






最近chatgpt、谷歌gemini、claude等大语言模型普及开来了。很多非从事人工智能或者机器学习行业的人也可以很轻松的利用AI帮助完成领域内相关工作,构建属于自己的AI助手,办事效率得到显著提升。那么今天我将为大家介绍LLMs的原理和其学习层级图!希望感兴趣的同学可以多多了解相关方面的内容,抓住大模型的发展机遇!
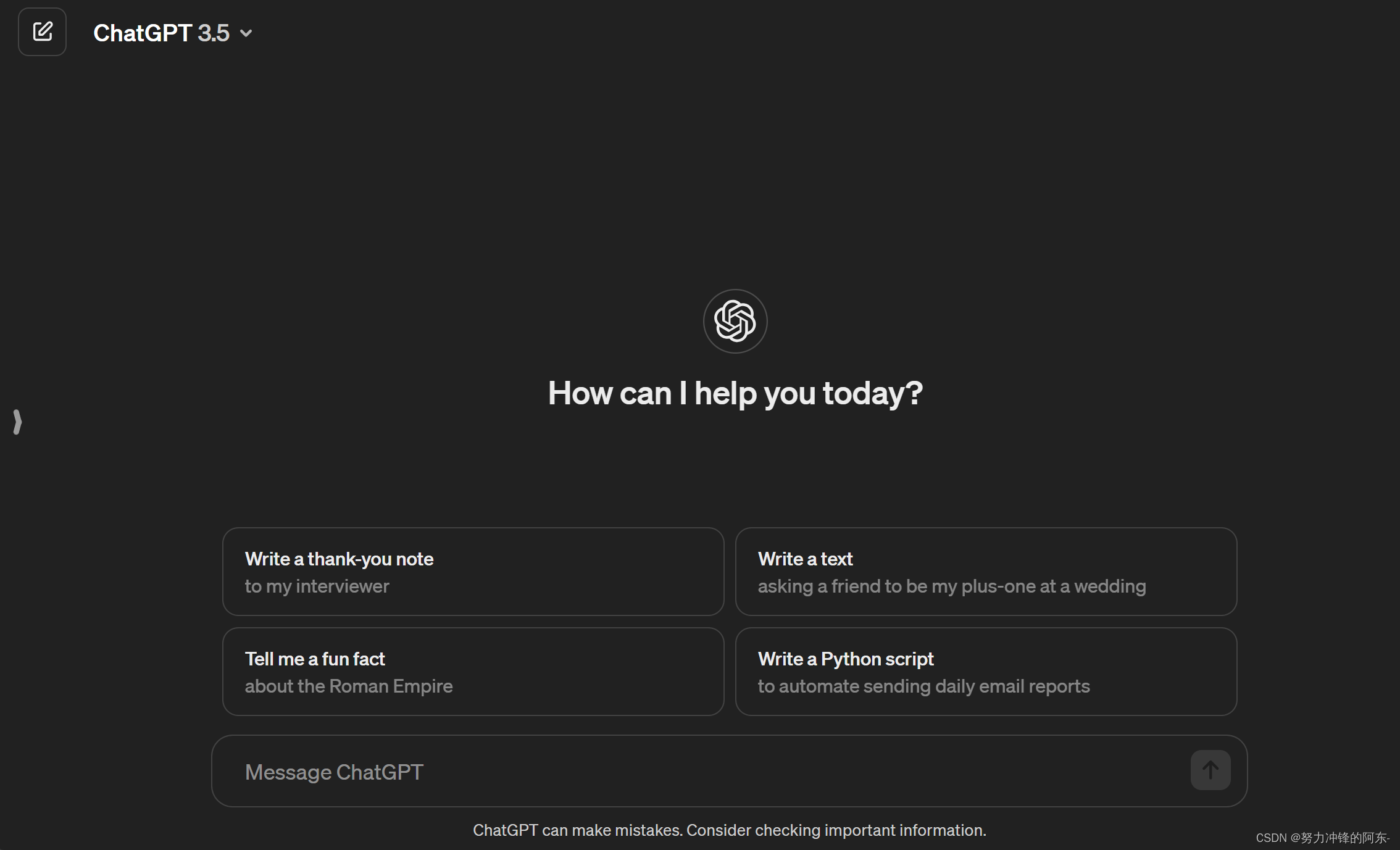

一、为什么叫“大”语言模型
首先,它属于语言模型的一种,例如LLMs都是基于NLP(自然语言处理)原理的,更具体的来说,得益于自