







逻辑回归理论
假设现在有一些数据点,我们用一条直线对这些点进行拟合(这条直线称为最佳拟合直线),这个拟合的过程就叫做回归。
可以理解为高中所学习到的最小二乘法确定解y=kx+b,将其拓展就变成了矩阵论中的最小二乘解
预测出结果01用阶跃函数sigmoid进行计算和划分
封装执行的logregres.py用来进行简单模板介绍,在之后的项目实操中,再更新对应的代码
导入的库
from __future__ import print_function
from numpy import *
import matplotlib.pyplot as plt
import numpy as np
框架函数
函数sigmoid
def sigmoid(inX):
return 1.0 / (1 + exp(-inX))
# 适用算法改进测马病
# Tanh是Sigmoid的变形,与 sigmoid 不同的是,tanh 是0均值的。因此,实际应用中,tanh 会比 sigmoid 更好。
return 2 * 1.0/(1+np.exp(-2*inX)) - 1
loadDataset函数与数据整理优化函数
主要功能是打开文本读取数据,前两个值是x1和x2,第三个值是数据对应的类别标签
def plotBestFit(dataArr, labelMat, weights):
'''
Desc:
将我们得到的数据可视化展示出来
Args:
dataArr:样本数据的特征
labelMat:样本数据的类别标签,即目标变量
weights:回归系数
Returns:
None
'''
def loadDataSet():
dataMat=[]
labelMat=[]
fr=open('testSet.txt')
for line in fr.readlines():
lineArr=line.strip().split()
dataMat.append([1.0,float(lineArr[0]),float(lineArr[1])])
return dataMat,labelMat
最优化理论
基于最优化方法的回归系数
得感谢讲最优化方法的游老师,没想到在这里把之前上课的内容串联起来了
梯度上升法
要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为 ▽ ,则函数 f(x, y) 的梯度由下式表示:
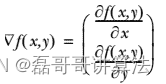
直线搜索and下面会对算法进行优化使用了牛顿和最速下降的方法,需要概念解释的话可以看一下本人上传的最优化笔记csdn包,有详细推理笔记和pdf原文还有习题。
结合矩阵论中的偏导和方向下降方向导数一起理解
梯度上升算法沿梯度方向移动了一步。可以看到,梯度算子总是指向函数值增长最快的方向。这里所说的是移动方向,而未提到移动量的大小。该量值称为步长,记作 α 。用向量来表示的话,梯度上升算法的迭代公式如下:
梯度上升迭代公式

回归原理
每个回归系数初始化为 1
重复 R 次:
计算整个数据集的梯度
使用 步长 x 梯度 更新回归系数的向量
返回回归系数
将上文的测试代码执行绘图结果
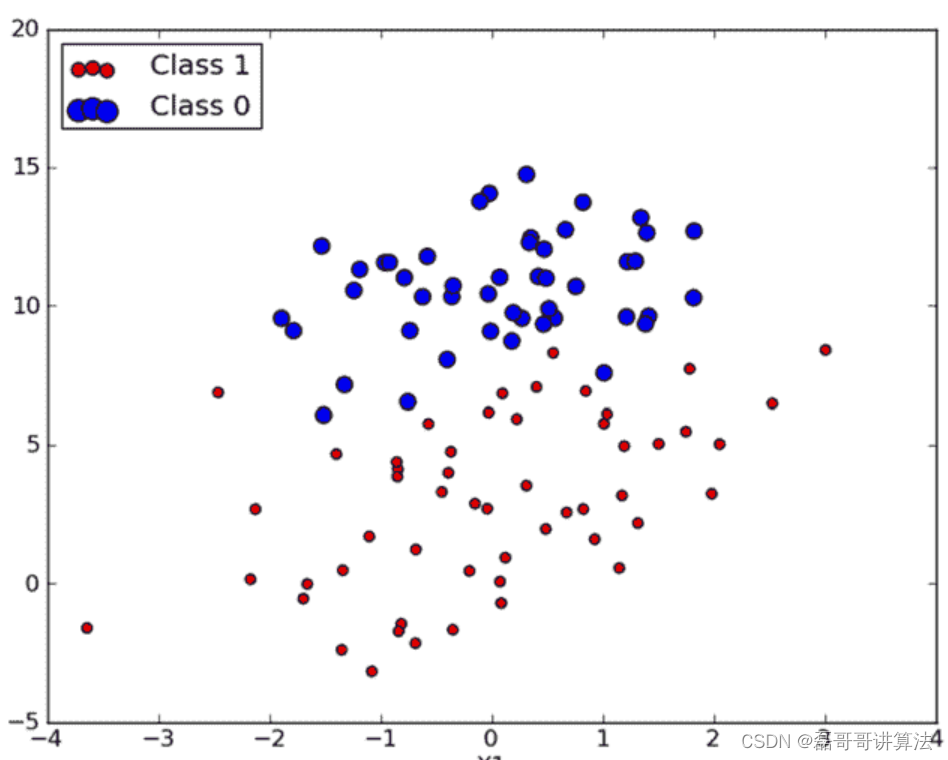
准备数据: 由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳
# 解析数据
def loadDataSet(file_name):
'''
Desc:
加载并解析数据
Args:
file_name -- 要解析的文件路径
Returns:
dataMat -- 原始数据的特征
labelMat -- 原始数据的标签,也就是每条样本对应的类别。即目标向量
'''
# dataMat为原始数据, labelMat为原始数据的标签
dataMat = []
labelMat = []
fr = open(file_name)
for line in fr.readlines():
lineArr = line.strip().split()
