







 博客围绕关联分析、数据集预处理压缩和推荐算法展开。关联分析介绍了Apriori原理和FP - growth算法;数据集预处理压缩涉及PCA主成分简化数据和SVD简化数据;还提及主流推荐方法,如基于知识的推荐,旨在帮助用户从海量信息中找到感兴趣内容。
博客围绕关联分析、数据集预处理压缩和推荐算法展开。关联分析介绍了Apriori原理和FP - growth算法;数据集预处理压缩涉及PCA主成分简化数据和SVD简化数据;还提及主流推荐方法,如基于知识的推荐,旨在帮助用户从海量信息中找到感兴趣内容。
引言
论如何在塔罗牌和代码中寻找你的命定之人,通过关联分析算法的前后原理迭代即可快速遇到crush
论如何用推荐算法找到Mr.idea or Mrs.right
tips:二进制恋爱中方予可做了一个追周林林的小程序,可以理解为推荐算法+关联分析+匈牙利舞会题。
关联分析
关联分析是一种在大规模数据集中寻找联通关系的任务,分为两种情况:
- 频繁项集(frequent item sets): 经常出现在一块的物品的集合。
- 关联规则(associational rules): 暗示两种物品之间可能存在很强的关系。
关联分析(关联规则学习):从大规模数据集中寻找物品间的隐含关系被称作 关联分析(associati analysis) 或者 关联规则学习(association rule learning) 。 下面是用一个 杂货店 例子来说明这两个概念,如下图所示:
Apriori原理

如果我们计算所有组合的支持度,也需要计算 15 次。即 2^N - 1 = 2^4 - 1 = 15。
随着物品的增加,计算的次数呈指数的形式增长 …
为了降低计算次数和时间,研究人员发现了一种所谓的 Apriori 原理,即某个项集是频繁的,那么它的所有子集也是频繁的。 例如,如果 {0, 1} 是频繁的,那么 {0}, {1} 也是频繁的。 该原理直观上没有什么帮助,但是如果反过来看就有用了,也就是说如果一个项集是 非频繁项集,那么它的所有超集也是非频繁项集,如下图所示:
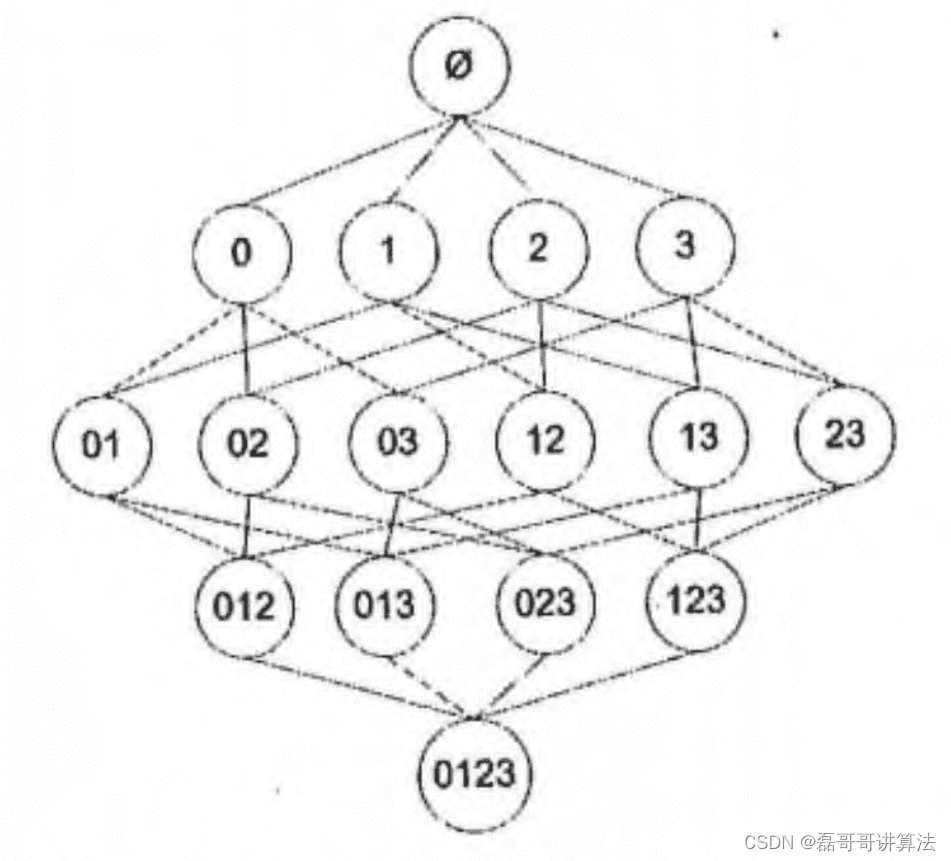
前面提到,关联分析的目标包括两项: 发现 频繁项集 和发现 关联规则。 首先需要找到 频繁项集,然后才能发现 关联规则。
先验集合
Apriori 算法是发现 频繁项集 的一种方法。 Apriori 算法的两个输入参数分别是最小支持度和数据集。 该算法首先会生成所有单个物品的项集列表。 接着扫描交易记录来查看哪些项集满足最小支持度要求,那些不满足最小支持度要求的集合会被去掉。 燃尽后对生下来的集合进行组合以声场包含两个元素的项集。 接下来再重新扫描交易记录,去掉不满足最小支持度的项集。 该过程重复进行直到所有项集被去掉。
加载数据集
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
# 创建集合 C1。即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
# 遍历所有的元素,如果不在 C1 出现过,那么就 append
C1.append([item])
# 对数组进行 `从小到大` 的排序
# print 'sort 前=', C1
C1.sort()
# frozenset 表示冻结的 set 集合,元素无改变;可以把它当字典的 key 来使用
return map(frozenset, C1)
生成候选集
- 计算候选集CK,当然了它不是凯文克莱恩香水名称,在数据集D中的支持度,并返回支持度大于最小支持度的数据
- 输入频繁项集列表 Lk 与返回的元素个数 k,然后输出所有可能的候选项集 Ck
- 找出数据集 dataSet 中支持度 >= 最小支持度的候选项集以及它们的支持度。即我们的频繁项集。
def scanD(D, Ck, minSupport):
"""scanD(计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于最小支持度 minSupport 的数据)
Args:
D 数据集
Ck 候选项集列表
minSupport 最小支持度
Returns:
retList 支持度大于 minSupport 的集合
supportData 候选项集支持度数据
"""
# ssCnt 临时存放选数据集 Ck 的频率. 例如: a->10, b->5, c->8
ssCnt = {}
for tid in D:
for can in Ck:
# s.issubset(t) 测试是否 s 中的每一个元素都在 t 中
if can.issubset(tid):
if not ssCnt.has_key(can):
ssCnt[can] = 1
else:
ssCnt[can] += 1
numItems = float(len(D)) # 数据集 D 的数量
retList = []
supportData = {}
for key in ssCnt:
# 支持度 = 候选项(key)出现的次数 / 所有数据集的数量
support = ssCnt[key]/numItems
if support >= minSupport:
# 在 retList 的首位插入元素,只存储支持度满足频繁项集的值
retList.insert(0, key)
# 存储所有的候选项(key)和对应的支持度(support)
supportData[key] = support
return retList, supportData
# 输入频繁项集列表 Lk 与返回的元素个数 k,然后输出所有可能的候选项集 Ck
def aprioriGen(Lk, k):
"""aprioriGen(输入频繁项集列表 Lk 与返回的元素个数 k,然后输出候选项集 Ck。
例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2}
仅需要计算一次,不需要将所有的结果计算出来,然后进行去重操作
这是一个更高效的算法)
Args:
Lk 频繁项集列表
k 返回的项集元素个数(若元素的前 k-2 相同,就进行合并)
Returns:
retList 元素两两合并的数据集
"""
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk):
L1 = list(Lk[i])[: k-2]
L2 = list(Lk[j])[: k-2]
# print '-----i=', i, k-2, Lk, Lk[i], list(Lk[i])[: k-2]
# print '-----j=', j, k-2, Lk, Lk[j], list(Lk[j])[: k-2]
L1.sort()
L2.sort()
