










大家好,作者就本篇博客分享自己在学习KMP算法的时候遇到的难点,我在学习KMP算法的时候也在网上看了不少视频和资料,但发现对其中个别问题讲的都不太透彻,所以本文针对这些问题做出更加浅显易懂的解释,也就是相关理论证明比较少,旨在结合自己的理解用最直白的话说出对KMP的学习心得,希望能尽可能的帮助一些朋友加深对KMP算法的认识,同时也希望得到朋友们的指点!
说明:
1:由衷的感谢sofu6以及July所写博客对本文的大力支持,文中的部分插图源自sofu6。
2:本文没有对相等前后缀(很简单,不必担心不懂)的概念做出解释,如果有需要请评论区留言!
3:本文尚未对Next数组优化问题进行说明,不过后续会补上,敬请期待!
4:下面是我自己学习时遇到的问题,以这几个问题为主线解释KMP算法。
- 为什么主串不回溯,模式串回溯到对应Next数组值下标处?
- 为什么会有Next[ 0 ] = -1 这个初始化?
- 如何求Next[j + 1]呢?
一:引言
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。KMP算法的时间复杂度O(m+n)
二:简单模式匹配算法
子串的定位操作通常称为串的模式匹配,它求的是子串(模式串)在主串中的位置,最常见的应用也就是关键字搜索了。针对一般的方法我们也称之为暴力解法,顾名思义,没有半点技巧,重复回溯,重复比较,时间复杂度为O(m * n)。
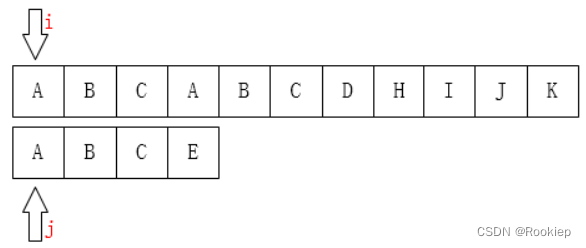
如上图,我们一开始从左到右依次匹配,当遇到不匹配的时候,模式串回退到起始位置,主串回退到起始比较的下一个位置,我相信这不难理解!如下图:
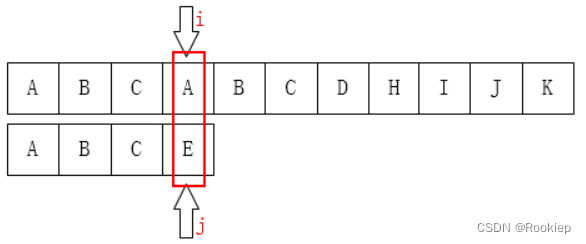
A和E位置处不相等,此时我们 i 回溯到开始比较的下一个位置,j回溯到模式串起始位置。
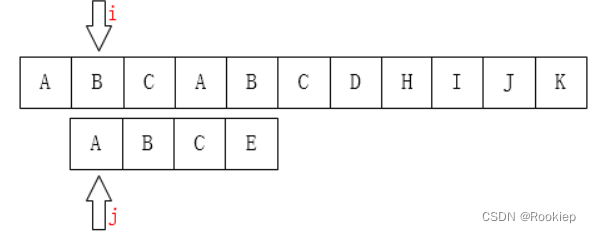
总之就是,如果对应字符匹配,就一起手牵手往下走,一旦闹矛盾(不匹配),模式串就一夜回到解放前(回到模式串首字符),而主串伤敌一千,自损八百(回到开始比较位置的下一位),然后两者又重新开始比较。
暴力匹配的问题就在于想问题太简单,完全没有珍惜自己的过去(没有利用已经匹配过的信息),我们思考一个问题🔎⁉️:
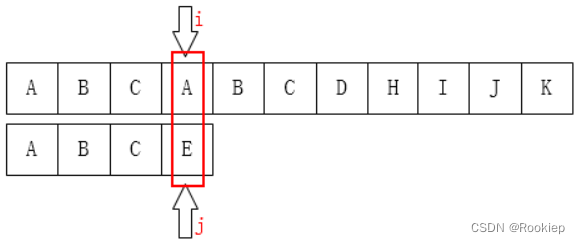
我们人是高级动物,针对这种不匹配情况,我们下一步会怎么去匹配?
