







数据来源
https://archive.ics.uci.edu/dataset/2/adult
也可以从我的github进行下载
https://github.com/harkbox/DataAnalyseStudy
过程
首先;关于教育背景的部分翻译有问题。
本次使用字典嵌套记录数据,并且通过lambda在sorted内部进行对某个字典的排序,最后用plotly进行绘图
本次提取数据的时候,用到了array的布尔型数组,这是比较方便的一种做法
import numpy as np
import matplotlib.pyplot as plt
from plotly.graph_objs import Bar,Layout
from plotly import offline
filename='/Users/oommnn/Desktop/学习笔记/数据可视化30天项目/adult.csv'
change_educations=['学士','大专','11年级','研究生','教授','副学士','副学士','9年级','7 -8年级','12年级',
'硕士','1 -4年级','10年级','博士','5 -6年级','学前']
educations=[' Bachelors', ' Some-college', ' 11th', ' HS-grad', ' Prof-school',
' Assoc-acdm', ' Assoc-voc', ' 9th', ' 7th-8th', ' 12th', ' Masters', ' 1st-4th',
' 10th', ' Doctorate', ' 5th-6th', ' Preschool']
#生成结果字典
results={}
for education in change_educations:
results[education]={'sum':0,'sum_over_50k':0,'ratio':0.0}
user_info=np.dtype([('education','U20'),('income','U10')])
data=np.loadtxt(filename,delimiter=',',dtype=user_info,usecols=(3,14))
#替换数据
i=0
for education in educations:
flag=(data['education']==education)
data['education'][flag]=change_educations[i]
i=i+1
#获得总数和超过50k的数据
for education in change_educations:
isedu=data['education']==education
#记录每个学位的总人数
results[education]['sum']=len(data['education'][isedu])
#获得超过50k的该学位的布尔数组
isrel=data[isedu]['income']==' >50K'
results[education]['sum_over_50k']=len(data[isedu][isrel])
results[education]['ratio']=results[education]['sum_over_50k']/results[education]['sum']
#key=lambda item: item[1] 是Python中用于排序或过滤列表的一个常见表达式。
#这里的 lambda 创建了一个匿名函数,它接受一个参数 item(假设是一个元组或其他可迭代对象),然后返回 item 的第二个元素,即 item[1]。
#返回的是列表的元组;按照item进行排序
sorted_items_by_values = sorted(results.items(), key=lambda item: item[1]['ratio'],reverse=True)
sorted_dict_by_values = dict(sorted_items_by_values)
#print(sorted_items_by_values)
#获得x,y和hovertext的值
x_values=list(sorted_dict_by_values.keys())
y_values=list(sorted_dict_by_values[key]['ratio'] for key in sorted_dict_by_values.keys())
hovertext_values=list(f"总数:{sorted_dict_by_values[key]['sum']}" for key in sorted_dict_by_values.keys())
#可视化;并且鼠标显示总人数标签
data=[{'type':'bar',
'x':x_values,
'y':y_values,
'hovertext':hovertext_values
}]
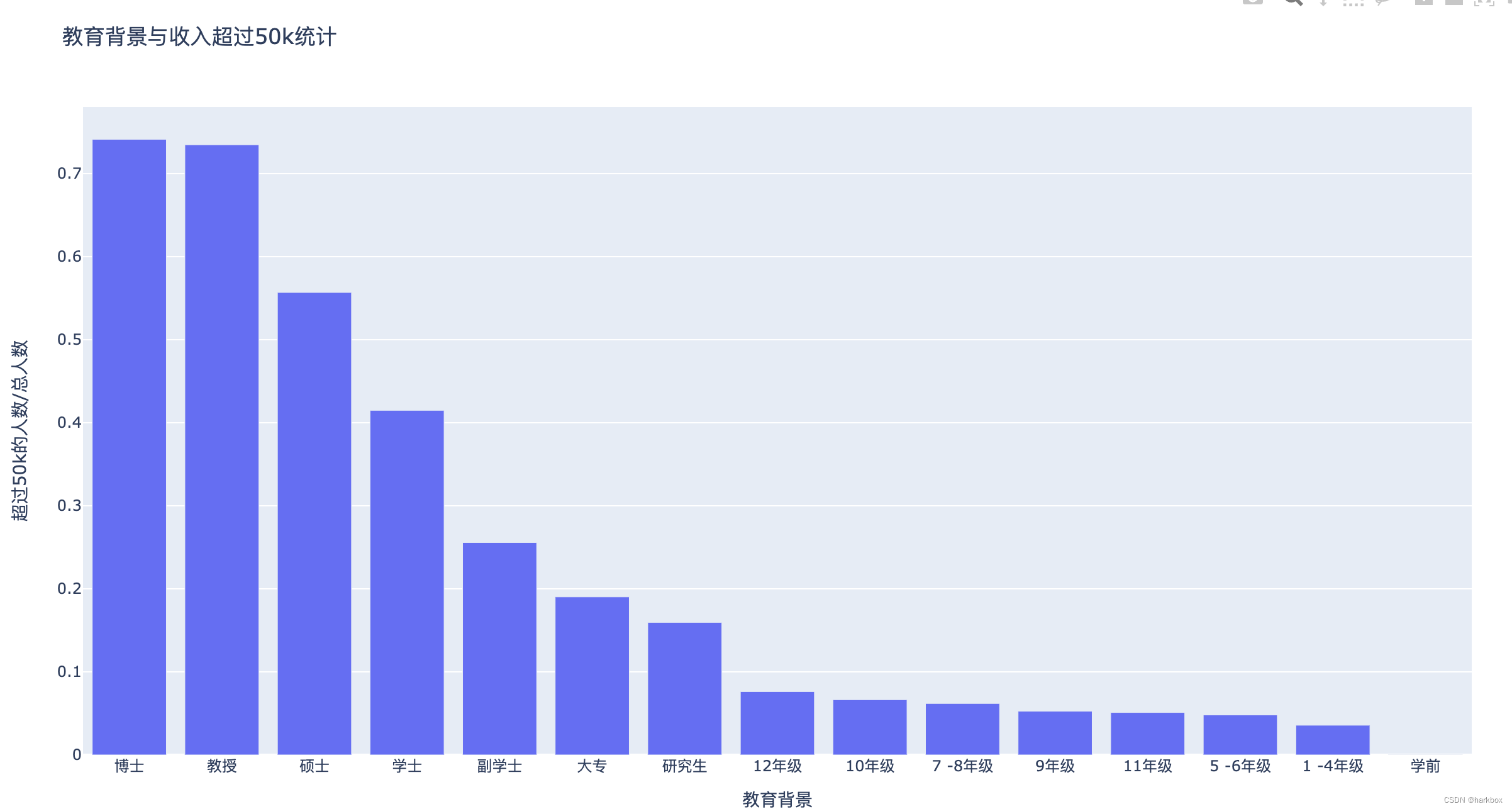
mylayout={'title':'教育背景与收入超过50k统计',
'xaxis':{'title':'教育背景',},
'yaxis':{'title':'超过50k的人数/总人数'}
}
fig={'data':data,'layout':mylayout}
offline.plot(fig,filename='adult.html')














 1072
1072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