# 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
定义Logistic回归梯度上升优化算法
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) # 转换为 NumPy 矩阵
# 转化为矩阵[[0,1,0,1,0,1.....]],并转制[[0],[1],[0].....]
# 将行向量转化为列向量 => 矩阵的转置
labelMat = mat(classLabels).transpose() # 首先将数组转换为 NumPy 矩阵,然后再将行向量转置为列向量
m,n = shape(dataMatrix)
alpha = 0.001
# 迭代次数
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights) # 矩阵乘法
error = (labelMat - h) # 向量相减
# 0.001* (3*m)*(m*1) 表示在每一个列上的一个误差情况,最后得出 x1,x2,xn的系数的偏移量
weights = weights + alpha * dataMatrix.transpose() * error # 矩阵乘法,最后得到回归系数
return array(weights)
绘图数据集合Logistic回归最佳拟合直线
def plotbestfit(wei):
'''
Desc:
将我们得到的数据可视化展示出来
Args:
dataArr:样本数据的特征
labelMat:样本数据的类别标签,即目标变量
weights:回归系数
Returns:
None
'''
weights=wei.getA()
dataMat,labelMat=loadDataSet()
dataArr=array(dataMat)
n=shape(dataArr)[0]
xcord1=[];ycord1=[]
xcord2=[];ycord2=[]
for i in range(n):
if int(labelMat[i])==1:
xcord1.append(dataArr[i,1])
ycord2.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1])
ycord2.append(dataArr[i,2])
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(xcord1,ycord1,s=30,c='r',marker='s')
ax.scatter(xcord2,ycord2,s=30,c='g')
x=arange(-3.0,3.0,0.1)
y=(-weights[0]-weights[1]*x)/weights[2]
ax.plot(x,y)
plt.xlabel('x1')
plt.ylabel('x2')
plt.show()
回归优化
梯度上升算法在每次更新回归系数时都需要遍历整个数据集,该方法在处理 100 个左右的数据集时尚可,但如果有数十亿样本和成千上万的特征,那么该方法的计算复杂度就太高了。一种改进方法是一次仅用一个样本点来更新回归系数,该方法称为 随机梯度上升算法。由于可以在新样本到来时对分类器进行增量式更新,因而随机梯度上升算法是一个在线学习算法。与 “在线学习” 相对应,一次处理所有数据被称作是 “批处理”
# 随机梯度上升
def stocGradAscent(dataMatrix,classLabels):
m,n=shape(dataMatrix)
alpha=0.01
weights=ones(n)
for i in range(m):
h=sigmoid(sum(dataMatrix[i]*weights))
error=classLabels[i]-h
weights=weights+alpha*error*dataMatrix[i]
return weights
# 随机梯度上升算法优化可以用于和之前的两种方法对比实验
def storGradAscent(dataMatrix,classLabels,numIter=150):
m, n = shape(dataMatrix)
weights = ones(n)
for j in range(numIter):
dataindex=range(m)
for i in range(m):
# 每次的参数调整
alpha=4/(1.0+j+i)+0.01
randindex=int(random.uniform(0,len(dataindex)))
h=sigmoid(sum(dataMatrix[i]*weights))
error=classLabels[randindex]-h
weights=weights+alpha*error*dataMatrix[randindex]
del(dataindex[randindex])
return weights
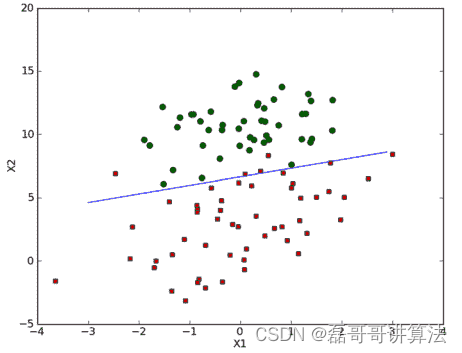
最后将结果分类展示
def testLR():
dataMat, labelMat = loadDataSet("TestSet.txt")
dataArr = array(dataMat)
weights = gradAscent(dataArr, labelMat)
