







原文链接:https://blog.csdn.net/Swocky/article/details/106433925
题目:Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network
链接:https://arxiv.org/abs/1803.07835v1
摘要
作者在本文提出了一种能够同时进行3D面目结构重建与提供密集对齐的方法。为了实现这个效果,作者设计了一个称为UV位置映射的2D表示,能够在UV空间中记录一个人脸的3D形状,然后训练一个卷积神经网络来从一张2D图像中重建这张图。本文还在训练过程中的loss里引入了一个权重mask来提高网络性能。该方法并不依赖任何先验人脸模型,并且能够伴随着语义重建整张人脸的面部几何。同时,网络非常轻量,9.8ms便可以处理一张图片,比之前很多工作速度都快。最后在多种比较有挑战性的数据集下表现出了超过SOTA的效果,无论是重建还是对齐任务上。代码可以参考:https://github.com/YadiraF/PRNet
1、介绍

3D面部重建和面部对齐是计算机视觉中两种基本的且高度相关的主题。在最近几十年,这两个领域之间的研究者相互促进。最初,检测空间的2D基准点的人脸对齐很大程度上主要被用作其他面部任务例如人脸识别以及辅助3D面部重建。然而,研究者发现2D任免对其在处理大量的姿态或扰动时存在问题。随着深度学习的发展,很多计算机视觉任务已经被使用卷积神经网络解决了,因此这些工作开始使用CNN来估计3D Morphable Mode系数或者3D模型翘曲函数从2D面部图像中恢复相应的3D信息,产生了密集人脸对齐和3D人脸重建的结果。然而,这些方法的表现被由面部模型偏差或模版的3D空间限制,它需要的包括透视投影或3D Thin
Plate Spline (TPS)变换在内的方法也增加了整体的复杂度。
最近,两个跨越了模型空间限制的端到端方法实现了SOTA。一个训练复杂的网络来回归2D坐标中的68个面部关键点,但是需要一个额外的网络来估计深度值。并且,并没有提供人脸对齐。另外一个方法提出了一个体积表示的3D人脸,并且使用神经网络从2D图像中回归。然而,这个表示销毁了点的语义,导致网络需要在整个面部上回归来存储仅作为一部分体积的面部形状。所以这个表示限制了恢复形状的分辨率,且需要一个复杂的网络对其进行回归。作者发现这些限制在基于模型的方法中不存在,这促使作者找到了一个新的方法同时实现3D重建和密集人脸对齐。
在本文中,作者移除了一个称为Position map Regression Network的端到端方法来讲密集对齐与3D人脸重建合并起来。作者的方法速度很快且很轻量,通过精心设计的3D面部结构的2D表示和相应的代价函数来实现。文中设计的UV位置应设可以通过2D点记录3D人脸点云,同时保持每个UV的语义。模型采用encoder-deocder结构,以及一个更注重歧义区域从2D面部图片中回归UV位置映射的权重loss。
总结一下,本文主要的贡献如下:
- 第一次不受低维方法空间的限制通过端到端方法同时解决了面部对齐与3D人脸重建
- 为了直接回归3D面部结构和密集对齐,作者提出了一种UV位置映射在2D角度记录3D点
- 提出了权重掩码并计算权值loss进行训练,从而提升模型的性能表现
- 提出了一个超过100FPS的轻量级框架
- 在AFLW2000-3D和Florence数据集上都便显出相对于SOTA超过25%的提升
2、相关工作
3D面部重建
基于3DMM的方法是目前单目3D面部形状重建中最流行的方法,之前大多的方法都是去建立3D几何结构的特别点和本地特征,这解决了回归3DMM系数的非线性提升函数。然而,这些方法严重依赖高精度的标注或特征点检测,因此所以很多方法首先使用CNN来学习输入图像和3D模版之间的密集对应,然后计算3DMM参数。最近的工作也太多了使用CNN来直接预测3DMM参数,在迭代过程中花费很多时间。然后还有通过端对端CNN直接预测3DMM形状的方法。另外,非监督的方法也在被研究,有的可以使用面部纹理信息回归3DMM,不需要训练数据的帮助,但在large-poses和不平衡的光照下表现很差。然而,这些方法主要的问题是它们是基于模型的,造成3D几何结构的限制,限制了模型的shape space以及从估计的参数中产生3D网络的后处理。一些其他的方法可以不需要3D外形偏差来重建,但是仍然依赖面部模板。例如学习3D Thin Plate Spline翘曲函数。显然,这些重建都被限制在对应的模型中,当模板改变时几何结构也会发生改变。
最近还有直接通过volumetric CNN回归进行3D面部结构映射,虽然不受模型空间限制,但是需要复杂的网络结构和很长的预测时间。而作者提出的方法不仅不受模型的限制,还十分轻量。
人脸对齐
最初,有很多通过2D面部标注进行人脸对齐的方法,例如经典的Active Appearance Model(AMM)和 Constrained Local Models(CLM)。然后级联回归和基于CNN的方法被广泛使用,然而,2D标注只回归可见点,当面部姿态很大的时候难以识别。最近的一些工作开始用3DMM或通过2D面部图像得到3D面部模板,通过深度网络直接预测热度图来获取3D面部标注并实现SOTA。密集面部对齐意味着方法需要提供2D和3D之间几何结构的关联,有的方法通过深度神经网络直接学习,但是预测的关联并不完整,只有可见的人脸区域。作者的方法可以解决面部所有的区域,也不需要3DMM、TPS参数。
3、方法介绍
3D Face Representation
作者的方法首先要通过深度网络学习一个3D面部几何结构和3D图像间的对应,一个比较容易想到且通用的思想是把所有3D面部点连接为一个向量,但是这样会丢失点之间的几何关联。然后就很容易想到可以让空间关联的点共享权值,通过卷积层就能够很容易地实现。坐标转为一维向量需要全卷积层来预测每个点,需要更多的参数,且难以计算。有一篇论文(原论文的参考51)提出了一种点集产生网络来直接将3D点云从一张图像中预测为一个向量。然后点最多只有1024个,远远不够。所以有的方法回归一些模型参数而不是坐标点,需要训练时特别注意,例如使用Mahalanobis距离和不可避免地将估计的面几何限制在其模型空间内。VRN网络可以使用全卷积网络,然而降低了点云的分辨率,大部分输出有关非表面的点的输出很少使用。
因此作者就提出了UV位置映射,通过二维表示三维,它也是最近很常用信息表示方法,包括脸部的纹理信息。
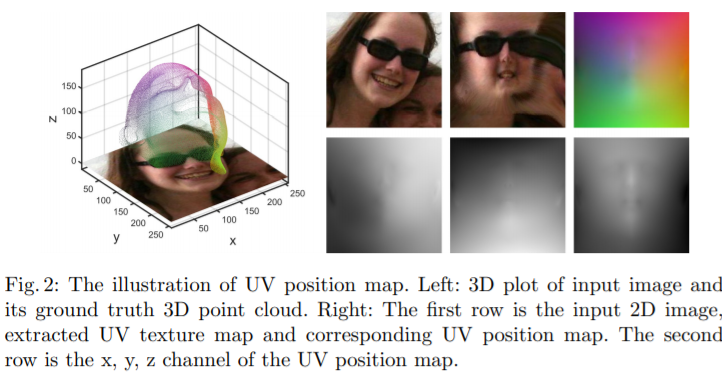
左图是输入图像的3D图和3D点云ground-truth;右边第1行,分别是2D图像,UV文理映射图,相应的UV位置映射图;右边第2行,分别是UV位置映射图的x,y,z通道。
为了保持点的语义,作者基于3DMM创建了UV坐标,并且其相应的3D形状需要用于端对端训练, 300W-LP是一个包括超过60k符合3DMM参数图像的数据集,很适合形成训练对。另外,3DMM参数基于Basel Face Model(BFM)实现,因此为了充分利用数据集,作者根据BFM设置了UV坐标。具体地说,作者使用参数化的UV坐标来计算有conformal Laplacian权重的Tutte embedding,然后将网格边界映射为正方形。由于BFM中的角点超过50K,因此使用256作为位置映射的大小,能够得到比较高的精度。
因此,作者提出的位置映射在保留语义信息的同时通过二维记录了3D面部信息,能够通过CNN同时获得3D面部结构以及进行人脸对齐。另外,位置应设包括整张脸的全部信息,与很多其他方法不同。
Network Architecture and Loss Function


