








原文链接:https://www.zhihu.com/question/64470274
https://blog.csdn.net/jiangpeng59/article/details/77646186
跑试验的间隙,遇到了同样的困惑,看了一圈答案之后,想明白了。再来给大家白话解释一遍。
根据Keras 官方文档的函数定义:
keras.layers.LSTM(units, activation='tanh', recurrent_activation='sigmoid', ....
units: Positive integer, dimensionality of the output space.
先给结论:这里的units就是输出层的维度。
比如:inputs=[100,300], units=128, 那么你经过一层LSTM之后,得到的output=[100,128].
答案里面可以参考
的言简意赅的答案,以及 的详细答案。=====================================================
现在开始说自己的理解,主要是根据lonlon ago的回答基础上,再对他的回答进行注解。
先这样想:
你有一段话,这段话有100个字,你经过一种embedding作用(e.g. Word2Vec),每个字都用一个300维的向量表示。那么这100个字是有先后顺序的,也就是时序信息的。所以,你现在相当于有一个[100,300]的矩阵,这就是你的input。现在,有一个神奇的DL层,经过这个层之后呢,你原来的[100, 300]矩阵,就会变成[100,128]的矩阵。这里的300维降到128维,可以想“全连接”层,也就是相当于过了一个隐含层,得到了隐含表达(hidden representation)。
上面提到的神奇的DL层就是LSTM!
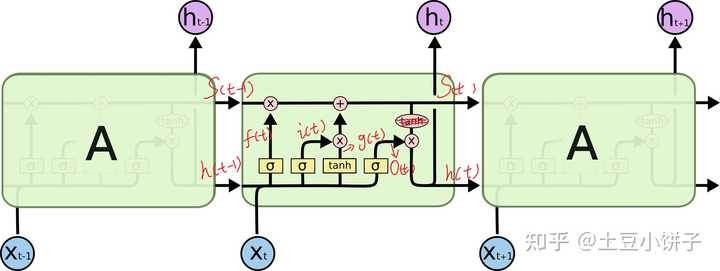
假如现在处理第50个字:第50个字 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/49e212f6e7a3a2f5247b144eadd8e6b8.png) (300维)以及前面49个字的隐状态,也就是别的答案里的cell的状态,
(300维)以及前面49个字的隐状态,也就是别的答案里的cell的状态, ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/acda5416271ca9059400f3ade5fb0f3e.png) (128维), 这两个会拼接在一起形成一个428维的输入。这个输入会在当前的cell中,分别经过那4个小黄框,注意啦!每个小皇框的输出都被设定成为128维度(对,就是你赋给units的值), 所以后面的一些列操作都是在128维基础上进行相乘、相加(就是图里的红色的小圆圈)。一系列操作之后,你会产生一个
(128维), 这两个会拼接在一起形成一个428维的输入。这个输入会在当前的cell中,分别经过那4个小黄框,注意啦!每个小皇框的输出都被设定成为128维度(对,就是你赋给units的值), 所以后面的一些列操作都是在128维基础上进行相乘、相加(就是图里的红色的小圆圈)。一系列操作之后,你会产生一个 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/2caedae8a2b19f46514c407c5e1f55ec.png) ,也是128维度的,如此进行下去...
,也是128维度的,如此进行下去...
如果在LSTM层中设置了return_sequences=True, 就会把 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/ba386a5ca8705f64c67cb9b9a4e62a24.png) 的一共100个向量都返回给你,形成一个[100, 128]的矩阵。反之,如果 return_sequences=False, 你就只会得到
的一共100个向量都返回给你,形成一个[100, 128]的矩阵。反之,如果 return_sequences=False, 你就只会得到 ![[公式]](https://i-blog.csdnimg.cn/blog_migrate/71c98d638df7e887fbb37bf4acfd2583.png) 的一个向量,还是128维的。
的一个向量,还是128维的。
就这样,希望我讲明白了!
P.S. 这个讲解也很清晰:
=====================================================
LSTM层
keras.layers.recurrent.LSTM(units, activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0)
- 1
核心参数
units:输出维度
input_dim:输入维度,当使用该层为模型首层时,应指定该值(或等价的指定input_shape)
return_sequences:布尔值,默认False,控制返回类型。若为True则返回整个序列,否则仅返回输出序列的最后一个输出
input_length:当输入序列的长度固定时,该参数为输入序列的长度。当需要在该层后连接Flatten层,然后又要连接Dense层时,需要指定该参数,否则全连接的输出无法计算出来。
输入shape
形如(samples,timesteps,input_dim)的3D张量
输出shape
如果return_sequences=True:返回形如(samples,timesteps,output_dim)的3D张量否则,返回形如(samples,output_dim)的2D张量
1.输入和输出的类型
相对之前的tensor,这里多了个参数timesteps,其表示啥意思?举个栗子,假如我们输入有100个句子,每个句子都由5个单词组成,而每个单词用64维的词向量表示。那么samples=100,timesteps=5,input_dim=64,你可以简单地理解timesteps就是输入序列的长度input_length(视情而定)
2.units
假如units=128,就一个单词而言,你可以把LSTM内部简化看成
Y
=
X
1
×
64
W
64
×
128
Y=X_{1\times64}W_{64\times128}
</span><span class="katex-html"><span class="base"><span class="strut" style="height: 0.68333em; vertical-align: 0em;"></span><span class="mord mathit" style="margin-right: 0.22222em;">Y</span><span class="mspace" style="margin-right: 0.277778em;"></span><span class="mrel">=</span><span class="mspace" style="margin-right: 0.277778em;"></span></span><span class="base"><span class="strut" style="height: 0.891661em; vertical-align: -0.208331em;"></span><span class="mord"><span class="mord mathit" style="margin-right: 0.07847em;">X</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height: 0.301108em;"><span class="" style="top: -2.55em; margin-left: -0.07847em; margin-right: 0.05em;"><span class="pstrut" style="height: 2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mtight"><span class="mord mtight">1</span><span class="mbin mtight">×</span><span class="mord mtight">6</span><span class="mord mtight">4</span></span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height: 0.208331em;"><span class=""></span></span></span></span></span></span><span class="mord"><span class="mord mathit" style="margin-right: 0.13889em;">W</span><span class="msupsub"><span class="vlist-t vlist-t2"><span class="vlist-r"><span class="vlist" style="height: 0.301108em;"><span class="" style="top: -2.55em; margin-left: -0.13889em; margin-right: 0.05em;"><span class="pstrut" style="height: 2.7em;"></span><span class="sizing reset-size6 size3 mtight"><span class="mord mtight"><span class="mord mtight">6</span><span class="mord mtight">4</span><span class="mbin mtight">×</span><span class="mord mtight">1</span><span class="mord mtight">2</span><span class="mord mtight">8</span></span></span></span></span><span class="vlist-s"></span></span><span class="vlist-r"><span class="vlist" style="height: 0.208331em;"><span class=""></span></span></span></span></span></span></span></span></span></span> ,X为上面提及的词向量比如64维,W中的128就是units,也就是说通过LSTM,把词的维度由64转变成了128</p>
3.return_sequences
我们可以把很多LSTM层串在一起,但是最后一个LSTM层return_sequences通常为false,具体看下面的栗子。
栗子
Sentence01: you are really a genius
model = Sequential()
model.add(LSTM(128, input_dim=64, input_length=5, return_sequences=True))
model.add(LSTM(256, return_sequences=False))
- 1
- 2
- 3