# weights = stocGradAscent0(dataArr, labelMat)
# weights = stocGradAscent1(dataArr, labelMat)
plotBestFit(dataArr, labelMat, weights)
//都可以试试,毕竟优化效果还是明显的,下文的代码使用最下面的随机梯度上升
随机梯度伪代码
# 随机梯度上升
# 梯度上升优化算法在每次更新数据集时都需要遍历整个数据集,计算复杂都较高
# 随机梯度上升算法(随机化)
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) # 创建与列数相同的矩阵的系数矩阵,所有的元素都是1
# 随机梯度, 循环150,观察是否收敛
for j in range(numIter):
# [0, 1, 2 .. m-1]
dataIndex = range(m)
for i in range(m):
# i和j的不断增大,导致alpha的值不断减少,但是不为0
alpha = 4/(1.0+j+i)+0.0001 # alpha 会随着迭代不断减小,但永远不会减小到0,因为后边还有一个常数项0.0001
# 随机产生一个 0~len()之间的一个值
# random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。
randIndex = int(random.uniform(0,len(dataIndex)))
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
下文是机器学习实战中,对于疝气实战中一些数据变换处理的解释,从而使得随机梯度伪代码也做了对应的数据处理

通过之后优化,肉眼可见的分类效果提升
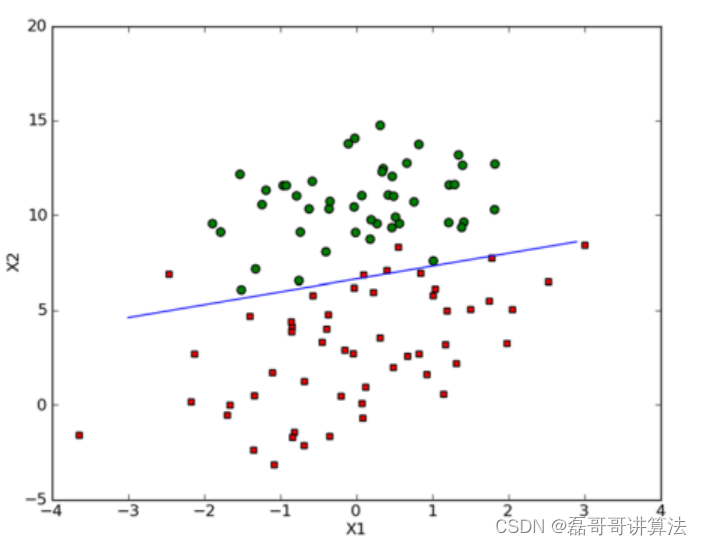
疝气马病项目实战手搓版
从疝气病症预测病马的死亡率
收集数据: 给定数据文件
准备数据: 用 Python 解析文本文件并填充缺失值
分析数据: 可视化并观察数据
训练算法: 使用优化算法,找到最佳的系数
测试算法: 为了量化回归的效果,需要观察错误率。根据错误率决定是否回退到训练阶段,
通过改变迭代的次数和步长的参数来得到更好的回归系数
最优化的方向梯度下降的迭代,认为是回归
数据集下载开源的是horse-colic.data and horse-colic.test
会涉及一些非常规的定义数,需要处理数据中的缺失值,或者直接舍弃。
假设有100个样本和20个特征,这些数据都是机器收集回来的。若机器上的某个传感器损坏导致一个特征无效时该怎么办?此时是否要扔掉整个数据?这种情况下,另外19个特征怎么办? 它们是否还可以用?答案是肯定的。因为有时候数据相当昂贵,扔掉和重新获取都是不可取的,所以必须采用一些方法来解决这个问题。
可选的数据保留做法:
- 使用可用特征的均值来填补缺失值;
- 使用特殊值来填补缺失值,如 -1;
- 忽略有缺失值的样本;
- 使用有相似样本的均值添补缺失值;
- 使用另外的机器学习算法预测缺失值。
数据预处理
下文对数据集进行操作
def GetData(path):
Data = []
Label = []
index = [2,24,25,26,27]
with open(path) as f:
for line in f.readlines():
LineArr = line.strip().split(" ")
m = np.shape(LineArr)[0]
data = []
for i in range(m):
if i in index:
continue
elif i == 22:
#下标为22的属性是分类
#1代表活着,标记设为1
#2,3分别代表死亡,安乐死,标记设为0
if LineArr[i] == '?':
Label.append(0)
elif int(LineArr[i]) == 1:
Label.append(1)
else:
Label.append(0)
else:
if LineArr[i] == '?':
data.append(0.0)
else:
data.append(float(LineArr[i]))
Data.append(data)
Data = np.array(Data)
Label = np.array(Label)
return Data,Label
def ZeroProcess(data):
"""
:param data:需要进行0值处理的数据
:return: 返回把0值已经处理好的数据
"""
m,n = np.shape(data)
for i in range(n):
avg = np.average(data[:,i])
if np.any(data[:,i]) == 0:
for j in range(m):
data[j][i] = avg
else:
continue
return data
def autoNorm(Data):
"""
:param Data: 需要进行归一化的数据
:return: 进行Max-Min标准化的数据
"""
#求出数据中每列的最大值,最小值,以及相应的范围
data_min = Data.min(0)
data_max = Data.max(0)
data_range = data_max-data_min
#进行归一化
m = np.shape(Data)[0]
