







SPMV稀疏矩阵向量乘笔记(24)
Merge-based Parallel Sparse Matrix-Sparse Vector Multiplication with a Vector Architecture浅读 (2)
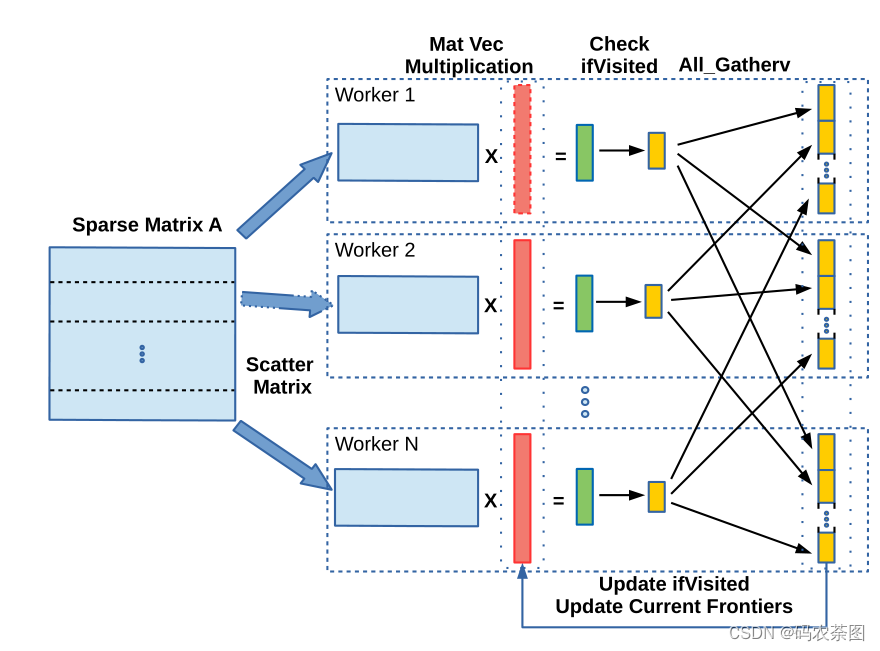
PARALLEL BFS ALGORITHM(后续有时间再看)
- 与DFS不同,解释了为啥BFS本质上是并行的,输入向量x表示每次迭代访问的边界顶点,结果向量y中的所有非零元素表示当前边界的邻居,并包括下一次迭代的边界。
THE SPMSPV-2DMERGE ALGORITHM
- A为CCS格式,x和y为list格式,merge分为四个步骤(stage)
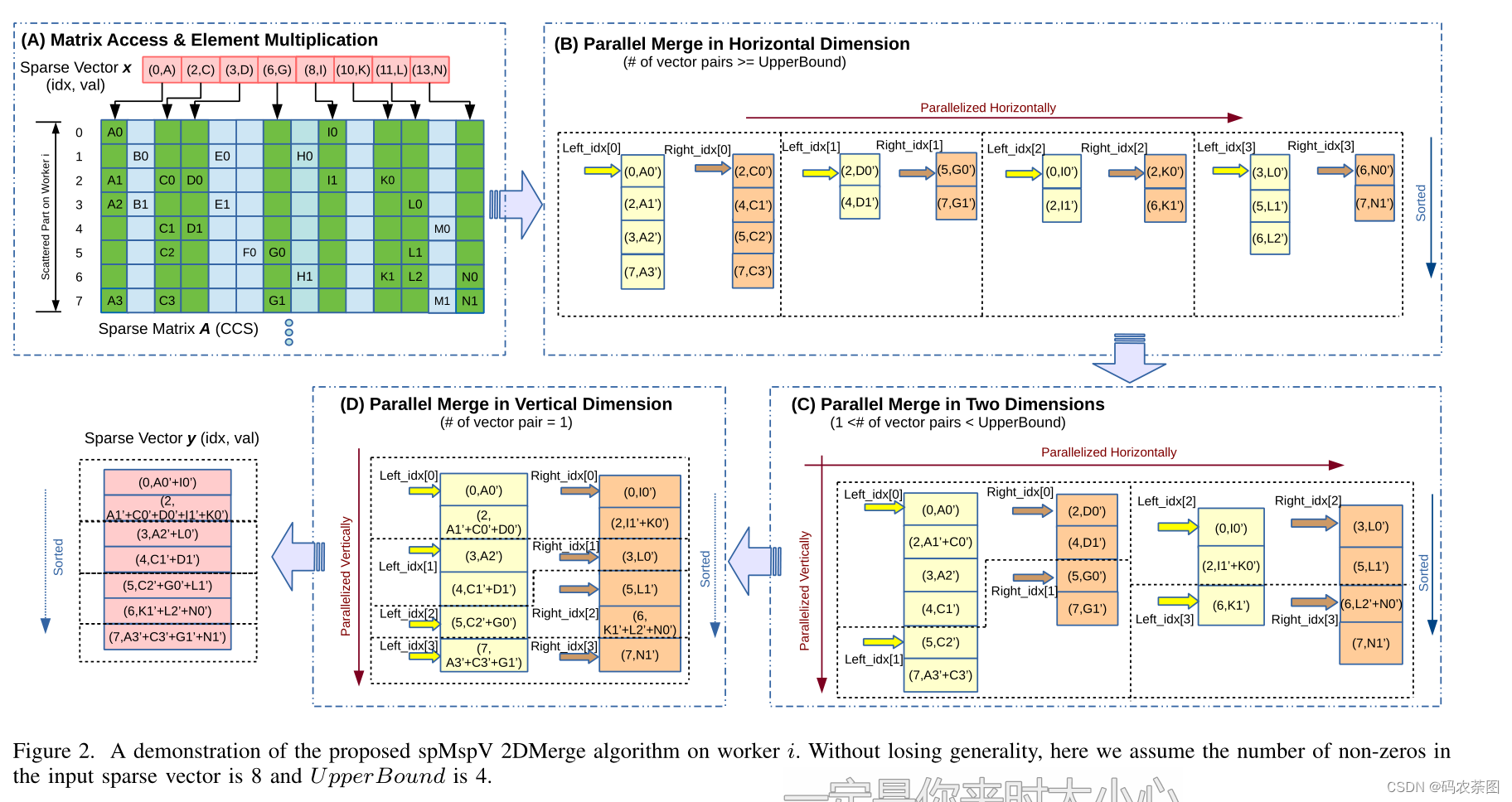
- Stage A: Matrix Access and Element Multiplication
- 分配了两个缓冲区bcur和bnext,大小为所有选中列中非零元的总数,left_idx和right_idx用于表示缓冲区bcur中每个向量的当前合并位置
- bcur中保存的是A[j,i]*val[i]的每个结果
- Stage B: Parallel Merge in Horizontal Dimension
- left_idx[i]和right_idx[i]两两成对,根据idx(即行值)进行相应的merge