# 第一次 L1,L2 为空,元素直接进行合并,返回元素两两合并的数据集
# if first k-2 elements are equal
if L1 == L2:
# set union
# print 'union=', Lk[i] | Lk[j], Lk[i], Lk[j]
retList.append(Lk[i] | Lk[j])
return retList
# 找出数据集 dataSet 中支持度 >= 最小支持度的候选项集以及它们的支持度。即我们的频繁项集。
def apriori(dataSet, minSupport=0.5):
"""apriori(首先构建集合 C1,然后扫描数据集来判断这些只有一个元素的项集是否满足最小支持度的要求。那么满足最小支持度要求的项集构成集合 L1。然后 L1 中的元素相互组合成 C2,C2 再进一步过滤变成 L2,然后以此类推,知道 CN 的长度为 0 时结束,即可找出所有频繁项集的支持度。)
Args:
dataSet 原始数据集
minSupport 支持度的阈值
Returns:
L 频繁项集的全集
supportData 所有元素和支持度的全集
"""
# C1 即对 dataSet 进行去重,排序,放入 list 中,然后转换所有的元素为 frozenset
C1 = createC1(dataSet)
# print 'C1: ', C1
# 对每一行进行 set 转换,然后存放到集合中
D = map(set, dataSet)
# print 'D=', D
# 计算候选数据集 C1 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据
L1, supportData = scanD(D, C1, minSupport)
# print "L1=", L1, "\n", "outcome: ", supportData
# L 加了一层 list, L 一共 2 层 list
L = [L1]
k = 2
# 判断 L 的第 k-2 项的数据长度是否 > 0。第一次执行时 L 为 [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])]]。L[k-2]=L[0]=[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])],最后面 k += 1
while (len(L[k-2]) > 0):
# print 'k=', k, L, L[k-2]
Ck = aprioriGen(L[k-2], k) # 例如: 以 {0},{1},{2} 为输入且 k = 2 则输出 {0,1}, {0,2}, {1,2}. 以 {0,1},{0,2},{1,2} 为输入且 k = 3 则输出 {0,1,2}
# print 'Ck', Ck
Lk, supK = scanD(D, Ck, minSupport) # 计算候选数据集 CK 在数据集 D 中的支持度,并返回支持度大于 minSupport 的数据
# 保存所有候选项集的支持度,如果字典没有,就追加元素,如果有,就更新元素
supportData.update(supK)
if len(Lk) == 0:
break
# Lk 表示满足频繁子项的集合,L 元素在增加,例如:
# l=[[set(1), set(2), set(3)]]
# l=[[set(1), set(2), set(3)], [set(1, 2), set(2, 3)]]
L.append(Lk)
k += 1
# print 'k=', k, len(L[k-2])
return L, supportData
- 计算可信度和频繁项集的规划
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
"""calcConf(对两个元素的频繁项,计算可信度,例如: {1,2}/{1} 或者 {1,2}/{2} 看是否满足条件)
Args:
freqSet 频繁项集中的元素,例如: frozenset([1, 3])
H 频繁项集中的元素的集合,例如: [frozenset([1]), frozenset([3])]
supportData 所有元素的支持度的字典
brl 关联规则列表的空数组
minConf 最小可信度
Returns:
prunedH 记录 可信度大于阈值的集合
"""
# 记录可信度大于最小可信度(minConf)的集合
prunedH = []
for conseq in H: # 假设 freqSet = frozenset([1, 3]), H = [frozenset([1]), frozenset([3])],那么现在需要求出 frozenset([1]) -> frozenset([3]) 的可信度和 frozenset([3]) -> frozenset([1]) 的可信度
# print 'confData=', freqSet, H, conseq, freqSet-conseq
conf = supportData[freqSet]/supportData[freqSet-conseq] # 支持度定义: a -> b = support(a | b) / support(a). 假设 freqSet = frozenset([1, 3]), conseq = [frozenset([1])],那么 frozenset([1]) 至 frozenset([3]) 的可信度为 = support(a | b) / support(a) = supportData[freqSet]/supportData[freqSet-conseq] = supportData[frozenset([1, 3])] / supportData[frozenset([1])]
if conf >= minConf:
# 只要买了 freqSet-conseq 集合,一定会买 conseq 集合(freqSet-conseq 集合和 conseq集合 是全集)
print(freqSet-conseq, '-->', conseq, 'conf:', conf)
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
"""rulesFromConseq
Args:
freqSet 频繁项集中的元素,例如: frozenset([2, 3, 5])
H 频繁项集中的元素的集合,例如: [frozenset([2]), frozenset([3]), frozenset([5])]
supportData 所有元素的支持度的字典
brl 关联规则列表的数组
minConf 最小可信度
"""