Norm_Data = Data - np.tile(data_min,(m,1))
Norm_Data = Norm_Data / data_range
return Norm_Data
def PreProcess(data):
"""
数据预处理,包括0值处理和归一化
:param data:需要处理的数据
:return: 已经处理好的数据
"""
#对数据进行0值处理
Non_Zero_Data = ZeroProcess(data)
#对数据进行归一化
Norm_Data = autoNorm(Non_Zero_Data)
return Norm_Data
数据集有效导入
path1 = "./horse_colic_train.txt"
path2 = "./horse_colic_test.txt"
Train_Data,Train_Label = GetData(path1)
Test_Data,Test_Label = GetData(path2)
#数据预处理,包括0值处理和归一化
Train_Data_Precess = PreProcess(Train_Data)
Test_Data_Process = PreProcess(Test_Data)
#设置matplotlib,能让它显示中文
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
原始的数据集经过预处理后,保存成两个文件: horseColicTest.txt 和 horseColicTraining.txt 。
根据项目提供的特征对之前的模板函数进行略微修改
def stocGradAscent0(dataMatrix, classLabels):
'''
Desc:
随机梯度下降,只使用一个样本点来更新回归系数
Args:
dataMatrix -- 输入数据的数据特征(除去最后一列)
classLabels -- 输入数据的类别标签(最后一列数据)
Returns:
weights -- 得到的最佳回归系数
'''
m, n = shape(dataMatrix)
alpha = 0.01
# n*1的矩阵
# 函数ones创建一个全1的数组
weights = ones(n) # 初始化长度为n的数组,元素全部为 1
for i in range(m):
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn,此处求出的 h 是一个具体的数值,而不是一个矩阵
h = sigmoid(sum(dataMatrix[i] * weights))
# print 'dataMatrix[i]===', dataMatrix[i]
# 计算真实类别与预测类别之间的差值,然后按照该差值调整回归系数
error = classLabels[i] - h
# 0.01*(1*1)*(1*n)
# print weights, "*" * 10, dataMatrix[i], "*" * 10, error
weights = weights + alpha * error * dataMatrix[i]
return weights
# 随机梯度下降算法(随机化)
def stocGradAscent1(dataMatrix, classLabels, numIter):
m, n = shape(dataMatrix)
weights = ones(n) # 创建与列数相同的矩阵的系数矩阵,所有的元素都是1
# 随机梯度, 循环150,观察是否收敛
for j in range(numIter):
# [0, 1, 2 .. m-1]
dataIndex = range(m)
for i in range(m):
# i和j的不断增大,导致alpha的值不断减少,但是不为0
alpha = 4 / (
1.0 + j + i
) + 0.0001 # alpha 会随着迭代不断减小,但永远不会减小到0,因为后边还有一个常数项0.0001
# 随机产生一个 0~len()之间的一个值
# random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。
randIndex = int(random.uniform(0, len(dataIndex)))
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn
h = sigmoid(sum(dataMatrix[dataIndex[randIndex]] * weights))
error = classLabels[dataIndex[randIndex]] - h
# print weights, '__h=%s' % h, '__'*20, alpha, '__'*20, error, '__'*20, dataMatrix[randIndex]
weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]]
# del (dataIndex[randIndex])
return weights
测试算法: 为了量化回归的效果,需要观察错误率。根据错误率决定是否回退到训练阶段,通过改变迭代的次数和步长的参数来得到更好的回归系数
回归分类函数
# 分类函数,根据回归系数和特征向量来计算 Sigmoid的值
def classifyVector(inX, weights):
