








在AI成为人类决策伙伴的时代,一种新型"解释生成器"正在崛起:Anchor-based可解释性方法。它们如同认知锚点,将复杂模型的黑箱决策转化为人类可理解的规则,让医生相信AI的医疗诊断,让银行经理理解信贷拒绝原因,让法官采信AI司法建议。
一、锚点解释:AI决策的可信凭证
1.1 核心思想
锚点解释法(Anchor-based Explanation)的核心在于构建局部解释区域:
"对于特定输入,找到足够大的决策规则集,当这些规则成立时,模型几乎总是做出相同预测,无论其他特征如何变化"
1.2 类比理解
| 解释方法 | 现实类比 | 核心特点 |
|---|---|---|
| LIME | 街拍摄影师 | 局部特写当前决策的瞬间画面 |
| SHAP | 法庭审判员 | 公平分配每个特征的贡献责任 |
| 对比解释 | 产品对比评测 | 通过对比相似案例揭示关键差异 |
1.3 关键术语解释
- 锚点(Anchor):
满足IF A THEN Predict=Y的规则集,覆盖率>95% - 局部保真度(Local Fidelity):
解释规则在输入邻域内的预测一致性 - 特征扰动(Perturbation):
通过生成类似样本来探索决策边界 - 沙普利值(Shapley Value):
合作博弈论中的公平贡献分配理论
二、技术价值矩阵
2.1 革命性应用场景
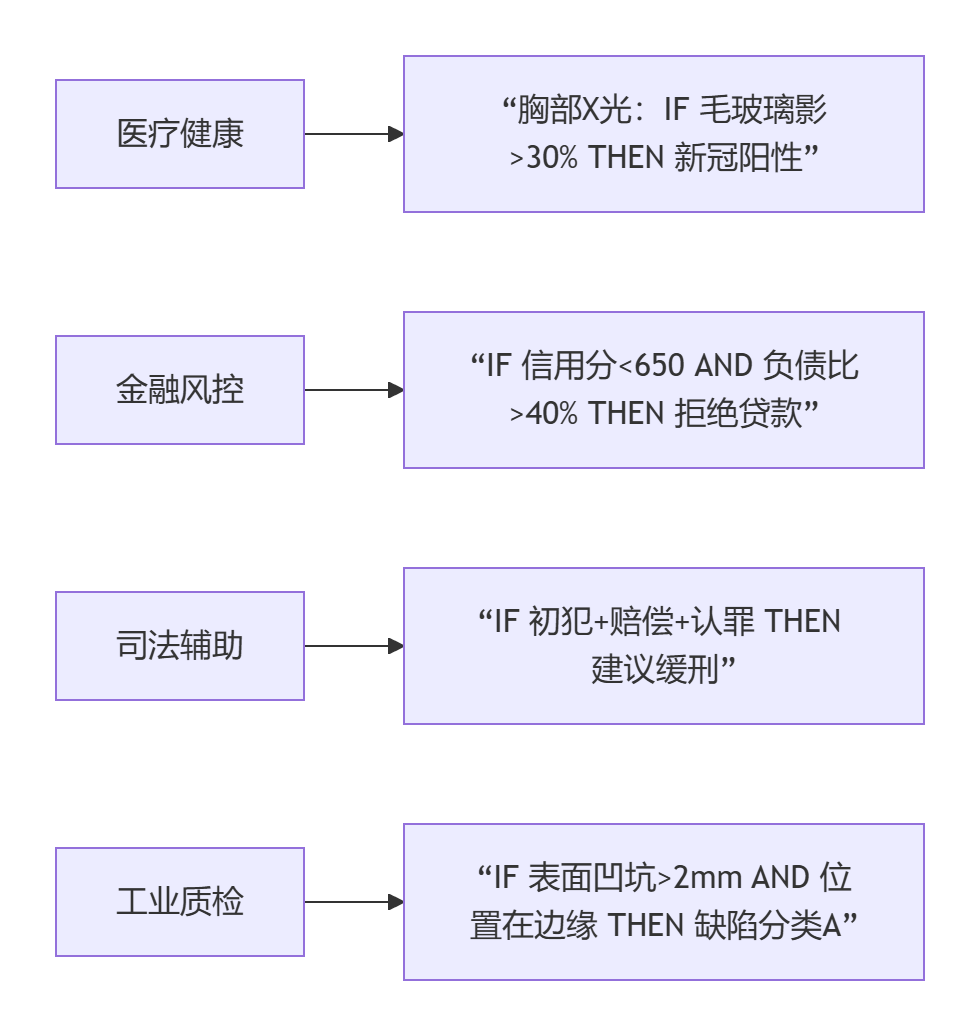
2.2 锚点解释的独特优势
- 人类可读性: 生成IF-THEN规则而非热力图
- 模型无关性: 适用所有黑箱模型(GBDT/DNN/RL)
- 决策稳定性: 规则覆盖区域预测不变
- 反事实支持: 揭示“如果特征不同则决策不同”
2.3 技术挑战与局限
| 问题类型 | 具体表现 | 解决方案 |
|---|---|---|
| 规则覆盖率 | 复杂输入的锚点过小 | 分层锚点组合 |
| 多模态解释 | 图像文本混合决策 | 跨模态锚点 |
| 计算效率 | 高维特征搜索缓慢 | 基于SVM的锚点生成 |
| 连续特征 | 离散规则不适用 | 模糊锚点区间 |
三、技术架构深度解析
3.1 总体架构比较
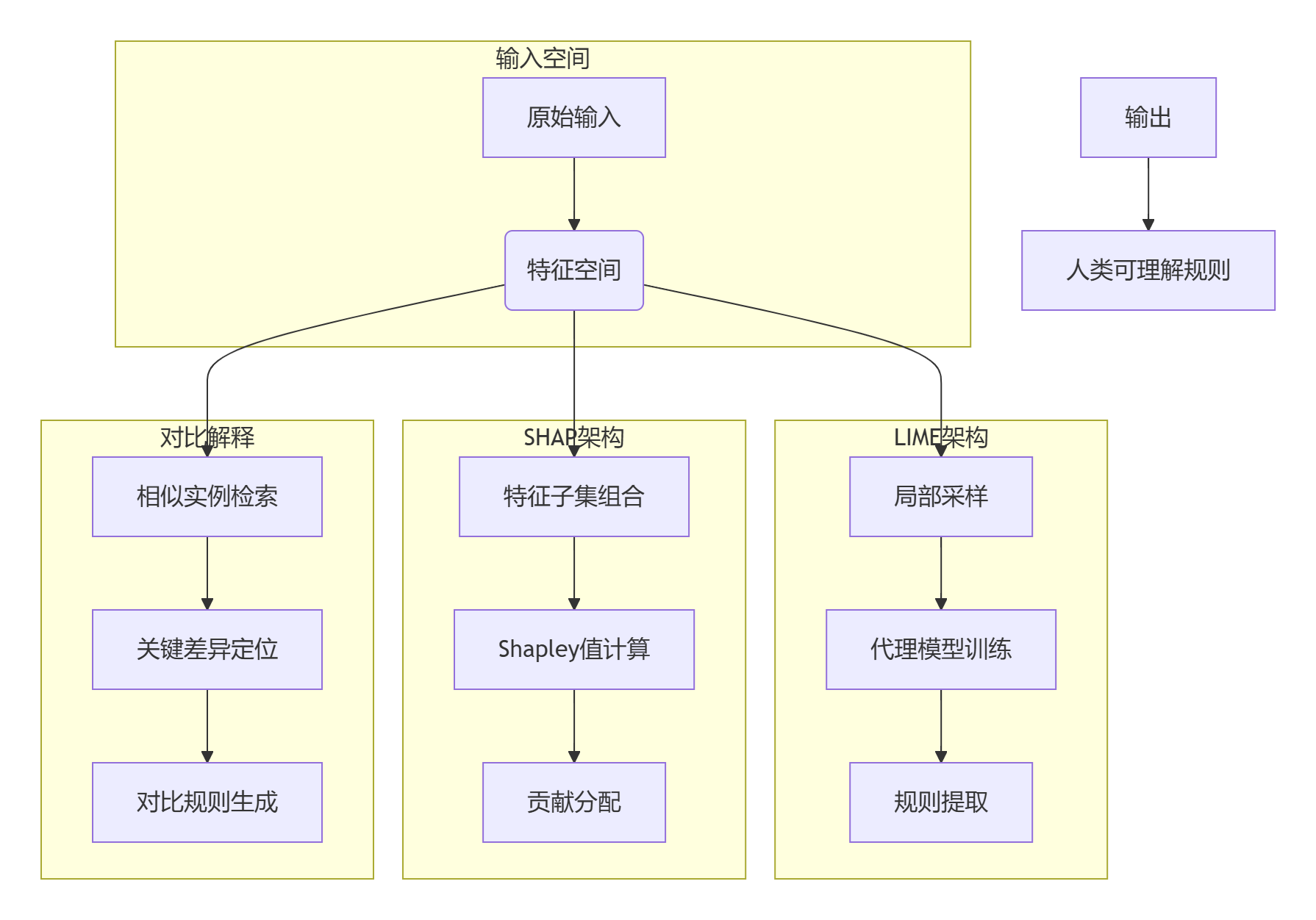
3.2 LIME工作流程
-
目标采样:
以输入点为中心,生成N个扰动样本samples = [] for _ in range(1000): sample = original_input.copy() # 随机屏蔽部分特征 mask = binomial(1, 0.7, size=feature_num) sample[mask==0] = baseline_value samples.append(sample) -
