







InnoDB存储引擎的B+树索引:
- 每个索引都对应一棵 B+ 树, B+ 树分为好多层,最下边一层是叶子节点,其余的是内节点。所有 用户记录都存储在 B+ 树的叶子节点,所有 目录项记录 都存储在内节点。
- InnoDB 存储引擎会自动为主键(如果没有它会自动帮我们添加)建立 聚簇索引 ,聚簇索引的叶子节点包含完整的用户记录。
- 我们可以为自己感兴趣的列建立 二级索引 , 二级索引 的叶子节点包含的用户记录由 索引列 + 主键 组成,所以如果想通过 二级索引 来查找完整的用户记录的话,需要通过 回表 操作,也就是在通过 二级索引找到主键值之后再到 聚簇索引 中查找完整的用户记录。
- B+ 树中每层节点都是按照索引列值从小到大的顺序排序而组成了双向链表,而且每个页内的记录(不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单链表。如果是 联合索引 的话,则页面和记录先按照 联合索引 前边的列排序,如果该列值相同,再按照 联合索引 后边的列排序。
- 通过索引查找记录是从 B+ 树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了Page Directory (页目录),所以在这些页面中的查找非常快。
7.1 索引的代价
空间上:
每建立一个索引都要为它建立一棵 B+ 树,每一棵 B+ 树的每一个节点都是一个数据页,一个页默认会占用 16KB 的存储空间,一棵很大的 B+ 树由许多数据页组成。
时间上:
每次对表中的数据进行增、删、改操作时,都需要去修改各个 B+ 树索引。而且我们讲过, B+ 树每层节点都是按照索引列的值从小到大的顺序排序而组成了双向链表。不论是叶子节点中的记录,还是内节点中的记录(也就是不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单向链表。而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收啥的操作来维护好节点和记录的排序。
7.2 B+树索引适用的条件
先创建一个表:

对于这个 person_info 表我们需要注意两点:
- 表中的主键是 id 列,它存储一个自动递增的整数。所以 InnoDB 存储引擎会自动为 id 列建立聚簇索引。
- 我们额外定义了一个二级索引 idx_name_birthday_phone_number ,它是由3个列组成的联合索引。所以在这个索引对应的 B+ 树的叶子节点处存储的用户记录只保留 name 、 birthday 、 phone_number 这三个列的值以及主键 id 的值,并不会保存 country 列的值。
从这两点注意中我们可以再次看到,一个表中有多少索引就会建立多少棵 B+ 树, person_info 表会为聚簇索引和 idx_name_birthday_phone_number 索引建立2棵 B+ 树。
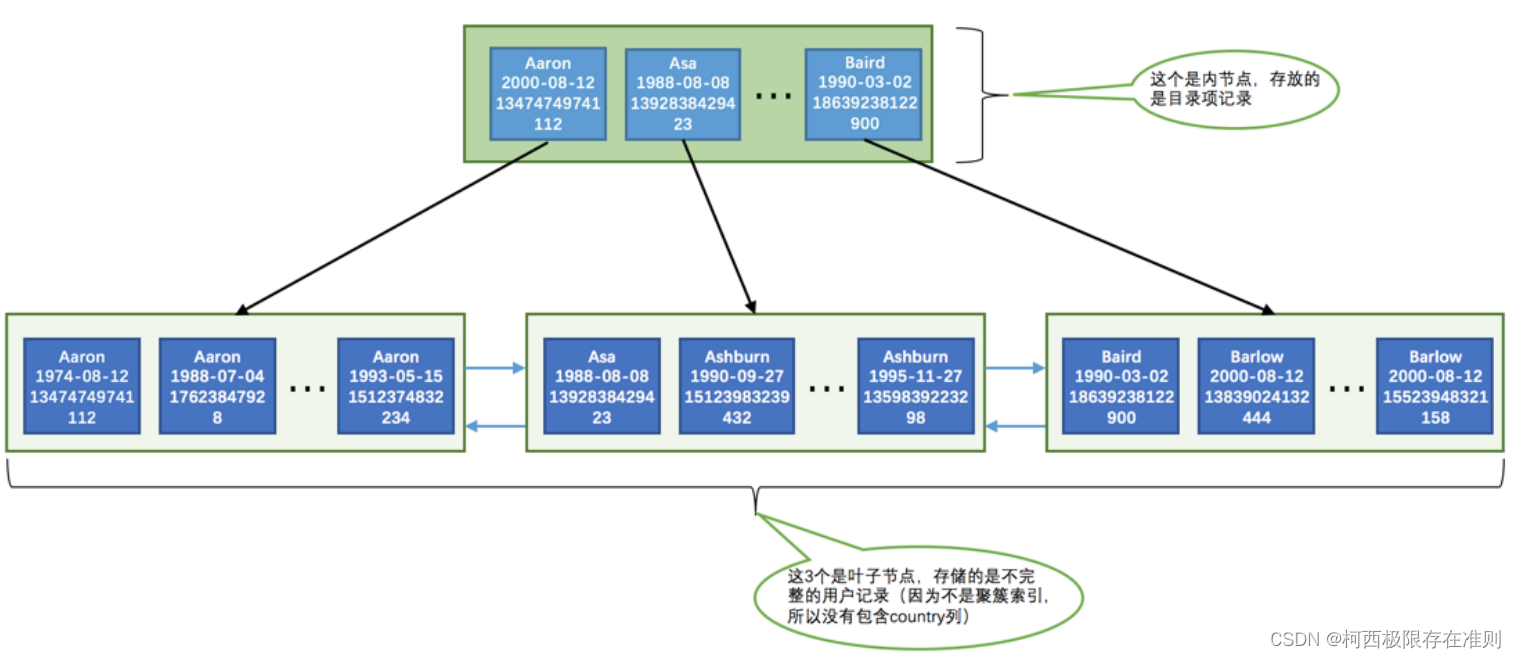
内节点中存储的是 目录项记录 ,叶子节点中存储的是 用户记录 (由于不是聚簇索引,所以用户记录是不完整的,缺少 country 列的值)。从图中可以看出,这个 idx_name_birthday_phone_number 索引对应的 B+ 树中页面和记录的排序方式就是这样的:
- 先按照 name 列的值进行排序。
- 如果 name 列的值相同,则按照 birthday 列的值进行排序。
- 如果 birthday 列的值也相同,则按照 phone_number 的值进行排序。
7.2.1 全值匹配
SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday = '1990-09-27' AND phon我们建立的 idx_name_birthday_phone_number 索引包含的3个列在这个查询语句中都展现出来了。大家可以想象一下这个查询过程:
- 因为 B+ 树的数据页和记录先是按照 name 列的值进行排序的,所以先可以很快定位 name 列的值是 Ashburn的记录位置。
- 在 name 列相同的记录里又是按照 birthday 列的值进行排序的,所以在 name 列的值是 Ashburn 的记录里又可以快速定位 birthday 列的值是 '1990-09-27' 的记录。
- 如果很不幸, name 和 birthday 列的值都是相同的,那记录是按照 phone_number 列的值排序的,所以联合索引中的三个列都可能被用到。
7.2.2 匹配左边的列
在我们的搜索语句中可以不用包含全部联合索引中的列,只包含左边的就行,比方说下边的查询语句:
SELECT * FROM person_info WHERE name = 'Ashburn';如果我们想使用联合索引中尽可能多的列,搜索条件中的各个列必须是联合索引中从最左边连续的列。比方说联合索引 idx_name_birthday_phone_number 中列的定义顺序是 name 、birthday 、 phone_number ,如果我们的搜索条件中只有 name 和 phone_number ,而没有中间的 birthday ,比方说这样:
SELECT * FROM person_info WHERE name = 'Ashburn' AND phone_number = '15123983239';这样只能用到 name 列的索引, birthday 和 phone_number 的索引就用不上了,因为 name 值相同的记录先按照birthday 的值进行排序, birthday 值相同的记录才按照 phone_number 值进行排序。
7.2.3 匹配列前缀
某个列建立索引的意思其实就是在对应的 B+ 树的记录中使用该列的值进行排序,比方说person_info 表上建立的联合索引 idx_name_birthday_phone_number 会先用 name 列的值进行排序,所以这个联合索引对应的 B+ 树中的记录的 name 列的排列就是这样的:

