







DenseFuse: A Fusion Approach to Infrared and Visible Images 阅读笔记
论文地址:https://arxiv.org/abs/1804.08361
如有侵权请联系我们
摘要
提出了一种新的红外和可见光图像融合问题的深度学习体系结构。与传统的卷
积网络不同,我们的编码网络是由卷积层、融合层和稠密块组成的,其中每层
的输出相互连接。我们尝试使用这种架构在编码过程中从源图像中获取更多有
用的特征。设计了两个融合层(融合策略)来融合这些特征。最后,通过解码
器重建融合图像。
介绍
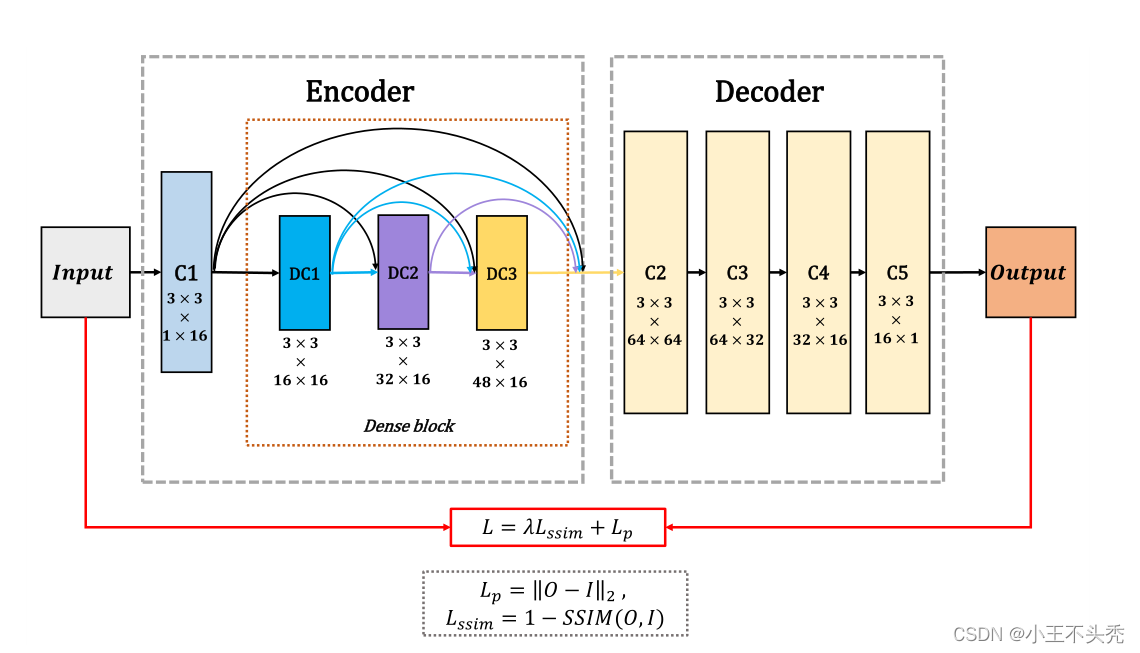
网络中包含编码网络和解码网络
编码网络包含CNN和DENSE block,由该网络提取图像特征
设置DENSE block的原因是因为传统的CNN只使用最后一层的feature map,这就损失了之前层中的信息,而dense block 很好的规避了这个问题
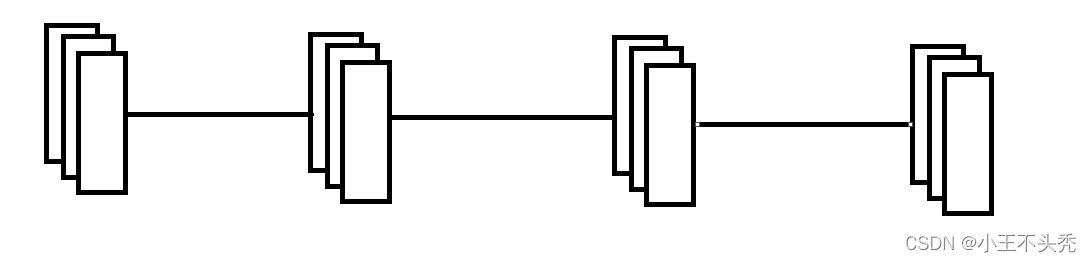
如下图,这是传统的神经网络
下图是dense block
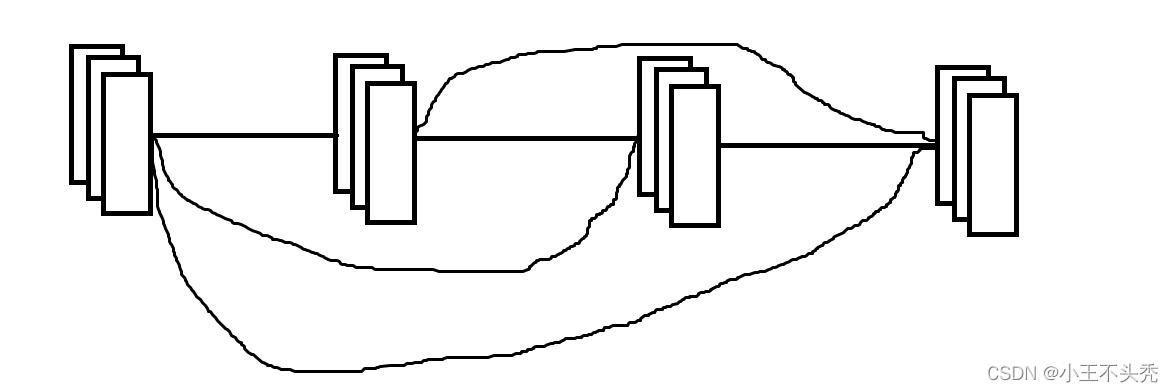
可以看出,每一层的结果都传递给之后的每一层,这样保证了中间层的有效信息也可以被使用
融合策略用于融合图像,文中提到的融合策略有两种,分别是加法策略和l1-norm 策略