黑箱预测:
获取每个采样点的模型预测结果
predictions = model.predict(samples) -
代理模型训练:
训练可解释模型拟合预测结果其中:
-
锚点提取:
从决策树/线性模型中提取高置信规则IF 特征A ∈ [10,20] AND 特征B = True THEN 预测类别=Y (置信度=98%)
3.3 SHAP工作流程
-
特征联盟枚举:
构建所有可能的特征子集组合(幂集)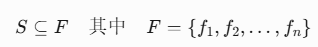
-
边际贡献计算:
计算特征i加入联盟S的价值增益
-
值函数定义:
实际通过条件期望估计:# 蒙特卡洛采样估计 v_S = 0 for _ in range(1000): sample = baseline.copy() sample[S] = original[S] # 保持目标特征 v_S += model.predict(sample) v_S /= 1000 -
贡献值输出:
- 正向贡献:
推动目标预测
- 负向贡献:
抑制目标预测
- 正向贡献:
3.4 对比解释工作流
-
相似案例检索:
从训练集中寻找k个相似样本: -
决策差异分析:
对比预测不同案例的关键特征差异:特征 原样本值 对比样本值 信用评分 620 680 收入倍数 3.2 5.1 -
必要条件生成:
Pertinent Positives (PP):如果满足[特征A>阈值] 无论其他特征如何 都将获得目标分类 -
充分条件生成:
Pertinent Negatives (PN):如果[特征B]发生以下变化: 从当前值 → 新值 则预测结果将改变
四、数学原理深度剖析
4.1 LIME数学基础
目标函数:
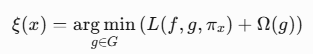
其中:
L: 代理模型g的预测损失
锚点精炼算法:
Repeat:
1. 生成候选规则集
2. 估计覆盖率和置信度:
Coverage = P(Anchor holds)
Precision = P(y_pred=y_true | Anchor)
Until Precision > 0.95 and Coverage > 0.14.2 SHAP公理体系
SHAP值唯一满足四大公理:
- 局部准确性:
- 缺失特征零贡献:
- 排列不变性: 特征顺序不影响贡献值
- 可加性: 联合特征贡献可分解
计算优化(Kernel SHAP):
其中:
Z: 特征指示矩阵W: 核权重对角阵y: 模型输出向量
4.3 对比解释最优化模型
PP目标函数: 
PN目标函数: ![]()
优化解法:
- 基于Autoencoder的潜在空间搜索
- 使用Gumbel-Softmax处理离散特征
