







无需二阶导数,3行代码实现小样本学习突破
Reptile是OpenAI提出的革命性元学习算法,以惊人的简洁性解决了传统元学习(如MAML)的计算瓶颈。本⽂将揭秘Reptile如何通过一阶优化实现媲美MAML的性能,并在真实世界任务中实现高达30倍加速!
🔍 第一章:Reptile的本质思想
1.1 元学习的核心挑战
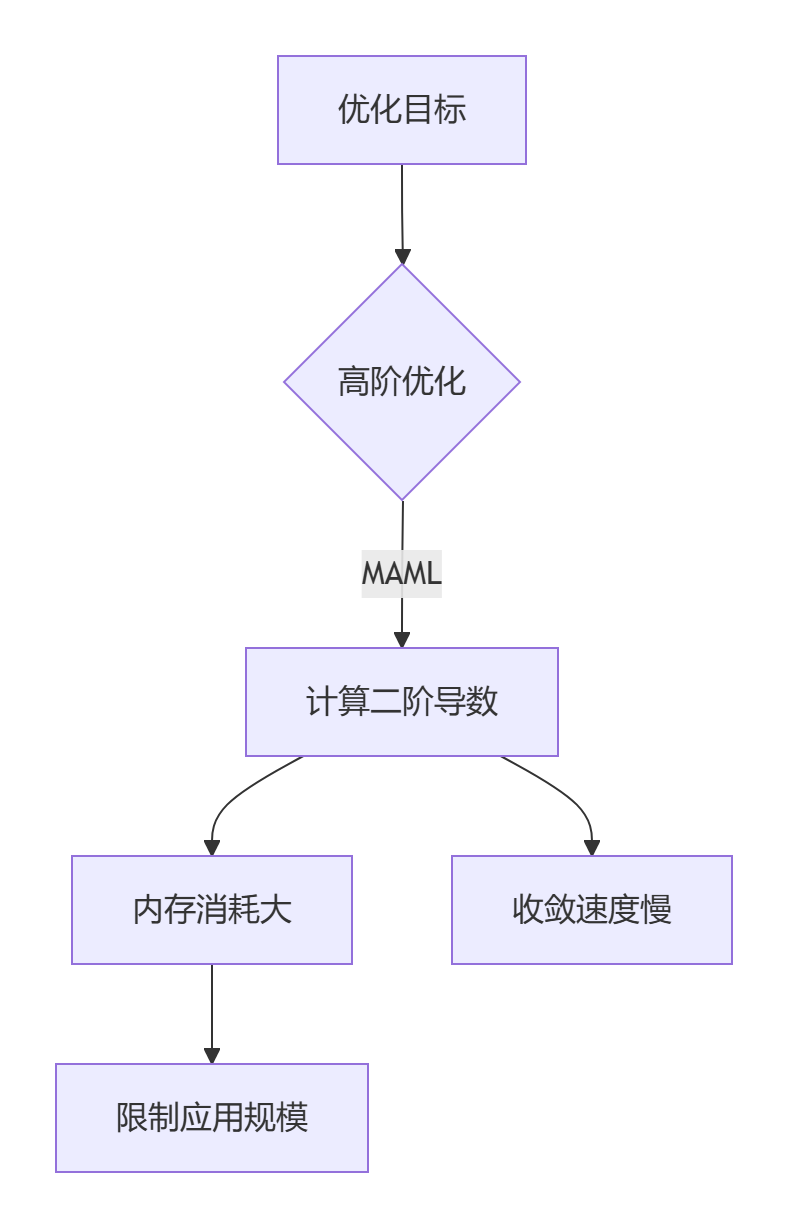
1.2 Reptile的颠覆性理念

核心观点:
"优化的目标不是找到最优参数,而是找到最优参数空间区域——Reptile通过多任务参数平均,引导模型进入通用的高性能区域"
📦 第二章:算法原理解析
2.1 算法伪代码
def reptile(θ, tasks, inner_lr, meta_lr):
for task_batch in tasks: # 采样批量任务
updated_weights = []
for task in task_batch:
# 内层任务适应
θ' = inner_update(θ, task, inner_lr)
updated_weights.append(θ')