- left_idx[i]存的是一个int,表示当前处于第几行。猜测例如left_idex[0]为0,right_idx[i]为5,这是第一组,第二组例如left_idex[1]为7,right_idx[i]为12.因为bcur的数据格式为(idx,val),并且是一维的
- 最终每队合并成一个保持排序的结果向量,数量也减少一半
- 该步骤主要用的Comp_Merge,伪代码如下

- Stage C: Parallel Merge in Two Dimensions
- 当向量对的数量小于规定的上限值,将每个向量对划分为多个区域并并行合并,进一步提高了向量寄存器的效率
- 所以并行和向量化不仅存在于向量对外部,内部也存在
- 划分方式这里目前没看太懂,后续补上
- Stage D: Parallel Merge in V ertical Dimension
- 当矢量对的数量减少到一个时,矢量化只在垂直方向上进行
Optimization Techniques
- C、D的划分方式
- 简单方法:将左侧进行均匀划分,然后对右侧进行二分搜索,找到左侧划分后每块的下界位置。
- 存在问题:存在重叠部分较小,即idx相同范围的小的情况,会产生负载不均衡
- 本文方法:Adapt-Partition,首先,根据左右向量的总大小确定每个区域的大小。然后生成归并路径,对向量对进行二分搜索。因此,一对中的每个区域将包含类似数量的元素进行比较(看不懂)
- 简单方法:将左侧进行均匀划分,然后对右侧进行二分搜索,找到左侧划分后每块的下界位置。















 6676
6676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









