录,不单单可以记录和以后的查看回滚,也可以进行一些数据再操作或者check
CREATE TRIGGER trigger_name
{BEFORE | AFTER} {INSERT | UPDATE| DELETE }
ON table_name FOR EACH ROW
trigger_body;
删除触发器
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name;
展示触发器
show triggers
new 和old是触发器对于数据的甄别和再操作的前提,所以用new和old来区分到底谁在trigger里面执行抑或者怎么执行。
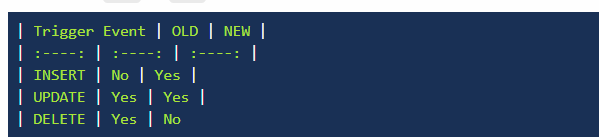
触发器的创建和语法 new和old 要结合trigger语法的可行性考虑,只能操作存在的元素项。
BEFORE INSERT
CREATE TRIGGER trigger_name
BEFORE INSERT
ON table_name FOR EACH ROW
//trigger_body;
begin
//执行内容
end;
after insert 以及之后的update 和delete 如出一辙,只需要缓一缓trigger后的名词和考虑每组trigger要执行的内容即可。
当存在多个触发器的时候,就要讲究次序,那么就引入
DELIMITER $$
CREATE TRIGGER trigger_name
{BEFORE|AFTER}{INSERT|UPDATE|DELETE}
ON table_name FOR EACH ROW
{FOLLOWS|PRECEDES} existing_trigger_name
BEGIN
-- statements
END$$
DELIMITER ;
在这个语法中,FOLLOWS 或 PRECEDES 指定了新的触发器应该在现有触发器之前或之后被调用。
FOLLOWS 允许新的触发器在一个现有的触发器之后激活。
PRECEDES 允许新的触发器在现有触发器之前激活。
MySQL 允许你通过使用 CALL 语句从一个触发器调用一个存储过程。通过这样做,你可以在几个触发器中重复使用同一个存储过程。
然而,触发器不能调用有 OUT 或 INOUT 参数的存储过程,或使用动态 SQL 的存储过程。
解决这种情况通常 用create procedure 与call的联动来未卜先知
比如银行取钱的例子,用户取钱之前先得让系统查一下有没有钱,不然怎么取钱呢,所以在银行的数据库中会增加一个procedure的附加进程,在被call调用,它的存在可以被理解为,goto语句或者内敛函数,省着重复去写,但也要提前申明它的生命周期。
拿银行做一个例子
DELIMITER $$
CREATE PROCEDURE Withdraw(
fromAccountId INT,
withdrawAmount DEC(10,2)
)
BEGIN
IF withdrawAmount <= 0 THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'The withdrawal amount must be greater than zero';
END IF;
UPDATE accounts
SET amount = amount - withdrawAmount
WHERE accountId = fromAccountId;
END$$
DELIMITER ;
DELIMITER $$
CREATE TRIGGER before_accounts_update
BEFORE UPDATE
ON accounts FOR EACH ROW
BEGIN
CALL CheckWithdrawal (
OLD.accountId,
OLD.amount - NEW.amount
);
END$$
DELIMITER ;
九、view the end war(小点点小豆豆)
1.view
结合文章一开始的引入环节,view和tables的关系就变成了变相的将查询保存在一个文件中,可以是 .txt 或 .sql 文件,以便稍后可以从 MySQL Workbench 或任何其他 MySQL 客户端工具打开和执行它。所以可以有一个明确的合理定义:
将查询保存在数据库服务器中,并为其指定一个名称。这种命名的查询被称为数据库视图,或者简单地说:视图。
用文章开头的预设tables
CREATE VIEW v_courses_teachers
AS
SELECT courses.name AS name, created_at, teachers.name AS teacher
FROM courses
INNER JOIN teachers ON courses.teacher_id = teachers.id;
一旦你执行了 CREATE VIEW 语句,MySQL 就会创建视图并将其存储在数据库中。
现在,你可以在 SQL 语句中把该视图作为表来引用。例如,你可以使用 SELECT 语句查询 v_courses_teachers 视图的数据:
请注意,视图并不实际存储数据。当你对视图发出 SELECT 语句时,MySQL 会执行视图定义中指定的基础查询,并返回结果集。由于这个原因,有时,视图被称为虚拟表。
MySQL 允许你根据从一个或多个表中检索数据的 SELECT 语句创建一个视图。这张图片说明了一个基于多个表的列的视图。

使用view 有着很大的优势
MySQL 视图的优势
-
简化复杂的查询
视图有助于简化复杂的查询。如果你有任何经常使用的复杂查询,你可以基于它创建一个视图,这样你就可以通过使用一个简单的 SELECT 语句来引用该视图,而不是重新输入查询内容。 -
使业务逻辑一致
假设你不得不在每个查询中重复写相同的公式。或者你有一个具有复杂业务逻辑的查询。为了使这种逻辑在不同的查询中保持一致,你可以使用一个视图来存储计算结果,并隐藏其复杂性。 -
增加额外的安全层
一个表可能会暴露出很多数据,包括敏感数据,如个人和银行信息。
通过使用视图和权限,你可以限制用户可以访问哪些数据,只向他们暴露必要的数据。
例如,表 employees 可能包含 SSN 和地址信息,这些信息应该只由人力资源部门访问。
如果要将一般信息,如名字、姓氏和性别暴露给总务部门,你可以基于这些列创建一个视图,并授予总务部门的用户访问该视图,而不是整个表 employees。 -
实现向后兼容
在遗留系统中,视图可以实现向后兼容。
假设,你想把一个大表规范化为许多小表。而且你不想影响当前引用该表的应用程序。
在这种情况下,你可以在新表的基础上创建一个名称与表相同的视图,这样所有的应用程序都可以像引用表一样引用该视图。
5.需要注意的是 view与table 不可重名
2. create view
CREATE VIEW 语句在数据库中创建一个新的视图。下面是 CREATE VIEW 语句的基本语法:
CREATE [OR REPLACE] VIEW [db_name.]view_name [(column_list)]
AS
select-statement;
如果你想替换一个已经存在的视图,请使用 OR REPLACE 选项。如果该视图不存在,OR REPLACE 没有任何作用。
默认情况下,CREATE VIEW 语句在当前数据库中创建一个视图。如果你想在给定的数据库中明确地创建一个视图,你可以用数据库的名称来限定视图的名称。
view就是变相的table 可以这样借鉴式的学习和使用view
基于一个视图创建视图
MySQL 允许您基于另一个视图来创建视图。
例如,您可以创建一个名为 bigSalesOrder 的视图基于 salesPerOrder,查看以显示总计大于 60000 的每个销售订单如下:
CREATE VIEW bigSalesOrder AS
SELECT
orderNumber,
ROUND(total,2) as total
FROM
salePerOrder
WHERE
total > 60000;
view的操作和语法和table的基本一致只需要将table 换成view即可,在这里就不再赘述了
MySQL ALTER VIEW 语句改变了一个现有视图的定义。ALTER VIEW 的语法与 CREATE VIEW 语句相似。
ALTER
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement;
展示全部视图
SHOW FULL TABLES
WHERE table_type = 'VIEW';
因为 SHOW FULL TABLES 语句同时返回表和视图,你需要添加一个
WHERE 子句来只获得视图。
如果你想显示另一个数据库的所有视图,你可以使用这个语法:
SHOW FULL TABLES
[{FROM | IN } database_name]
WHERE table_type = 'VIEW';
在这个语句中,我们在 FROM 或 IN 子句后面指定了要显示视图的数据库名称。
下面的例子显示了来自 sys 数据库的所有视图:
SHOW FULL TABLES IN sys
WHERE table_type='VIEW';
重命名
用于重命名视图的 RENAME TABLE 的基本语法:
RENAME TABLE original_view_name
TO new_view_name;
在这个语法中:
首先,在 RENAME TABLE 关键字后面指定要重命名的视图的名称。
然后,在 TO 关键字后面指定视图的新名称。
注意,你不能使用 RENAME TABLE 语句将视图从一个数据库移到另一个数据库。
试图这样做将导致一个错误。
另一种间接重命名视图的方法是使用 DROP VIEW 和 CREATE VIEW 语句的序列。
首先,使用 SHOW CREATE VIEW 语句来复制视图的 DDL。
其次,使用 DROP VIEW 语句放弃该视图。
最后,用你在步骤 1 中复制的 DDL 创建一个新的视图,并将其重新命名。
通过使用一连串的 DROP 和 CREATE VIEW 语句,
你可以将一个视图从一个数据库转移到另一个数据库。
删除视图
DROP VIEW 语句从数据库中删除了一个视图。