解码网络有4个CNN,用于重构图像
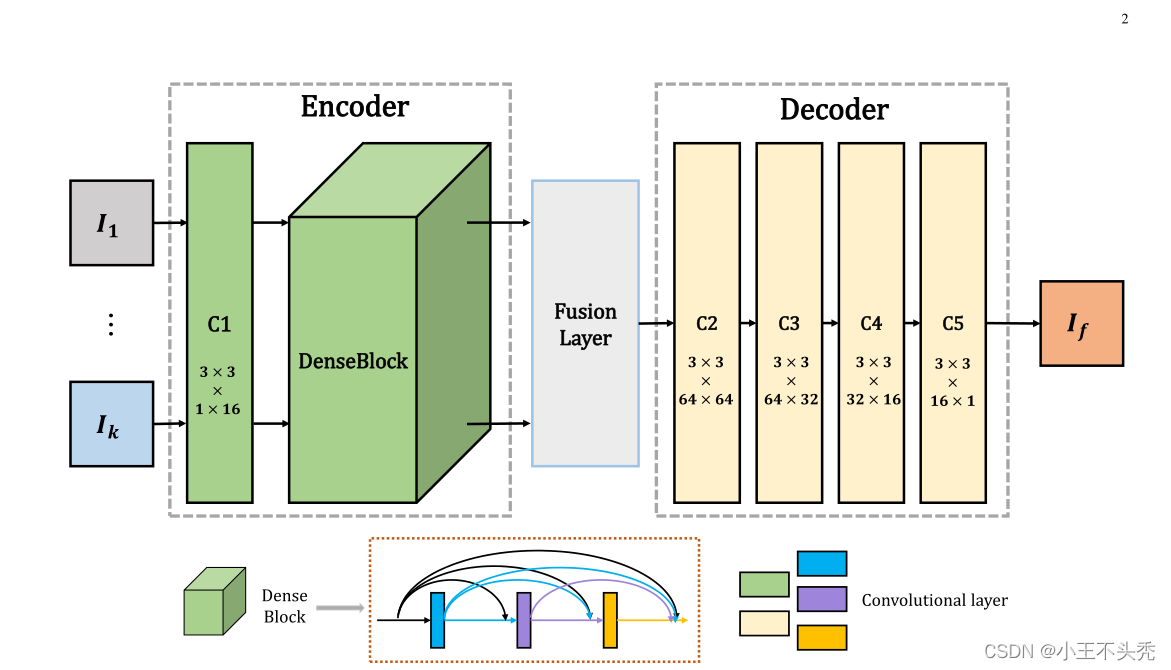
整个网络结构如下图所示
相关工作
等等等等等等。。。。。。
融合方法
文章中主要提到的是灰度图像的融合,因为彩色图像的融合和灰度图像的融合相似,文章中就没有细致介绍。
如下图所示,输入模型中的I1到Ik,包括红外图像和可视图像,这里不做区分,这里输入的图像数量k>=2,这里我个人的理解是,我们需要做红外图像和可视图像的融合,这就要保证输入模型中图片至少有一个可视图像和一个红外图像,所以说需要k>=2。
而且输入的图像应该是对齐的,如果没有对齐,会使用其他三篇论文中所提到的对齐算法进行对齐(这三篇论文还没读,之后看看)
网络的架构包含三部分,编码器,融合层和解码器
编码器
包含两部分,一层普通的CNN和一个DenseBlock,DenseBlock在第一部分的介绍中已经解释了,这里就不再做说明。
第一层CNN用于提取粗糙的图像特征,之后在进入DenseBlock之后,由于DenseBlock结构的特殊性,可以避免中间层重要特征的丢失
编码器中的CNN使用的卷积核都是3*3,步长都是为1,这就使得任何大小的图像都可以作为该模型的输入
对于编码网络中的每个卷积层,特征映射的输入通道数为16。
编码层输出会作为融合层的输入
解码器
解码器同样也有四个CNN层,解码器中的输入通道从左至右越来越少,直到最后输出时就是一个通道了,最后一个通道的结果就是我们重建的图像