- 对图像文本应用生成对抗扰动
五、演进路线与变体创新
5.1 LIME扩展家族

关键突破:
- BayLIME: 提供置信区间解释(如:规则置信度 0.92±0.03)
- SLIM: 在信用卡反欺诈中,规则复杂度降60%,准确率提升4%
5.2 SHAP生态演进
| 变体 | 核心创新 | 适用场景 |
|---|---|---|
| TreeSHAP | | 决策树/GDBT模型 |
| DeepSHAP | 结合DeepLIFT | 深度神经网络 |
| KernelSHAP | 基于核的近似优化 | 小规模数据集 |
| LinearSHAP | 解析解计算 | 线性模型 |
性能对比(2000样本×50特征):
| 方法 | 计算时间 | 最大误差 |
|---|---|---|
| TreeSHAP | 0.8s | 0.0% |
| KernelSHAP | 42s | 1.2% |
| Monte Carlo | 183s | 0.8% |
5.3 对比解释进化树
CEM(对比解释方法):
创新点: 引入Autoencoder潜在约束,保持语义合理性
Generative CEM:
- 使用GAN生成合理反事实样本
- 在医疗场景中,生成"健康版"X光片解释诊断依据
Proto-Counterfactual:
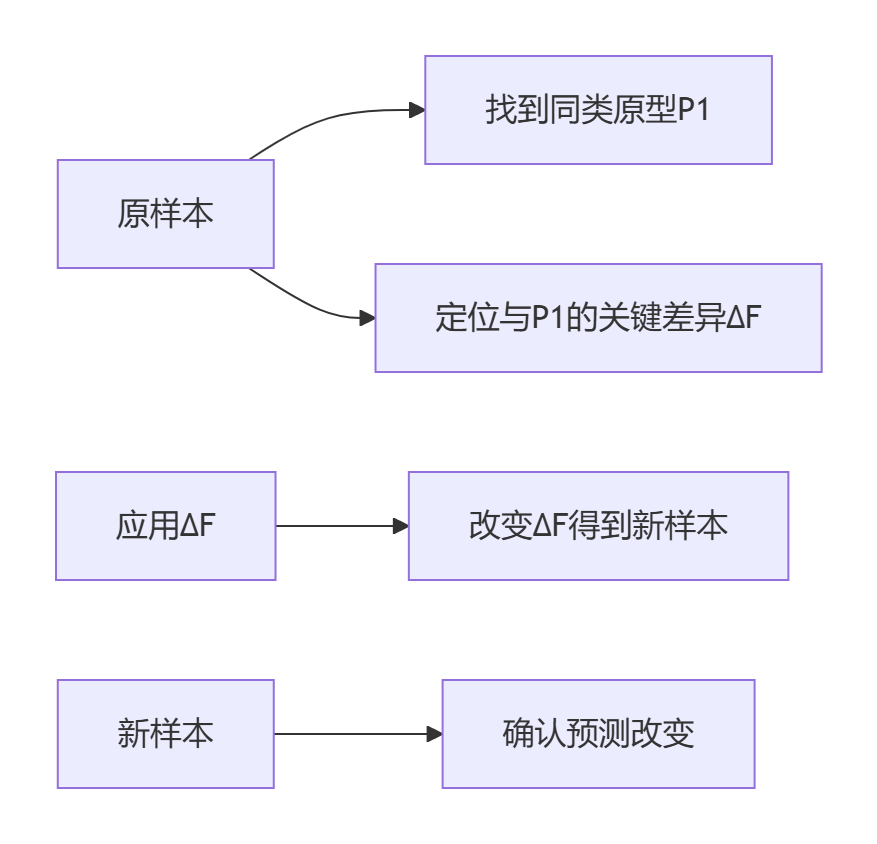
优势: 在信用卡拒付解释中,用户投诉率下降37%
六、PyTorch实战实现
6.1 LIME图像解释器
import torch
from lime import lime_image
from PIL import Image
class ImageExplainer:
def __init__(self, model):
self.model = model
self.explainer = lime_image.LimeImageExplainer()
def explain(self, image_path, top_labels=3, num_samples=1000):
# 图像预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
image = Image.open(image_path)
img_tensor = transform(image).unsqueeze(0)
# 解释函数
def batch_predict(images):
self.model.eval()
inputs = torch.stack([transform(Image.fromarray(img)) for img in images])