# H[0] 是 freqSet 的元素组合的第一个元素,并且 H 中所有元素的长度都一样,长度由 aprioriGen(H, m+1) 这里的 m + 1 来控制
# 该函数递归时,H[0] 的长度从 1 开始增长 1 2 3 ...
# 假设 freqSet = frozenset([2, 3, 5]), H = [frozenset([2]), frozenset([3]), frozenset([5])]
# 那么 m = len(H[0]) 的递归的值依次为 1 2
# 在 m = 2 时, 跳出该递归。假设再递归一次,那么 H[0] = frozenset([2, 3, 5]),freqSet = frozenset([2, 3, 5]) ,没必要再计算 freqSet 与 H[0] 的关联规则了。
m = len(H[0])
if (len(freqSet) > (m + 1)):
# print 'freqSet******************', len(freqSet), m + 1, freqSet, H, H[0]
# 生成 m+1 个长度的所有可能的 H 中的组合,假设 H = [frozenset([2]), frozenset([3]), frozenset([5])]
# 第一次递归调用时生成 [frozenset([2, 3]), frozenset([2, 5]), frozenset([3, 5])]
# 第二次 。。。没有第二次,递归条件判断时已经退出了
Hmp1 = aprioriGen(H, m+1)
# 返回可信度大于最小可信度的集合
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
print('Hmp1=', Hmp1)
print('len(Hmp1)=', len(Hmp1), 'len(freqSet)=', len(freqSet))
# 计算可信度后,还有数据大于最小可信度的话,那么继续递归调用,否则跳出递归
if (len(Hmp1) > 1):
# print '----------------------', Hmp1
# print len(freqSet), len(Hmp1[0]) + 1
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
- 生成需要的关联规则
def generateRules(L, supportData, minConf=0.7):
"""generateRules
Args:
L 频繁项集列表
supportData 频繁项集支持度的字典
minConf 最小置信度
Returns:
bigRuleList 可信度规则列表(关于 (A->B+置信度) 3个字段的组合)
"""
bigRuleList = []
# 假设 L = [[frozenset([1]), frozenset([3]), frozenset([2]), frozenset([5])], [frozenset([1, 3]), frozenset([2, 5]), frozenset([2, 3]), frozenset([3, 5])], [frozenset([2, 3, 5])]]
for i in range(1, len(L)):
# 获取频繁项集中每个组合的所有元素
for freqSet in L[i]:
# 假设: freqSet= frozenset([1, 3]), H1=[frozenset([1]), frozenset([3])]
# 组合总的元素并遍历子元素,并转化为 frozenset 集合,再存放到 list 列表中
H1 = [frozenset([item]) for item in freqSet]
# 2 个的组合,走 else, 2 个以上的组合,走 if
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
def getActionIds():
from time import sleep
from votesmart import votesmart
# votesmart.apikey = 'get your api key first'
votesmart.apikey = 'a7fa40adec6f4a77178799fae4441030'
actionIdList = []
billTitleList = []
fr = open('data/11.Apriori/recent20bills.txt')
for line in fr.readlines():
billNum = int(line.split('\t')[0])
try:
billDetail = votesmart.votes.getBill(billNum) # api call
for action in billDetail.actions:
if action.level == 'House' and (action.stage == 'Passage' or action.stage == 'Amendment Vote'):
actionId = int(action.actionId)
print('bill: %d has actionId: %d' % (billNum, actionId))
actionIdList.append(actionId)
billTitleList.append(line.strip().split('\t')[1])
except:
print("problem getting bill %d" % billNum)
sleep(1) # delay to be polite
return actionIdList, billTitleList
def getTransList(actionIdList, billTitleList): #this will return a list of lists containing ints
itemMeaning = ['Republican', 'Democratic']#list of what each item stands for
for billTitle in billTitleList:#fill up itemMeaning list
itemMeaning.append('%s -- Nay' % billTitle)
itemMeaning.append('%s -- Yea' % billTitle)
transDict = {}#list of items in each transaction (politician)
voteCount = 2
for actionId in actionIdList:
sleep(3)
print('getting votes for actionId: %d' % actionId)
try:
voteList = votesmart.votes.getBillActionVotes(actionId)
for vote in voteList:
if not transDict.has_key(vote.candidateName):
transDict[vote.candidateName] = []
if vote.officeParties == 'Democratic':
transDict[vote.candidateName].append(1)
elif vote.officeParties == 'Republican':
transDict[vote.candidateName].append(0)
if vote.action == 'Nay':
transDict[vote.candidateName].append(voteCount)
elif vote.action == 'Yea':
transDict[vote.candidateName].append(voteCount + 1)
except:
print("problem getting actionId: %d" % actionId)
voteCount += 2
return transDict, itemMeaning
分级法的思路, 频繁项集->关联规则
- 首先从一个频繁项集开始,接着创建一个规则列表,其中规则右部分只包含一个元素,然后对这个规则进行测试。
- 接下来合并所有剩余规则来创建一个新的规则列表,其中规则右部包含两个元素。
如下图:
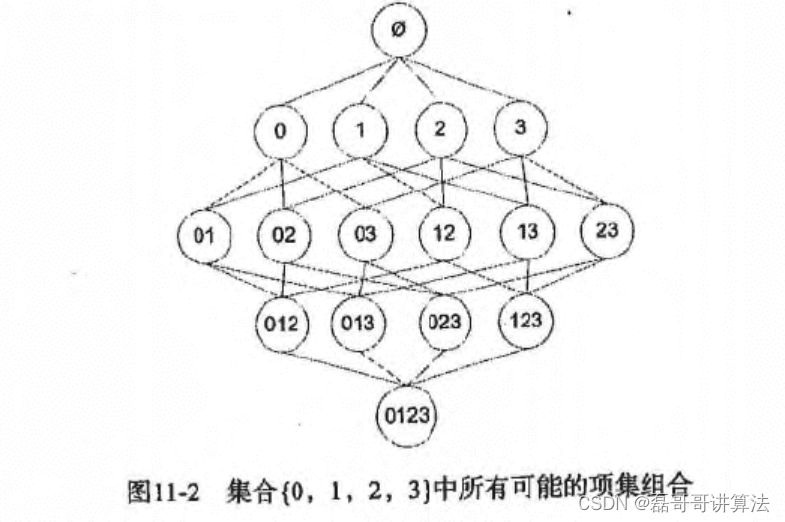
- 每次增加频繁项集的大小,Apriori 算法都会重新扫描整个数据集,是算法的问题也是改进的计划
FP-growth算法
使用FP-growth算法来高效发现频繁项集
- 一种非常好的发现频繁项集算法。
- 基于Apriori算法构建,但是数据结构不同,使用叫做 FP树 的数据结构结构来存储集合。下面我们会介绍这种数据结构。
- 基于数据构建FP树
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue # 节点名称
self.count = numOccur # 节点出现次数
self.nodeLink = None # 不同项集的相同项通过nodeLink连接在一起
# needs to be updated
self.parent = parentNode # 指向父节点