(1)我们把输入的单词,转换为维度64的词向量,小矩形的数目即单词的个数input_length
(2)通过第一个LSTM中的Y=XW,这里输入为维度64,输出为维度128,而return_sequences=True,我们可以获得5个128维的词向量V1’…V5’
(3)通过第二个LSTM,此时输入为V1’…V5’都为128维,经转换后得到V1’’…V5’'为256维,最后因为return_sequences=False,所以只输出了最后一个红色的词向量
网友提问:
(1)activation='tanh’对应哪个门?
我们看看源码:
if self.implementation == 2: #If set to 2 (LSTM/GRU only) z = K.dot(inputs * dp_mask[0], self.kernel) z += K.dot(h_tm1 * rec_dp_mask[0], self.recurrent_kernel) if self.use_bias: z = K.bias_add(z, self.bias)z0 <span class="token operator">=</span> z<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span> <span class="token punctuation">:</span>self<span class="token punctuation">.</span>units<span class="token punctuation">]</span> z1 <span class="token operator">=</span> z<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span> self<span class="token punctuation">.</span>units<span class="token punctuation">:</span> <span class="token number">2</span> <span class="token operator">*</span> self<span class="token punctuation">.</span>units<span class="token punctuation">]</span> z2 <span class="token operator">=</span> z<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span> <span class="token number">2</span> <span class="token operator">*</span> self<span class="token punctuation">.</span>units<span class="token punctuation">:</span> <span class="token number">3</span> <span class="token operator">*</span> self<span class="token punctuation">.</span>units<span class="token punctuation">]</span> z3 <span class="token operator">=</span> z<span class="token punctuation">[</span><span class="token punctuation">:</span><span class="token punctuation">,</span> <span class="token number">3</span> <span class="token operator">*</span> self<span class="token punctuation">.</span>units<span class="token punctuation">:</span><span class="token punctuation">]</span> i <span class="token operator">=</span> self<span class="token punctuation">.</span>recurrent_activation<span class="token punctuation">(</span>z0<span class="token punctuation">)</span> f <span class="token operator">=</span> self<span class="token punctuation">.</span>recurrent_activation<span class="token punctuation">(</span>z1<span class="token punctuation">)</span> c <span class="token operator">=</span> f <span class="token operator">*</span> c_tm1 <span class="token operator">+</span> i <span class="token operator">*</span> self<span class="token punctuation">.</span>activation<span class="token punctuation">(</span>z2<span class="token punctuation">)</span> <span class="token comment">#**关注点**</span> o <span class="token operator">=</span> self<span class="token punctuation">.</span>recurrent_activation<span class="token punctuation">(</span>z3<span class="token punctuation">)</span>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
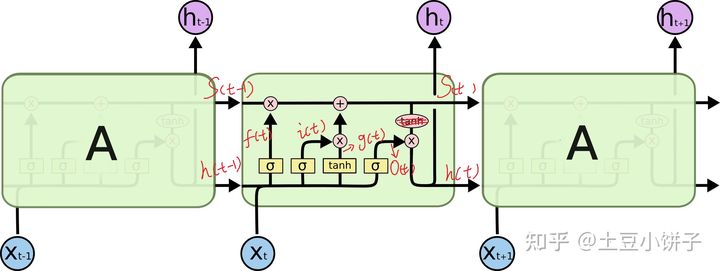
关注点那行代码对应下面的图(这块应该是输入门):

参考:
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://www.zhihu.com/question/41949741?sort=created
http://www.cnblogs.com/leeshum/p/6133290.html
http://spaces.ac.cn/archives/4122/ (word2vec和Ebedding的区别)

















 7514
7514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









