







目录
1 引言
Elasticsearch(ES)作为分布式搜索引擎,其核心优势在于 高可用性和 高性能查询,而 副本(Replica) 是实现这两大特性的关键机制。本文将探讨:
- 副本在Elasticsearch中的核心作用
- 副本与主分片的关系
- 副本如何提升系统可用性和查询性能
- 副本配置的最佳实践
2 什么是副本(Replica)?
副本是主分片(Primary Shard)的 完整拷贝,存储相同的数据,但 不直接参与写入操作。它的核心价值体现在:
- 数据冗余:防止数据丢失
- 故障恢复:主分片宕机时自动接管
- 负载均衡:分担查询请求,提高吞吐量

流程说明:
- 客户端写入数据到主分片(P0)
- 主分片将数据同步到所有副本(R0、R1)
- 副本完成同步后返回确认,写入操作完成
3 副本的核心作用
3.1 保障高可用性
当主分片不可用时,Elasticsearch会自动 将副本提升为新的主分片,确保服务不中断:

故障恢复流程:
- 节点监测到主分片P0不可用(心跳超时)
- 集群重新选举,副本R0被提升为新主分片
- 新主分片继续处理写入和查询请求
3.2 提升查询性能
副本可以 并行处理查询请求,显著降低高并发场景下的延迟:
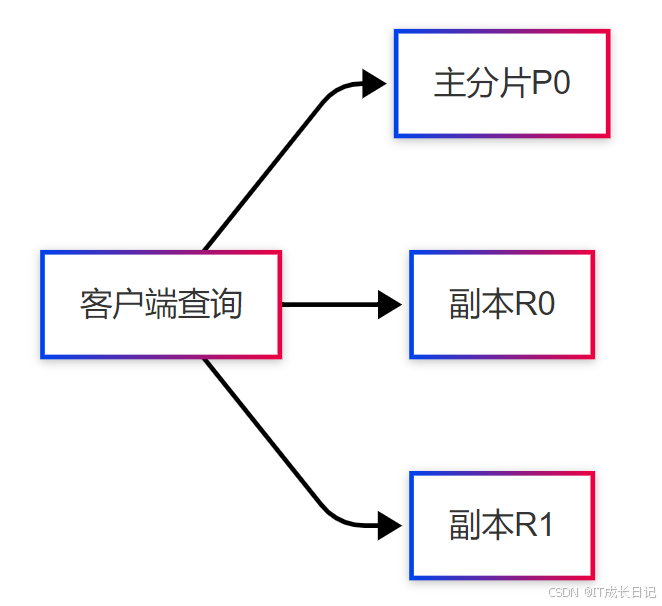
查询分发机制:
- Elasticsearch的协调节点(Coordinating Node)会轮询所有可用分片(主分片+副本)
- 读请求负载均衡到不同节点,避免单点过载
3.3 数据可靠性保障
副本通过 多副本存储策略防止数据丢失:
- 默认配置"number_of_replicas": 1表示每个主分片有1个副本
- 可配置为2或更高,适用于金融级数据安全要求
4 副本与主分片的协同机制
4.1 写入流程详解
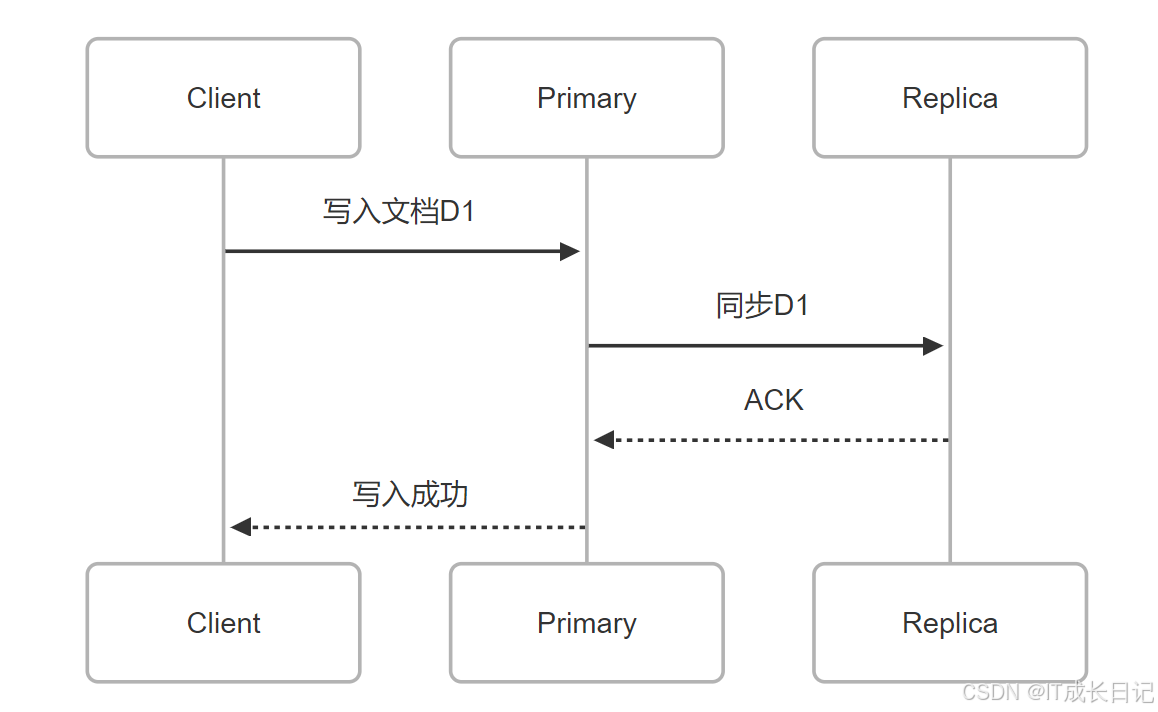
Elasticsearch采用 写一致性策略(默认quorum):
- 必须成功写入(number_of_replicas + 1) / 2个分片(含主分片)
- 避免"脑裂"导致数据不一致
4.2 数据同步原理
副本通过 事务日志(Translog) 实现可靠同步:
- 主分片先将操作记录到Translog
- 异步将数据刷新(Refresh)到Lucene段文件
- 副本通过分段拉取方式保持数据一致
5 副本配置最佳实践
5.1 副本数量设置