prob = sigmoid(sum(inX * weights))
if prob > 0.5: return 1.0
else: return 0.0
# 打开测试集和训练集,并对数据进行格式化处理
def colicTest():
frTrain = open('horseColicTraining.txt')
frTest = open('horseColicTest.txt')
trainingSet = []
trainingLabels = []
# 解析训练数据集中的数据特征和Labels
# trainingSet 中存储训练数据集的特征,trainingLabels 存储训练数据集的样本对应的分类标签
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
# 使用 改进后的 随机梯度下降算法 求得在此数据集上的最佳回归系数 trainWeights
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 500)
# trainWeights = stocGradAscent0(array(trainingSet), trainingLabels,150)
errorCount = 0
numTestVec = 0.0
# 读取 测试数据集 进行测试,计算分类错误的样本条数和最终的错误率
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights)) != int(
currLine[21]):
errorCount += 1
errorRate = (float(errorCount) / numTestVec)
print("the error rate of this test is: %f" % errorRate)
return errorRate
# 调用 colicTest() 10次并求结果的平均值
def multiTest():
numTests = 10
errorSum = 0.0
for k in range(numTests):
errorSum += colicTest()
print("after %d iterations the average error rate is: %f" % (numTests, errorSum / float(numTests)))
执行结果
 同时计算涉及到多特征向量每一个对应的回归系数,以及最后的常数项。
同时计算涉及到多特征向量每一个对应的回归系数,以及最后的常数项。
回归的目的是寻找一非线性函数sigmoid的最佳拟合函数。与其对应还有SVM支持向量机,下一部分将和其进行对比看一下效果

不同算法模型性能对比
仍然根据之前的疝气马病数据集,但是使用datapolish处理后的新版数据集,float&&int&&String导致数字化转化操作的特征向量就会被删减或者根据PCA降维度操作省略掉。
总而言之,一切的基础,数据集的预处理。
优秀的数据预处理
# 取得列信息
with open("resources/horse-colic.names", 'r', encoding='utf-8') as f:
data_names = f.read()
data_columns = re.findall(r'(?<=[0-9]:).*', data_names)
data_columns = [col.strip() for col in data_columns[:-3]]
data_columns
# 离散列
columns_discrete = ['surgery?', 'Age', 'temperature of extremities', 'peripheral pulse',
'mucous membranes', 'capillary refill time', 'pain - a subjective judgement of the horse\'s pain level', 'peristalsis',
'abdominal distension', 'nasogastric tube', 'nasogastric reflux', 'rectal examination - feces', 'abdomen', 'abdominocentesis appearance']
# 独热编码列
col_oneHot = ['surgery?', 'Age']//这个是疝气数据集对应的特征名称
符合三种模型都能使用的数据结构,新的处理方式,和上文提供的不一样
def load_data(data_path):
horse_data = pd.read_csv(data_path, header=None, sep=r"\s+")
horse_data = horse_data.loc[:, :22] # 只取到死亡情况
horse_data.columns = data_columns # 修改列名
horse_data = horse_data.replace("?", float('Nan'))
return horse_data
def del_invalid(horse_data, NAN_THRES=0.5):
col_del = ["Hospital Number"] # 医院编号与存活率关系不大,选择删除