💡💡💡当然,我们一眼看去就知道 i 不用回溯,把模式串的首位右移到 i 位置(也即 j 回到首位),为什么呢?因为在已匹配的信息中,主串前面除了第一个位置是A(同时也是模式串的第一个字符),下一个A的位置就是 i 的位置了,所以也只有从这个位置开始才有可能匹配!这就是我们人类思考问题利用了先验知识。科学家们也就想到把这种利用先验信息的思想运用到计算机上,这也是KMP算法最核心的思想,即利用匹配失败位置前面匹配成功字符串的信息,避免主串的回溯和尽量减少模式串的回溯,以达到快速匹配的目的。
暴力匹配代码:
int ViolentMatch(string& s, string& t)
{
int sLen = s.size();
int tLen = t.size();
int i = 0, j = 0;
while (i < sLen && j < tLen)
{
if (s[i] == t[j]){
i++;
j++;
}
else{
i = i - j + 1;
j = 0;
}
}
if (j == tLen){
return i - j;
}
else{
return -1;
}
}
下面我直接给出KMP代码,以供我们对比两种算法的区别:
int KmpSearch(string& s, string& t)
{
int i = 0,j = 0;
int tLen = t.size();
int sLen = s.size();
/*vector<int> Next;
Next.resize(tLen, 0);
GetNext(t, Next);*/
while (j < tLen && i < sLen)
{
if (j == -1 || s[i] == t[j]){
i++;
j++;
}
else {
j = Next[j];
}
}
if (j == tLen) {
return (i - j);
}
else {
return -1;
}
}
✔️我们观察上面两段代码最大的区别就在于当发生不匹配的时候回溯的问题,这也是KMP算法最大的改进点,从一定程度上大大优化了匹配效率。
三:KMP算法思想
简单一句话:就是当模式串的某个字符与主串的某个字符不匹配的时候,保证主串不回溯,子串的 j 应该回溯到什么位置。
下面我们简单看两个匹配情况,浅析一下它的规律:
🅰️情景一:
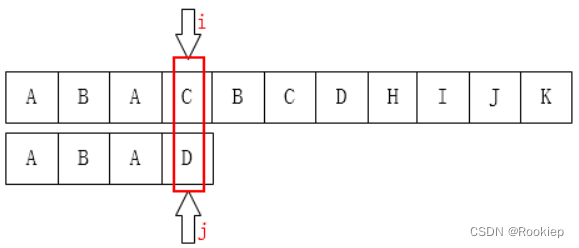
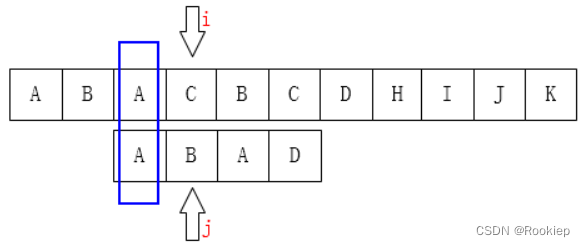
回溯:
🅱️情景二:
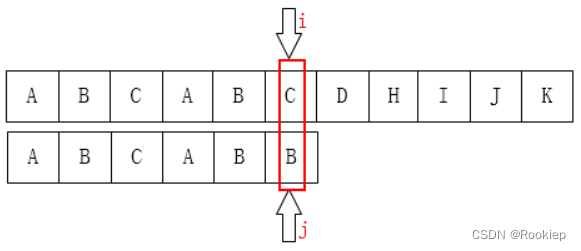
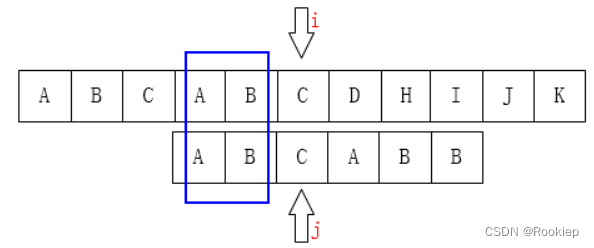
回溯:
说明:字符串下标以及后文的Next数组下标均是从0开始!
我们看上面两种kmp的回溯是否发现了一点端倪?