self.children = {} # 存储叶子节点
-
遍历所有的数据集合,计算所有项的支持度。
-
丢弃非频繁的项。
-
基于 支持度 降序排序所有的项。
-
所有数据集合按照得到的顺序重新整理。
-
重新整理完成后,丢弃每个集合末尾非频繁的项。
-
读取每个集合插入FP树中,同时用一个头部链表数据结构维护不同集合的相同项。
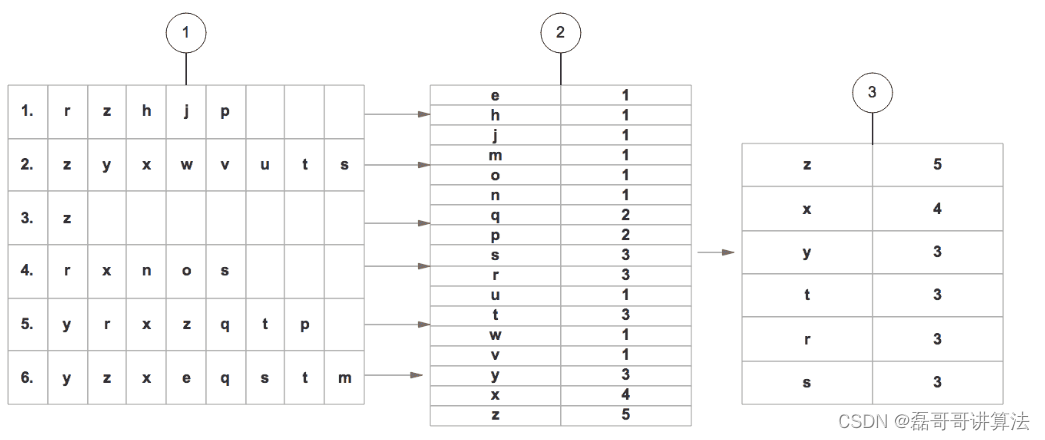
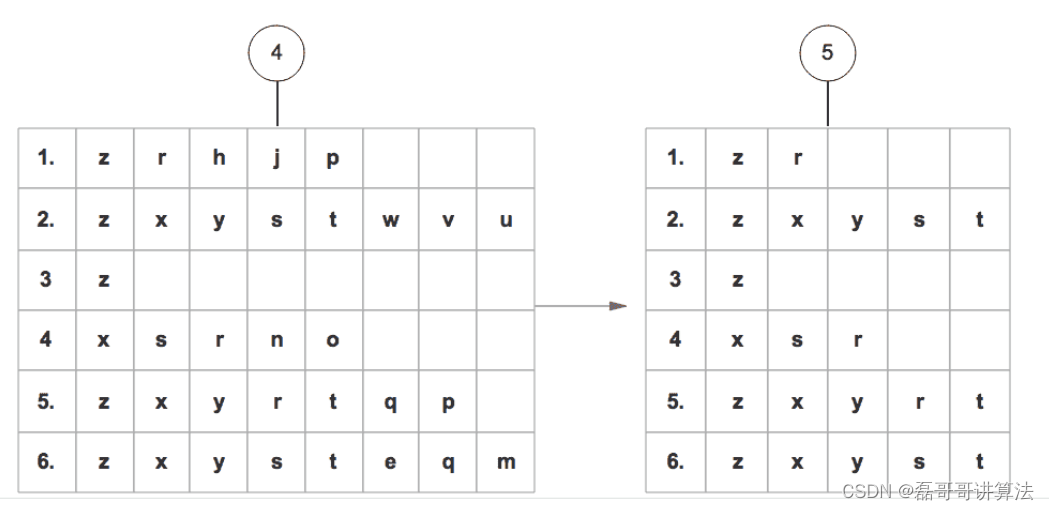
从FP树中挖掘出频繁项集重组 -
对头部链表进行降序排序
-
对头部链表节点从小到大遍历,得到条件模式基,同时获得一个频繁项集。
-
可以理解为huffman编码构树然后用链表重连dijstra图
-
条件模式基:头部链表中的某一点的前缀路径组合就是条件模式基,条件模式基的值取决于末尾节点的值。
条件FP树:以条件模式基为数据集构造的FP树叫做条件FP树。
FP-growth算法优缺点
* 优点: 1. 因为 FP-growth 算法只需要对数据集遍历两次,所以速度更快。
2. FP树将集合按照支持度降序排序,不同路径如果有相同前缀路径共用存储空间,使得数据得到了压缩。
3. 不需要生成候选集。
4. 比Apriori更快。
* 缺点: 1. FP-Tree第二次遍历会存储很多中间过程的值,会占用很多内存。
2. 构建FP-Tree是比较昂贵的。
* 适用数据类型: 标称型数据(离散型数据)。
FPG代码实现
算法代码实现如下:
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue
self.count = numOccur
self.nodeLink = None
# needs to be updated
self.parent = parentNode
self.children = {}
def inc(self, numOccur):
"""inc(对count变量增加给定值)
"""
self.count += numOccur
def disp(self, ind=1):
"""disp(用于将树以文本形式显示)
"""
print(' '*ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind+1)
def loadSimpDat():
simpDat = [['r', 'z', 'h', 'j', 'p'],
['z', 'y', 'x', 'w', 'v', 'u', 't', 's'],
['z'],
['r', 'x', 'n', 'o', 's'],
# ['r', 'x', 'n', 'o', 's'],
['y', 'r', 'x', 'z', 'q', 't', 'p'],
['y', 'z', 'x', 'e', 'q', 's', 't', 'm']]
return simpDat
def createInitSet(dataSet):
retDict = {}
for trans in dataSet:
if frozenset(trans) not in retDict.keys():
retDict[frozenset(trans)] = 1
else:
retDict[frozenset(trans)] += 1
return retDict
# this version does not use recursion
def updateHeader(nodeToTest, targetNode):
"""updateHeader(更新头指针,建立相同元素之间的关系,例如: 左边的r指向右边的r值,就是后出现的相同元素 指向 已经出现的元素)
从头指针的nodeLink开始,一直沿着nodeLink直到到达链表末尾。这就是链表。
性能: 如果链表很长可能会遇到迭代调用的次数限制。
Args:
nodeToTest 满足minSup {所有的元素+(value, treeNode)}
targetNode Tree对象的子节点
"""
# 建立相同元素之间的关系,例如: 左边的r指向右边的r值
while (nodeToTest.nodeLink is not None):
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
def updateTree(items, inTree, headerTable, count):
"""updateTree(更新FP-tree,第二次遍历)
# 针对每一行的数据
# 最大的key, 添加
Args:
items 满足minSup 排序后的元素key的数组(大到小的排序)
inTree 空的Tree对象
headerTable 满足minSup {所有的元素+(value, treeNode)}
count 原数据集中每一组Kay出现的次数
"""
# 取出 元素 出现次数最高的
# 如果该元素在 inTree.children 这个字典中,就进行累加
# 如果该元素不存在 就 inTree.children 字典中新增key,value为初始化的 treeNode 对象
if items[0] in inTree.children:
# 更新 最大元素,对应的 treeNode 对象的count进行叠加
inTree.children[items[0]].inc(count)
else:
# 如果不存在子节点,我们为该inTree添加子节点
inTree.children[items[0]] = treeNode(items[0], count, inTree)
# 如果满足minSup的dist字典的value值第二位为null, 我们就设置该元素为 本节点对应的tree节点
# 如果元素第二位不为null,我们就更新header节点
if headerTable[items[0]][1] is None:
# headerTable只记录第一次节点出现的位置
headerTable[items[0]][1] = inTree.children[items[0]]
else:
# 本质上是修改headerTable的key对应的Tree,的nodeLink值
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1:
# 递归的调用,在items[0]的基础上,添加item0[1]做子节点, count只要循环的进行累计加和而已,统计出节点的最后的统计值。
updateTree(items[1:], inTree.children[items[0]], headerTable, count)
def createTree(dataSet, minSup=1):
"""createTree(生成FP-tree)
Args:
dataSet dist{行: 出现次数}的样本数据
minSup 最小的支持度
Returns:
retTree FP-tree
headerTable 满足minSup {所有的元素+(value, treeNode)}
"""
# 支持度>=minSup的dist{所有元素: 出现的次数}
headerTable = {}
# 循环 dist{行: 出现次数}的样本数据
for trans in dataSet:
# 对所有的行进行循环,得到行里面的所有元素
# 统计每一行中,每个元素出现的总次数
for item in trans:
# 例如: {'ababa': 3} count(a)=3+3+3=9 count(b)=3+3=6
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
# 删除 headerTable中,元素次数<最小支持度的元素
for k in list(headerTable.keys()): # python3中.keys()返回的是迭代器不是list,不能在遍历时对其改变。
if headerTable[k] < minSup:
del(headerTable[k])
# 满足minSup: set(各元素集合)
freqItemSet = set(headerTable.keys())
# 如果不存在,直接返回None
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
# 格式化: dist{元素key: [元素次数, None]}
headerTable[k] = [headerTable[k], None]
# create tree
retTree = treeNode('Null Set', 1, None)
# 循环 dist{行: 出现次数}的样本数据
for tranSet, count in dataSet.items():
# print('tranSet, count=', tranSet, count)
# localD = dist{元素key: 元素总出现次数}
localD = {}
for item in tranSet:
# 判断是否在满足minSup的集合中
if item in freqItemSet:
# print('headerTable[item][0]=', headerTable[item][0], headerTable[item])
localD[item] = headerTable[item][0]