# 去除缺失值占比较多的特征
for col in horse_data.columns:
if horse_data[col].isna().sum() > len(horse_data) * NAN_THRES and col not in col_del:
col_del.append(col)
return col_del
def preprocess(horse_data, col_del):
horse_data = horse_data.drop(columns=col_del)
horse_data = horse_data.dropna(subset=['outcome']).reset_index(drop=True) # 删除标签缺失的样本
x_data = horse_data.drop(columns=['outcome'])
y_data = horse_data[['outcome']]
# outcome列修改,2(死亡)、3(被安乐死)均表示死亡,都以2表示;1表示存活
y_data.loc[y_data['outcome'] == '3', 'outcome'] = '2'
y_data['outcome'] = pd.to_numeric(y_data['outcome'], errors='coerce').astype('int32')
# 分离离散列和连续列,分别处理
x_discrete = x_data[list(set(columns_discrete) - set(col_del))]
x_continue = x_data.drop(columns=x_discrete.columns)
# 离散变量one-hot编码
for col in col_oneHot:
if col in x_discrete.columns:
column_onehot = pd.get_dummies(x_discrete[col], prefix=col)
x_discrete = x_discrete.drop(columns=col)
x_discrete = pd.concat([x_discrete, column_onehot], axis=1)
# 用众数填补缺失值
imp = SimpleImputer(strategy='most_frequent')
x_discrete = pd.DataFrame(imp.fit_transform(x_discrete), columns=x_discrete.columns, index=None)
for col in x_discrete.columns:
x_discrete[col] = pd.to_numeric(x_discrete[col]).astype('int32')
# 用均值填充连续变量缺失值
for col in x_continue.columns:
x_continue[col] = pd.to_numeric(x_continue[col], errors='coerce').astype("float64")
x_continue[col] = x_continue[col].fillna(x_continue[col].mean())
# 归一化
x_continue = (x_continue - x_continue.mean()) / (x_continue.max() - x_continue.min())
horse_data = pd.concat([x_discrete, x_continue, y_data], axis=1)
horse_data = horse_data.sort_index(axis=1) # 对列名排序保证验证集和训练集特征一一对应
return horse_data
上面的数据集操作,就是在手搓版上面的GetData,以及后面的归一化。
相关系数,向量过多,容易过拟合,所以选择了可以使用的降维度方法、PCA模式识别讲的方法。
通过相关混淆矩阵,选择12个特征列
df_corr = horse_data.corr()
sns.heatmap(df_corr, cmap="YlGnBu")
x = horse_data.drop(columns=["outcome"])
y = horse_data["outcome"]
pca = PCA(n_components=12)
x = pca.fit_transform(x)
df_corr = pd.DataFrame(x, index=None).corr()
sns.heatmap(df_corr, cmap="YlGnBu")
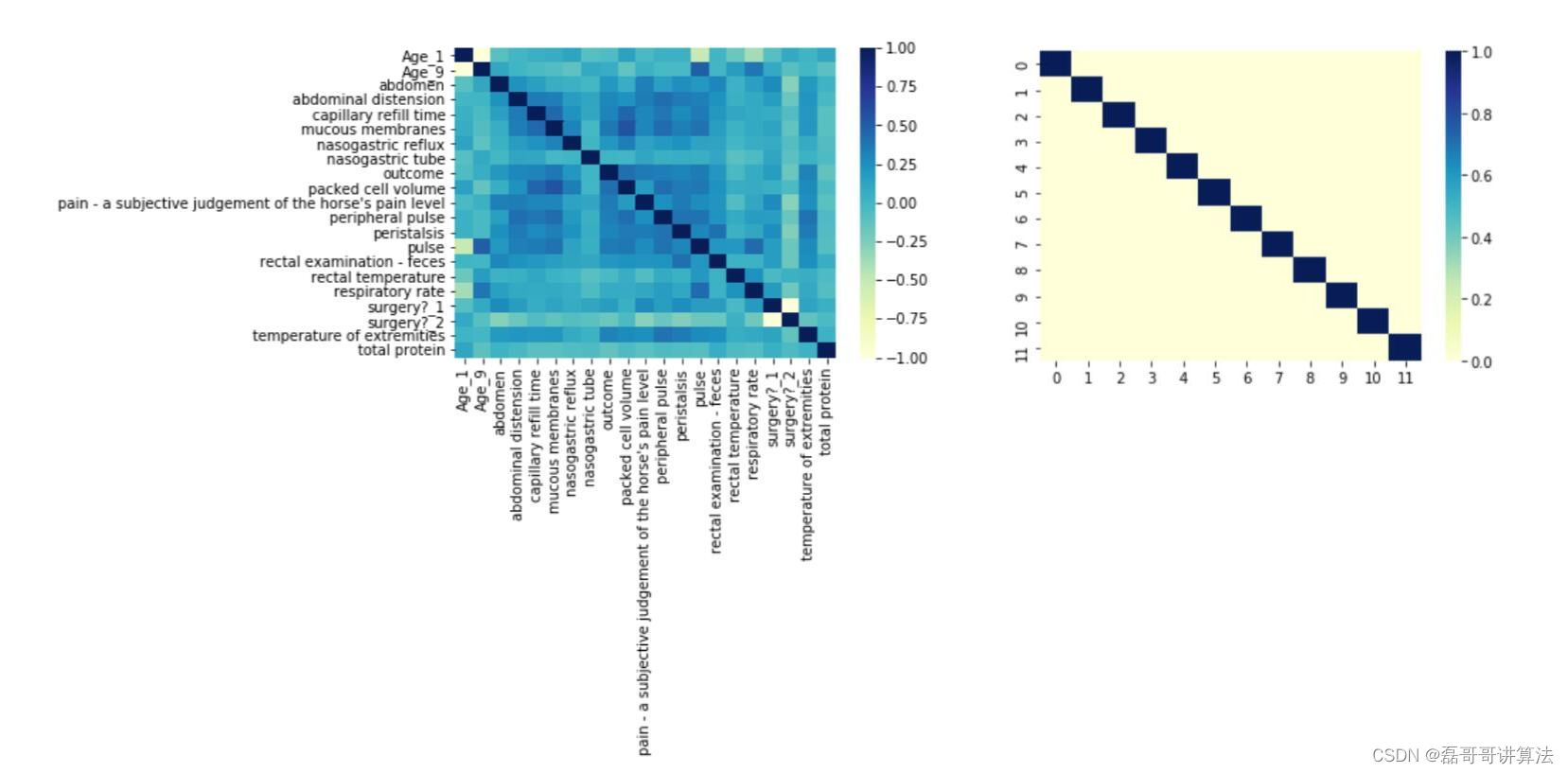
过程展示一下特征值混淆矩阵的结果。
data_test = load_data("horse-colic.test")
data_test = preprocess(data_test, col_del)
x_data_test = data_test.drop(columns=["outcome"])
x_data_test = pca.transform(x_data_test)
y_data_test = data_test['outcome']
这是比较nice的数据预处理,之后的算法模型效率对比就直接调用库里的函数了。
因为Python库里都已经配置好了。老四样性能对比呈现较为直观
模型算法对比