当在模式串的下标为 J 的位置处不匹配时,那么在比较指针的左侧主串与模式串对应的J个字符子串是完全匹配的,而且这个子串最前面的K个字符和最后面的K个字符是一样的(也就是最长相等前后缀),这个K也就是匹配失败后J要回溯到的下标。
我在学习的时候遇到的第一个问题❔❔❔就是,为什么回溯到这里?学习的时候虽然感觉是对的,但总是迷迷糊的,说服不了自己!💢
对此做出解释对上面发生的根本原因:
📘用公式表述就是:P[0 ~ k-1] = P[j - k ~ j-1]。
📒用白话表述就是:模式串下标J前面的子串中前K个字符和后K个字符一模一样!
📙用图形表述就是:
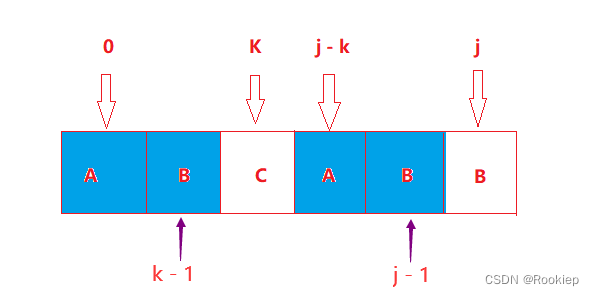
那么为什么J回溯到下标为K的位置呢? 下面证明:
📘用公式说:
S[ i ] != P[ j ]时:
有S【i - j ~ i - 1】= P【0 ~ j - 1】;
由上文:P[0 ~ k-1] = P[j - k ~ j-1];
所以:S【i - k ~ i - 1】 = P【0 ~ k - 1】;
📒用白话说:在模式串不匹配位置左侧的子串中,子串与对应的主串是完全匹配的,当该模式串子串中存在最长相等前后缀的时候,子串的前K个字符和后K个字符相等,又子串的后K个字符和主串对应的后K个字符相等,由传递性得:子串的前K个字符和主串的后K个字符相等!
📙用图来说:
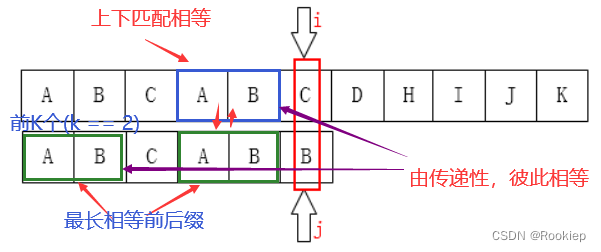
所以:当发生不匹配时,直接移动模式串,使模式串原来的前缀部分移动到后缀原先的位置(也即 j == K),可保证当前比较指针所在的位置左侧的模式串与主串是匹配的!
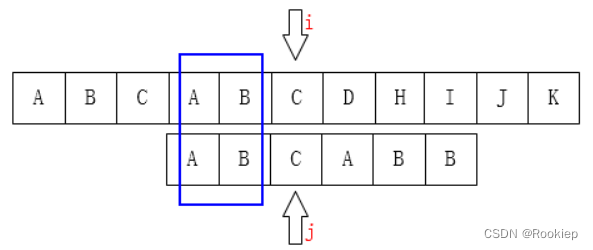
四:求NEXT数组
💥KMP的思想,也即当下标为 J 位置处发生不匹配时,前面第0 ~ J个子串的最长相等前后缀长度为K,那么模式串应该回溯到下标为K的位置处重新匹配。
那么针对每一个位置都可能发生不匹配,这个K在KMP算法中就是用的NEXT数组记录的!
🌹🌹🌹明白了KMP的思想,下一个关键点也就是求Next数组,我相信很多朋友对这个Next数组的理解还是摸棱两可的,那么希望我接下来的思路能够帮助到您!
本文规定:Next【j】代表的含义是:当前字符之前的字符串中,最长的相等前缀后缀的长度。例如如果next 【j】 = k,代表 j 之前的字符串中有最大长度为k 的相同前缀后缀。
说明:规定Next数组的规则并不唯一,可以把最大长度表(也称为前缀表)看做是next 数组的雏形,甚至就把它当做Next数组也是可以的,也可以把前缀表整体右移一位(本文采用的规则),也可以是前缀表右移一位再+1,总之Next数组规定多种多样,区别不过是怎么用的问题。
Next数组的作用也就是在某个字符失配时,该字符对应的 next 值会告诉你下一步匹配中,模式串应该跳到哪个位置(跳到next [j] 的位置)。如果next [j] 等于0或 -1,则跳到模式串的开头字符,若next [j] = k 且 k > 0,代表下次匹配跳到下标为next [ j ] (j = Next [ j ]) 的位置处,而不是跳到开头。
1️⃣第一步:
根据Next[ j ] 的含义,我们初始化Next[ 0 ] = -1;
我遇到的第二个问题❔❔❔就是为什么会有Next[ 0 ] = -1 这个初始化?