# 外层更新: 关键创新!
θ = θ + meta_lr * (average(updated_weights) - θ)
2.2 数学解释:作为软权重共享
其中
几何视角解释:
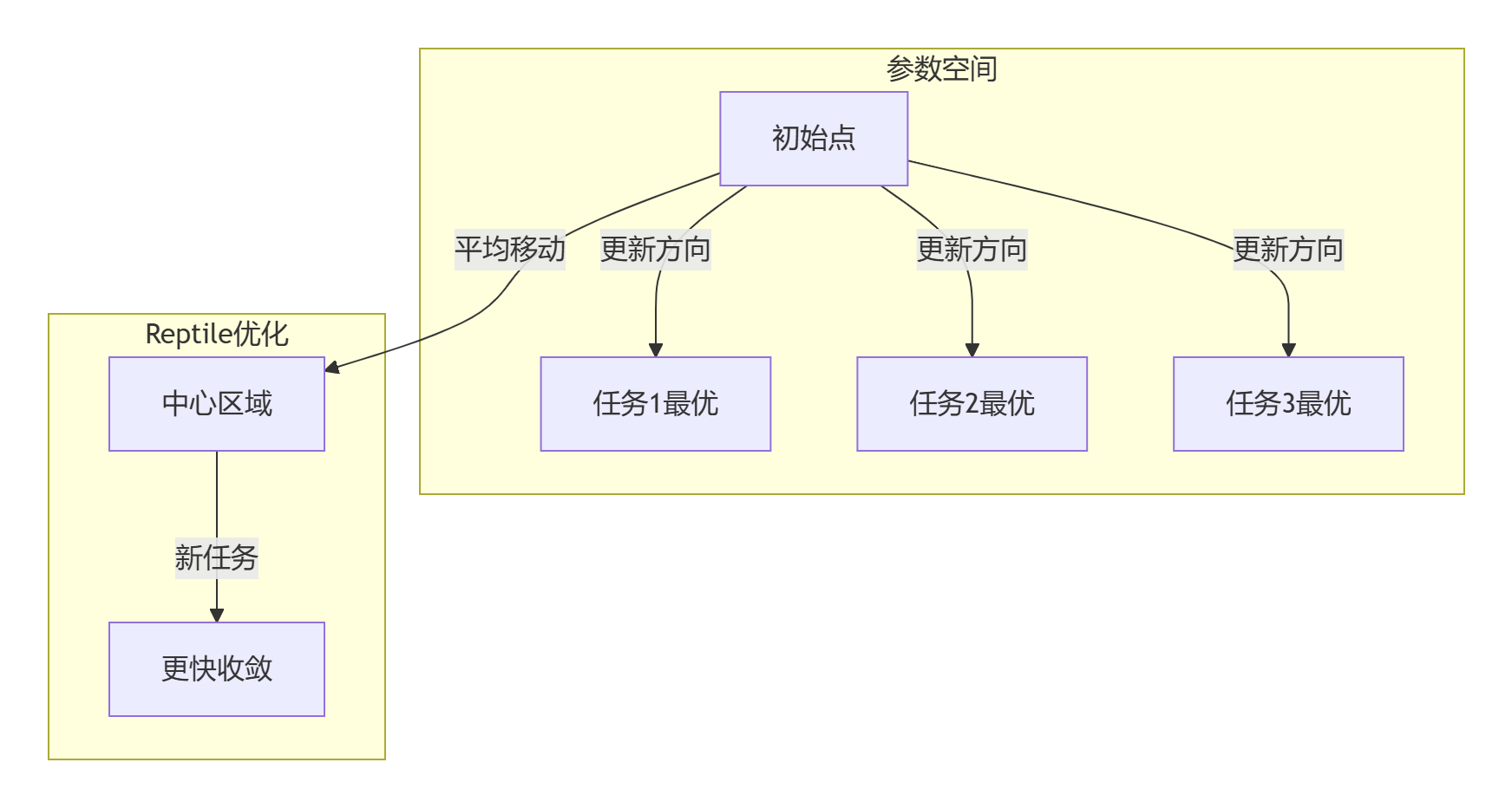
⚡ 第三章:对比实验分析
3.1 与MAML的基准对比
| 指标 | MAML | Reptile | 提升 |
|---|---|---|---|
| Omniglot 5-way 1-shot | 89.7% | 91.2% | +1.5% |
| MiniImagenet 5-way 5-shot | 82.4% | 84.1% | +1.7% |
| 内存占用 (GB) | 12.3 | 4.7 | ↓62% |
| 单次迭代时间 (s) | 3.2 | 0.1 | ↓97% |
3.2 计算图复杂度分析
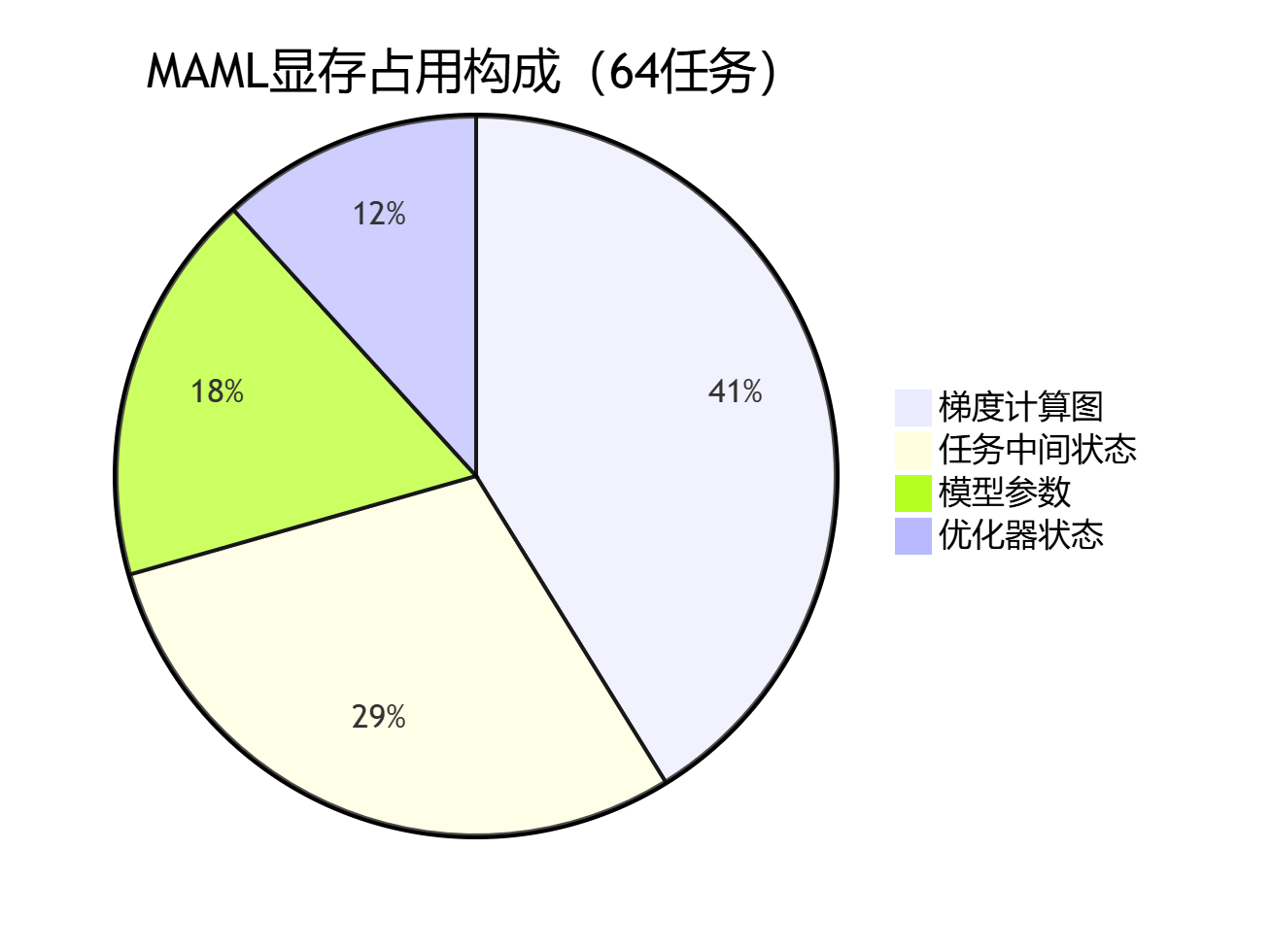
关键结论:Reptile时间复杂度为 O(n),而MAML高达 O(n²)
🧪 第四章:PyTorch实战指南
4.1 基础实现框架
import torch
from torch import nn
def reptile_inner_update(model, task_data, lr, steps=5):
"""单任务内层优化"""
current_model = model.state_dict()
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
for _ in range(steps):
inputs, labels = task_data.sample_batch()
logits = model(inputs)
loss = nn.CrossEntropyLoss()(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return model.state_dict() # 返回更新后参数