penalty惩罚函数C个,构建params_grid[‘C’]给出了一系列C的取值,模型将尝试这些不同的值来找到最佳的C。
在支持向量机(Support Vector Machine,SVM)中,scale和auto是用于调整gamma参数的两个选项。
scale选项表示使用特征数据的标准差来计算gamma的值。具体而言,对于每个特征,gamma的值将被设置为1 / (n_features * X.var()),其中n_features是特征的数量,X.var()是特征数据的方差。这种设置使得gamma的值与特征数据的尺度有关。
auto选项表示使用1 / n_features作为gamma的值。这种设置假设所有特征具有相同的重要性,因此gamma的值不依赖于特征数据的尺度。
SVM支持向量机
params_grid = {
'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000],
'gamma': ['scale', 'auto']
}
grid = GridSearchCV(svm.SVC(), param_grid=params_grid, cv=3, verbose=1)
grid.fit(x, y)
svm_clf = grid.best_estimator_
svm_clf.fit(x, y)
svm_clf.score(x_data_test, y_data_test)
print(classification_report(svm_clf.predict(x_data_test), y_data_test))
执行结果如下:
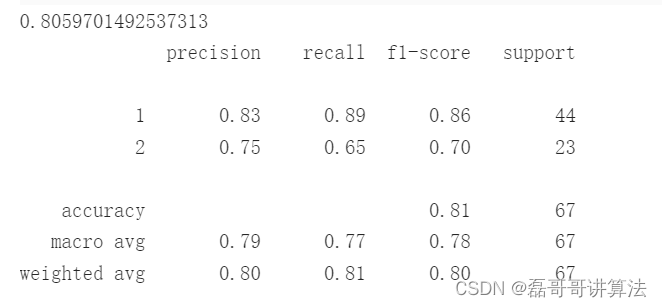
逻辑回归
params_grid = {
'penalty': ['l1', 'l2', 'elasticnet'],
'C': [0.001, 0.01, 0.1, 1, 10, 100, 1000]
}
grid = GridSearchCV(LogisticRegression(), param_grid=params_grid, cv=3, verbose=1)
grid.fit(x, y)
lgr_clf = grid.best_estimator_
lgr_clf.fit(x, y)
lgr_clf.score(x_data_test, y_data_test)
print(classification_report(lgr_clf.predict(x_data_test), y_data_test))
执行结果如下:
adaboost分类器
决策树,因为要是讲数据全都导入测试,那么每组都受到是否判断影响,受到对的特征干扰影响大,所以需要剔除更多缺失值占比比较多的列,降低干扰,
horse_data = load_data("horse-colic.data")
col_del = del_invalid(horse_data, 0.3) # 降低阈值,剔除更多存在缺失值的列
horse_data = preprocess(horse_data, col_del)
horse_data.info()
col_del
df_corr = horse_data.corr()
sns.heatmap(df_corr, cmap="YlGnBu")
x = horse_data.drop(columns=["outcome"])
y = horse_data["outcome"]
pca = PCA(n_components=15)
x = pca.fit_transform(x)
data_test = load_data("horse-colic.test")
data_test = preprocess(data_test, col_del)
x_data_test = data_test.drop(columns=["outcome"])
x_data_test = pca.transform(x_data_test)
y_data_test = data_test['outcome']
params_grid = {
'base_estimator__max_depth': range(3, 15),
'learning_rate': [0.1, 0.3, 0.5, 0.7, 1],
'n_estimators': range(50, 100, 10),
'random_state': [48]
}
grid = GridSearchCV(AdaBoostClassifier(DecisionTreeClassifier()), param_grid=params_grid, cv=3, verbose=1, n_jobs=-1)
grid.fit(x, y)
ada_clf = grid.best_estimator_
ada_clf.fit(x, y)
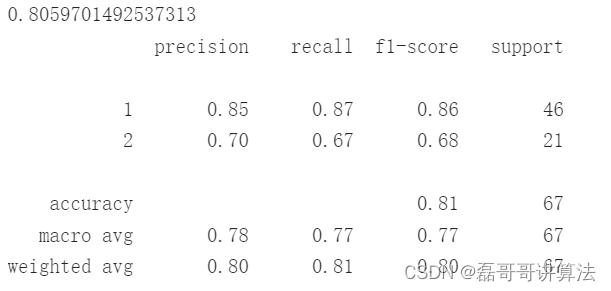
ada_clf.score(x_data_test, y_data_test)
print(classification_report(ada_clf.predict(x_data_test), y_data_test))
执行结果如下:

END
根据机器学习实战,尝试性让代码跑起来,如果需要详细代码和数据集,可以直接在我账号资源里找,直接免费下载了。然后想一下之前学过一些机器学习比较基础的代码,和最近学过的最优化,模式识别,矩阵论,三个真的是息息相关,而且发现当他们融合贯通之后,代码就更容易理解,也不需要像之前强行背代码逻辑。