注意力机制的提出和transformer模型架构的提出,近些年来,这些方法在图像、语言等方向也得到了扩展应用,进而有了图像生成模型DALLE以及前段时间爆火的视频生成模型Sora等。当然,除了依靠优秀的机器学习方法,更加关键的是GPU硬件的支持,它们保障模型的训练速度、决定可接纳训练知识库的大小,最终也关系到模型的训练质量。
大语言模型的模型训练参数是海量的,可达到 ~100-1000亿个参数。
二、零样本学习
零样本学习是一种机器学习技术,它允许模型在没有看到任何训练数据的情况下识别和分类新的类别。利用语义信息来建立不同类别之间的联系。模型通过学习已知类别的语义信息,并将其推广到新的类别上,从而识别和分类新的类别。
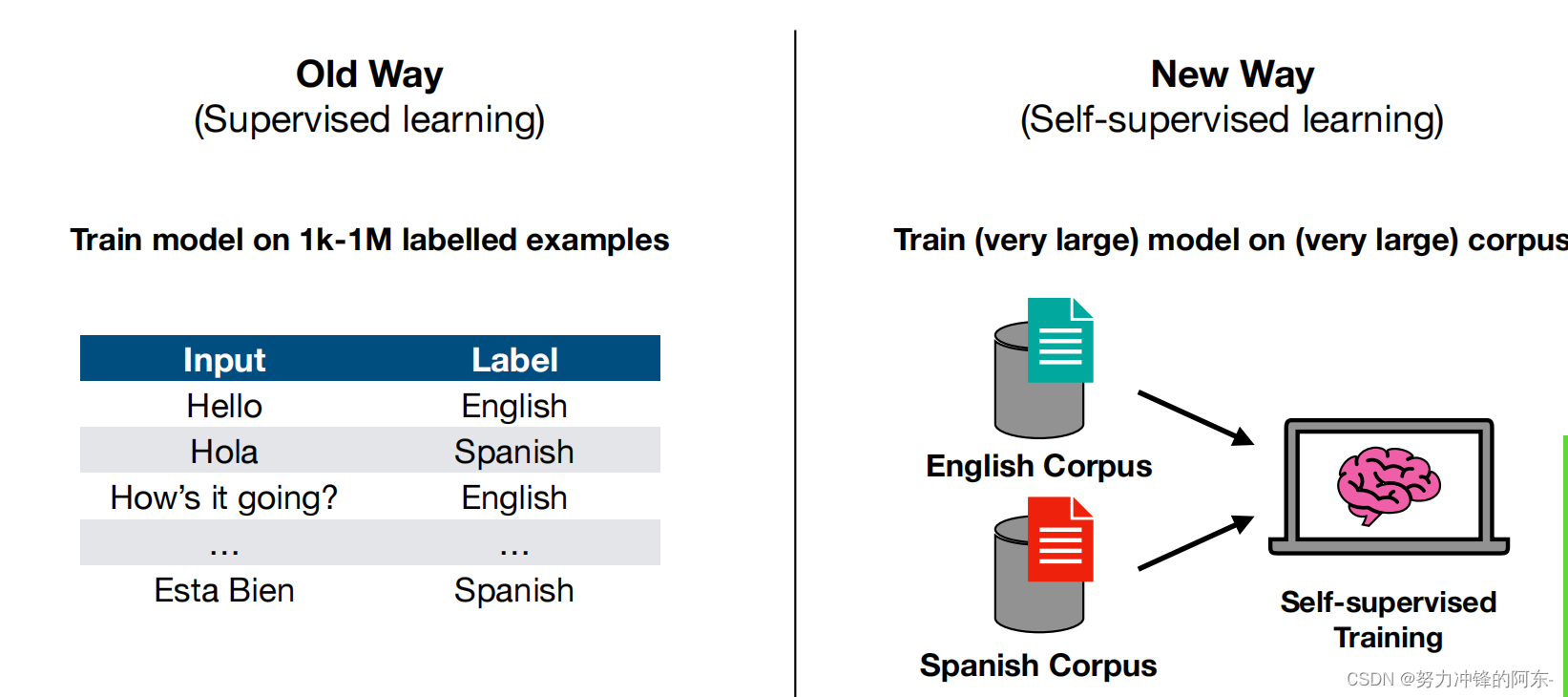
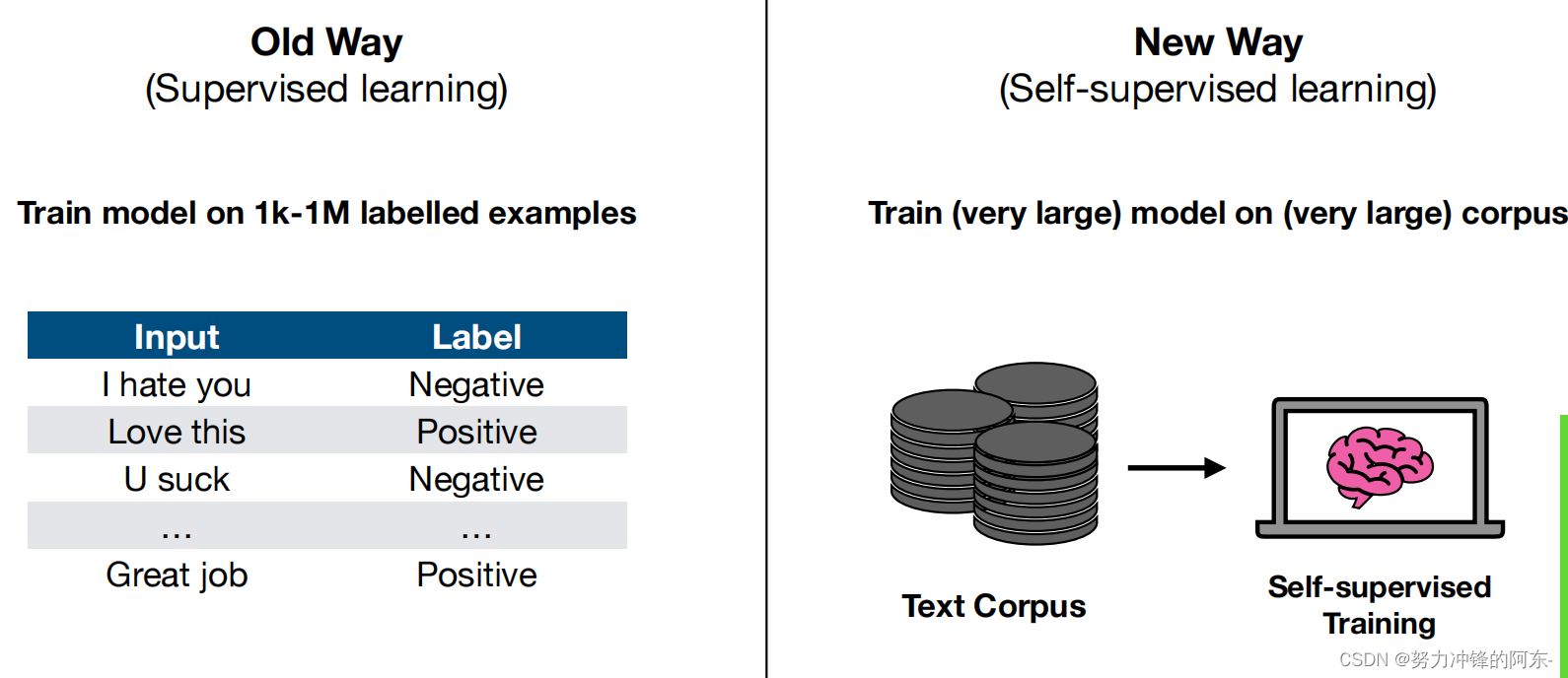
起初,要实现大模型的功能需利用监督学习进行训练,像上图中的文本翻译任务、语义分类任务都需要有严格的输入输出标签数据实例集样本。目前,大模型采用自监督学习的方式,只需要准备好相关知识的语料库,例如文本语料库、要翻译的不同语言的语料库等。这些库中内容被打上了标签,可以直接通过简短的编程处理后,对模型进行海量数据的训练,便捷性大大提升!(考验硬件水平)。
