





所谓图像翻译,指从一副图像到另一副图像的转换。可以类比机器翻译,一种语言转换为另一种语言。下图就是一些典型的图像翻译任务:比如语义分割图转换为真实街景图,灰色图转换为彩色图,白天转换为黑夜......

本文主要介绍图像翻译的三个比较经典的模型pix2pix,pix2pixHD, vid2vid。pix2pix提出了一个统一的框架解决了各类图像翻译问题,pix2pixHD则在pix2pix的基础上,较好的解决了高分辨率图像转换(翻译)的问题,vid2vid则在pix2pixHD的基础上,较好的解决了高分辨率的视频转换问题。三个模型一步一个脚印,不断改进。
1、pix2pix
论文:pix2pix 代码:GitHub
本文最大的贡献在于提出了一个统一的框架解决了图像翻译问题。
在这篇paper里面,作者提出的框架十分简洁优雅(好用的算法总是简洁优雅的)。相比以往算法的大量专家知识,手工复杂的loss。这篇paper非常粗暴,使用CGAN处理了一系列的转换问题。
上面展示了许多有趣的结果,比如分割图
简单粗暴的办法
最直接的想法就是,设计一个CNN网络,直接建立输入-输出的映射,就像图像去噪问题一样。可是对于上面的问题,这样做会带来一个问题。生成图像质量不清晰。
拿下图第二排的分割图

如何解决模糊呢?
这里作者想了一个办法,即加入GAN的Loss去惩罚模型。GAN相比于传统生成式模型可以较好的生成高分辨率图片。思路也很简单,在上述直观想法的基础上加入一个判别器,判断输入图片是否是真实样本。模型示意图如下:

上图模型和CGAN有所不同,但它是一个CGAN,只不过输入只有一个,这个输入就是条件信息。原始的CGAN需要输入随机噪声,以及条件。这里之所有没有输入噪声信息,是因为在实际实验中,如果输入噪声和条件,噪声往往被淹没在条件C当中,所以这里直接省去了。
其他tricks
从上面两点可以得到最终的Loss由两部分构成:
- 输出和标签信息的L1 Loss。
- GAN Loss - 测试也使用Dropout,以使输出多样化
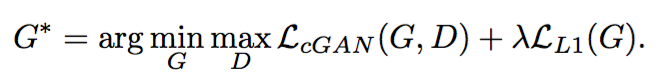
采用L1 Loss而不是L2 Loss的理由很简单,L1 Loss相比于L2 Loss保边缘(L2 Loss基于高斯先验,L1 Loss基于拉普拉斯先验)。
GAN Loss为LSGAN的最小二乘Loss,并使用PatchGAN(进一步保证生成图像的清晰度)。PatchGAN将图像换分成很多个Patch,并对每一个Patch使用判别器进行判别(实际代码实现有更取巧的办法,实际是这样实现的:假设输入一张256x256的图像到判别器,输出的是一个4x4的confidence map,每一个像素值代表当前patch是真实图像的置信度。感受野就是当前的图像patch),将所有Patch的Loss求平均作为最终的Loss。
2、pix2pixHD
论文:pix2pixHD 代码:GitHub
这篇paper作为pix2pix的改进版本,如其名字一样,主要是可以产生高分辨率的图像。具体来说,作者的贡献主要在以下两个方面:
- 使用多尺度的生成器以及判别器等方式从而生成高分辨率图像。
- 使用了一种非常巧妙的方式,实现了对于同一个输入,产生不同的输出。并且实现了交互式的语义编辑方式,这一点不同于pix2pix中使用dropout保证输出的多样性。
高分辨率图像生成
为了生成高分辨率图像,作者主要从三个层面做了改进:
- 模型结构
- Loss设计
- 使用Instance-map的图像进行训练。
模型结构
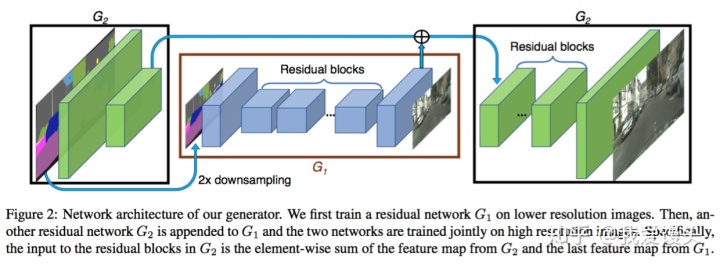
生成器由两部分组成,G1和G2,其中G2又被割裂成两个部分。G1和pix2pix的生成器没有差别,就是一个end2end的U-Net结构。G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加融合信息,把融合后的信息送入G2的后半部分输出高分辨率图像。
判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。判别的三个尺度为:原图,原图的1/2降采样,原图的1/4降采样(实际做法为在不同尺度的特征图上进行判别,而非对原图进行降采样)。显然,越粗糙的尺度感受野越大,越关注全局一致性。
生成器和判别器均使用多尺度结构实现高分辨率重建,思路和PGGAN类似,但实际做法差别比较大。
Loss设计
这里的Loss由三部分组成:
- GAN loss:和pix2pix一样,使用PatchGAN。
- Feature matching loss:将生成的样本和Ground truth分别送入判别器提取特征,然后对特征做Element-wise loss
- Content loss:将生成的样本和Ground truth分别送入VGG16提取特征,然后对特征做Element-wise loss

