










【读论文】Rethinking the necessity of image fusion in high-level vision tasks: A practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity
论文: https://www.sciencedirect.com/science/article/pii/S1566253523001860
更多红外与可见光图像融合的论文的具体的解读欢迎大家来到红外与可见光图像融合专栏,关于该领域的问题也欢迎大家私信或则公众号联系我。
介绍
好久没看过论文,今天刚好有空,又找了一篇information fusion的论文,咱们一起看看吧。

这篇论文和我们之前见到的论文不大一样,至于有啥不一样,咱们来看看吧。
解决的问题
- 基于特征融合的高级视觉任务存在一些缺陷,例如单个特征提取分支会影响性能,两个独立分支会导致融合性能的下降。
- 现有的方法往往都基于单个任务设计的,不能很好的推广至其他任务。
- 证明了融合图像在多模态高级视觉任务的优越性
网络架构
整体架构
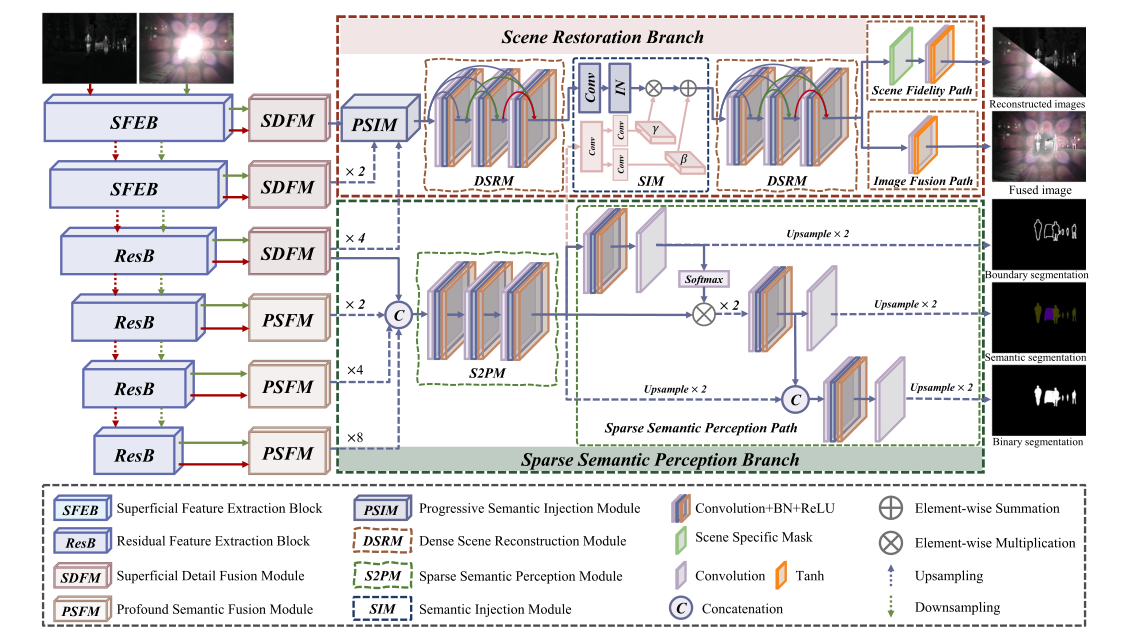
整体的架构如上图所示,给我的感觉就像第一次看到DIVFusion 的架构一样。
现在先不看特征提取部分的内容,先看下场景恢复分支(scene restoration branch ) 和 稀疏语义感知分支( sparse semantic perception branch) 这俩哈。
可以看到场景恢复分支最后有两个输出结果,但除了最后一部分不同,两个输出结果对应路径的前半部分是相同的。
其中DSRM的作用就是基于密集连接来实现图像恢复的,最终的就是在于这个SIM(语义注入模块) ,这一部分是干什么的, 我们接下来再说。我们先来看一下稀疏语义感知分支。
稀疏语义感知分支( sparse semantic perception branch)
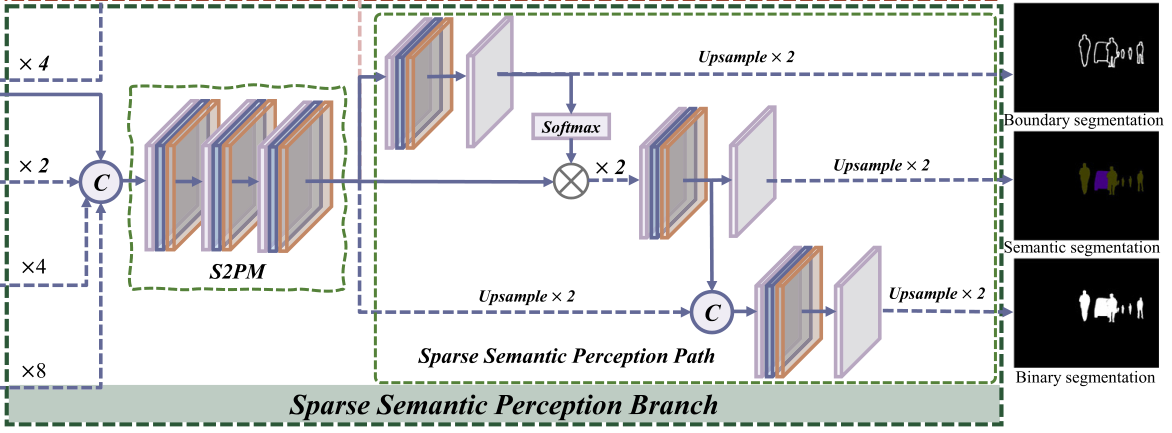
现在看一下这个语义感知分支,可以看到的是,这个分支有三个结果了,好家伙!

