







 本文详细指导了如何在Windows系统上安装VS2017,配置CUDA环境,包括CUDA的下载、安装步骤,以及如何在VS2017中创建、配置CUDA项目,涉及添加系统变量、环境变量和编译设置。最后介绍了在Clion中使用CUDA的教程和常见错误排查。
本文详细指导了如何在Windows系统上安装VS2017,配置CUDA环境,包括CUDA的下载、安装步骤,以及如何在VS2017中创建、配置CUDA项目,涉及添加系统变量、环境变量和编译设置。最后介绍了在Clion中使用CUDA的教程和常见错误排查。
GPU开发环境配置
一、VS2017安装
-
下载VS
下载链接:需要登陆微软账号,没有注册一个即可

Tips: 如果发现打不开,或者速度很慢,可以设置一下DNS服务器地址,操作方法如下
打开Windows设置,选择网络和Internet

打开网络和共享中心

选择当前连接的网络,然后点击属性


打开Internet协议版本4(TCP/IPv4)

照着下图进行配置,将DNS服务器配置为4.2.2.2

设置完DNS服务器之后再打开微软的网站,可以发现速度快多了。
-
安装VS
安装组件选择,只需要选择最基本的C/C++开发即可

安装位置更改,这里我将软件安装在了E盘,对于文件夹的命名不要出现中文!

点击安装即可

安装完成后打开界面如下

-
创建一个C++项目进行测试


点击确定,等待项目创建完成,项目会自动创建一个cpp文件,测试代码如下:
// test1.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。 // #include <iostream> int main() { std::cout << "Hello World!\n"; } // 运行程序: Ctrl + F5 或调试 >“开始执行(不调试)”菜单 // 调试程序: F5 或调试 >“开始调试”菜单 // 入门使用技巧: // 1. 使用解决方案资源管理器窗口添加/管理文件 // 2. 使用团队资源管理器窗口连接到源代码管理 // 3. 使用输出窗口查看生成输出和其他消息 // 4. 使用错误列表窗口查看错误 // 5. 转到“项目”>“添加新项”以创建新的代码文件,或转到“项目”>“添加现有项”以将现有代码文件添加到项目 // 6. 将来,若要再次打开此项目,请转到“文件”>“打开”>“项目”并选择 .sln 文件执行程序:

可以看到控制台输出结果:

至此VS安装完毕,接下来进行CUDA的安装。
二、CUDA安装
-
下载CUDA
CUDA Toolkit Archive | NVIDIA Developer


-
安装CUDA
双击下载的exe,进行安装

使用默认路径即可

等待解压

解压完成后会自动跳转到下一步,首先会检查系统兼容性,等待,然后出现如下界面,证明系统兼容此版本CUDA。点击同意并继续

点击下一步,这里我选择自定义

选择安装组件,全部勾选

设置安装位置,这里我安装在E盘,然后点击下一步

等待安装


安装完成,点击关闭

-
添加系统变量

点击新建,按照下面的代码添加系统变量
CUDA_SDK_PATH = E:\NVIDIA Corporation\CUDA Samples\v10.1 CUDA_LIB_PATH = %CUDA_PATH%\lib\x64 CUDA_BIN_PATH = %CUDA_PATH%\bin CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64 CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64如:添加
CUDA_SDK_PATH = E:\NVIDIA Corporation\CUDA Samples\v10.1,如下图所示:

所有变量添加完成后的系统变量如下,注意检查变量中不能有多余的空格。

其中CUDA_PATH和CUDA_V10_1是安装CUDA时自动添加的。CUDA _PATH_V10_1中的10_1是你安装CUDA的版本号
-
添加环境变量到PATH
%CUDA_LIB_PATH% %CUDA_BIN_PAHT% %CUDA_SDK_BIN_PAHT% %CUDA_SDK_LIB_PATH%结果如下:

完成后重启电脑。 win+R打开cmd,输入set cuda:

-
检查CUDA是否安装成功
打开cmd,输入:cd E:\NVIDIA GPU Computing Toolkit\CADA\v10.1\extras\demo_suite进入自己安装的目录(注意,安装路径要正确,这里我在安装的时候不小心把CUDA写成了CADA)
输入dir命令可以查看当前路径下的文件,可以看到有一个名为deviceQuery.exe的文件