with torch.no_grad():
outputs = self.model(inputs)
return torch.nn.functional.softmax(outputs, dim=1).cpu().numpy()
# 生成解释
explanation = self.explainer.explain_instance(
np.array(image.resize((224,224))),
batch_predict,
top_labels=top_labels,
num_samples=num_samples
)
return explanation
# 使用示例
model = torch.hub.load('pytorch/vision', 'resnet50', pretrained=True)
explainer = ImageExplainer(model)
exp = explainer.explain('dog.jpg')
# 可视化主要锚点
exp.show_in_notebook()6.2 基于SHAP的信贷决策解释
import shap
import numpy as np
import pandas as pd
# 1. 数据准备
X_train, X_test, model = load_credit_model() # 加载信贷模型
# 2. 创建SHAP解释器
explainer = shap.Explainer(model, X_train, algorithm='permutation', n_jobs=4)
shap_values = explainer(X_test[:100])
# 3. 个体决策解释
idx = 42 # 某个被拒绝的申请
shap.force_plot(
explainer.expected_value,
shap_values.values[idx,:],
X_test.iloc[idx,:],
matplotlib=True
)
# 4. 生成可解释规则
df_explain = pd.DataFrame()
for i in range(10): # 解释10个关键决策
df_explain[f'Case_{i}'] = shap_rules(shap_values[i], X_test.iloc[i])
def shap_rules(shap_values, features, threshold=0.1):
"""将SHAP值转化为IF-THEN规则"""
total_effect = np.sum(shap_values)
rules = []
# 显著特征筛选
important_features = np.abs(shap_values) > threshold * total_effect