字符串排序的本质就是比较哪个字符串大一点儿,哪个字符串小一点,比较字符串大小就用到了该列的字符集和比较规则。这里需要注意的是,一般的比较规则都是逐个比较字符的大小,也就是说我们比较两个字符串的大小的过程其实是这样的:
- 先比较字符串的第一个字符,第一个字符小的那个字符串就比较小。
- 如果两个字符串的第一个字符相同,那就再比较第二个字符,第二个字符比较小的那个字符串就比较小。
- 如果两个字符串的第二个字符也相同,那就接着比较第三个字符,依此类推。
所以一个排好序的字符串列其实有这样的特点:
- 先按照字符串的第一个字符进行排序。
- 如果第一个字符相同再按照第二个字符进行排序。
- 如果第二个字符相同再按照第三个字符进行排序,依此类推。
也就是说这些字符串的前n个字符,也就是前缀都是排好序的,所以对于字符串类型的索引列来说,我们只匹配它的前缀也是可以快速定位记录的,比方说我们想查询名字以 'As' 开头的记录,那就可以这么写查询语句:
SELECT * FROM person_info WHERE name LIKE 'As%';但是需要注意的是,如果只给出后缀或者中间的某个字符串,比如这样:
SELECT * FROM person_info WHERE name LIKE '%As%';MySQL 就无法快速定位记录位置了,因为字符串中间有 'As' 的字符串并没有排好序,所以只能全表扫描了。有时候我们有一些匹配某些字符串后缀的需求,比方说某个表有一个 url 列,该列中存储了许多url:

假设已经对该 url 列创建了索引,如果我们想查询以 com 为后缀的网址的话可以这样写查询条件: WHERE urlLIKE '%com' ,但是这样的话无法使用该 url 列的索引。为了在查询时用到这个索引而不至于全表扫描,我们可以把后缀查询改写成前缀查询,不过我们就得把表中的数据全部逆序存储一下,也就是说我们可以这样保存 url列中的数据:

这样再查找以 com 为后缀的网址时搜索条件便可以这么写: WHERE url LIKE 'moc%' ,这样就可以用到索引了。
















 1739
1739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