💡原来这种情况针对的就是模式串首位就不匹配的情况:
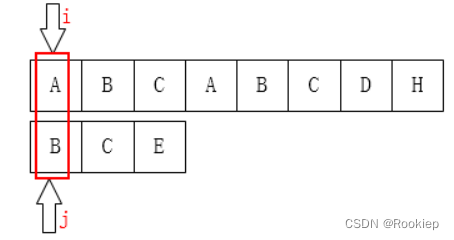
此时j == 0,此时 j 已经在最左边了,不能再回溯了,所以只能让主串的 i 到下一个位置!
我们结合代码来理解就好了:
int KmpSearch(string& s, string& t)
{
int i = 0;
int j = 0;
int tLen = t.size();
int sLen = s.size();
/*vector<int> Next;
Next.resize(tLen, 0);
GetNext(t, Next);*/
while (j < tLen && i < sLen)
{
if (j == -1 || s[i] == t[j])
{
i++;
j++;
}
else {
j = Next[j];
}
}
if (j == tLen) {
return (i - j);
}
else {
return -1;
}
}
当j == Next[ j ] = Next[0] = -1 时,此时 j = 0,也就说明模式串第一个字符与主串当前位置就不匹配,我们不能在回溯模式串,能做的只有让主串下标移到下一个位置。也即这两句代码:
if (j == -1 || s[i] == t[j])
{
i++;
j++;
}
当j = -1 时,i++ 后实现了主串下标移到下一个位置,j++后变为0,也就是模式串第一个字符!
2️⃣第二步:
Next 数组考虑的是除当前字符外的最长相同前缀后缀。
下面我遇到的第三个问题❔❔❔就是如何求Next[j + 1]呢?
当我们求Next[j + 1]时,前面Next [0,1,…,j ]均已经求得,对于Next [ j ] = k,说明在前 j 个元素中前后K个字符相等,也即P[0 ~ k-1] = P[j - k ~ j-1]。
🅰️如果此时还有P [ k ] = P[ j ],那么就有P[0 ~ k-1] + P[k] = p[j-k ~ j-1] + P[j],即P[0 ~ k] = P[j-k ~ j],得出Next[ j + 1 ] = Next[ j ] + 1 = K+1;
上面这段话也就是用文字证明了对于Next [ j ] = k,当P [ k ] = P[ j ]时,有Next[ j + 1 ] = K+1。
下面我们再用画图的方式来解释:
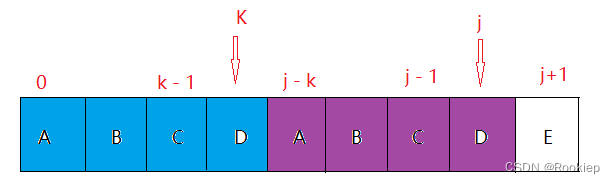
求Next[j + 1]时,Next[ j ] = k,此时有ABC = ABC,若此时P [ k ] = P[ j ],那么在【0~j】的范围,就有前缀ABCD = 后缀ABCD,那么Next[ j + 1] = Next[ j ] + 1 = k+ 1。
🅱️如果此时P [ k ] != P[ j ],那么我们就用到递归找更短的相等前后缀思想求Next [ j + 1] = k + 1(这个k代表什么请继续看后续!):
当P [ k ] != P[ j ]时,相当于在【0~j】的范围内,不存在长度为 k + 1的前缀P [ 0 ~ k] = P [ j - k ~ j ] , 那么我们就要去找更短的相等前后缀,必须保证前缀的最后一个元素等于P [ j ]的同时,前缀其他元素等于P [ j ] 前面对应的元素,此时Next[ j + 1] = k + 1(注意此时k已经经过 k = Next [ k ] 发生变化)。