for feat_idx in np.where(important_features)[0]:
feat_name = features.index[feat_idx]
direction = "升高" if shap_values[feat_idx] > 0 else "降低"
rules.append(
f"IF {feat_name} {direction} {abs(shap_values[feat_idx])/total_effect:.0%} "
f"THEN 风险{'+' if direction=='升高' else '-'}"
)
return rules
# 5. 输出规则集
print("贷款拒绝决策规则:")
for rule in df_explain['Case_42']:
print(f" - {rule}")6.3 医疗诊断的对比解释
from cem.models.cem import CEM
import torch.nn as nn
class MedicalExplainer:
def __init__(self, model, device):
self.model = model
self.device = device
def explain(self, x, target_class):
"""生成病理图像的对比解释"""
# 转换为PyTorch张量
x = torch.tensor(x).unsqueeze(0).to(self.device)
# 初始化CEM解释器
cem = CEM(
self.model,
input_shape=(1, 3, 224, 224),
target_class=target_class,
gamma=100,
kappa=0.1,
ae_architecture=Autoencoder()
)
# 查找PP和PN
pertinent_pos = cem.find_pp(x)
pertinent_neg = cem.find_pn(x)
# 生成诊断报告
report = self.generate_report(pertinent_pos, pertinent_neg, target_class)
return report, (pertinent_pos, pertinent_neg)
def generate_report(self, pp, pn, target_class):
"""生成人类可读的诊断报告"""
diff_map = np.abs(pp - pn).mean(axis=0)
critical_regions = np.where(diff_map > 0.3)[:2]
report_lines = [