# print('localD=', localD)
# 对每一行的key 进行排序,然后开始往树添加枝丫,直到丰满
# 第二次,如果在同一个排名下出现,那么就对该枝丫的值进行追加,继续递归调用!
if len(localD) > 0:
# p=key,value; 所以是通过value值的大小,进行从大到小进行排序
# orderedItems 表示取出元组的key值,也就是字母本身,但是字母本身是大到小的顺序
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)]
# print 'orderedItems=', orderedItems, 'headerTable', headerTable, '\n\n\n'
# 填充树,通过有序的orderedItems的第一位,进行顺序填充 第一层的子节点。
updateTree(orderedItems, retTree, headerTable, count)
return retTree, headerTable
def ascendTree(leafNode, prefixPath):
"""ascendTree(如果存在父节点,就记录当前节点的name值)
Args:
leafNode 查询的节点对于的nodeTree
prefixPath 要查询的节点值
"""
if leafNode.parent is not None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath)
def findPrefixPath(basePat, treeNode):
"""findPrefixPath 基础数据集
Args:
basePat 要查询的节点值
treeNode 查询的节点所在的当前nodeTree
Returns:
condPats 对非basePat的倒叙值作为key,赋值为count数
"""
condPats = {}
# 对 treeNode的link进行循环
while treeNode is not None:
prefixPath = []
# 寻找改节点的父节点,相当于找到了该节点的频繁项集
ascendTree(treeNode, prefixPath)
# 排除自身这个元素,判断是否存在父元素(所以要>1, 说明存在父元素)
if len(prefixPath) > 1:
# 对非basePat的倒叙值作为key,赋值为count数
# prefixPath[1:] 变frozenset后,字母就变无序了
# condPats[frozenset(prefixPath)] = treeNode.count
condPats[frozenset(prefixPath[1:])] = treeNode.count
# 递归,寻找改节点的下一个 相同值的链接节点
treeNode = treeNode.nodeLink
# print(treeNode)
return condPats
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
"""mineTree(创建条件FP树)
Args:
inTree myFPtree
headerTable 满足minSup {所有的元素+(value, treeNode)}
minSup 最小支持项集
preFix preFix为newFreqSet上一次的存储记录,一旦没有myHead,就不会更新
freqItemList 用来存储频繁子项的列表
"""
# 通过value进行从小到大的排序, 得到频繁项集的key
# 最小支持项集的key的list集合
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1][0])]
print('-----', sorted(headerTable.items(), key=lambda p: p[1][0]))
print('bigL=', bigL)
# 循环遍历 最频繁项集的key,从小到大的递归寻找对应的频繁项集
for basePat in bigL:
# preFix为newFreqSet上一次的存储记录,一旦没有myHead,就不会更新
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
print('newFreqSet=', newFreqSet, preFix)
freqItemList.append(newFreqSet)
print('freqItemList=', freqItemList)
condPattBases = findPrefixPath(basePat, headerTable[basePat][1])
print('condPattBases=', basePat, condPattBases)
# 构建FP-tree
myCondTree, myHead = createTree(condPattBases, minSup)
print('myHead=', myHead)
# 挖掘条件 FP-tree, 如果myHead不为空,表示满足minSup {所有的元素+(value, treeNode)}
if myHead is not None:
myCondTree.disp(1)
print('\n\n\n')
# 递归 myHead 找出频繁项集
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
print('\n\n\n')
数据集预处理压缩
PCA 主成分简化数据
PCA主要于模式识别的课程上学习的
特征向量压缩,抓取关键点,也就是降维技术的应用,在面对大规模特征下的解决方案
- 使得数据集更容易使用
- 降低很多算法的计算开销
- 去除噪音
- 使得结果易懂
数据预处理的三种操作
- 主成分分析(Principal Component Analysis, PCA)
- 通俗理解: 就是找出一个最主要的特征,然后进行分析。
- 例如: 考察一个人的智力情况,就直接看数学成绩就行(存在: 数学、语文、英语成绩)
- 因子分析(Factor Analysis)
- 通俗理解: 将多个实测变量转换为少数几个综合指标。它反映一种降维的思想,通过降维将相关性高的变量聚在一起,从而减少需要分析的变量的数量,而减少问题分析的复杂性
- 例如: 考察一个人的整体情况,就直接组合3样成绩(隐变量),看平均成绩就行(存在: 数学、语文、英语成绩)
- 应用的领域: 社会科学、金融和其他领域在因子分析中,我们
假设观察数据的成分中有一些观察不到的隐变量(latent variable)。
假设观察数据是这些隐变量和某些噪音的线性组合。
那么隐变量的数据可能比观察数据的数目少,也就说通过找到隐变量就可以实现数据的降维。
- 独立成分分析(Independ Component Analysis, ICA)
- 通俗理解: ICA 认为观测信号是若干个独立信号的线性组合,ICA 要做的是一个解混过程。
- 例如: 我们去ktv唱歌,想辨别唱的是什么歌曲?ICA 是观察发现是原唱唱的一首歌【2个独立的声音(原唱/主唱)】。
ICA 是假设数据是从 N 个数据源混合组成的,这一点和因子分析有些类似,这些数据源之间在统计上是相互独立的,而在 PCA 中只假设数据是不相关(线性关系)的。 - 同因子分析一样,如果数据源的数目少于观察数据的数目,则可以实现降维过程。
压缩原理
- 找出第一个主成分的方向,也就是数据 方差最大 的方向。
- 找出第二个主成分的方向,也就是数据 方差次大 的方向,并且该方向与第一个主成分方向 正交(orthogonal 如果是二维空间就叫垂直)。
- 通过这种方式计算出所有的主成分方向。
- 通过数据集的协方差矩阵及其特征值分析,我们就可以得到这些主成分的值。
- 一旦得到了协方差矩阵的特征值和特征向量,我们就可以保留最大的 N 个特征。这些特征向量也给出了 N 个最重要特征的真实结构,我们就可以通过将数据乘上这 N 个特征向量 从而将它转换到新的空间上。
代码实现
将特征压缩汇总后用混淆矩阵呈现
def loadDataSet(fileName, delim='\t'):