模型结构还是比较清晰,也不是特别复杂。输入是RGB图像,输出是UV位置映射图。然后设计了一个loss函数计算GT和位置映射的差异。MSE由于对所有点都一样,所以并不适合学习这个位置映射。事实上脸部中的中心区域有有更多的特征,因此作者设计了一个权值mask。

这个mask还是很清晰的,颜色越浅权值越大,例如五官最为重要,以及一些脸部关键点。
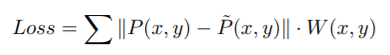
4、实验结果
3D面部对齐
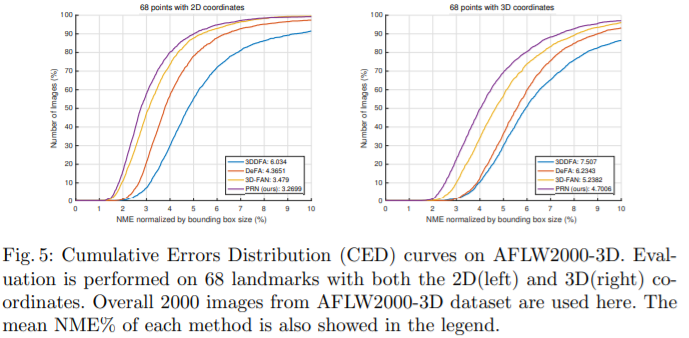
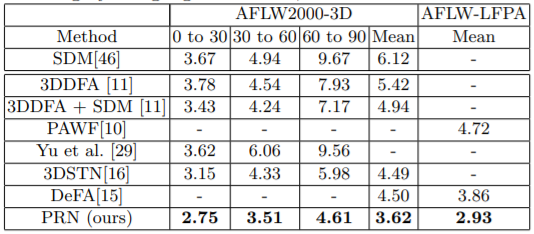