所以准备新开一个专题啦机器学习,也许会发现新的理解。
风月不相干,春秋两不沾
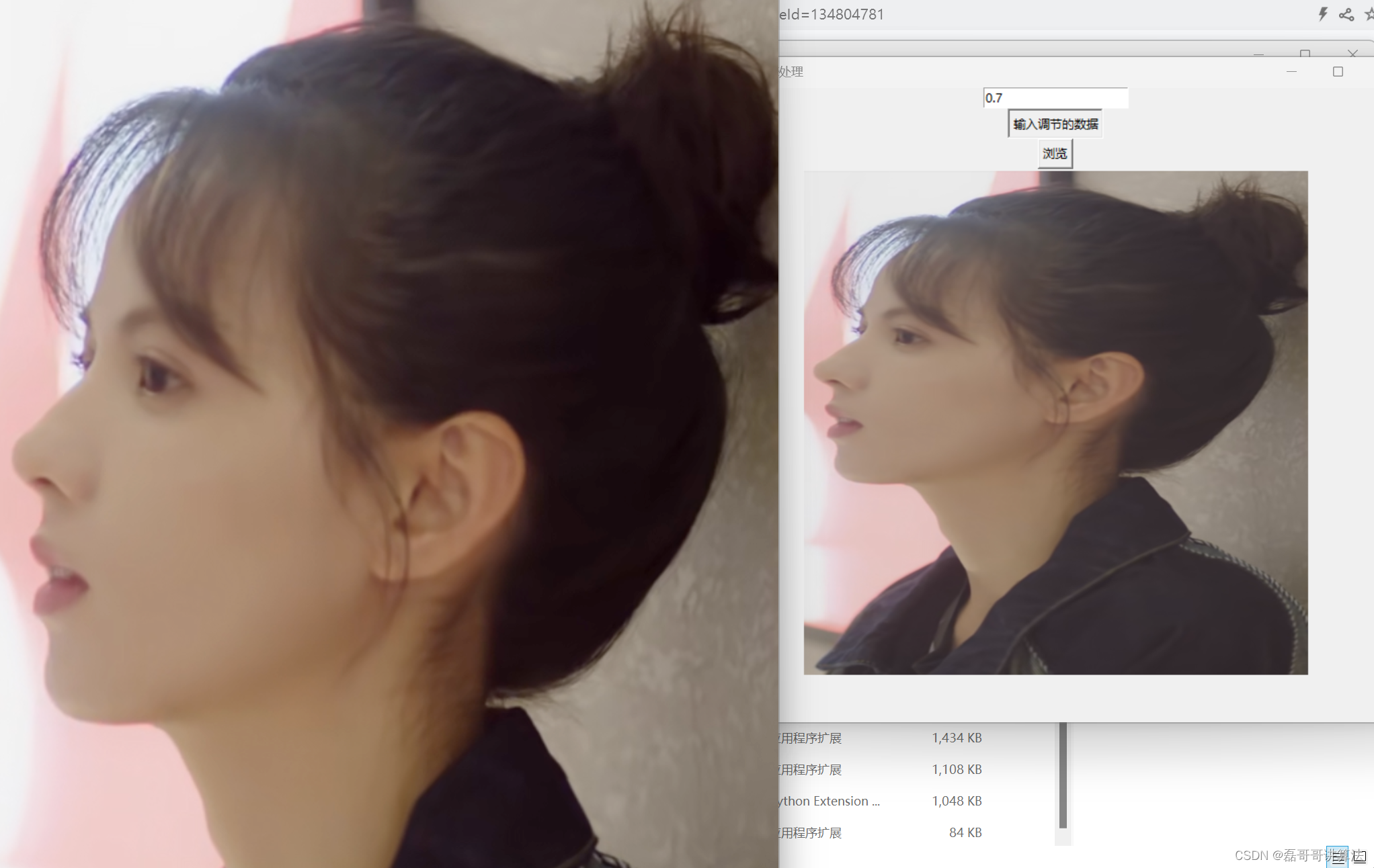
上传一个自己写的小图像调节程序,把小姐姐图片直接导入就可以实现亮度调节哦
也许执行的效果会有些慢,因为不太想依赖于掉包,手搓迭代的循环修改
import math
from tkinter import messagebox
import numpy as np
import cv2
import tkinter as tk
from tkinter import filedialog
from PIL import ImageTk,Image
def GammaTranform(c,gamma,image):
# 三通道
h,w,d = image.shape[0],image.shape[1],image.shape[2]
new_img = np.zeros((h,w,d),dtype=np.float32)
for i in range(h):
for j in range(w):
new_img[i,j,0] = c*math.pow(image[i, j, 0], gamma)
new_img[i,j,1] = c*math.pow(image[i, j, 1], gamma)
new_img[i,j,2] = c*math.pow(image[i, j, 2], gamma)
cv2.normalize(new_img,new_img,0,255,cv2.NORM_MINMAX)
new_img = cv2.convertScaleAbs(new_img)
return new_img
def browse_image():
global selected_image_path
filename = filedialog.askopenfilename(filetypes=[("Image Files", "*.png;*.jpg;*.jpeg")])
if filename:
# 清空之前的图片
if image_label.winfo_exists():
image_label.pack_forget()
# 加载并显示图片
image = Image.open(filename)
image = image.resize((500, 500)) # 调整图片大小
photo = ImageTk.PhotoImage(image)
image_label.config(image=photo)
image_label.image = photo
image_label.pack()
selected_image_path=filename
def convert_to_unicode_escape(path):
# 将非ASCII字符转换为Unicode转义序列
path = path.encode('unicode_escape').decode()
return path
def polishpicture(num,image_path):
img = cv2.imread(image_path, 1)
if img is None:
messagebox.showinfo("无法加载图像")
num=float(num)
new_img =GammaTranform(1,num,img)
cv2.imshow('polishpicture',new_img)
cv2.imwrite('demon.jpg',new_img)
cv2.waitKey(0)
def process_image_path(data):
num=entry.get()
if num.lower() == "end":
messagebox.showinfo("测试结束", "测试已结束!")
window.destroy()
else:
try:
num = float(num) # 尝试将内容转换为浮点数
polishpicture(num,selected_image_path)
except ValueError:
messagebox.showinfo("测试数据错误","请重新输入合理数据")
entry.delete(0, tk.END)
# 创建窗口
window = tk.Tk()
window.title("图像光感处理")
window.geometry("700x600+300+400")
# 创建文本框
entry = tk.Entry(window)
entry.pack()
# 创建按钮
button = tk.Button(window, text="输入调节的数据", command=lambda: process_image_path(entry.get()))
button.pack()
sendbutton=tk.Button(window,text="浏览",command=browse_image)
sendbutton.pack()
image_label=tk.Label(window)
# 运行窗口的主循环
window.mainloop()
运行效果如下:图片就是用小糖心啦

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