fr = open(fileName)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [list(map(float, line)) for line in stringArr]
#注意这里和python2的区别,需要在map函数外加一个list(),否则显示结果为 map at 0x3fed1d0
return mat(datArr)
def pca(dataMat, topNfeat=9999999):
"""pca
Args:
dataMat 原数据集矩阵
topNfeat 应用的N个特征
Returns:
lowDDataMat 降维后数据集
reconMat 新的数据集空间
"""
# 计算每一列的均值
meanVals = mean(dataMat, axis=0)
# print('meanVals', meanVals)
# 每个向量同时都减去 均值
meanRemoved = dataMat - meanVals
# print('meanRemoved=', meanRemoved)
# cov协方差=[(x1-x均值)*(y1-y均值)+(x2-x均值)*(y2-y均值)+...+(xn-x均值)*(yn-y均值)+]/(n-1)
'''
方差: (一维)度量两个随机变量关系的统计量
协方差: (二维)度量各个维度偏离其均值的程度
协方差矩阵: (多维)度量各个维度偏离其均值的程度
当 cov(X, Y)>0时,表明X与Y正相关;(X越大,Y也越大;X越小Y,也越小。这种情况,我们称为“正相关”。)
当 cov(X, Y)<0时,表明X与Y负相关;
当 cov(X, Y)=0时,表明X与Y不相关。
'''
covMat = cov(meanRemoved, rowvar=0)
# eigVals为特征值, eigVects为特征向量
eigVals, eigVects = linalg.eig(mat(covMat))
# print('eigVals=', eigVals)
# print('eigVects=', eigVects)
# 对特征值,进行从小到大的排序,返回从小到大的index序号
# 特征值的逆序就可以得到topNfeat个最大的特征向量
'''
>>> x = np.array([3, 1, 2])
>>> np.argsort(x)
array([1, 2, 0]) # index,1 = 1; index,2 = 2; index,0 = 3
>>> y = np.argsort(x)
>>> y[::-1]
array([0, 2, 1])
>>> y[:-3:-1]
array([0, 2]) # 取出 -1, -2
>>> y[:-6:-1]
array([0, 2, 1])
'''
eigValInd = argsort(eigVals)
# print('eigValInd1=', eigValInd)
# -1表示倒序,返回topN的特征值[-1 到 -(topNfeat+1) 但是不包括-(topNfeat+1)本身的倒叙]
eigValInd = eigValInd[:-(topNfeat+1):-1]
# print('eigValInd2=', eigValInd)
# 重组 eigVects 最大到最小
redEigVects = eigVects[:, eigValInd]
# print('redEigVects=', redEigVects.T)
# 将数据转换到新空间
# print( "---", shape(meanRemoved), shape(redEigVects))
lowDDataMat = meanRemoved * redEigVects
reconMat = (lowDDataMat * redEigVects.T) + meanVals
# print('lowDDataMat=', lowDDataMat)
# print('reconMat=', reconMat)
return lowDDataMat, reconMat
def replaceNanWithMean():
datMat = loadDataSet('data/13.PCA/secom.data', ' ')
numFeat = shape(datMat)[1]
for i in range(numFeat):
# 对value不为NaN的求均值
# .A 返回矩阵基于的数组
meanVal = mean(datMat[nonzero(~isnan(datMat[:, i].A))[0], i])
# 将value为NaN的值赋值为均值
datMat[nonzero(isnan(datMat[:, i].A))[0],i] = meanVal
return datMat
def show_picture(dataMat, reconMat):
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(dataMat[:, 0].flatten().A[0], dataMat[:, 1].flatten().A[0], marker='^', s=90)
ax.scatter(reconMat[:, 0].flatten().A[0], reconMat[:, 1].flatten().A[0], marker='o', s=50, c='red')
plt.show()
SVD简化数据
SVD繁琐的公式证明在矩阵论里详细讲过,SVD对图像的应用在之前的博客也显示了对于璇姐的图像处理。
利用 SVD 从数据中构建一个主题空间。再在该空间下计算其相似度。(从高维-低维空间的转化,在低维空间来计算相似度,SVD 提升了推荐系统的效率。)
例如菜馆菜肴推荐
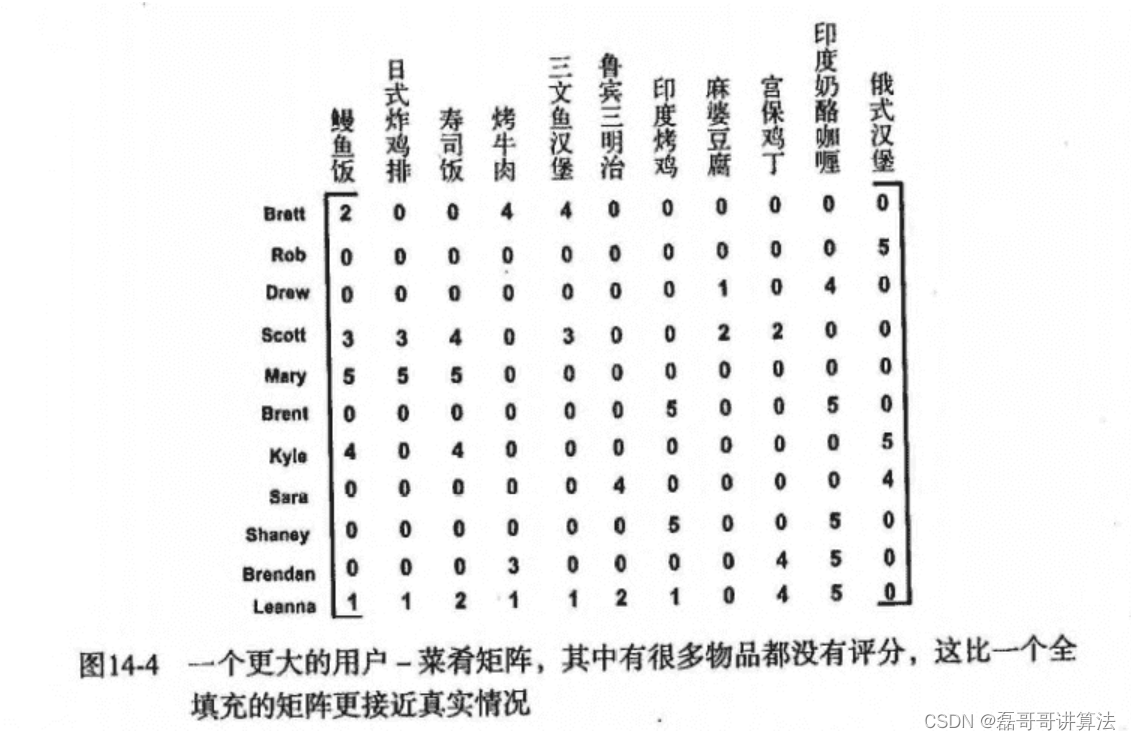
实现代码加注释
def loadExData3():
# 利用SVD提高推荐效果,菜肴矩阵
# 可以修改原数据集合,用对对比
# return[[2, 0, 0, 4, 4, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5],
# [0, 0, 0, 0, 0, 0, 0, 1, 0, 4, 0],
# [3, 3, 4, 0, 3, 0, 0, 2, 2, 0, 0],
# [5, 5, 5, 0, 0, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0, 0, 5, 0, 0, 5, 0],
# [4, 0, 4, 0, 0, 0, 0, 0, 0, 0, 5],
# [0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 4],
# [0, 0, 0, 0, 0, 0, 5, 0, 0, 5, 0],
# [0, 0, 0, 3, 0, 0, 0, 0, 4, 5, 0],
# [1, 1, 2, 1, 1, 2, 1, 0, 4, 5, 0]]
# 修改后的数据(增加了第1道菜和最后1到菜,同时有3个人吃,从而计算基于物品的协同过滤效果,原来才一个人)
return[[2, 0, 0, 4, 4, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5],
[0, 0, 0, 0, 0, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 3, 0, 0, 2, 2, 0, 8],
[5, 5, 5, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 5, 0, 0, 5, 0],
[4, 0, 4, 0, 0, 0, 0, 0, 0, 0, 5],
[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 0, 0, 0, 5, 0, 0, 5, 0],
[0, 0, 0, 3, 0, 0, 0, 0, 4, 5, 0],
[1, 1, 2, 1, 1, 2, 1, 0, 4, 5, 6]]
def loadExData2():