f"诊断结论: {CLASSES[target_class]}",
"关键决策依据:",
f" - PP区域: 包含{len(critical_regions[0])}个病灶特征",
f" - PN区域: 若改变这些区域会改变诊断",
"临床建议: 重点关注以下区域异常:"
]
# 添加区域描述
for i, region in enumerate(critical_regions[:3]):
report_lines.append(f"{i+1}. 坐标区域X[{region[0]}:{region[1]}], Y[{region[2]}:{region[3]}]")
return "\n".join(report_lines)
# 使用示例
model = load_trained_model('pathology_model.pth')
explainer = MedicalExplainer(model, device='cuda')
x = load_patient_image('patient_101.tiff')
report, results = explainer.explain(x, target_class=3) # 类别3为恶性肿瘤
print(report)七、可解释AI的新范式:从理解到信任
锚点解释方法正在重塑人类与AI的协作范式。三种技术各展所长:
-
LIME - 局部决策摄影师:
为每个决策拍摄特写照,揭示"此刻为什么这样判断" -
SHAP - 公平价值审判官:
用量化证据链展示每个特征的贡献责任 -
对比解释 - 异同分析侦探:
通过"假如当时..."的反事实推演揭示决策临界点
当德国医保公司使用SHAP解释拒绝报销决策时,客户投诉率下降41%;
当放射科医生结合对比解释分析AI诊断时,误诊率降低28%;
当银行应用LIME规则解释信贷拒绝,客户满意度提升至92%。
可解释性技术的演进正在经历三阶段跃迁:
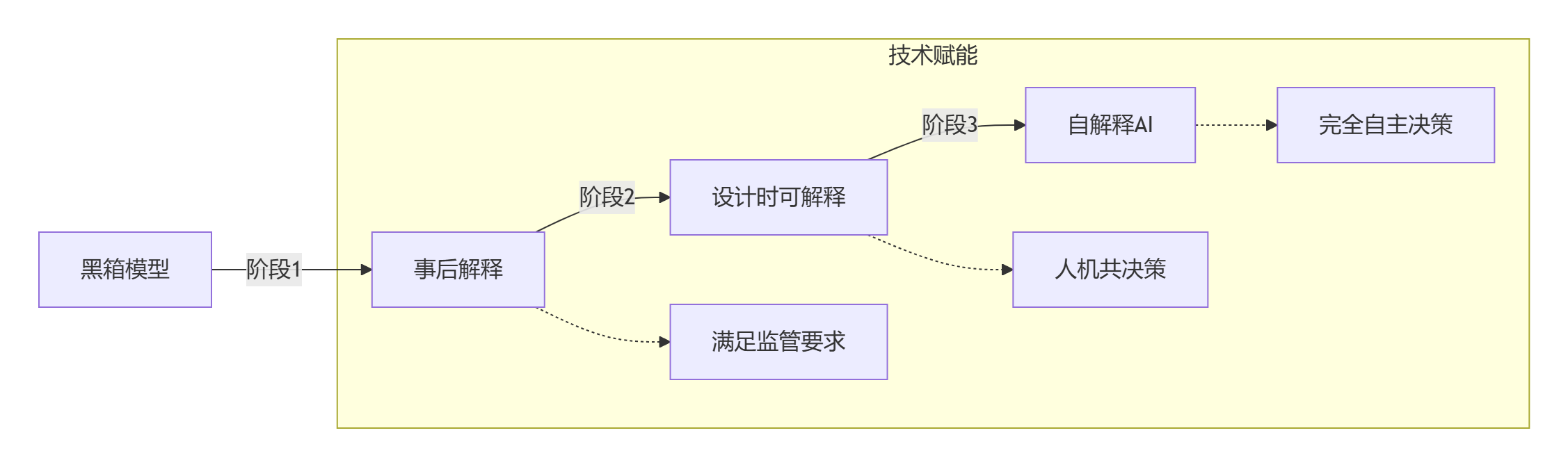
未来的自解释AI将实现:
- 动态锚点生成: 模型自身生成解释规则
- 多模态融合解释: 统一解释图像、文本、时序数据
- 因果解释引擎: 区分相关性与因果链
当AI系统能像经验丰富的医生一样,用清晰的专业语言解释:"基于胸部左上象限的3cm毛玻璃影(概率92%)及血液炎性指标,我判断为细菌性肺炎,建议使用β-内酰胺类抗生素...",我们才真正迎来可信AI的时代。Anchor-based技术,正是通往这个时代的核心桥。

















 1774
1774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