我们再看回来哈,这个分支为什么要有三个结果呢?
作者在前面提到,以往的与高级视觉任务相结合的方法存在一个问题 都使用特定的模型来约束最终的结果,从而限制了对其他模型的适用性。 由于我对分割领域不是很了解,这里说一下我自己的观点。
该框架输出的三个输出分别对应三种任务,分别是边缘分割,二进制分割和语义分割,这三类输出公用一个S2PM,是不是也就是说S2PM提取的语义信息要同时满足这三类任务,也就可以理解为S2PM提取的语义信息不是为了单个任务设计的,而是包含了多个任务所通用的语义信息。这种通用的信息相比于针对单个具体任务提取的语义信息来说,更适合其他任务。
然后看一下这个网络架构,如果看文章参考的论文来说的话,其实二者存在一定的不一致,参考的网络如下图
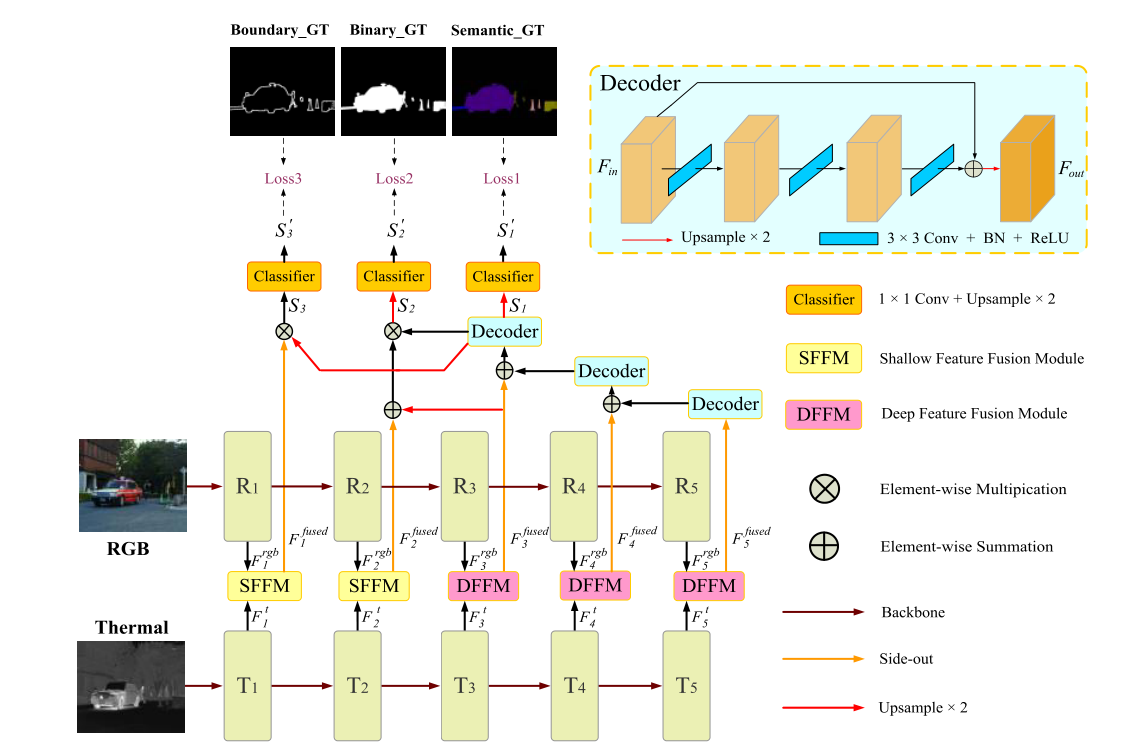
可以看到的是,这篇论文中最深层的特征用于预测语义分割掩码,次深层特征用于提取二进制分割掩码,最后浅层特征用于预测边界分割结果。
如果用这个逻辑理解这个网络结构确实有些困难,但归根结底也都是深层特征预测语义分割和二进制分割。
场景恢复分支(scene restoration branch )