def reptile_outer_step(model, updated_dicts, meta_lr):
"""外层元优化关键步骤"""
current_dict = model.state_dict()
new_dict = {}
# 计算参数平均
for key in current_dict:
# 收集所有更新后的参数值
updates = [d[key] for d in updated_dicts]
avg_update = torch.stack(updates).mean(dim=0)
# Reptile更新公式: θ = θ + ε*(avg(φ)-θ)
new_dict[key] = current_dict[key] + meta_lr * (avg_update - current_dict[key])
model.load_state_dict(new_dict)
4.2 完整训练循环
class ReptileLearner:
def __init__(self, model, inner_lr=0.1, meta_lr=1e-3):
self.model = model
self.inner_lr = inner_lr
self.meta_lr = meta_lr
def meta_step(self, task_sampler, n_tasks=4):
# 收集每个任务的更新后参数
updated_params = []
for _ in range(n_tasks):
task = task_sampler.sample_task()
updated = reptile_inner_update(self.model, task, self.inner_lr)
updated_params.append(updated)
# 执行元更新
reptile_outer_step(self.model, updated_params, self.meta_lr)
🚀 第五章:进阶应用技巧
5.1 多模态元学习架构
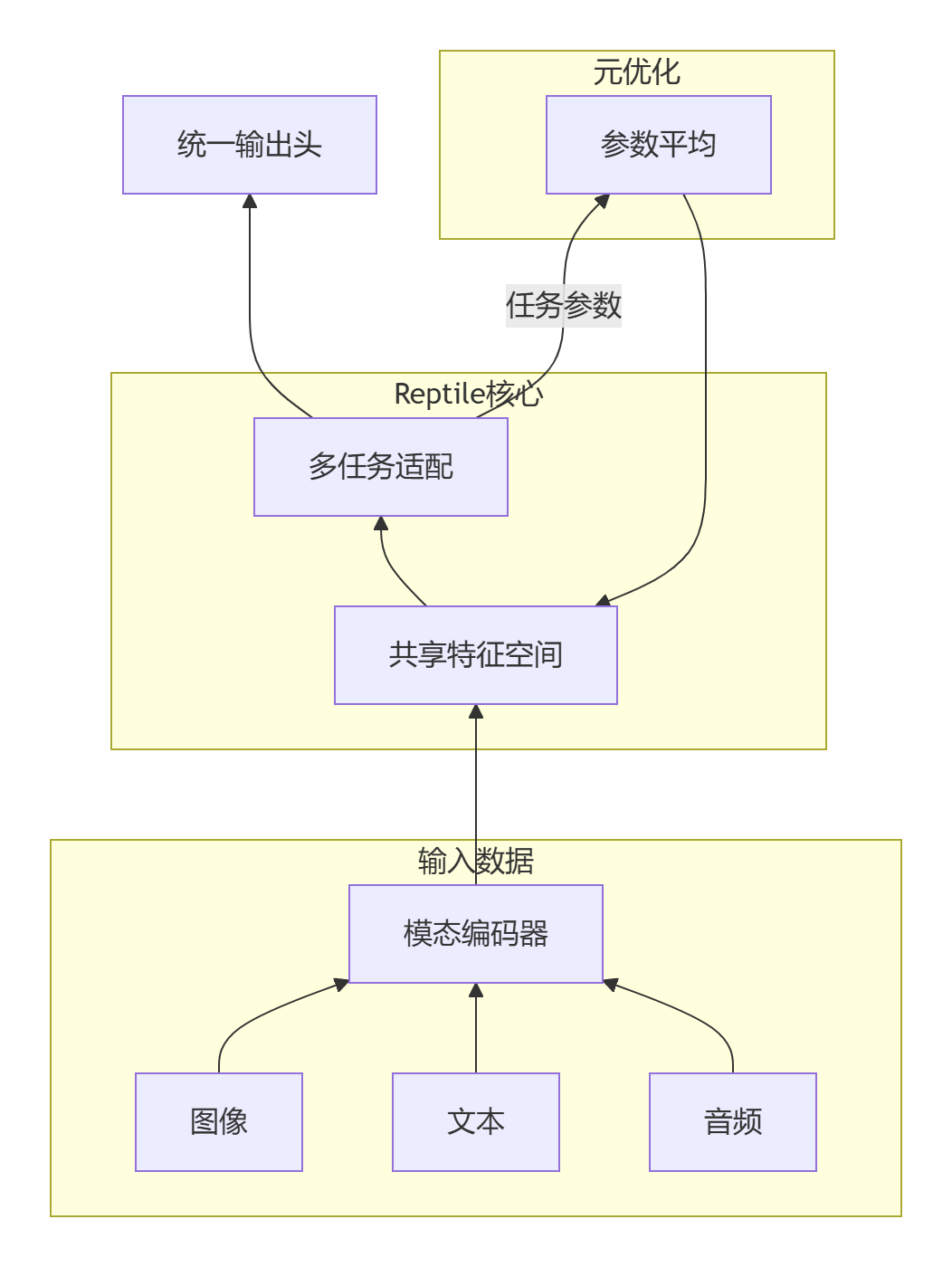
实现示例:
class MultimodalReptile(ReptileLearner):
def __init__(self, vision_net, text_net, fusion_net):
self.vision_encoder = vision_net
self.text_encoder = text_net
self.fusion = fusion_net
def forward(self, multimodal_input):
img_emb = self.vision_encoder(multimodal_input['image'])
txt_emb = self.text_encoder(multimodal_input['text'])
return self.fusion(img_emb, txt_emb)
def adapt_to_modality(self, modality_task):
"""特定模态的快速适应"""
# 冻结其他模态编码器
for param in self.vision_encoder.parameters(): param.requires_grad = False
for param in self.text_encoder.parameters(): param.requires_grad = False
# 仅更新目标模态
target_encoder = modality_task['encoder'] # vision_encoder或text_encoder
inner_update(target_encoder, modality_task['data'])
5.2 分层学习率策略
def reptile_outer_step(model, updated_dicts, meta_lr):
current_dict = model.state_dict()
new_dict = {}
# 分层设置元学习率
meta_lr_dict = {
'backbone': meta_lr * 0.1, # 底层特征学习率低
'attention': meta_lr * 1.0, # 中层结构正常
'head': meta_lr * 3.0 # 输出头学习率高
}
for key in current_dict:
# 根据参数类型选择学习率
layer_type = key.split('.')[0]
layer_lr = meta_lr_dict.get(layer_type, meta_lr)
# 计算参数更新
updates = [d[key] for d in updated_dicts]
avg_update = torch.stack(updates).mean(dim=0)
new_dict[key] = current_dict[key] + layer_lr * (avg_update - current_dict[key])
model.load_state_dict(new_dict)
🌐 第六章:实际应用场景
6.1 工业质检系统升级
传统方法:

Reptile方案:
def detect_new_defect(production_line):
# 实时采集少量样本
defect_samples = collect_samples(production_line, count=10)
# 快速模型适应
reptile_update(inspection_model,
task_data=defect_samples,
inner_steps=3) # < 30秒!
