







基于Fisher 线性判别方法的数据分类问题
ps:作者是很用心写的,如果觉得不错,请给作者一点鼓励噢!(点赞收藏评论噢)
1 Fisher 线性判别方法介绍
1.1 方法总括
Fisher线性判别方法可概括为把 d 维空间的样本投影到一条直线上,形成一维空间,即通过降维去解决两分类问题。如何根据实际数据找到一条最好的、最易于分类的投影方向,是 Fisher 判别方法所要解决的基本问题。
1.2 求解过程
1.2.1 核心思想
假设有一集合 D 包含 m 个 n 维样本{x1, x2, …, xm},第一类样本集合记为 D1,规模为 N1,第二类样本集合记为 D2,规模为 N2。若对 xi 的分量做线性组合可得标量:yi = wTxi(i=1,2,…,m)这样便得到 m 个一维样本 yi 组成的集合, 并可分为两个子集 D’1 和 D’2。计算阈值 yo,当 yi>yo 时判断 xi 属于第一类, 当 yi<yo 时判断 xi 属于第二类,当 yi=yo 时 xi 可判给任何一类或者拒收。
1.2.2 具体推导
在一维 Y 空间:
(1)各类样本的均值
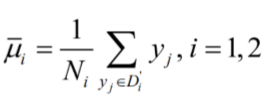
(2)样本类内离散度
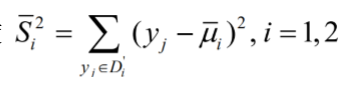
(3)总样本类内离散度
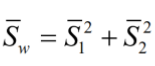
(4)样本类间离散度
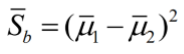
在 n 维 X 空间
(1)各类样本的均值向量
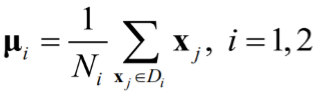
(2)样本类内离散度矩阵 Si 和总样本类内离散度矩阵 Sw
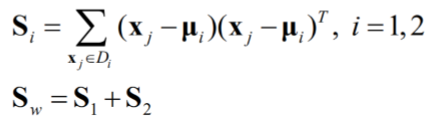
(3)样本类间离散度矩阵
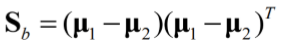
目标:
投影后,在一维 Y 空间中各类样本尽可能分得开些,即使原样本向量在该 方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求. 所以得到fisher准则函数如下:
Fisher 准则函数:
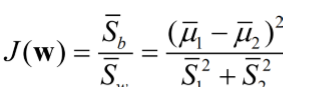

最佳变换向量 w*的求取
要求使 J(w)最大的 w,可以采用 Lagrange 乘子法求解。
假设分母等于非零常数, 定义 Lagrange 函数为:

由于 w 的模对问题本身无关紧要,因此
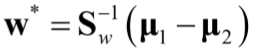
降维:
对样本集合作线性变换 w*Tx,得到n个样本投影后的样本值 y1,y2,……, yn
阈值:
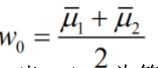
分类:
当 yi>wo 为第一类,当 yi<wo 为第二类
2 数据集介绍
2.1 iris 数据集
在 Iris 数据集中有三类(Setosa、Versicolour、Virginica)数据,每类 分别有 50 个数据,每个数据有 4 维特征,分别为 sepal length、sepal width、 petal length、petal width(萼片长度(cm)、萼片宽度(cm)、花瓣长度(cm)、花瓣宽度(cm))
2.2 sonar 数据集
在 Sonar 数据集中有两类(字母“R”(岩石)和“M”(矿 井)),分别有 97 个和 111 个数据,每个数据有 60 维的特征。
3 算法介绍
对于 iris 数据集,由于 Fisher 线性判别方法只能够判别两类,所以将 Iris 数据集分三种情况:1-2 类,1-3 类,2-3 类,分别判断每一种情况的 Fisher 判 别准确率。对于 sonar 数据集由于只有两类,直接利用 Fisher 分类即可。 采用随机取样方法,在每一次迭代过程中,将每一个类别中的样本重新排序, 以接近 3:1 的比例取前 1/4 为测试集,后 3/4 为训练集,进行分类。对于 iris 每一类数据集,取打乱后的前 15 个数据为测试集,后 35 个为训练集,在训练 集上找到最佳投影方向,并因此来分类测试集,此过程重复 20 次,最后将求出 的 20 个准确率求平均值。将用于判断的特征从 1 个逐步增加到所有特征,绘制 准确率曲线。对于 sonar 第 1 类数据,取前 24 个为测试集,后 73 个为测试集, 对于第二类数据我取前 28 个为测试集,后 83 个为测试集,重复和 iris 数据分 类一样的过程
4 仿真结果分析
随着分类特征数的增加,准确率呈现波动上升状态,最后准确率稳定在 81%上下