场景恢复分支放在稀疏语义感知分支之后来讲,是因为场景恢复分支要利用稀疏语义分支提取的语义信息,也就是说稀疏语义分支的S2PM的输出也会注入到SIM中。
那么为什么要用稀疏语以分支提取的语义信息呢?
也就是说前面作者所提到的,现有的方法融合的图像并没有包含适合分割的语义特征信息,通过这种方式可以将语义信息注入到最终的融合图像中从而提高分割任务的性能。
这个注入的方式就很有意思了,这里用了一个SIM结构,不知道大家刚开始看的时候是什么感觉,反正我是真没看懂,这是干了啥。

但幸好在知乎上找到了答案,这里稍稍总结下。
我们可以简单想一下,用于分割的特征和用于图像融合的特征肯定会存在差别,毕竟是两个任务所需要的特征信息。这时候我们如果只是简单的对两类特征进行拼接,肯定会影响后续的处理。就像是,我要做一道菜,本来要的是一个切好的胡萝卜,结果你给我掺了点42号混凝土,这饭还怎么做?

**那就很清楚了,这个SIM就是用于消除因特征之间差异可能对后续处理产生的不良影响。**至于是怎么消除差异的,这里我就不献丑了,大家可以看看原论文。
图像还原部分就比较简单了,一方面使用下面这个路径来确保两类源图像中的信息得以充分提取。
另一方面就是下面这个路径来生成我们需要的融合图像了

总结
损失函数这里就不说了,原论文介绍的很清晰,整个文章读下来,最惊艳的就是网络结构,很巧妙的将分割所需要的语义信息注入到融合图像中,同时也为图像融合正名,证明在多模态高级视觉任务中,基于多模态特征的高级视觉任务所能达到的高度,我们使用融合图像也可以达到。
其他融合图像论文解读
》红外与可见光图像融合专栏,快来点我呀《
【读论文】DIVFusion: Darkness-free infrared and visible image fusion
【读论文】RFN-Nest: An end-to-end residual fusion network for infrared and visible images
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
参考
[1] Rethinking the necessity of image fusion in high-level vision tasks: A practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity















 1656
1656











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