DROP VIEW [IF EXISTS] view_name;
在这个语法中,你在 DROP VIEW 关键字后面指定要删除的视图的名称。
IF EXISTS 选项只有在视图存在的情况下才会有条件地删除该视图。
要一次删除多个视图,可以使用下面的语法:
DROP VIEW [IF EXISTS] view_name1 [,view_name2]...;
在这种语法中,如果在 DROP VIEW 子句后指定的任何视图不存在,
DROP VIEW 语句就会失败,并且不会删除任何视图。
如果你使用 IF EXISTS 选项,并且有一些视图不存在,
DROP VIEW 语句会为每个不存在的视图生成一个 Note。
3. MERGE、TEMPTABLE 和 UNDEFINE
CREATE VIEW 和 ALTER VIEW 语句有一个可选的子句:ALGORITHM。
它决定了 MySQL 如何处理一个视图,可以取三个值之一:MERGE、TEMPTABLE 和 UNDEFINE。也就是视图处理算法
1.algorithm
CREATE [OR REPLACE][ALGORITHM = {MERGE | TEMPTABLE | UNDEFINED}]
VIEW
view_name[(column_list)]
AS
select-statement;
1. merge
当你从 MERGE 视图查询时,MySQL 处理以下步骤。
首先,将输入查询与视图定义中的 SELECT 语句合并为一个单一的查询。
然后,执行合并后的查询以返回结果集。
注意,将输入查询和视图定义的 SELECT 语句合并成一个单一的查询被称为视图解析。
2.TEMPTABLE
当你向 TEMPTABLE 视图发出查询时,MySQL 会执行这些步骤。
首先,创建一个临时表来存储视图定义中的 SELECT 的结果。
然后,针对该临时表执行输入查询。
因为 MySQL 必须创建临时表来存储结果集,并将数据从基表移到临时表,所以 TEMPTABLE 算法的效率比 MERGE 算法低。
注意,TEMPTABLE 视图不能被更新。
3.UNDEFINED
当你创建视图而不指定 ALGORITHM 子句或明确指定 ALGORITHM=UNDEFINED 时,UNDEFINED 是默认算法。
此外,当你用 ALGORITHM=MERGE 创建视图,而 MySQL 只能用临时表处理该视图时,MySQL 会自动将算法设置为 UNDEFINED 并产生一个警告。
UNDEFINED 允许 MySQL 选择 MERGE 或 TEMPTABLE。而如果可能的话,MySQL 更倾向于 MERGE 而不是 TEMPTABLE,因为 MERGE 通常比 TEMPTABLE 更有效。
2. Adjustable
在 MySQL中,视图不仅是可查询的,也是可更新的。
这意味着你可以使用 INSERT 或 UPDATE 语句。
也可以使用 DELETE 语句通过视图删除基础表的行。
however
要创建一个可更新的视图,定义该视图的 SELECT 语句不能包含以下任何元素。
聚合函数,如 MIN,MAX,SUM,AVG 和 COUNT
DISTINCT
GROUP BY 子句
HAVING 子句
UNION 或 UNION ALL 子句
外连接
在 SELECT 子句或 WHERE 子句中的子查询,指的是在 FROM 子句中出现的表
在 FROM 子句中对不可更新的视图的引用
只引用字面意义的值
对基表的任何列的多次引用
如果你用 TEMPTABLE 算法创建一个视图,你不能更新这个视图。
注意,有时可以使用内部连接来创建基于多个表的可更新视图。
4. WITH CHECK OPTION
有时,你创建一个视图来显示一个表的部分数据。然而,一个简单的视图是可更新的,因此有可能更新那些通过视图不可见的数据。这种更新会使视图不一致。为了确保视图的一致性,在创建或修改视图时,要使用 WITH CHECK OPTION 子句。
WITH CHECK OPTION 是 CREATE VIEW 语句的一个可选子句。WITH CHECK OPTION 防止视图更新或插入通过它不可见的行。换句话说,每当你通过视图更新或插入基表的行时,MySQL 确保插入或更新操作符合视图的定义。
CREATE [OR REPLACE VIEW] view_name
AS
select_statement
WITH CHECK OPTION;
十、summary
文章结束啦,很基础的语法并且也结合了个人理解。
一些练习题可以多csdn或者百度一下,一开始个人也不是很了解,但是刷了一周的sql习题,嵌套 文本转换分析 连接表这几个重点也逐渐突破了,可以给其他初学者或者rush 期末的同学借鉴一下。
文章里也有两个彩蛋 ,一个是花园宝宝id,另一个是某人的生日啦。
sql永无止境,有一个良好的sql基础,也是写项目的稳定基石。
That is all ,it is my pLeasure!
by icelei
















 933
933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