三、大语言模型运作过程
我们以文本生成为例,其实大模型会根据输入的内容判断一句话的下一个字该生成什么内容的概率,最终,会返回概率值最大的文本,不断进行自回归,直到生成完所有内容。这是一个大概过程,内部具体过程则要经过文本嵌入、分词表、transformer、decoder等一系列操作,感兴趣的话,大家可以深入了解。
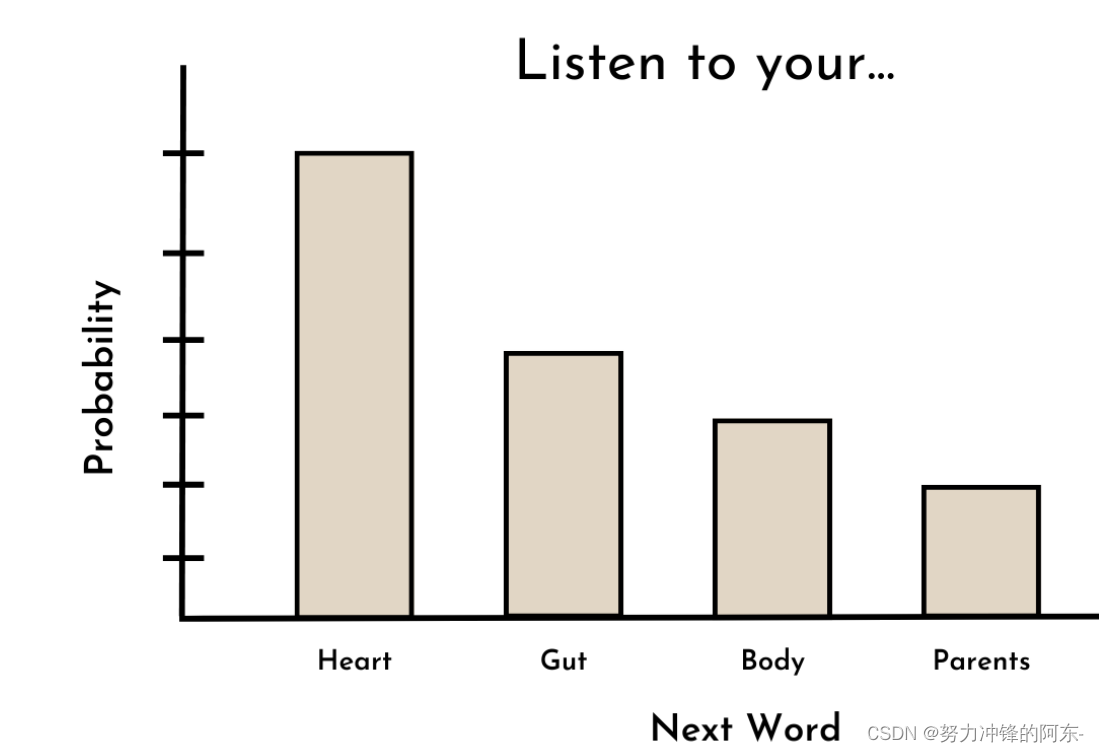

四、使用大语言模型的不同阶段
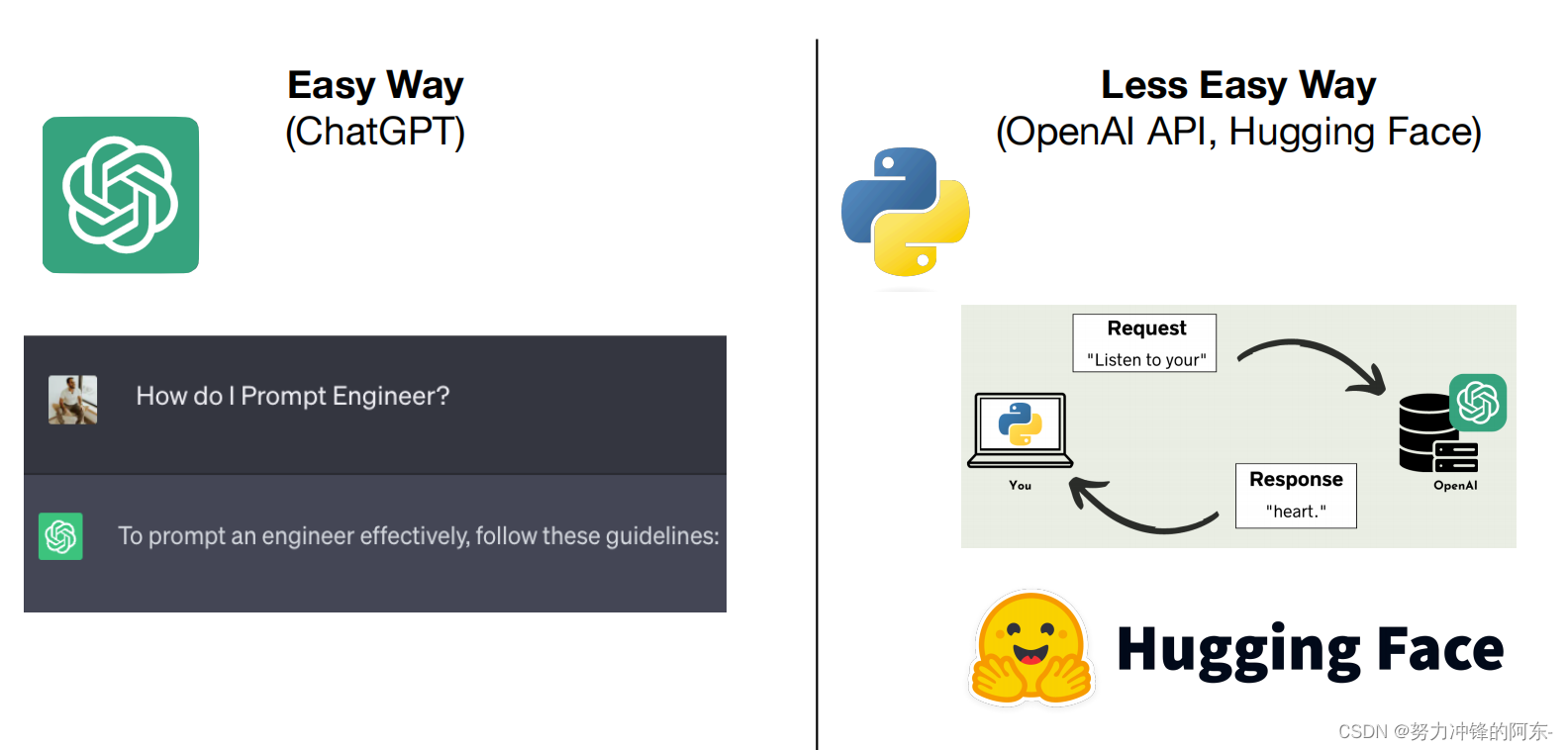
