







How to deal with bad training
some reference
- Eigen value:特征值
- Overfit :过拟合
- Critical point :临界点
- batch :批处理
- small batch :小批量
- Batch Normalization:批量标准化
- Feature Normalization:特征规范化
- Cross Entropy:交叉熵
- One-Hot Vector:独热编码
n维列向量,只有一个索引位取1,其余位置均为0
- soft-max
输入任意值,输出值在0到1之间
如何处理训练不好的情况
首先我们先来看一下这张整体分析图

从上图可以看出训练不好的情况整体分为两种:
- Loss on training data is large 训练数据的误差大
- Loss on training data is small but on testing data is large 训练数据的误差小但是测试数据的误差大
下面分别具体看一下。
1、Loss on training data is large

- Model bias :大海捞针,针根本不在海里。模型过于简单,需要通过增加输入的features、使用Deep Learning 等方式重新设计一个弹性更大的模型。
- Optimization issue :针在海里,却捞不到。
观察一下这张Loss函数的图,我们要做的是通过Optimization找到Loss函数的最小值,也就是这张图的最低点。Optimization一般采用Gradient Descent的方法,如果training的过程中遇到当前最优(Stuck at local minima)、等于0(Stuck at saddle point)、趋近于0(Very slow at the plateau) 等问题,都会导致训练失败。

解决的思路大体上分为两种,有山挡路:一方面,我们可以通过各种方式绕山而行。针对具体问题具体解决,如果卡在critical point,就想办法绕过去或者频繁更新参数减少这种可能性,如果是在“平原地带走不动” ,可以调整参数,增大此时的冲量等等;另一方面,可以直接把山铲平,改变error Surface 的 landscape,为Optimization提供良好的先提条件。
Critical point
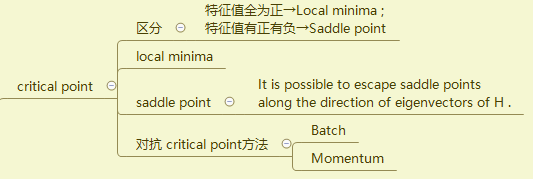
先了解一下什么是critical point。Critical point是梯度为0(或接近于0)的点,包括local minima和saddle point 。将L(θ)在θ’处泰勒展开,得到下图式子,Critical point 位置处绿色框内值为0,可以通过红色框内的值来判断是哪一种critical point。

在临界点处,可以得到如下式子:

接着判断H矩阵特征值的正负(H矩阵里面的元素是L的二次微分),如果所有的特征值都是正的,就是Local minima;如果特征值有正有负,就是saddle point。

判断结束之后,如果是Local minima则无路可走,四周地势都比这个点要高,但可以通过batch和Momentum来有效的对抗Local minima(以及saddle point)的出现;如果是saddle point,则是可以逃离的,那么怎么逃离呢?

答:依然是借助H矩阵。
设λ是矩阵H小于0的特征值,μ是λ的特征向量,由线代知识:

可以得到 L(θ) < L(θ’),也就是说我们应该从现在的位置θ’ 沿着特征向量μ的方向移动到 θ处,就可以逃离鞍点,得到更小的Loss。

Batch and Momentum
上面提到过Batch和Momentum都是可以对抗Critical point的方法,本质上是针对梯度极小或者为0的情况。
Batch,也就是批处理。顾名思义,把整笔资料分成很多份,每一份就是一个batch,每一份资料的大小称为batch size。每次更新是取一个batch的资料,计算Gradient和Loss等参数,字后进行update。把所有的batch过完一遍,就是一个epoch(即把所有训练数据完整的过一遍)

进行批处理的时候,就不得不考虑batch size的问题了。显然,LB(Large Batch)完成一个epoch的速度更快(并行处理),但是SB(Small Batch)进行Optimization的效果更好,这个不难理解,我们取两种极端的情况,如果是Full Batch的话,走到Critical point梯度为0就卡住了;但如果是Small batch,因为是每次挑一个Batch算Loss,这意味着每次的Loss函数都不一样,如果L1的Gradient是0卡住了,继续计算L2 的Gradient不一定卡住,可以继续让Loss变小。所以Noisy update对Optimization,甚至是Generalization都是有利的。
所以我们需要找到一个合适的batch size的值,兼顾Time for one epoch和Optimization的效果。

Momentum很好理解,我就不赘述了,对比看下下面两张图。
- (Vanilla) Gradient Descent

- Gradient Descent + Momentum

关于m的说明:

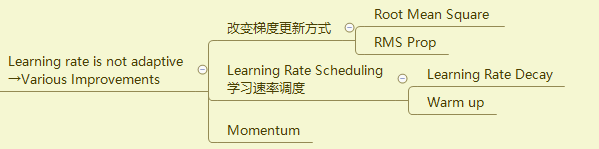
Adaptive Learning Rate
在Optimization时,随着参数的不断update,Loss不再变化,大概率是走到了Critical point吗?其实不是的,李老师说Critical point其实并不常遇到,很有可能是下图所示情况,虽然Loss不再下降,但是gradient并不等于0,在error Surface的两个谷壁之间来回振荡。

再举个例子,下图是convex optimization(凸优化)的error Surface。假设黑色圆圈处是起始点,黄色X是这个error Surface的最低点,我们要从起始点处做gradient descend到底最低点X处。
 )
)
凸优化误差曲面的等高线是椭圆的并且这个椭圆的长轴非常长,gradient非常小,坡度变化非常缓慢;短轴相反,长度很短,且坡度很陡。这就会导致如果lr比较大,参数就会在山壁两端振荡掉不下去;如果lr小了,到了坡度平缓的地方根本走不动。

所以我们需要一个可以自己调节的lr。自适应的lr能够实现在坡度缓的地方变大,在坡度陡的地方变小。即Learning rate需要客制化。
具体优化的流程看下面的流程图吧

Learning Rate Decay和Warm up示意图如下:

最后呈现出来的优化效果就是下图所示:

Classification
说明改变Loss Function可以简化Optimization
Batch Normalization
Batch Normalization就是最前面导图里提到的把山铲平。
因为不同的特征值X差别比较大,所以当不同权重W变化时,对整体值的影响也不一样,批标准化的核心在于归一化。

下图某一列表示同一个特征值的不同元素,绿色框内同一行的值代表不同特征值X的同一纬度,计算出同一行的平均值m,标准差σ,再按照下图中的公式去做归一化。

2、Loss on training data is small but on testing data is large

Overfitting
写到这里,Overfitting才正式出场。所以并不是只要测试结果不好,误差大就是过拟合,只有当训练数据的Loss比较小,但是测试结果的Loss比较大时才有可能是Overfitting。
解决Overfitting最直接的方法是增加训练数据,这个既可以直接增加样本数目,也可以通过data augmentation来达到这一目的。数据增强是什么意思呢?data augmentation就是根据你对一些问题的理解,自己创造出新的资料。举个简单的例子,你原本的训练数据有一只猫和一只狗的图片,现在你可以把它们左右翻转,这样你的训练样本就多了。但是资料的创造要符合常理,做影像辨识的时候,不会把照片上下翻转,因为这不是真实世界会出现的影像。
mismatch
训练集和测试集的分布不一样。















 2165
2165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









