







动机
实现高分辨率的图像生成
网络结构
在pix2pix的基础上,增加了一个“从糙到精生成器(coarse-to-fine generator)”、一个多尺度鉴别器架构和一个健壮的对抗学习目标函数。
从糙到精生成器
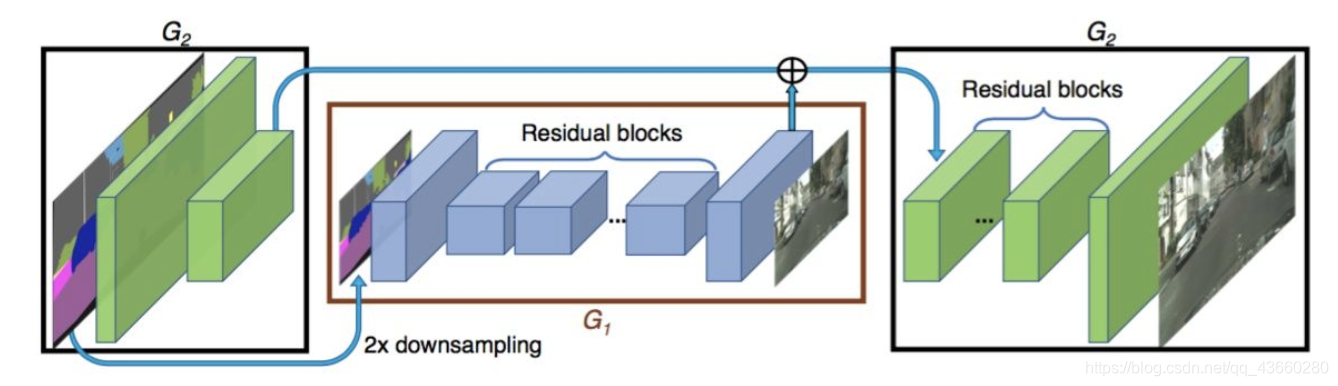
生成器包含G1和G2两个子网络,G1是全局生成网络,G2是局部增强网络。
在训练时,先训练全局生成器G1,然后训练局部增强器G2,然后整体微调所有网络的参数 。
- G2又被割裂成两个部分。G1和pix2pix的生成器没有差别,就是一个end2end的U-Net结构。G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加融合信息,把融合后的信息送入G2的后半部分输出高分辨率图像。
- G1计算的分辨率是1024×512,而G2将输出图像的分辨率扩大到4倍,也就是横向纵向分别乘以2,2048×1024。
如果想生成分辨率更高的图片,可以再继续增加局部增强网络的个数,输出4096×2048的图。
多尺度鉴别器
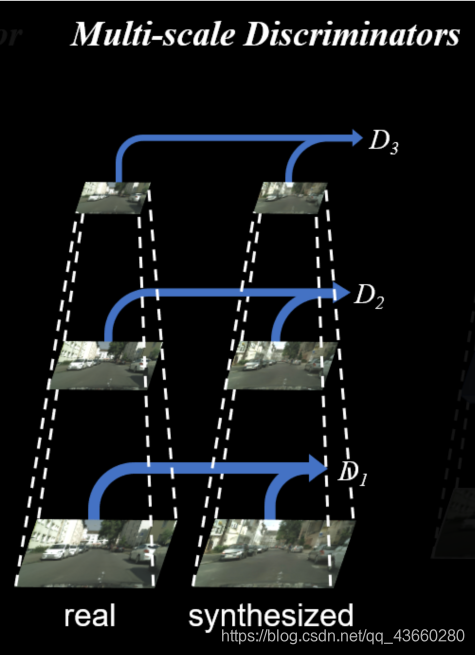
判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。
判别的三个尺度为:原图,原图的1/2降采样,原图的1/4降采样(实际做法为在不同尺度的特征图上进行判别,而非对原图进行降采样)。
如上图所示,这三个鉴别器D1、D2和D3有着相同的网络结构,但是在不同尺寸的图像上进行训练。通过对高分辨率图像进行两次降低采样,生成3种大小的图像,然后训练鉴别器D1、D2和D3分别来辨别这3种尺寸图像的真假。
最粗糙尺度上的鉴别器感受野最大,越关注全局一致性,负责让图像全局和谐,最精细尺度的鉴别器负责引导生成器生成出精致的细节。
创新点
改进的损失函数
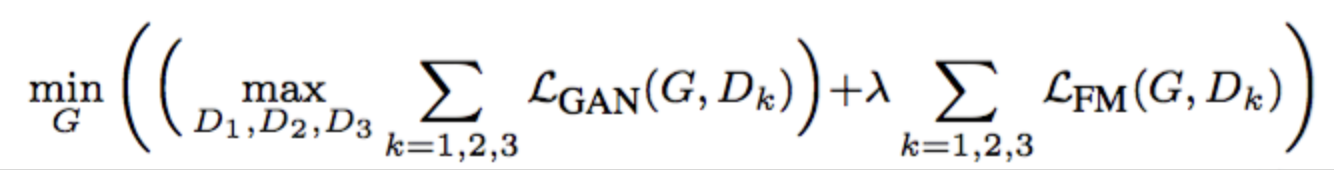
总的损失函数为对抗损失(Loss GAN)、特征匹配损失(Feature matching loss)和内容损失(Content loss):
- GAN loss:和pix2pix一样,使用PatchGAN。
- Feature matching loss:将生成的样本和Ground truth分别送入判别器提取特征,然后对特征做Element-wise loss
- Content loss:将生成的样本和Ground truth分别送入VGG16提取特征,然后对特征做Element-wise loss
Feature matching loss和Content loss只保证内容一致,细节则由GAN去学习
为什么算两个特征的loss呢?