随着特征数的增加,分类准确率越来越高,且每两类分类准确率在加入 4 个特征 之后都在 95%以上。
结论:在第一程度上特征数量越多准确率越高,但这不是绝对的。
6 反思
在我的方法中,取 1….d-1 个特征进行分类时,只是单纯取了每个数据的前 d-1 个特征,没有去随机取 d-1 个特征验证不同特征搭配组合分类时的准确率。
7 matlab 代码
%Sonar数据集上分类
F=xlsread('E:/Sonar.xls');%导入 sonar 数据
S=[];
for j=1:60 A1=F(1:97,2:j+1);%sonar 第一类数据 B1=F(98:208,2:j+1);%sonar 第二类数据集
a4=zeros(73,j);
b4=zeros(83,j);
s1=zeros(j);%样本类内离散度矩阵
s2=zeros(j);
sw=zeros(j);%总样本类内离散度矩阵
w=zeros(j,1)%投影方向
y1=zeros(1,73);%测试集投影后的样本值
y2=zeros(1,83);
y3=zeros(1,24);%训练集投影后的样本值
y4=zeros(1,28);
V=[]%准确率矩阵
for i=1:20
r1=randperm(97,97);
r2=randperm(111,111);
A=A1(r1,:);%将第一类数据随机打乱
B=B1(r2,:);%将第二类数据随机打乱
a1=A(1:24,:);%将前 24 个取做第一类测试集 a4=A(25:97,:);%第一类训练集
b1=B(1:28,:);%将前 28 个取做第二类测试集 b4=B(29:111,:);%第二类训练集
m1=mean(a4);
m2=mean(b4);
for i=1:73
s1=s1+(a4(i,:)-m1)'*(a4(i,:)-m1);
end
for i=1:83
s2=s2+(b4(i,:)-m2)'*(b4(i,:)-m2);
end
sw=s1+s2;
w=(sw^-1)*(m1-m2)';
y1=w'*a4';%投影后的样本值
y2=w'*b4';
wo=(mean(y1)+mean(y2))/2%阈值
y3=w'*a1';
y4=w'*b1';
k1=0;%第一类测试准确个数
k2=0;%第二类测试准确个数
for i=1:24
if(y3(i)>wo)
k1=k1+1;
end
end
for i=1:28
if(y4(i)<wo)
k2=k2+1;
end
end
v=(k1+k2)/52;%准确率
V=[V,v];
s=mean(V)%平均准确率
end
S=[S,s];
end
plot(S);
%iris数据集上1,2类分类
F=xlsread('E:\iris.xlsx');%导入iris数据
S=[];
for j=1:4
A1=F(1:50,1:j);%iris第一类数据
B1=F(51:100,1:j);%iris第二类数据集
a4=zeros(35,j);
b4=zeros(35,j);
s1=zeros(j);%样本类内离散度矩阵
s2=zeros(j);
sw=zeros(j);%总样本类内离散度矩阵
w=zeros(j,1)%投影方向
y1=zeros(1,35);%测试集投影后的样本值
y2=zeros(1,35);
y3=zeros(1,15);%训练集投影后的样本值
y4=zeros(1,15);
V=[]%准确率矩阵
for i=1:20
r1=randperm(50,50);
r2=randperm(50,50);
A=A1(r1,:);%将第一类数据随机打乱
B=B1(r2,:);%将第二类数据随机打乱
a1=A(1:15,:);%将前15个取做第一类测试集
a4=A(16:50,:);%第一类训练集
b1=B(1:15,:);%将前15个取做第二类测试集
b4=B(16:50,:);%第二类训练集
m1=mean(a4);
m2=mean(b4);
for i=1:35
s1=s1+(a4(i,:)-m1)'*(a4(i,:)-m1);
end
for i=1:35
s2=s2+(b4(i,:)-m2)'*(b4(i,:)-m2);
end
sw=s1+s2;
w=(sw^-1)*(m1-m2)';
y1=w'*a4';%投影后的样本值
y2=w'*b4';
wo=(mean(y1)+mean(y2))/2%阈值
y3=w'*a1';
y4=w'*b1';
k1=0;%第一类测试准确个数
k2=0;%第二类测试准确个数
for i=1:15
if(y3(i)>wo)
k1=k1+1;
end
end
for i=1:15
if(y4(i)<wo)
k2=k2+1;
end
end
v=(k1+k2)/30;%准确率