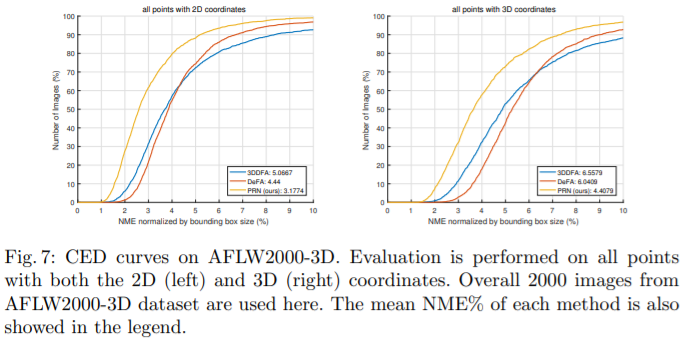
3D面部重建
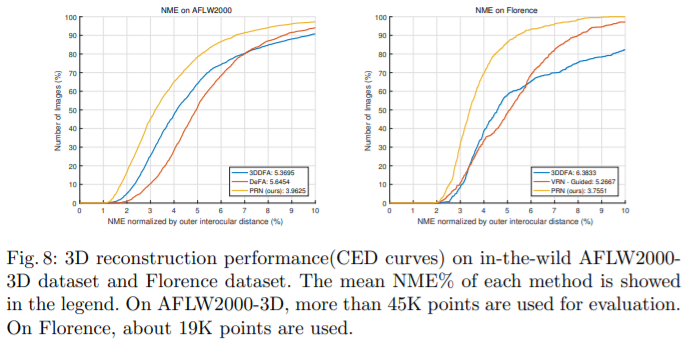
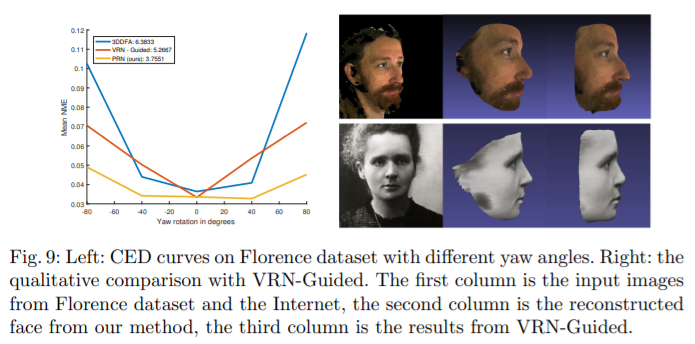
Runtime

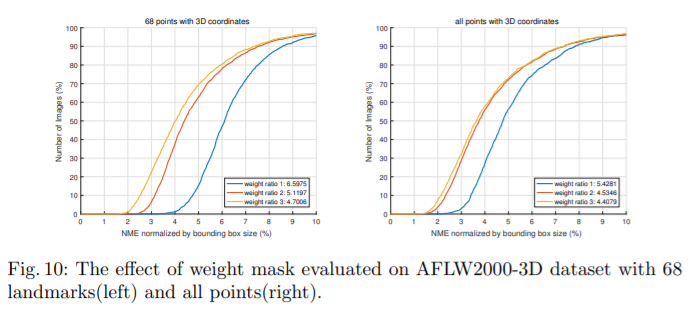
Ablation Study

总结
作者提出这个方法首先可以同时完成两个任务,且速度很快。第一次接触人脸重建的论文,可能分析的也不太正确。但是感觉其最大的创新就是使用了UV位置映射,从三维到二维,从而方便模型端到端的训练,训练的内容既有人脸位置信息,也有深度信息,还使用了一个mask来控制权重分配。
很值得借鉴的首先是这种维度转换,能够加快计算且效果较好,然后就是为了训练设计了端到端的模型,并且通过mask控制loss,让模型能够更好地聚焦在关键信息部分。
虽然这篇文章内容很多,但是很大的篇幅都在介绍过去方法的不足,实质性介绍本文方法的其实也不是特别多。其实现也不是特别复杂,但是这种维度转换的选择还是很巧妙的。















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