输入deviceQuery.exe执行,结果如下图所示,Result = PASS表示安装成功了,如果Result = Fail就重装或者更换CUDA的版本。

继续执行当前目录下的bandwidthTest.exe
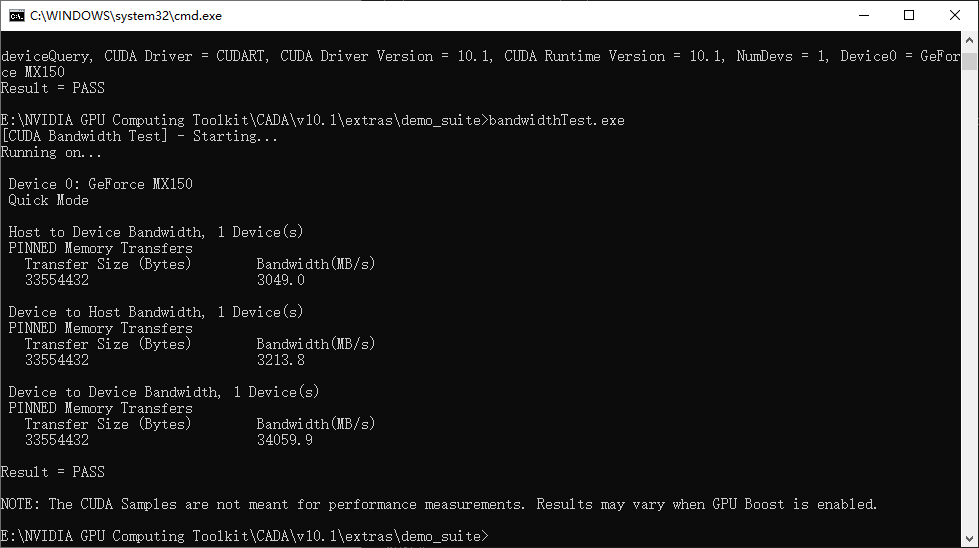
可以看到Result = PASS,证明安装成功。
三、在VS2017中配置CUDA
-
打开VS2017,创建项目

-
添加源文件*.cu


-
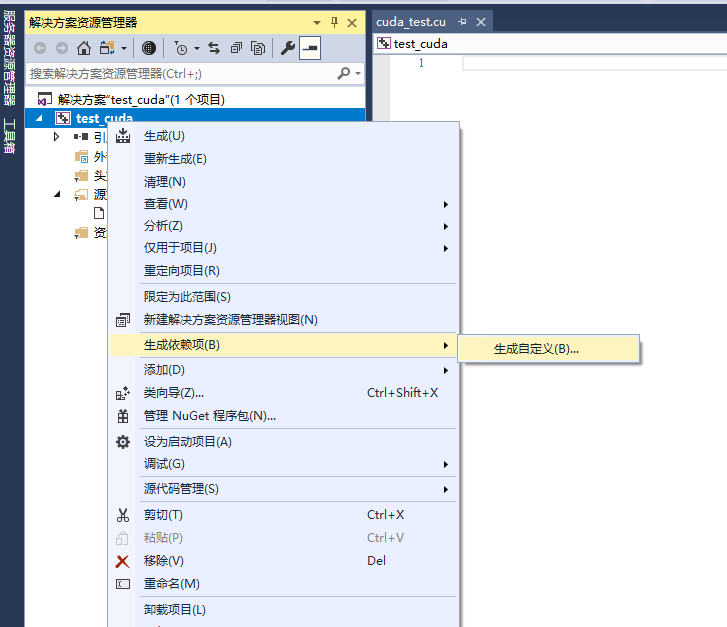
生成依赖项, 右击项目名称test_cuda→生成依赖项→生成自定义→选择CUDA10.1→确定