融合层
两个融合策略
- 相加策略
- l1-norm Strategy(不知道咋翻译。。。。。。)
训练
训练过程中只对编码器和解码器进行训练,当二者被训练好之后,在使用适应的融合策略对编码器获得的特征进行融合,然后再交给解码器进行重建图像,这种训练模式的好处可以为特定的融合任务设计合适的融合层,并且为融合层的下一步发展提供了空间。
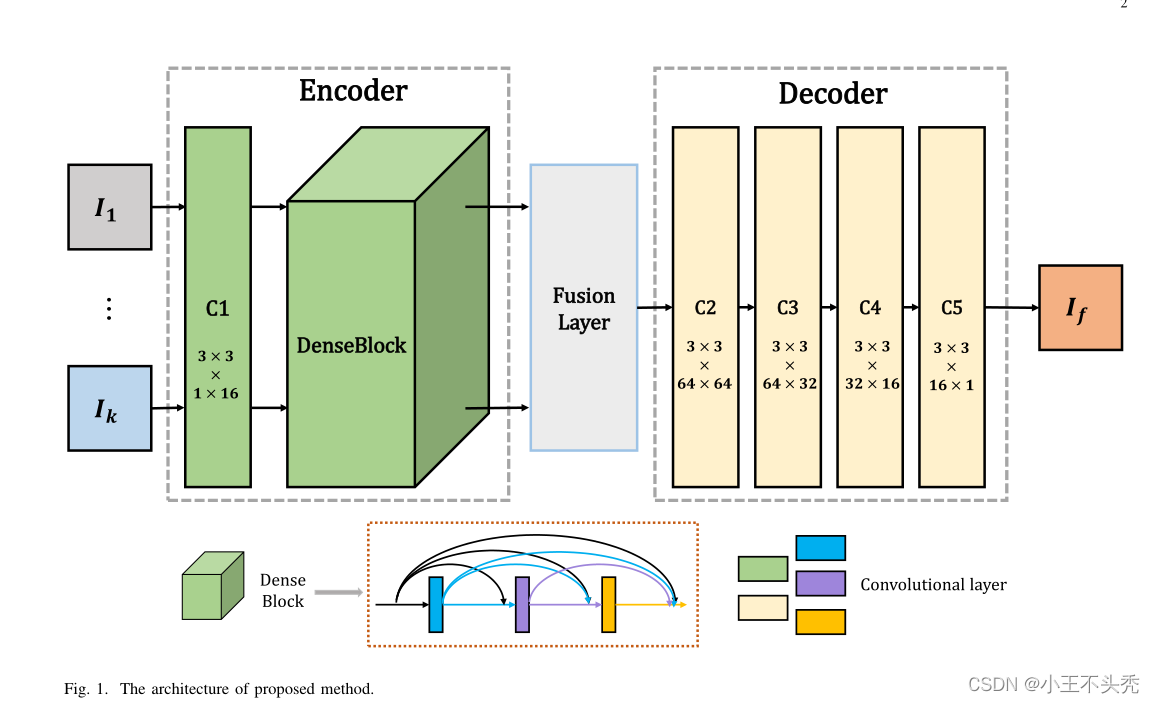
网络结构
整个网络的结构如下图所示
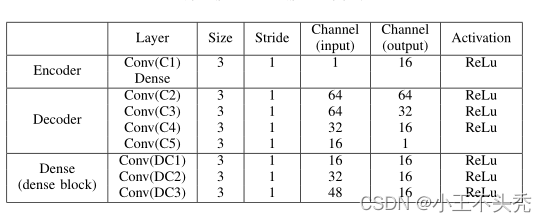
可以看出所有曾使用的激活函数都是Relu
损失函数
损失函数使用如下公式
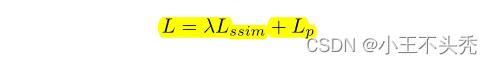
Lssim是结构相似性损失,Lp是像素损失
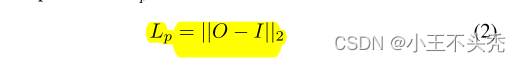
O是输出图像
I是输入图像
Lp就是二者之间的欧氏距离

SSIM是结构相似性运算,具体内容参考该论文
Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment:
from error visibility to structural similarity[J]. IEEE transactions on image
processing, 2004, 13(4): 600-612.