使用Feature matching loss和Content loss计算特征的loss,而不是计算生成样本和Ground truth的MSE,主要在于MSE会造成生成的图像过度平滑,缺乏细节。Feature matching loss和Content loss只保证内容一致,细节则由GAN去学习。
使用Instance-map的图像进行训练
pix2pix采用语义分割的结果进行训练,可是语义分割结果没有对同类物体进行区分,导致多个同一类物体排列在一起的时候出现模糊,这在街景图中尤为常见。在这里,作者使用个体分割(Instance-level segmention)的结果来进行训练,因为个体分割的结果提供了同一类物体的边界信息。具体做法如下:
- 根据个体分割的结果求出Boundary map
- 将Boundary map与输入的语义标签concatnate到一起作为输入 Boundary map求法很简单,直接遍历每一个像素,判断其4邻域像素所属语义类别信息,如果有不同,则置为1。下面是一个示例:

语义编辑
不同于pix2pix实现生成多样性的方法(使用Dropout),这里采用了一个非常巧妙的办法,即学习一个条件(Condition)作为条件GAN的输入,不同的输入条件就得到了不同的输出,从而实现了多样化的输出,而且还是可编辑的。具体做法如下:

- 首先训练一个编码器
- 利用编码器提取原始图片的特征,然后根据Labels信息进行Average pooling,得到特征(上图的Features)。这个Features的每一类像素的值都代表了这类标签的信息。
- 如果输入图像有足够的多,那么Features的每一类像素的值就代表了这类物体的先验分布。 对所有输入的训练图像通过编码器提取特征,然后进行K-means聚类,得到K个聚类中心,以K个聚类中心代表不同的颜色,纹理等信息。
- 实际生成图像时,除了输入语义标签信息,还要从K个聚类中心随机选择一个,即选择一个颜色/纹理风格
这个方法总的来说非常巧妙,通过学习数据的隐变量达到控制图像颜色纹理风格信息。
总结
作者主要的贡献在于:
- 提出了生成高分辨率图像的多尺度网络结构,包括生成器,判别器
- 提出了Feature loss和VGG loss提升图像的分辨率 - 通过学习隐变量达到控制图像颜色,纹理风格信息
- 通过Boundary map提升重叠物体的清晰度
可以看出,这篇paper除了第三点,都是针对性的解决高分辨率图像生成的问题的。可是本篇工作只是生成了高分辨率的图像,那对于视频呢?接下来会介绍Vid2Vid,这篇paper站在pix2pixHD的基础上,继续做了许多拓展,特别是针对视频前后帧不一致的问题做了许多优化。
3、vid2vid
论文:Vid2Vid 代码:项目主页
Vid2Vid作为pix2pix, pix2pixHD的改进版本,重点解决了视频到视频转换过程中的前后帧不一致性问题。
视频生成的难点
GAN在图像生成领域虽然研究十分广泛,然而在视频生成领域却还存在许多问题。主要原因在于生成的视频很难保证前后帧的一致性,容易出现抖动。对于视频问题,最直观的想法便是加入前后帧的光流信息作为约束,Vid2Vid也不例外。由于Vid2Vid建立在pix2pixHD基础之上,加入时序约束。因此可以实现高分辨率视频生成
作者给出的方案
- 生成器加入光流约束
- 判别器加入光流信息
- 对前景、背景分别建模
3.1 对生成器加入光流约束
符号定义:
- 输入图像序列:
- 目标图像序列:
- 生成的图像序列:
视频-视频转换问题可以建模为如下一个条件分布:
那么我们可以训练一个CNN,将条件分布
上面这个公式有三个未知量
-
表示t-1帧到t帧的光流,光流的计算通过学习一个CNN来实现。
-
表示利用t-1帧光流信息预测得到的第t帧的输出
-
表示当前帧的输出结果,也是利用CNN来实现。
-
表示输出结果的模糊程度。
最终输出的结果由
这个其实很简单,用
第一点改进就是这些啦。下面说一下第二点。 3.2 对判别器器加入光流约束
这里作者使用了两个判别器,一个是图像粒度的判别器。这个比较简答,使用CGAN。 另一个是视频粒度的判别器。输入为视频序列及其光流信息,同样输入到CGAN。 3.3 对前景,背景分别建模
对于语义地图转换为街景图这个任务,作者还分别对前景,背景进行建模,以加快收敛速度。具体来说,可以把语义地图中的“行人”,“车辆”当做前景,“树木”,“道路”当做背景。背景通常都是不动的,因此光流计算会很准,所以得到的图像也会很清晰。因此,我们可以设置一个mask,控制前景和背景的透明度。具体公式如下:
整个文章的idea就是上述三点了。对于前两点,在视频生成领域非常有借鉴意义。















 1642
1642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