1、提示词工程:这部分比较简单,可以直接通过chatgpt进行提示词工程的设置,好的提示词需要不断的实践,不同提示词的效果也会有加大的差异,所以问答和提示词也存在很多的学问!我们也可以通过调用API进行提示词工程的实践,但是不建议这种,对新手不怎么友好。
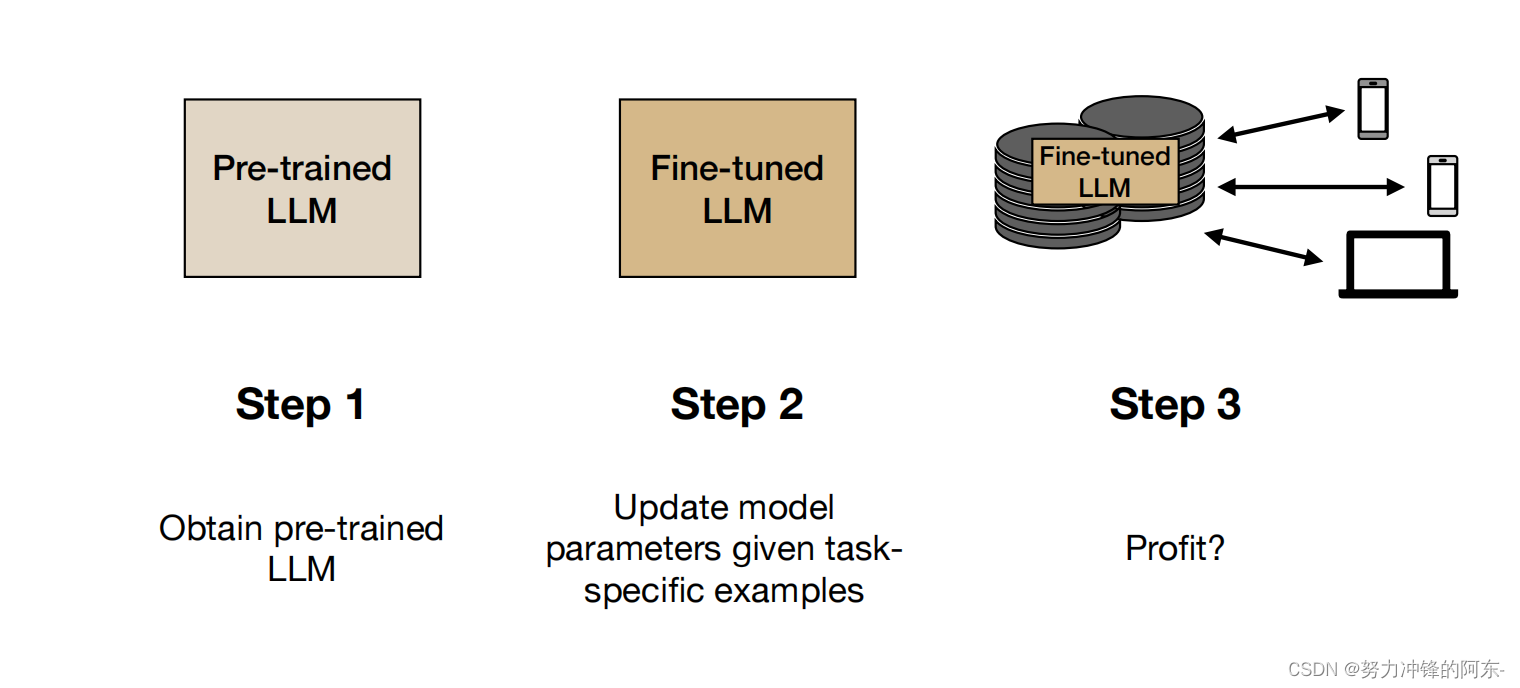
2、模型微调阶段(finetung):虽然我们没有强大的硬件资源(GPU/TPU)和海量数据,但是通过微调,我们可以利用开源的预训练模型,例如谷歌的Bert、GPT等,在此基础上准备一些我们领域的数据,即可非常便捷的对预训练模型进行微调,使其在此领域上回答的更好。