| 场景 | 推荐值 | 说明 |
| 开发环境 | 0 | 节省资源 |
| 生产环境(常规) | 1 | 平衡可靠性与资源消耗 |
| 关键业务(金融/医疗) | 2~3 | 更高容错能力 |
- 动态调整命令:
PUT /my_index/_settings
{
"number_of_replicas": 2
}5.2 跨机架/可用区部署
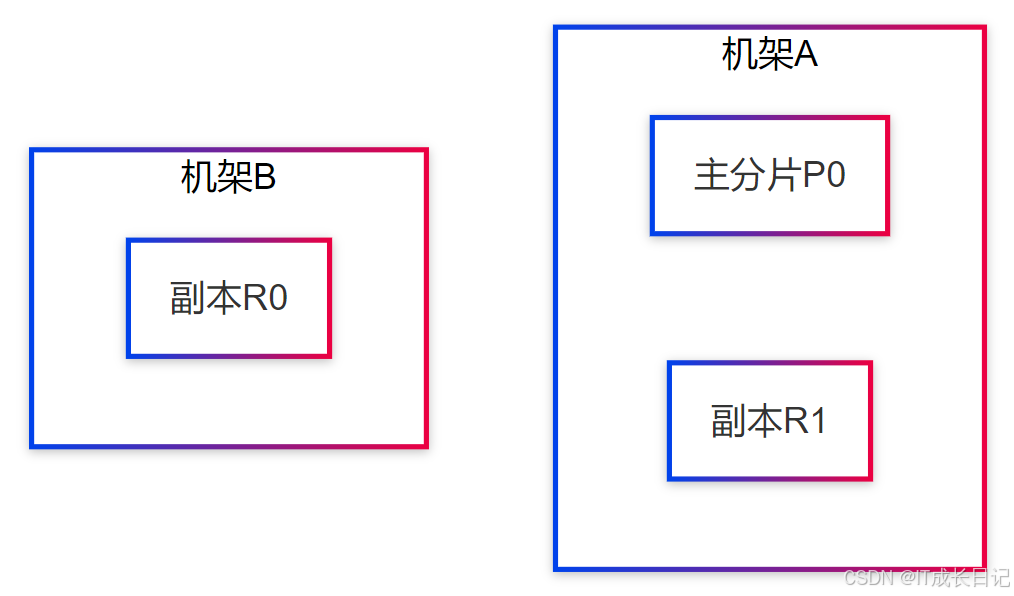
优势:
- 防止整个机架断电导致数据不可用
- 通过awareness属性强制跨域分布:
"cluster.routing.allocation.awareness.attributes": "rack"5.3 监控与调优
- 关键指标:
- unassigned_shards:未分配的副本数
- indexing_latency:副本同步延迟
- 优化建议:
- 避免单个节点承载过多副本(导致资源争抢)
- 热点索引可单独增加副本数
6 常见问题解决方案
Q1: 副本同步延迟高怎么办?
- 检查网络带宽和磁盘IO
- 调整refresh_interval(默认1秒):
PUT /my_index/_settings
{
"refresh_interval": "30s"
}Q2: 如何强制恢复丢失的副本?
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "all"
}
}Q3: 副本分片能变成主分片吗?
- 可以通过_cluster/reroute手动触发:
POST _cluster/reroute
{
"commands": [
{
"allocate_replica": {
"index": "my_index",
"shard": 0,
"node": "node-1"
}
}
]
}7 总结
副本机制是Elasticsearch架构设计的精华所在,通过:
- 数据冗余:抵御节点故障风险
- 负载均衡:提升查询吞吐量
- 自动故障转移:实现服务高可用
配置黄金法则:
- 生产环境至少配置1个副本
- 关键业务跨机架/可用区部署
- 监控unassigned_shards等核心指标
理解副本的工作原理,才能充分发挥Elasticsearch的分布式优势。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