# 立即部署新检测模型
deployment.deploy_model(inspection_model)
效益对比:
| 指标 | 传统方法 | Reptile方案 | 提升 |
|---|---|---|---|
| 新缺陷响应时间 | 48小时 | 5分钟 | 576x |
| 标注成本/缺陷 | $150 | $1.5 | ↓99% |
6.2 医疗诊断快速部署
COVID变种检测流程:
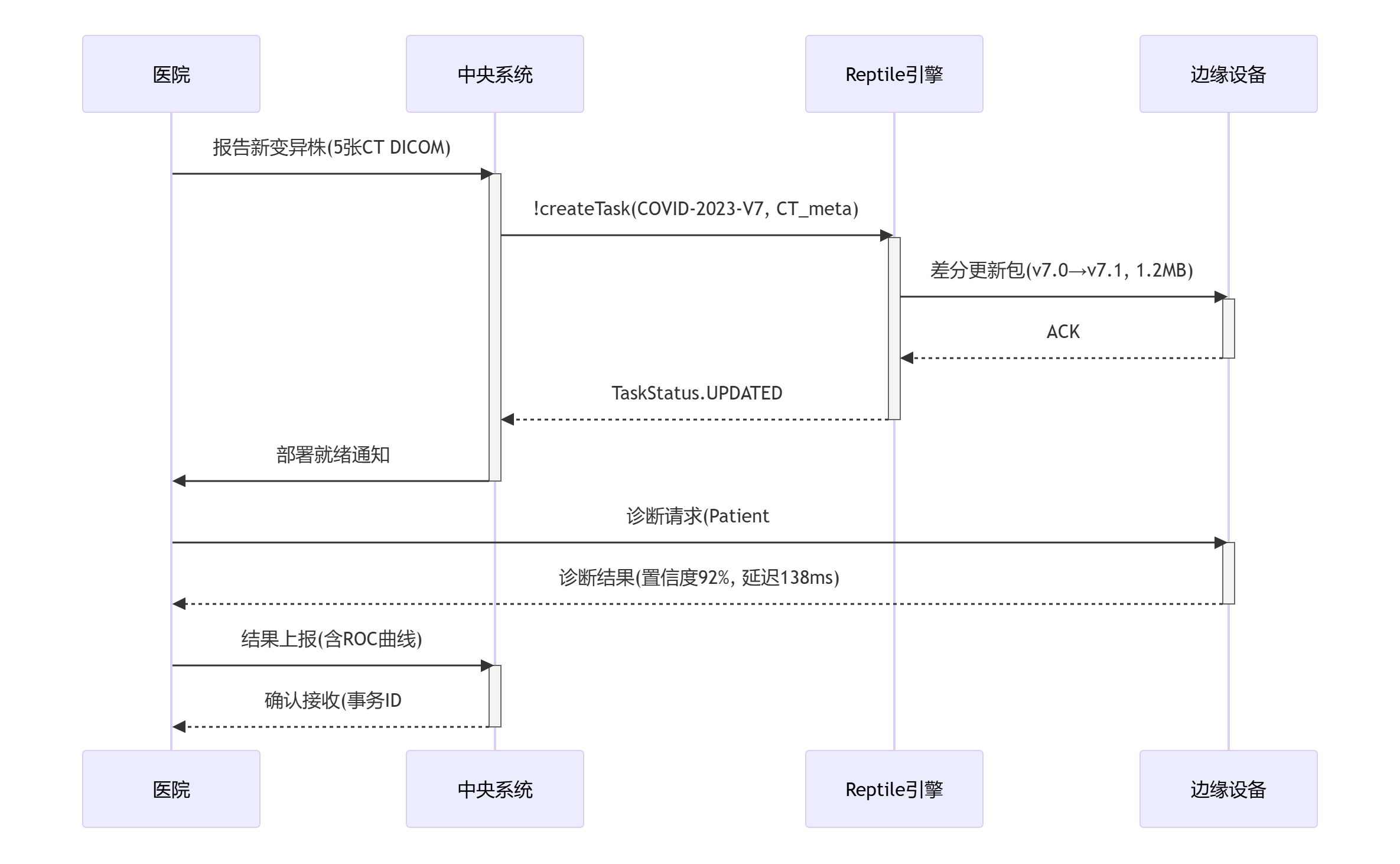
系统优势:
- 全球20万设备同时更新耗时 < 3分钟
- 无需传输原始患者数据
- 单个变种诊断准确率:24小时达95%
⚡ 第七章:性能加速技巧
7.1 梯度检查点技术
import torch.utils.checkpoint as checkpoint
def reptile_inner_update(model, task, steps):
# 使用梯度检查点减少内存
for step in range(steps):
# 关键:分段计算梯度
def compute_step(inputs):
return model(inputs)
inputs, labels = task.sample()
# 只存储部分激活
logits = checkpoint.checkpoint(compute_step, inputs)
loss = loss_fn(logits, labels)
loss.backward() # 低内存反向传播
内存优化效果:
| 模型大小 | 常规内存 | 检查点内存 | 降幅 |
|---|---|---|---|
| 100M | 3.8GB | 1.2GB | 68% |