# 书上代码给的示例矩阵
return[[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
def loadExData():
"""
# 推荐引擎示例矩阵
return[[4, 4, 0, 2, 2],
[4, 0, 0, 3, 3],
[4, 0, 0, 1, 1],
[1, 1, 1, 2, 0],
[2, 2, 2, 0, 0],
[1, 1, 1, 0, 0],
[5, 5, 5, 0, 0]]
"""
# # 原矩阵
# return[[1, 1, 1, 0, 0],
# [2, 2, 2, 0, 0],
# [1, 1, 1, 0, 0],
# [5, 5, 5, 0, 0],
# [1, 1, 0, 2, 2],
# [0, 0, 0, 3, 3],
# [0, 0, 0, 1, 1]]
# 原矩阵
return[[0, -1.6, 0.6],
[0, 1.2, 0.8],
[0, 0, 0],
[0, 0, 0]]
# 相似度计算,假定inA和inB 都是列向量
# 基于欧氏距离
def ecludSim(inA, inB):
return 1.0/(1.0 + la.norm(inA - inB))
# pearsSim()函数会检查是否存在3个或更多的点。
# corrcoef直接计算皮尔逊相关系数,范围[-1, 1],归一化后[0, 1]
def pearsSim(inA, inB):
# 如果不存在,该函数返回1.0,此时两个向量完全相关。
if len(inA) < 3:
return 1.0
return 0.5 + 0.5 * corrcoef(inA, inB, rowvar=0)[0][1]
# 计算余弦相似度,如果夹角为90度,相似度为0;如果两个向量的方向相同,相似度为1.0
def cosSim(inA, inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)
return 0.5 + 0.5*(num/denom)
# 基于物品相似度的推荐引擎
def standEst(dataMat, user, simMeas, item):
"""standEst(计算某用户未评分物品中,以对该物品和其他物品评分的用户的物品相似度,然后进行综合评分)
Args:
dataMat 训练数据集
user 用户编号
simMeas 相似度计算方法
item 未评分的物品编号
Returns:
ratSimTotal/simTotal 评分(0~5之间的值)
"""
# 得到数据集中的物品数目
n = shape(dataMat)[1]
# 初始化两个评分值
simTotal = 0.0
ratSimTotal = 0.0
# 遍历行中的每个物品(对用户评过分的物品进行遍历,并将它与其他物品进行比较)
for j in range(n):
userRating = dataMat[user, j]
# 如果某个物品的评分值为0,则跳过这个物品
if userRating == 0:
continue
# 寻找两个用户都评级的物品
# 变量 overLap 给出的是两个物品当中已经被评分的那个元素的索引ID
# logical_and 计算x1和x2元素的为True就为True(也就是列的值同时>0), 否则就为False
# item(0): [[ True] [False] [False] [ True] [ True] [False] [ True] [False] [False] [False] [ True]]
# j(10): [[False] [ True] [False] [False] [False] [False] [ True] [ True] [False] [False] [False]]
# +1-- [[False] [False] [False] [False] [False] [False] [ True] [False] [False] [False] [False]]
# +2-- [6]
# print("+++ item(%s): %s --- j(%s): %s" % (item, dataMat[:, item].A > 0, j, dataMat[:, j].A > 0))
# print("+1-- %s" % logical_and(dataMat[:, item].A > 0, dataMat[:, j].A > 0) )
# print("+2-- %s" % overLap)
overLap = nonzero(logical_and(dataMat[:, item].A > 0, dataMat[:, j].A > 0))[0]
# 如果相似度为0,则两着没有任何重合元素,终止本次循环
if len(overLap) == 0:
similarity = 0
# 如果存在重合的物品,则基于这些重合物重新计算相似度。
else:
# print("-%s- %s:%s -- %s:%s" % (overLap, item, dataMat[overLap, item], j, dataMat[overLap, j]) )
# 如果 overLap 长度是为3,说明3个人同时吃了 菜A并且也同时吃了菜B
# 那么就要找对 这3个人对应 菜评分的矩阵
# -[ 3 6 10](人)- 0(菜):[[3] [4] [1]] -- 10(菜):[[8] [5] [6]]
# 然后就可以计算出来两个菜之间的相似度
similarity = simMeas(dataMat[overLap, item], dataMat[overLap, j])
print('the %d and %d similarity is : %f' % (item, j, similarity))
# 相似度会不断累加,每次计算时还考虑相似度和当前用户评分的乘积
# similarity 用户相似度, userRating 用户评分
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0:
return 0
# 通过除以所有的评分总和,对上述相似度评分的乘积进行归一化,使得最后评分在0~5之间,这些评分用来对预测值进行排序
else:
return ratSimTotal/simTotal
# 基于SVD的评分估计
# 在recommend() 中,这个函数用于替换对standEst()的调用,该函数对给定用户给定物品构建了一个评分估计值
def svdEst(dataMat, user, simMeas, item):
"""svdEst( )
Args:
dataMat 训练数据集
user 用户编号
simMeas 相似度计算方法
item 未评分的物品编号
Returns:
ratSimTotal/simTotal 评分(0~5之间的值)
"""
# 物品数目
n = shape(dataMat)[1]
# 对数据集进行SVD分解
simTotal = 0.0
ratSimTotal = 0.0
# 奇异值分解
# 在SVD分解之后,我们只利用包含了90%能量值的奇异值,这些奇异值会以NumPy数组的形式得以保存
U, Sigma, VT = la.svd(dataMat)
# # 分析 Sigma 的长度取值
# analyse_data(Sigma, 20)
# 如果要进行矩阵运算,就必须要用这些奇异值构建出一个对角矩阵
Sig4 = mat(eye(4) * Sigma[: 4])
# 利用U矩阵将物品转换到低维空间中,构建转换后的物品(物品+4个主要的“隐形”特征)
# 公式1(目的是: 降维-改变形状,也改变大小) xformedItems = dataMat.T * U[:, :4] * Sig4.I
# 公式2(目的是: 压缩-不改变形状,改变大小) reconMat = U[:, :4] * Sig4.I * VT[:4, :]
# 其中: imgCompress() 是详细的案例
# 最近看到一篇文章描述,感觉挺有道理的,我就顺便补充一下注释: https://blog.csdn.net/qq_36523839/article/details/82347332
xformedItems = dataMat.T * U[:, :4] * Sig4.I
