







开设了会议学习系列~
主要注重理解专家的科研和讲述逻辑,以及锻炼画概念图流程图的能力
绘图软件:PPT🤗😏😋
第12期论坛视频链接: AI安全与隐私论坛第12期-密歇根州立大学汤继良教授-可信人工智能中的鲁棒性和公平性可以兼得吗.
1 Introduction

2 研究鲁棒性时,公平性会下降吗?
2.1 生成对抗样本generate adversarial attacks
给定模型
f
f
f、图像
x
x
x和对的标签
y
y
y,有
δ
\delta
δ让模型
f
f
f的误差达到最大:
m
a
x
∥
δ
∥
≤
ϵ
L
(
(
x
+
δ
)
,
y
)
\underset{\left \| \delta \right \| \le \epsilon }{max} L((x+\delta),y)
∥δ∥≤ϵmaxL((x+δ),y)
2.2 比较自然训练和对抗训练的标准误差和对抗误差
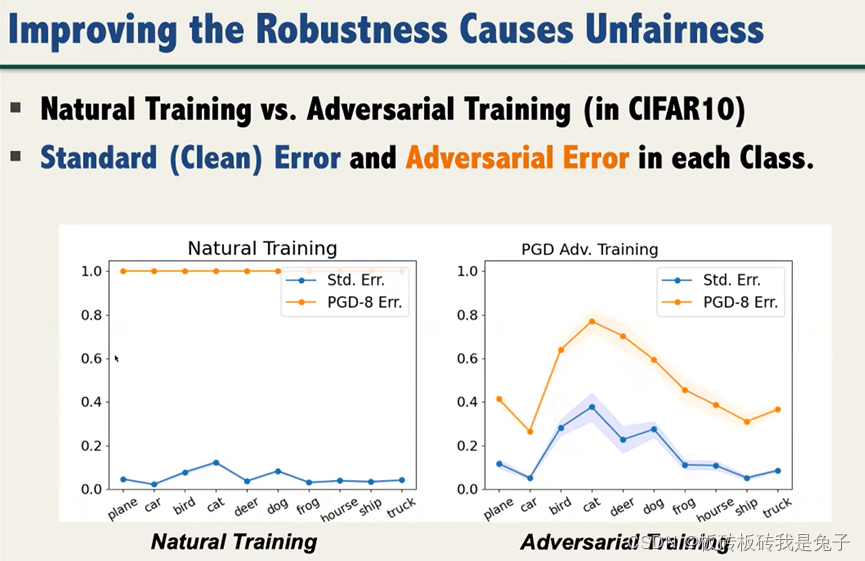
2.2.1 鲁棒性(观察黄色线与与蓝色线的差距)
鲁棒性是观察在加入对抗样本后,误差的变化。可以看出,natural training 的鲁棒性非常差:加入对抗样本后,模型基本上就错了。而对抗训练的鲁棒性就好于自然训练。
2.2.2 公平性(观察线的曲折程度)
公平性是观察针对不同种类的样本,模型的误差差距。可以看出,natrual training 点之间的差距明显小于对抗训练之间点的差距。
2.2.3 结论:提升鲁棒性时,公平性会下降
2.3 实验(证明普遍性)
2.3.1 理论背景
there are some classes whose data are harder to classify.