因为一个是自己的判别器提取的特征的loss,相当于“自检”; 一个是别的网络提取的特征算loss,相当于“他检”。
使用Instance-map的图像进行训练
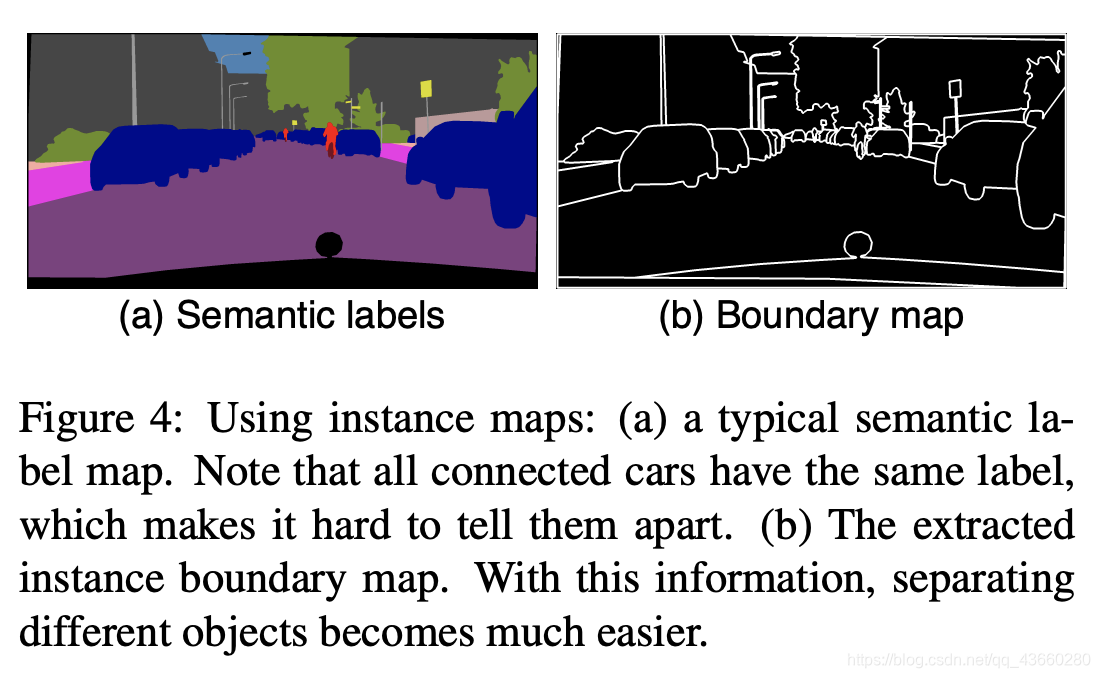
pix2pix采用语义分割的结果进行训练,可是语义分割结果没有对同类物体进行区分,导致多个同类物体排列在一起的时候出现模糊,这在街景图中尤为常见。在这里,作者使用实例分割(Instance-level segmention) 的结果来进行训练,因为实例分割的结果提供了同一类物体的边界信息。具体做法如下:
- 根据实例分割的结果求出Boundary map
- 将Boundary map与输入的语义标签concat到一起作为输入。
Boundary map求法很简单,直接遍历每一个像素,判断其4邻域像素所属语义类别信息。全部相同则置为0;如果有不同,则置为1。
语义编辑
不同于pix2pix实现生成多样性的方法(使用Dropout),这里采用了一个非常巧妙的办法,即学习一个条件(Condition)作为条件GAN的输入,不同的输入条件就得到了不同的输出,从而实现了多样化的输出,而且还是可编辑的。具体做法如下:
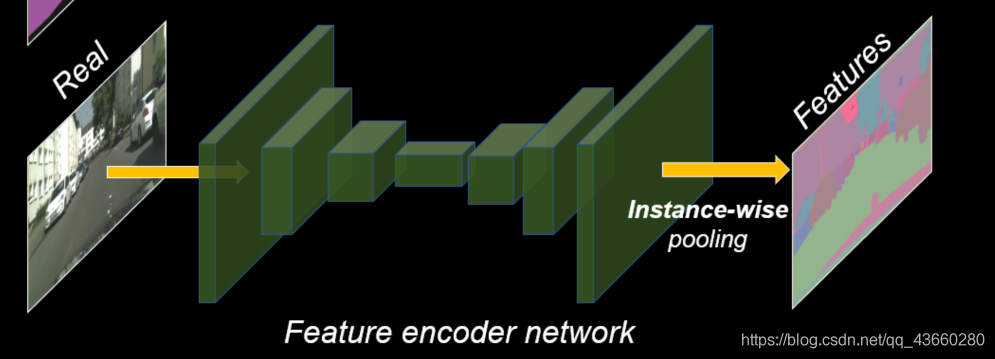
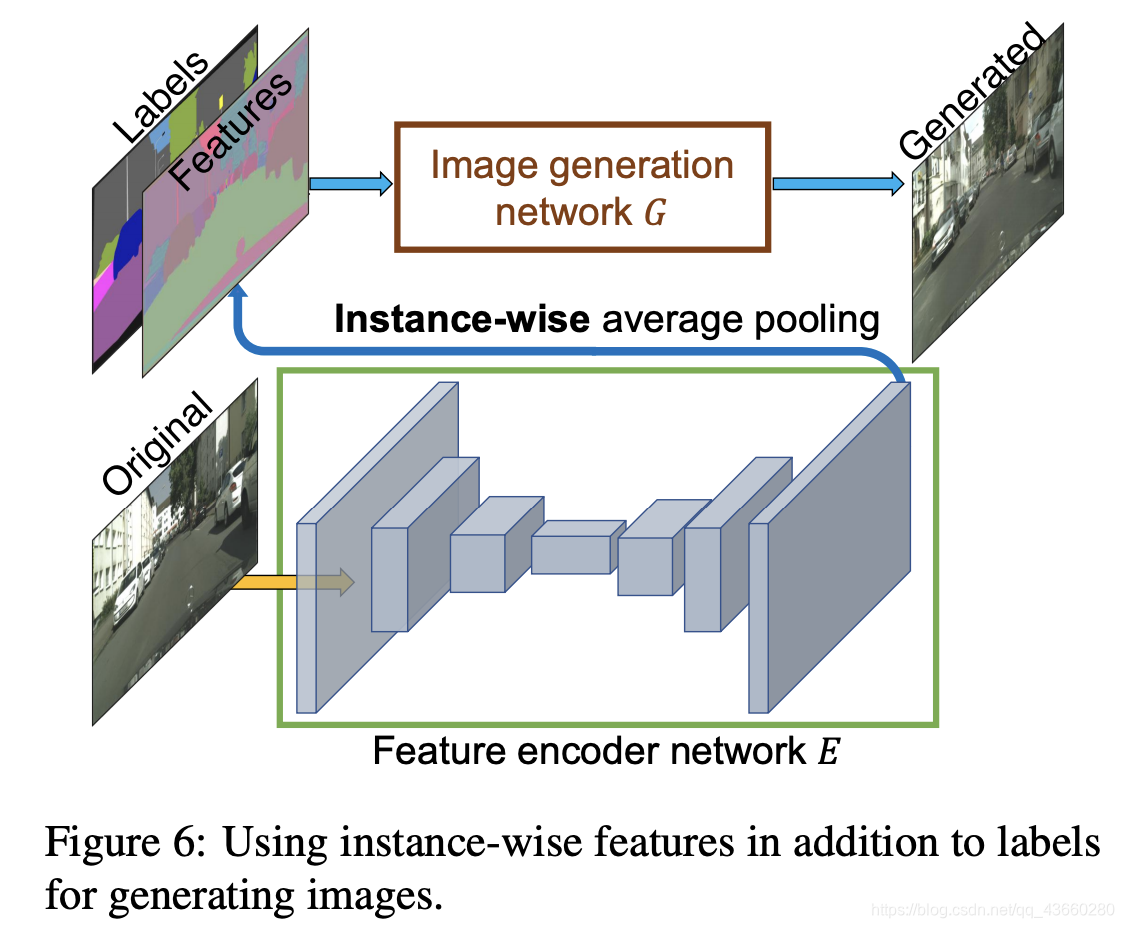
- 首先训练一个编码器
- 利用编码器提取原始图片的特征,进行Average pooling,得到特征(上图的Features)。这个Features的每一类像素的值都代表了这类标签的信息。
- 如果输入图像有足够的多,那么Features的每一类像素的值就代表了这类物体的先验分布。 对所有输入的训练图像通过编码器提取特征,然后进行K-means聚类,得到K个聚类中心,以K个聚类中心代表不同的颜色,纹理等信息。
- 实际生成图像时,除了输入语义标签信息(labels),还要从K个聚类中心随机选择一个,即选择一个颜色/纹理风格(即Features,从编码器提取过来的特征)
这个方法总的来说非常巧妙,通过学习数据的隐变量达到控制图像颜色纹理风格信息。
总结
作者主要的贡献在于:
- 提出了生成高分辨率图像的多尺度网络结构,包括生成器,判别器
- 通过Boundary map提升生成重叠物体的清晰度
- 提出了Feature loss和VGG loss提升图像的分辨率
- 通过学习隐变量达到控制图像颜色,纹理风格信息,交互式的语义编辑方式
参考文献:
- https://arxiv.org/abs/1711.11585v1
- https://zhuanlan.zhihu.com/p/56808180
- https://zhuanlan.zhihu.com/p/31627466

















 2288
2288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