# print('dataMat', shape(dataMat))
# print('U[:, :4]', shape(U[:, :4]))
# print('Sig4.I', shape(Sig4.I))
# print('VT[:4, :]', shape(VT[:4, :]))
# print('xformedItems', shape(xformedItems))
# 对于给定的用户,for循环在用户对应行的元素上进行遍历
# 这和standEst()函数中的for循环的目的一样,只不过这里的相似度计算时在低维空间下进行的。
for j in range(n):
userRating = dataMat[user, j]
if userRating == 0 or j == item:
continue
# 相似度的计算方法也会作为一个参数传递给该函数
similarity = simMeas(xformedItems[item, :].T, xformedItems[j, :].T)
# for 循环中加入了一条print语句,以便了解相似度计算的进展情况。如果觉得累赘,可以去掉
print('the %d and %d similarity is: %f' % (item, j, similarity))
# 对相似度不断累加求和
simTotal += similarity
# 对相似度及对应评分值的乘积求和
ratSimTotal += similarity * userRating
if simTotal == 0:
return 0
else:
# 计算估计评分
return ratSimTotal/simTotal
# recommend()函数,就是推荐引擎,它默认调用standEst()函数,产生了最高的N个推荐结果。
# 如果不指定N的大小,则默认值为3。该函数另外的参数还包括相似度计算方法和估计方法
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
"""svdEst( )
Args:
dataMat 训练数据集
user 用户编号
simMeas 相似度计算方法
estMethod 使用的推荐算法
Returns:
返回最终 N 个推荐结果
"""
# 寻找未评级的物品
# nonzero(a)函数一般返回两行array()。如果mat()一下,就是个2*N 的矩阵
# 其中 (array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0]),
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]))
# 例如: 上下取出来的数据(0, 0) 表示在矩阵的横纵坐标(行、列)的位置
# 由于是2为矩阵,所以 [1] 就是矩阵列,也就是商品ID的为主
# 对给定的用户建立一个未评分的物品列表
unratedItems = nonzero(dataMat[user, :].A == 0)[1]
# 如果不存在未评分物品,那么就退出函数
if len(unratedItems) == 0:
return 'you rated everything'
# 物品的编号和评分值
itemScores = []
# 在未评分物品上进行循环
for item in unratedItems:
# 获取 item 该物品的评分
estimatedScore = estMethod(dataMat, user, simMeas, item)
itemScores.append((item, estimatedScore))
# 按照评分得分 进行逆排序,获取前N个未评级物品进行推荐
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[: N]
def analyse_data(Sigma, loopNum=20):
"""analyse_data(分析 Sigma 的长度取值)
Args:
Sigma Sigma的值
loopNum 循环次数
"""
# 总方差的集合(总能量值)
Sig2 = Sigma**2
SigmaSum = sum(Sig2)
for i in range(loopNum):
SigmaI = sum(Sig2[:i+1])
'''
根据自己的业务情况,就行处理,设置对应的 Singma 次数
通常保留矩阵 80% ~ 90% 的能量,就可以得到重要的特征并取出噪声。
'''
print('主成分: %s, 方差占比: %s%%' % (format(i+1, '2.0f'), format(SigmaI/SigmaSum*100, '4.2f')))
# 图像压缩函数
# 加载并转换数据
def imgLoadData(filename):
myl = []
# 打开文本文件,并从文件以数组方式读入字符
for line in open(filename).readlines():
newRow = []
for i in range(32):
newRow.append(int(line[i]))
myl.append(newRow)
# 矩阵调入后,就可以在屏幕上输出该矩阵
myMat = mat(myl)
return myMat
图像压缩再回归
降低了图像的清晰度,但是大幅度降低内存。
# 打印矩阵
def printMat(inMat, thresh=0.8):
# 由于矩阵保护了浮点数,因此定义浅色和深色,遍历所有矩阵元素,当元素大于阀值时打印1,否则打印0
for i in range(32):
for k in range(32):
if float(inMat[i, k]) > thresh:
print(1,)
else:
print(0,)
print('')
# 实现图像压缩,允许基于任意给定的奇异值数目来重构图像
def imgCompress(numSV=3, thresh=0.8):
"""imgCompress( )
Args:
numSV Sigma长度
thresh 判断的阈值
"""
# 构建一个列表
myMat = imgLoadData('data/14.SVD/0_5.txt')
print("****original matrix****")
# 对原始图像进行SVD分解并重构图像e
printMat(myMat, thresh)
# 通过Sigma 重新构成SigRecom来实现
# Sigma是一个对角矩阵,因此需要建立一个全0矩阵,然后将前面的那些奇异值填充到对角线上。
U, Sigma, VT = la.svd(myMat)
# SigRecon = mat(zeros((numSV, numSV)))
# for k in range(numSV):
# SigRecon[k, k] = Sigma[k]
# 分析插入的 Sigma 长度
analyse_data(Sigma, 20)
SigRecon = mat(eye(numSV) * Sigma[: numSV])
reconMat = U[:, :numSV] * SigRecon * VT[:numSV, :]
print("****reconstructed matrix using %d singular values *****" % numSV)
printMat(reconMat, thresh)
推荐算法
随着互联网的快速发展,用户很难快速从海量信息中寻找到自己感兴趣的信息。因此诞生了: 搜索引擎+推荐系统
主流推荐方法如下:
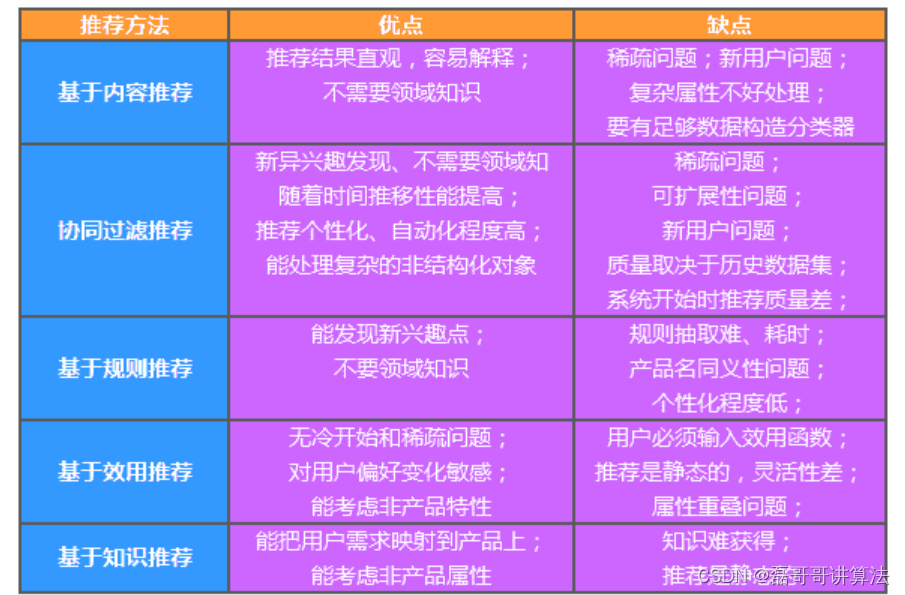
基于知识的推荐(Knowledge-based Recommendation)在某种程度是可以看成是一种推理(Inference)技术,它不是建立在用户需要和偏好基础上推荐的。基于知识的方法因它们所用的功能知识不同而有明显区别。效用知识(Functional Knowledge)是一种关于一个项目如何满足某一特定用户的知识,因此能解释需要和推荐的关系,所以用户资料可以是任何能支持推理的知识结构,它可以是用户已经规范化的查询,也可以是一个更详细的用户需要的表示。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