下面我们直接上图来理解:
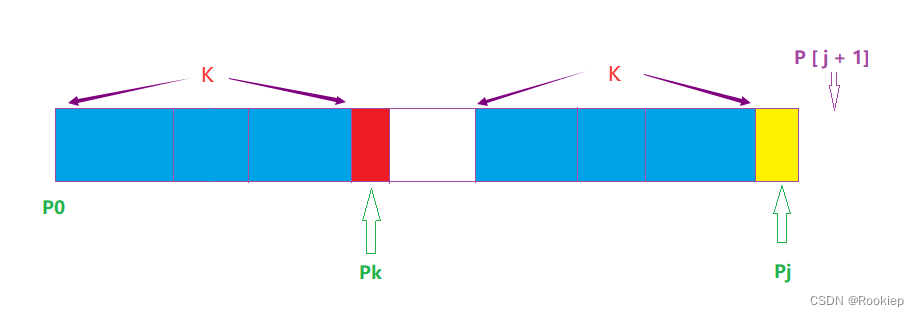
图中两蓝色部分相等(两部分任意对应位置相等),但是红色部分与黄色部分不相等,所以我们需要去找更短的相等前后缀!在此图的基础上往后递归。
在下标为K的字符Next数组的值为Next【k】,递归索引 K = Next【k】,
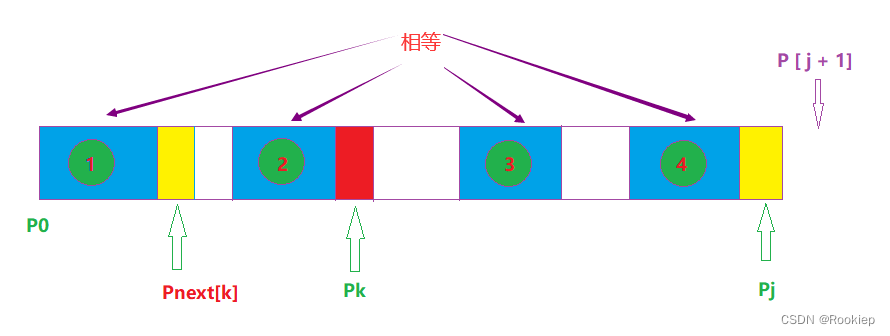
我们通过Next数组来索引,那么1,2,3,4部分均相等,最最最重要的是要证明第1部分和第4部分相等,这句话是非常重要的,(你想嘛,既然是求最长相等前后缀,那么肯定是要求首位两部分咯)。如果此时图中的Pnext[k] = Pj ,那么就有此时的Next [ j + 1] = 蓝色区域长度 + 1,也就是Next [ j + 1] = k + 1,不过此时的K是经历过更新的!
总结:结合上图来讲,若能在前缀“ P[ 0 ~ k ] ” 中不断的递归前缀索引 k = Next [ k ],找到一个字符Pk’ = Pj, 且满足P[0 ~ k’ - 1] = P[ j-k’ ~ Pj],则最大相同的前缀后缀长度为 k’ + 1,从而Next [ j + 1] = k’ + 1 = Next [ k’ ] + 1。否则如果前缀中没有找到一个字符Pk’ = Pj,则代表没有相同的前缀后缀,Next [ j + 1] = 0。
最后,我简单用文字描述一下KMP算法流程:假设主串匹配到了下标 i ,模式串匹配到了下标 j :
- 如果 j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
- 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),此时主串不回溯(i 不变),模式串回溯到 下标 j = next [j]处。
整体代码:
void GetNext(string& t, vector<int>& Next)
{
int k = -1;
int j = 0;
Next[0] = -1;
int tLen = t.size();
while (j < tLen - 1)
{
if (k == -1 || t[k] == t[j]) {
k++;
j++;
Next[j] = k;
}
else{
k = Next[k];
}
}
}
int KmpSearch(string& s, string& t)
{
int i = 0;
int j = 0;
int tLen = t.size();
int sLen = s.size();
vector<int> Next;
Next.resize(tLen, 0);
GetNext(t, Next);
while (j < tLen && i < sLen)
{
if (j == -1 || s[i] == t[j])
{
i++;
j++;
}
else {
j = Next[j];
}
}
if (j == tLen) {
return (i - j);
}
else {
return -1;
}
}
由衷的感谢看到这里的朋友,如果对文中内容有不明晰的地方,欢迎评论区指出,谢谢大家!















 1196
1196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