-
配置cuda_test.cu文件属性 ,右击cuda_test.cu文件→属性→配置属性→常规→项类型→CUDA C/C++


-
配置cuda工程属性,右击test_cuda→属性

在包含目录中添加
E:\NVIDIA GPU Computing Toolkit\CADA\v10.1\include
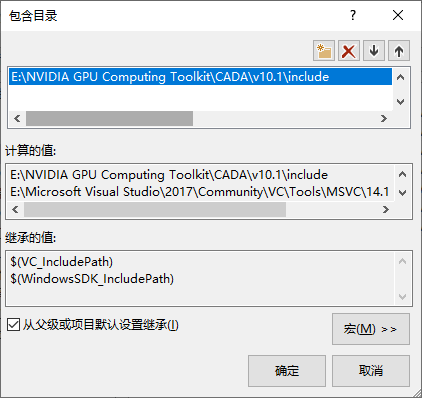
在库目录中添加
E:\NVIDIA GPU Computing Toolkit\CADA\v10.1\lib\x64


注意:要根据自己的CUDA安装添加正确的目录
-
添加依赖项,链接器→输入→附加依赖项。在附加依赖项中添加相应的.lib文件名称

这里将所有的lib都加上了
cublas.lib cublasLt.lib cuda.lib cudadevrt.lib cudart.lib cudart_static.lib cufft.lib cufftw.lib curand.lib cusolver.lib cusolverMg.lib cusparse.lib nppc.lib nppial.lib nppicc.lib nppicom.lib nppidei.lib nppif.lib nppig.lib nppim.lib nppist.lib nppisu.lib nppitc.lib npps.lib nvblas.lib nvgraph.lib nvjpeg.lib nvml.lib nvrtc.lib OpenCL.lib
-
添加测试程序
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> int main() { int deviceCount; cudaGetDeviceCount(&deviceCount); int dev; for (dev = 0; dev < deviceCount; dev++) { int driver_version(0), runtime_version(0); cudaDeviceProp deviceProp; cudaGetDeviceProperties(&deviceProp, dev); if (dev == 0) if (deviceProp.minor = 9999 && deviceProp.major == 9999) printf("\n"); printf("\nDevice%d:\"%s\"\n", dev, deviceProp.name); cudaDriverGetVersion(&driver_version); printf("CUDA驱动版本: %d.%d\n", driver_version / 1000, (driver_version % 1000) / 10); cudaRuntimeGetVersion(&runtime_version); printf("CUDA运行时版本: %d.%d\n", runtime_version / 1000, (runtime_version % 1000) / 10); printf("设备计算能力: %d.%d\n", deviceProp.major, deviceProp.minor); printf("Total amount of Global Memory: %u bytes\n", deviceProp.totalGlobalMem); printf("Number of SMs: %d\n", deviceProp.multiProcessorCount); printf("Total amount of Constant Memory: %u bytes\n", deviceProp.totalConstMem); printf("Total amount of Shared Memory per block: %u bytes\n", deviceProp.sharedMemPerBlock); printf("Total number of registers available per block: %d\n", deviceProp.regsPerBlock); printf("Warp size: %d\n", deviceProp.warpSize); printf("Maximum number of threads per SM: %d\n", deviceProp.maxThreadsPerMultiProcessor); printf("Maximum number of threads per block: %d\n", deviceProp.maxThreadsPerBlock); printf("Maximum size of each dimension of a block: %d x %d x %d\n", deviceProp.maxThreadsDim[0], deviceProp.maxThreadsDim[1], deviceProp.maxThreadsDim[2]); printf("Maximum size of each dimension of a grid: %d x %d x %d\n", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]); printf("Maximum memory pitch: %u bytes\n", deviceProp.memPitch); printf("Texture alignmemt: %u bytes\n", deviceProp.texturePitchAlignment); printf("Clock rate: %.2f GHz\n", deviceProp.clockRate * 1e-6f); printf("Memory Clock rate: %.0f MHz\n", deviceProp.memoryClockRate * 1e-3f); printf("Memory Bus Width: %d-bit\n", deviceProp.memoryBusWidth); } return 0; }运行代码时,注意选择对位数