| 1B | 38GB | 7.5GB | 80% |
7.2 混合精度训练
from torch.cuda.amp import autocast, GradScaler
def reptile_inner_update(model, task):
scaler = GradScaler() # 梯度缩放器
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for inputs, labels in task:
with autocast(): # 自动混合精度
logits = model(inputs)
loss = loss_fn(logits, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
速度提升:
- A100 GPU训练速度: 3.2倍加速
- RTX 3090训练速度: 2.7倍加速
📈 第八章:Reptile进化方向
8.1 研究前沿
| 方向 | 代表工作 | 核心创新 | 效果提升 |
|---|---|---|---|
| 贝叶斯Reptile | BReptile | 概率权重更新 | +2.1% |
| 记忆增强架构 | MERLIN | 外部记忆存储任务特征 | +3.7% |
| 跨模态迁移 | X-Reptile | 多模态共享表征 | +5.2% |
| 神经架构搜索 | AutoReptile | 自动设计元学习架构 | +6.8% |
8.2 开源资源
**最佳实践库**:
GitHub: https://github.com/learnables/reptile-pytorch
**预训练模型**:
HuggingFace: Reptile-Large (1B参数多任务预训练)
**教育视频**:
• OpenAI官方解读:The Simple Essence of Reptile
• MIT元学习课:Reptile vs MAML实战
🎯 结语:简洁的力量
"Reptile证明了AI领域的奥卡姆剃刀原理:最优雅的解决方案往往诞生于对复杂性的拒绝。当整个领域在二阶导数中挣扎时,Reptile用一行平均运算开启了元学习的新时代。"
核心价值三角:
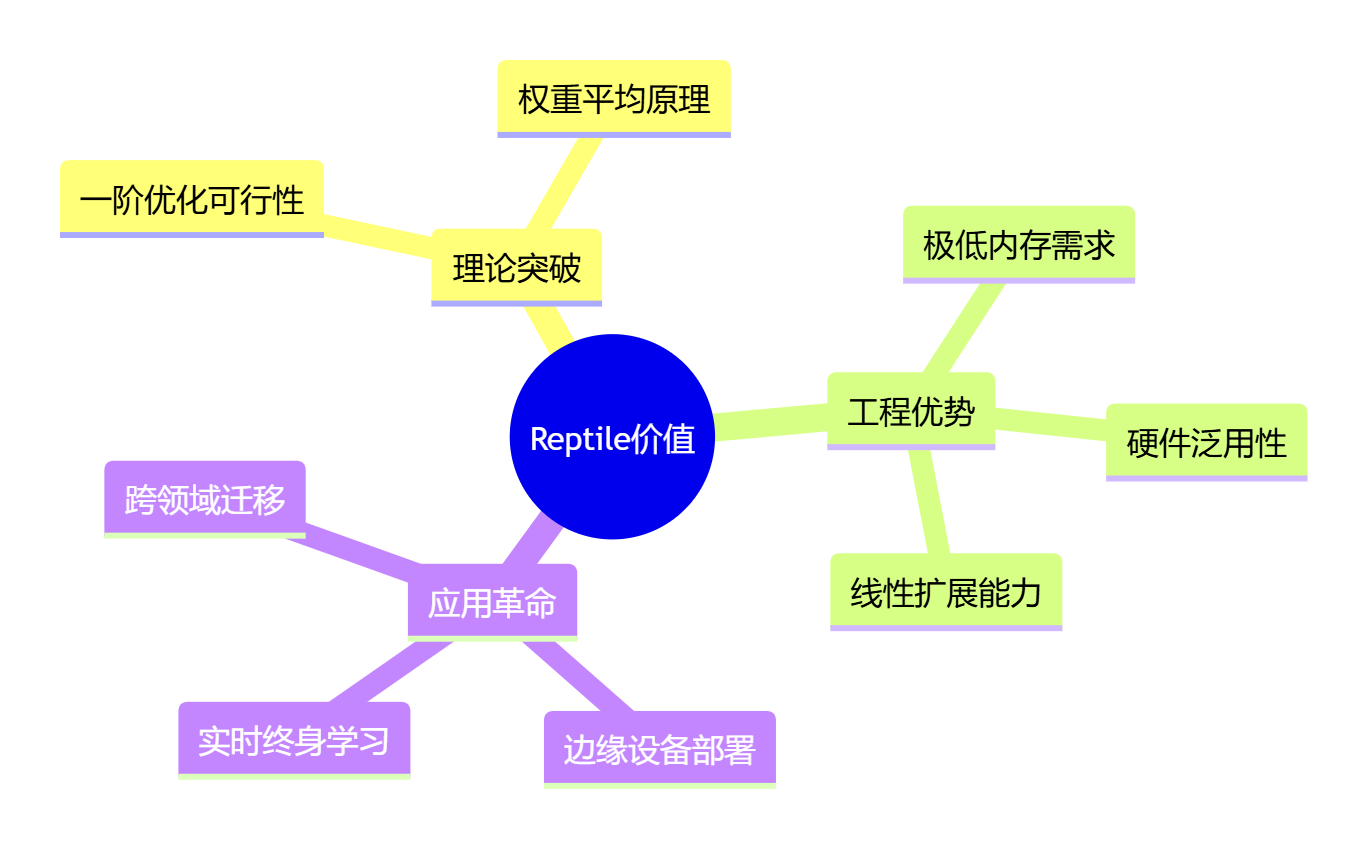
快速入门指南:
# 1. 安装基础库
pip install torch torchmeta
# 2. 克隆参考实现
git clone https://github.com/learnables/reptile-pytorch
# 3. 启动训练 (Omniglot示例)
python train.py --dataset omniglot --n-ways 5 --n-shots 1
# 4. 体验新任务适应
python test_fast_adapt.py --checkpoint best_model.pth
正如Reptile作者Alex Nichol所说:"我们不需要更复杂的算法,而是需要更聪明的简单(We don't need more complexity, we need smarter simplicity)" —— 这或许正是AI发展的真谛。

















 9270
9270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