V=[V,v];
s=mean(V)%平均准确率
end
S=[S,s];
end
plot(S);
%iris数据集1,3类分类
F=xlsread('E:\iris.xlsx');%导入iris数据
S3=[];
for j=1:4
A1=F(1:50,1:j);%iris第一类数据
B1=F(101:150,1:j);%iris第三类数据集
a4=zeros(35,j);
b4=zeros(35,j);
s1=zeros(j);%样本类内离散度矩阵
s2=zeros(j);
sw=zeros(j);%总样本类内离散度矩阵
w=zeros(j,1)%投影方向
y1=zeros(1,35);%测试集投影后的样本值
y2=zeros(1,35);
y3=zeros(1,15);%训练集投影后的样本值
y4=zeros(1,15);
V=[]%准确率矩阵
for i=1:20
r1=randperm(50,50);
r2=randperm(50,50);
A=A1(r1,:);%将第一类数据随机打乱
B=B1(r2,:);%将第三类数据随机打乱
a1=A(1:15,:);%将前15个取做第一类测试集
a4=A(16:50,:);%第一类训练集
b1=B(1:15,:);%将前15个取做第三类测试集
b4=B(16:50,:);%第三类训练集
m1=mean(a4);
m2=mean(b4);
for i=1:35
s1=s1+(a4(i,:)-m1)'*(a4(i,:)-m1);
end
for i=1:35
s2=s2+(b4(i,:)-m2)'*(b4(i,:)-m2);
end
sw=s1+s2;
w=(sw^-1)*(m1-m2)';
y1=w'*a4';%投影后的样本值
y2=w'*b4';
wo=(mean(y1)+mean(y2))/2%阈值
y3=w'*a1';
y4=w'*b1';
k1=0;%第一类测试准确个数
k2=0;%第三类测试准确个数
for i=1:15
if(y3(i)>wo)
k1=k1+1;
end
end
for i=1:15
if(y4(i)<wo)
k2=k2+1;
end
end
v=(k1+k2)/30;%准确率
V=[V,v];
s=mean(V)%平均准确率
end
S3=[S3,s];
end
plot(S3);
F=xlsread('E:\iris.xlsx');%导入iris数据
S1=[];
for j=1:4
A1=F(51:100,1:j);iris第二类数据
B1=F(101:150,1:j);%iris第三类数据集
a4=zeros(35,j);
b4=zeros(35,j);
s1=zeros(j);%样本类内离散度矩阵
s2=zeros(j);
sw=zeros(j);%总样本类内离散度矩阵
w=zeros(j,1)%投影方向
y1=zeros(1,35);%测试集投影后的样本值
y2=zeros(1,35);
y3=zeros(1,15);%训练集投影后的样本值
y4=zeros(1,15);
V=[]%准确率矩阵
for i=1:20
r1=randperm(50,50);
r2=randperm(50,50);
A=A1(r1,:);%将第二类数据随机打乱
B=B1(r2,:);%将第三类数据随机打乱
a1=A(1:15,:);%将前15个取做第二类测试集
a4=A(16:50,:);%第二类训练集
b1=B(1:15,:);%将前15个取做第三类测试集
b4=B(16:50,:);%第三类训练集
m1=mean(a4);
m2=mean(b4);
for i=1:35
s1=s1+(a4(i,:)-m1)'*(a4(i,:)-m1);
end
for i=1:35
s2=s2+(b4(i,:)-m2)'*(b4(i,:)-m2);
end
sw=s1+s2;
w=(sw^-1)*(m1-m2)';
y1=w'*a4';%投影后的样本值
y2=w'*b4';
wo=(mean(y1)+mean(y2))/2%阈值
y3=w'*a1';
y4=w'*b1';
k1=0;%第二类测试准确个数
k2=0;%第三类测试准确个数
for i=1:15
if(y3(i)>wo)
k1=k1+1;
end
end
for i=1:15
if(y4(i)<wo)
k2=k2+1;
end
end
v=(k1+k2)/30;%准确率
V=[V,v];
s=mean(V)%平均准确率
end
S1=[S1,s];
end
需要数据集可评论邮箱















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