结果如下
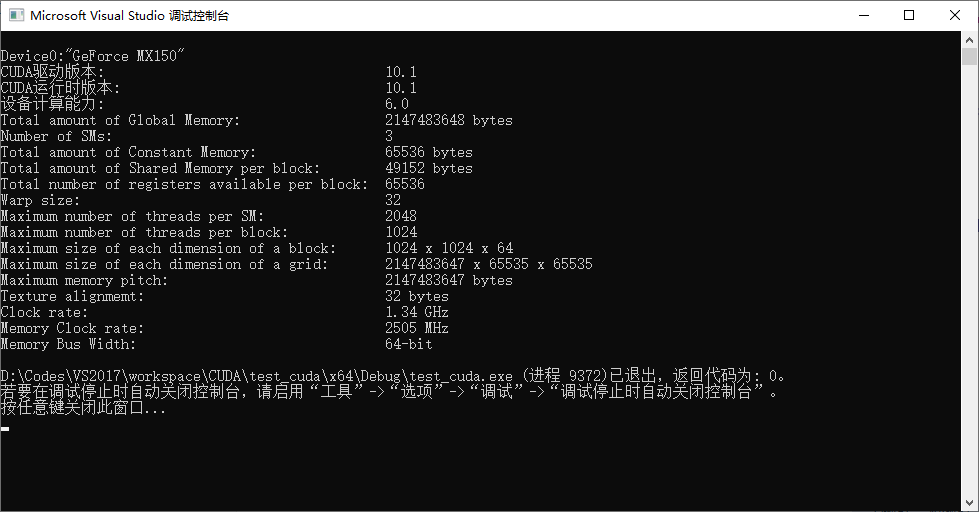
到此,CUDA环境以及VS2017就全部配置完毕!
四、使用Clion编写CUDA代码
使用Clion编写CUDA代码需要保证安装完成VS2017,CUDA,Clion等,其中VS2017和CUDA的安装方法在上面已经给出了,Clion可以参照网上的方法的进行安装。
-
新建工程demo1


点击Create创建工程
-
配置编译工具链,File→Settings→Build→Toolchains

点击+号添Visual Studio环境

点击文件夹的图标设置Toolset,选择VS的安装位置,我的位置为
E:\Microsoft Visual Studio\2017\Community,设置好路径后, 会自动扫描需要的组件,如下图所示
将Architecture选项设置为amd64