具体微调的步骤流程,大家可以看我主页的文章!掌握微调,我觉得就掌握了普通人玩转大模型的主要内容。
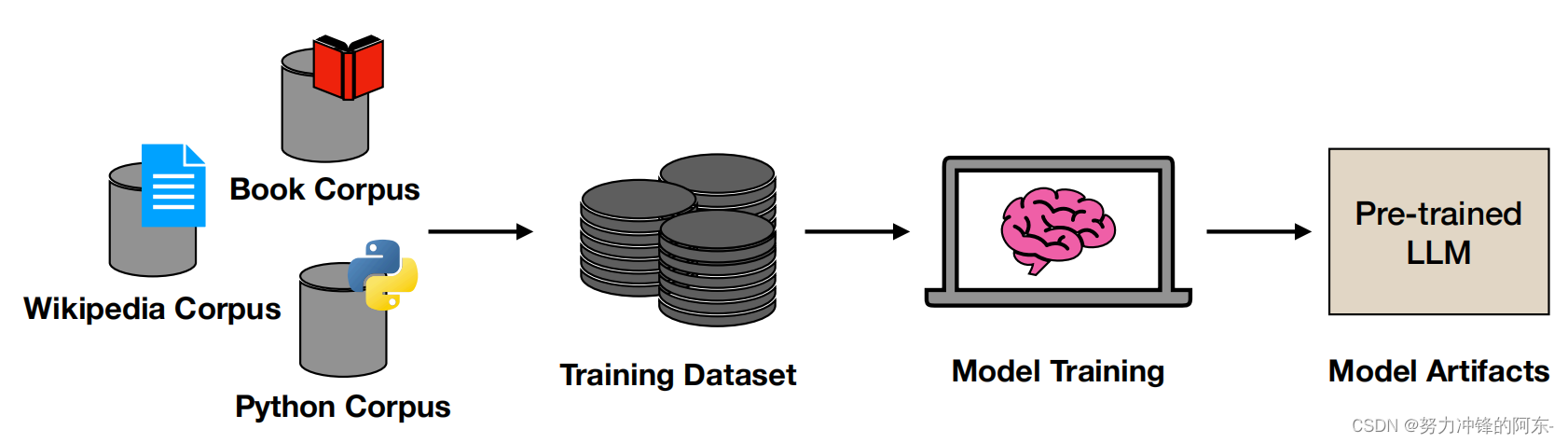
3、建立、部署自己的大语言模型:这一阶段需要我们准备自己邻域的语料库知识,这些知识可以是不同类型的,例如可以是代码、条目、书本知识、百科知识,这些语料库要进行处理,处理成训练数据集的格式后,输入到预训练模型中再次进行训练,最终即可得到我们自己的LLM了。并不需要从头开始训练,其中还会用到langchain、QloRA、RAG、Peft等相关知识,如果能够完成此部分的内容搭建,我觉得LLM的学习可以算得上扎实了。
好了,以上就是本文的全部内容了!大模型是时代的风口,我觉得也是每个人都该掌握的内容,未来必将是AI和人类共处的时代,大家抓住机会,努力学习!大家也可以关注我,我将为大家持续更新大模型的学习和其它相关知识,谢谢大家,你们的点赞、收藏是我更新的动力!
本文内容内容参考自:















 2361
2361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