(class较难指高斯分布较分散)
2.3.2 natural training训练结果
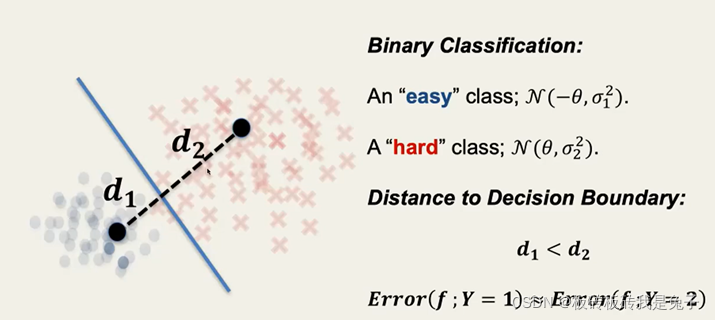
线性分类模型最终得到的判定边界距简单的class较近。
2.3.3 对抗训练结果
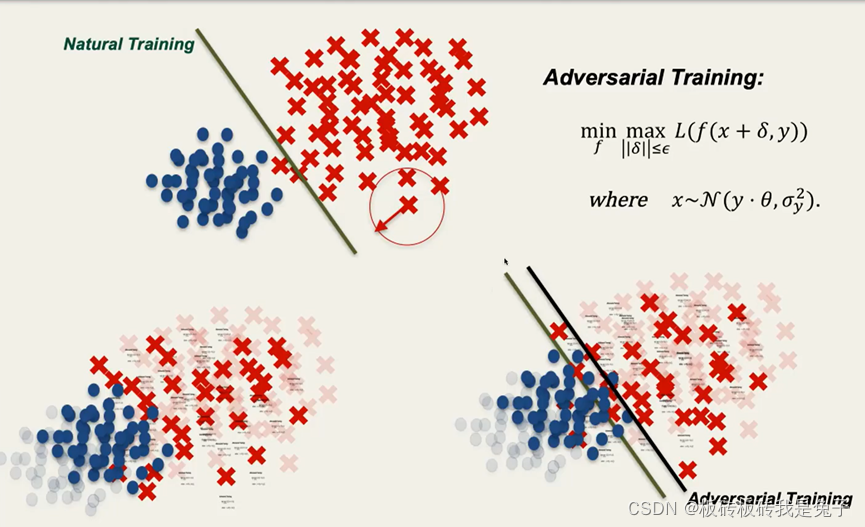
判定边界向难的class方向移动。
2.3.4 实验结论
对抗训练让简单class的分类结果更加精确,让难的class分类结果误差更大(简单的更简单,难的更难)。即,一般情况下,对抗训练会造成不公平的问题。

2.4 解决方案:如何在对抗训练中获得公平性
2.4.1 理论框架
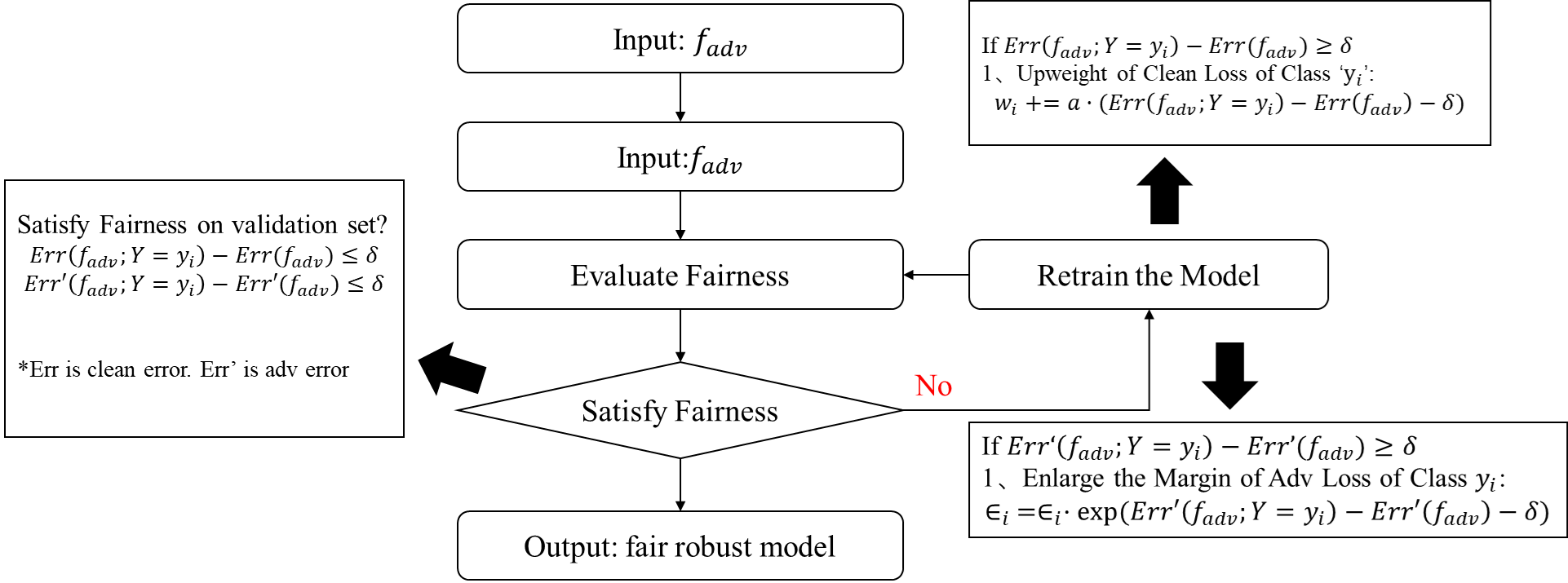
2.4.2 实验结果
在保证整体表现的同时,可以提高误差下限。
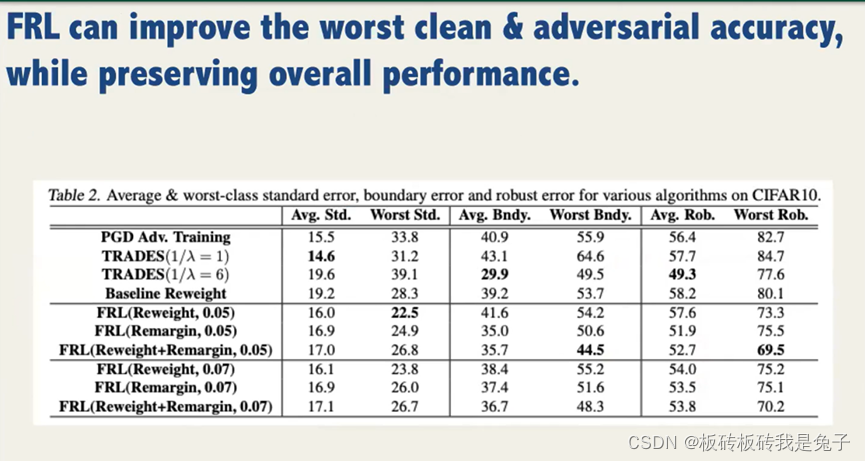
3 在保证公平性时,会让鲁棒性下降吗?
3.1 公平训练和公平性
3.1.1公平训练 Objective of Fair Training
m
i
n
f
L
(
f
;
D
c
)
s
.
t
.
g
j
(
D
c
;
f
)
≤
τ
.
∀
j
∈
Z
(
F
a
i
r
n
e
s
s
c
o
n
s
t
r
a
i
n
t
s
)
\begin{matrix} \underset{f }{min} L(f;D_c) \\ s.t.g_{j}(D_c;f)\le \tau. \forall j\in Z(Fairness constraints) \end{matrix}
fminL(f;Dc)s.t.gj(Dc;f)≤τ.∀j∈Z(Fairnessconstraints)
Notes:
D
c
D_c
Dc: clean training data
Z
Z
Z: all sensitive groups
3.1.2 公平的定义
在保证整体loss最优的情况下,不同group的loss的差距要小于特定值。
3.2 生成药饵攻击样本
The objective of Poisoning Attack:
m
a
x
D
p
L
(
f
;
D
c
)
s
.
t
.
f
∗
=
a
r
g
m
i
n
L
(
f
;
D
c
∪
D
p
)
a
n
d
g
j
(
D
c
∪
D
p
;
f
)
≤
τ
.