然后拖动环境名称Visual Studio到最上面,设置为默认,如下图所示

点击OK,然后添加测试代码
// CUDA runtime 库 + CUBLAS 库 #include "cuda_runtime.h" #include "cublas_v2.h" #include <time.h> #include <iostream> using namespace std; // 定义测试矩阵的维度 int const M = 5; int const N = 10; int main() { // 定义状态变量 cublasStatus_t status; // 在 内存 中为将要计算的矩阵开辟空间 float *h_A = (float*)malloc(N*M * sizeof(float)); float *h_B = (float*)malloc(N*M * sizeof(float)); // 在 内存 中为将要存放运算结果的矩阵开辟空间 float *h_C = (float*)malloc(M*M * sizeof(float)); // 为待运算矩阵的元素赋予 0-10 范围内的随机数 for (int i = 0; i < N*M; i++) { h_A[i] = (float)(rand() % 10 + 1); h_B[i] = (float)(rand() % 10 + 1); } // 打印待测试的矩阵 cout << "矩阵 A :" << endl; for (int i = 0; i < N*M; i++) { cout << h_A[i] << " "; if ((i + 1) % N == 0) cout << endl; } cout << endl; cout << "矩阵 B :" << endl; for (int i = 0; i < N*M; i++) { cout << h_B[i] << " "; if ((i + 1) % M == 0) cout << endl; } cout << endl; /* ** GPU 计算矩阵相乘 */ // 创建并初始化 CUBLAS 库对象 cublasHandle_t handle; status = cublasCreate(&handle); if (status != CUBLAS_STATUS_SUCCESS) { if (status == CUBLAS_STATUS_NOT_INITIALIZED) { cout << "CUBLAS 对象实例化出错" << endl; } getchar(); return EXIT_FAILURE; } float *d_A, *d_B, *d_C; // 在 显存 中为将要计算的矩阵开辟空间 cudaMalloc( (void**)&d_A, // 指向开辟的空间的指针 N*M * sizeof(float) // 需要开辟空间的字节数 ); cudaMalloc( (void**)&d_B, N*M * sizeof(float) ); // 在 显存 中为将要存放运算结果的矩阵开辟空间 cudaMalloc( (void**)&d_C, M*M * sizeof(float) ); // 将矩阵数据传递进 显存 中已经开辟好了的空间 cublasSetVector( N*M, // 要存入显存的元素个数 sizeof(float), // 每个元素大小 h_A, // 主机端起始地址 1, // 连续元素之间的存储间隔 d_A, // GPU 端起始地址 1 // 连续元素之间的存储间隔 ); cublasSetVector( N*M, sizeof(float), h_B, 1, d_B, 1 ); // 同步函数 cudaThreadSynchronize(); // 传递进矩阵相乘函数中的参数,具体含义请参考函数手册。 float a = 1; float b = 0; // 矩阵相乘。该函数必然将数组解析成列优先数组 cublasSgemm( handle, // blas 库对象 CUBLAS_OP_T, // 矩阵 A 属性参数 CUBLAS_OP_T, // 矩阵 B 属性参数 M, // A, C 的行数 M, // B, C 的列数 N, // A 的列数和 B 的行数 &a, // 运算式的 α 值 d_A, // A 在显存中的地址 N, // lda d_B, // B 在显存中的地址 M, // ldb &b, // 运算式的 β 值 d_C, // C 在显存中的地址(结果矩阵) M // ldc ); // 同步函数 cudaThreadSynchronize(); // 从 显存 中取出运算结果至 内存中去 cublasGetVector( M*M, // 要取出元素的个数 sizeof(float), // 每个元素大小 d_C, // GPU 端起始地址 1, // 连续元素之间的存储间隔 h_C, // 主机端起始地址 1 // 连续元素之间的存储间隔 ); // 打印运算结果 cout << "计算结果的转置 ( (A*B)的转置 ):" << endl; for (int i = 0; i < M*M; i++) { cout << h_C[i] << " "; if ((i + 1) % M == 0) cout << endl; } // 清理掉使用过的内存 free(h_A); free(h_B); free(h_C); cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); // 释放 CUBLAS 库对象 cublasDestroy(handle); getchar(); return 0; }修改CMakeLists.txt文件(CMake配置参考CLion中使用CMake导入第三方库的方法_hankerbit的博客,CLion中使用CMake导入第三方库的方法_atarik@163.com )
# cmake verson,指定cmake版本 cmake_minimum_required(VERSION 3.21) # project name,指定项目的名称,一般和项目的文件夹名称对应 project(demo1 CUDA) set(CMAKE_CUDA_STANDARD 14) set(INC_DIR E:\\NVIDIA GPU Computing Toolkit\\CADA\\v10.1\\include) set(LINK_DIR E:\\NVIDIA GPU Computing Toolkit\\CADA\\v10.1\\lib\\x64) # head file path,头文件目录 include_directories(${INC_DIR}) # 指定头文件的搜索路径,相当于指定 gcc 的 - I 参数 link_directories(${LINK_DIR}) # 动态链接库或静态链接库的搜索路径,相当于 gcc 的 - L 参数 link_libraries(cublas cublasLt cuda cudadevrt cudart cudart_static cufft cufftw curand cusolver cusolverMg cusparse nppc nppial nppicc nppicom nppidei nppif nppig nppim nppist nppisu nppitc npps nvblas nvgraph nvjpeg nvml nvrtc OpenCL) # All targets link with the same set of libs # add executable file,添加要编译的可执行文件 add_executable(demo1 main.cu) set_target_properties(demo1 PROPERTIES CUDA_SEPARABLE_COMPILATION ON) # add link library,添加可执行文件所需要的库,比如我们用到了libm.so(命名规则:lib+name+.so),就添加该库的名称 target_link_libraries(demo1 cublas) # 添加链接库, 相同于指定 - l 参数点击三角符号运行程序

可以看到控制台的输出

五、错误总结
-
在第一次执行程序的时候出现如下问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RXNHidiQ-1639213597856)(C:\Users\13751\AppData\Roaming\Typora\typora-user-images\image-20211207161509944.png)]](https://i-blog.csdnimg.cn/blog_migrate/c1b07dfdf6aadbc0dbdfb0ebd874b13e.png#pic_center)
原因是在配置库目录和包含目录的时候,路径不对,改为自己安装的正确路径即可,然后就是包含的库要完整,建议将所有的库都包含上,一定要正确配置路径
配置正确后,再执行程序,得到正确结果。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