因为结构相似性损失和像素损失之间相差三个数量级,因此lamda设置为1,10,100,1000
训练数据集
采用MS-COCO作为训练的数据集
下载地址参考该文章MS COCO数据集下载链接
在训练时,将图像转换为256*256大小,并且调整为灰度图
采用随机梯度下降方法进行训练,批量设置为2,周期设置为2
融合层
加法策略(Addition Strategy)
参考文章
Prabhakar K R, Srikar V S, Babu R V . DeepFuse: A Deep Unsu-
pervised Approach for Exposure Fusion with Extreme Exposure Im-
age Pairs[C]//2017 IEEE International Conference on Computer Vision
(ICCV). IEEE, 2017: 4724-4732.
与上述文章中提到的策略相似,公式如下
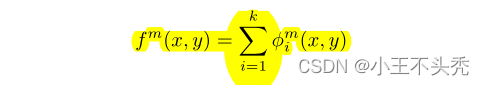
这里的fm代表融合之后的第m个通道的特征映射,φmi代表第 i 张图像的第 m 个通道的特征映射
这里的m满足 1=<m<=64,
不知道大家有没有和我一样疑惑的,这里的m为什么是<=64,明明上图结构提到的最后一层的输出是16通道的,如果有这个疑惑的话,看下图
这时因为使用的是DenseBlock,融合层的输入不仅仅只有DC3传递的16通道的特征映射,还有前面C1,DC1和DC2传递的特征映射,刚好是64个
l1-norm Strategy
公式如下
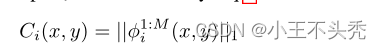
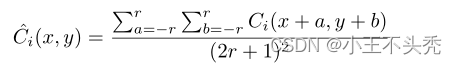
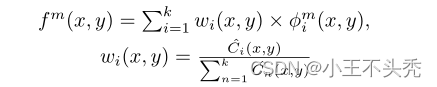
参考
Liu Y , Chen X, Ward R K, et al. Image fusion with convolutional
sparse representation[J]. IEEE signal processing letters, 2016, 23(12):
1882-1886.
这里没怎么看懂,后期再来补
总结
最后生成的fm作为解码器的输入
实验结果
这里回忆下前文损失函数的λ,当 λ 越大时,损失会下降的更快,但文中又提出当训练超过40000次时,无论选择 λ 为何值,都会产生最好的权重结果,但是 λ 越大培训阶段消耗的时间越少。
为了比较文中提到的融合方法与其他方法的优劣,使用了七个参数,有兴趣的去看一下(ps: 这里为啥不解释,因为我不知道这几个参数是干啥的)

这里稍微提下文章中关于色彩图像的融合,其实就是将彩色图像看作三个单通道的灰度图,将他们作为输入进行融合,最后再将三通道结合在一起
感悟
读了几遍之后,还有很多的不懂得,这里记录下现在的感悟,估计以后还会再改该文章
最后记录一下,第一次跑动论文的代码
艾玛,太不容易了

终于上GPU版本的Pytorch了
论文代码
参考
[1] DenseFuse: A Fusion Approach to Infrared and Visible Images



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