∀
j
∈
Z
\begin{matrix} \underset{D_p }{max} L(f;D_c) \\ s.t.f^* = argmin \quad L(f;D_c\cup D_p)\\ and \quad g_j(D_c\cup D_p;f)\le \tau. \forall j\in Z \end{matrix}
DpmaxL(f;Dc)s.t.f∗=argminL(f;Dc∪Dp)andgj(Dc∪Dp;f)≤τ.∀j∈Z
让样本的导入导致公平训练结果的错误率尽可能地高。
3.3 实验:公平训练导致鲁棒性下降的原因
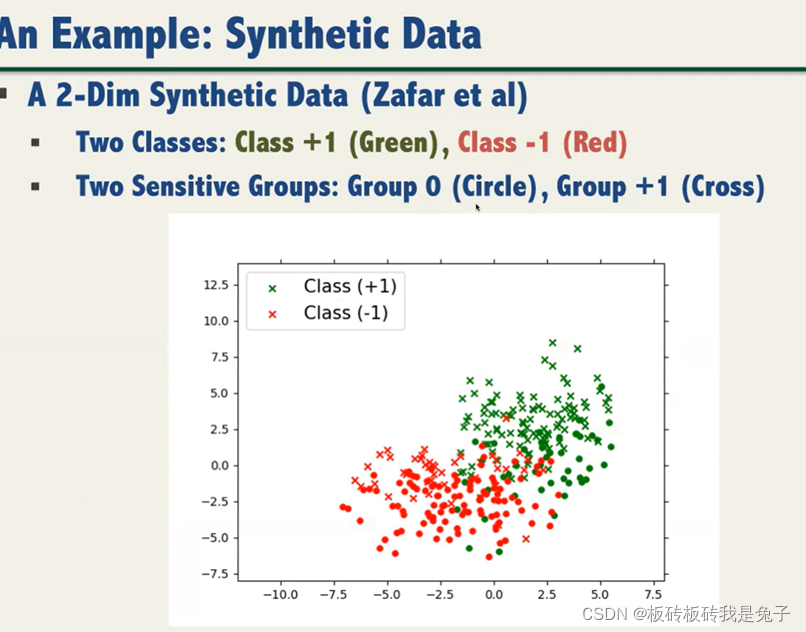
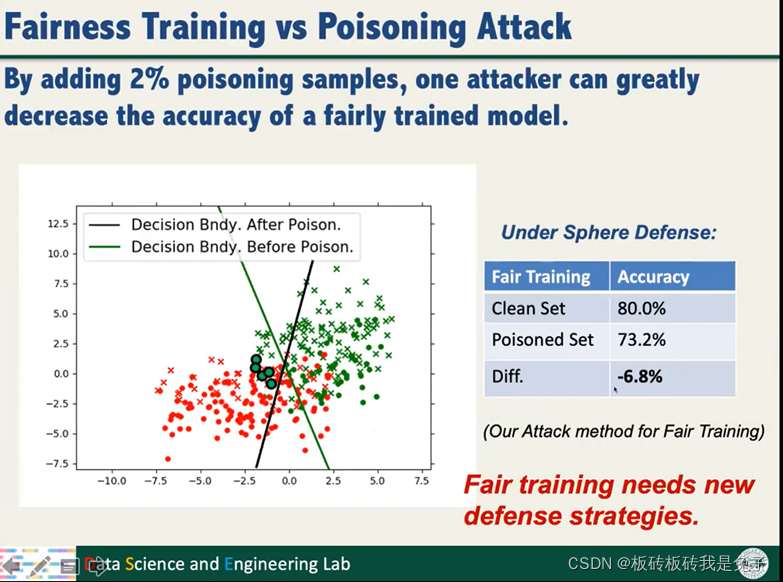
运用sphere defense方法,Natural training情况下,poison sample的攻击对accurancy影响不大。但是fairness training的情况下差别很大。
以上实验证明公平训练需要新的防御机制。
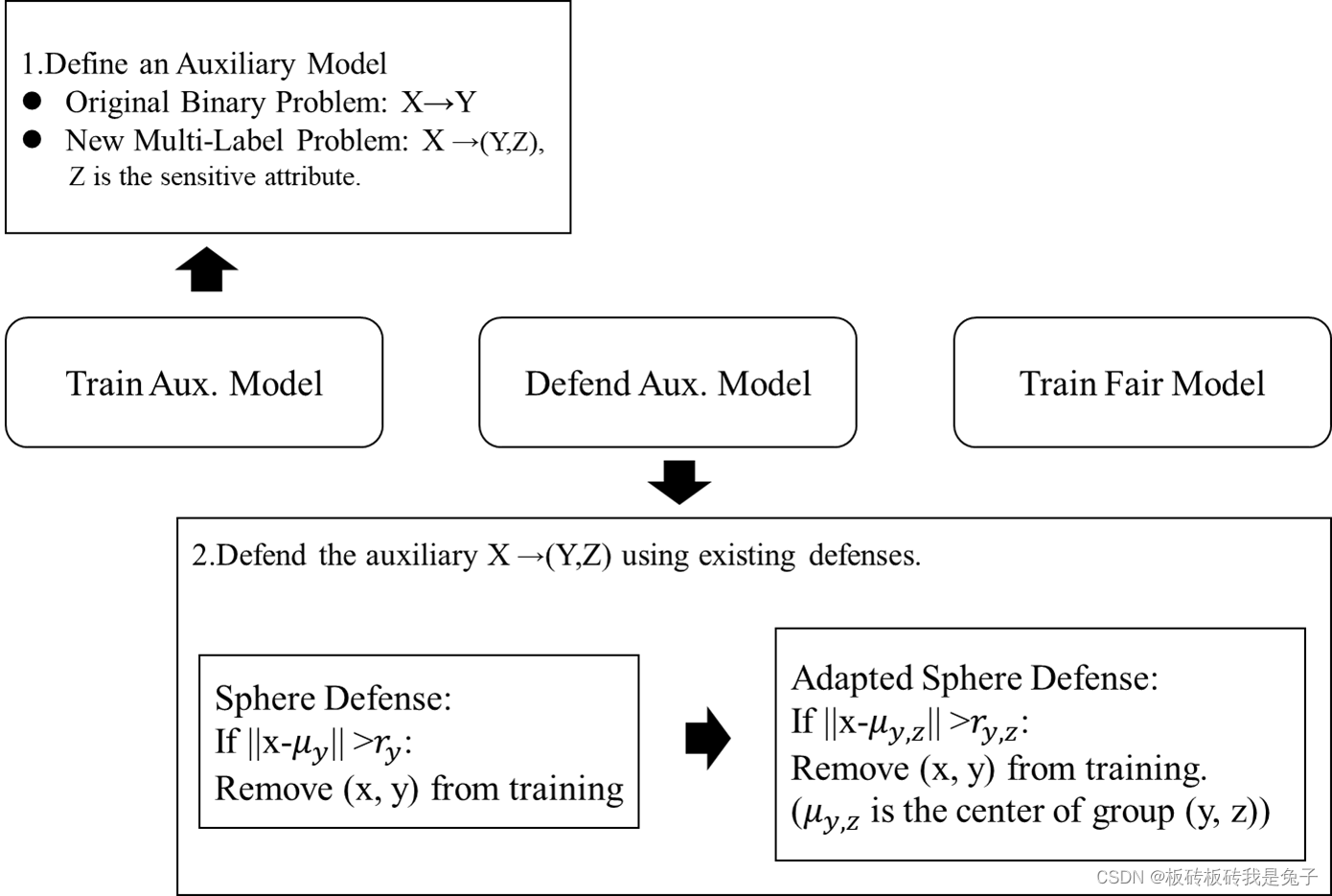
3.4 解决方案
Poison sample距离错误的样本的中心很近。Sphere defense会一初每个class的异常值。而公平学习不仅考虑label,还有考虑sensitive information(poison sample 也会考虑这个)。
所以我们也可以考虑移除每个sensitive group的异常值。
4 Conclusion
4.1 研究结论
AI Robustness and Fairness are related.
- Improving adversarial robustness can cause fairness issues.
- Fairness training can make AI models more vulnerable.
4.2 研究展望
目前的鲁棒性还没有达到要求。应当从以下两个方向努力。
- 导入模型的数据就是clean的。即先从perturbed data中找到clean data。
- 开发一些本身就具有鲁棒性的模型。

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









