







数据库设计三范式
第一范式:要求任何一张表必须有主键,每一个字段原子性不可再分。
第二范式:建立在第一范式的基础之上,要求所有非主键字段完全依赖主键,不要产生部分依赖。
第三范式:建立在第二范式的基础之上,要求所有非主键字段直接依赖主键,不要产生传递依赖。
目的:避免表中数据的冗余,空间的浪费。
第一范式
最核心 最重要的范式,所有表的设计都需要满足。
必须有主键,并且每一个字段都是原子性不可再分。

比如这个表,不满足第一范式,首先没有主键;联系方式可以分为邮箱地址和电话,不满足每一个字段原子性。改为以下:

pk表示primary key(主键)
第二范式
建立在第一范式的基础之上
要求所有非主键字段必须完全依赖主键,不要产生部分依赖。比如:
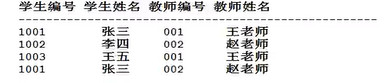
首先这张表不满足第一范式,因为没有主键。
修改如下:

学生编号 教师编号,两个字段联合做主键,复合主键。(primary key:学生编号+教师编号)
由此,满足第一范式。
但是不满足第二范式。观察复合主键,学生姓名依赖于学生编号,教师姓名依赖于教师编号。产生了部分依赖。
部分依赖的缺点是:数据冗余,空间浪费,比如上表张三 王老师出现了两次,存储了两次。
如何设计?
这个表是一个多对多关系,一个学生对应多个老师,比如张三对应王老师和赵老师,一个老师对应多个老师。划分为三张表:



fk:foreign key(外键)
多对多如何设计?
口诀:多对多,三张表,关系表两个外键!
第三范式
第三范式建立在第二范式的基础之上
要求所有非主键字段必须直接依赖主键,不要产生传递依赖。
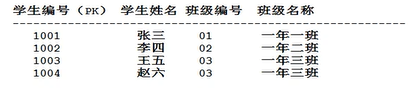
此表显然是一对多关系,一个班级对应多个学生。
分析:
满足第一范式:因为有主键,每一个字段原子性不可再分。
满足第二范式:因为主键都不是复合主键,不可能产生部分依赖。主键是单一主键。
不满足第三范式:产生了传递依赖。比如一年三班依赖于班级编号03,03依赖于主键。产生了传递依赖。产生了数据的冗余,这里一年三班存储了两次。
修改如下(两张表):

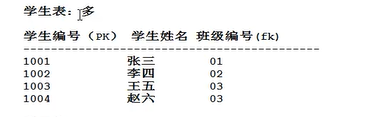
如何设计一对多?
一对多,两张表,多个表加外键!
总结:
数据库设计三范式是理论上的
实践和理论有的时候有偏差
最终的目的都是为了满足客户的需求,有的时候会拿冗余换速度。
因为在sql中,表和表之间的连接次数越多,效率越低(笛卡尔积)
有的时候可能会存在冗余,但是为了减少表的连接次数,这样做也是合理的,并且对于开发人员来说,sql语句的编写难度也会降低。















 950
950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









