








 超级会员免费看
超级会员免费看

论文信息

Tailoring Instructions to Student’s Learning Levels Boosts Knowledge Distillation
作者:Yuxin Ren, Zihan Zhong, Xingjian Shi, Yi Zhu, Chun Yuan, Mu Li
发表单位:清华大学, Boson AI(在Amazon AI lab工作时完成)
发表会议:ACL 2023, main conference
Submitted: May 16, 2023
开源代码:https://github.com/twinkle0331/LGTM
Boson AI
一家人工智能大模型应用方向创业公司。创始人为前亚马逊首席科学家李沐,和另一位前亚马逊AI大牛:Alex Smola (李沐的导师)。
ABS
普遍认为性能更卓越的教师模型不一定能带来更强的学生模型,很大程度是是因为当前教师模型训练过程和有效知识迁移之间的差异。
为了加强对教师训练过程的指导,我们引入了蒸馏影响的概念,以确定每个训练样本的蒸馏对学生泛化能力的影响。
在本文提出Learning Good Teacher Matters (LGTM),一个将蒸馏影响纳入教师模型学习过程的有效训练技术。
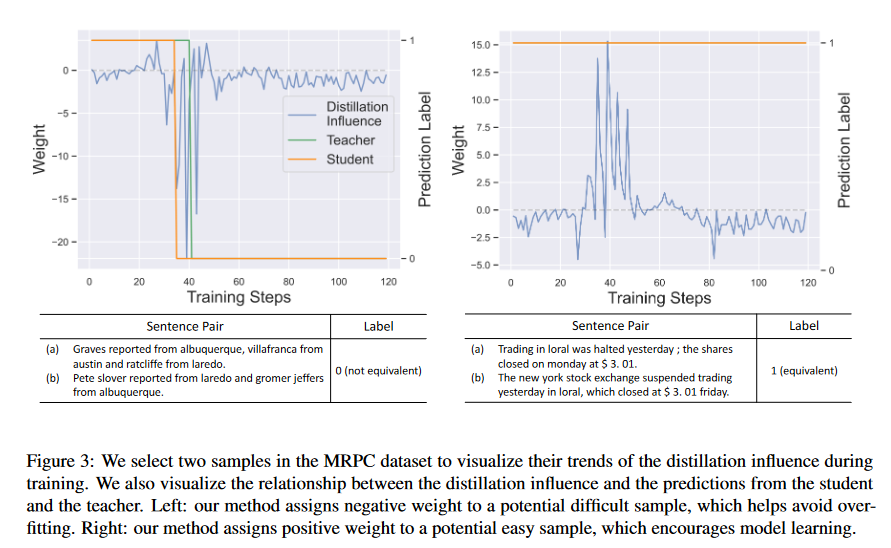
通过优先考虑可能提高学生泛化能力的样本, LGTM 在 GLUE 基准测试中的 6 项文本分类任务上优于 10 个常用的知识蒸馏baselines。
写作分析:ABS总共写了四句话,第一句给出Backgroud(普遍认为更好的教师模型 != > 更强的学生模型)和challenge(教师模型训练过程和有效知识迁移之间存在差异); 第二句给出motivation(加强对教师模型训练过程的指导)和本文method(蒸馏影响加入训练中…),第三句总结强调本文的method(LGTM);最后一句给出本文method带来的main results(超过10个常用的KD方法),以及给出开源代码链接。
INTRO
- NLP近期的成功得益于应用大规模预训练语言模型,模型宽度和深度的增加,带来存储和计算量的增加,难以部署。KD是用于制造高校小模型的一种解决方法,通过模仿更大的教师模型输出来转移知识。
- 理想情况下是性能更好的教师模型可以传给学生模型更多知识,但现有的一些文献说,一个效果更好的教师模型,不一定能教出更好的学生模型。这是由于效果更好的教师模型,往往和学生模型的规模差距更大,这在知识蒸馏的过程中容易产生优化困难的问题,继而导致教师学到的知识不能高效地传递给学生。
- 一种解决KD性能降低的方法是L2T(learning to teach),根据学生的反阿奎调整教师的输出。online distillation 和 meta distillation 是 learning to teach 两种有代表性的方法。然而,前者聚焦于学生在训练集上的反馈,而忽略了学生在验证集上的反馈,可能会削弱学生的泛化能力;后者虽然引入了学生在验证集上的反馈,但却忽略了教师自身在训练集上的学习,仅依靠学生的反馈调整教师的输出,容易导致教师的性能变差。
- 本文从影响函数的角度解释现有的L2T方法,因为分布相同权重给所有训练样本,导致了异常值对优化过程的影响;因此,提出了 LGTM(Learning Good Teacher Matters)模型,包含 distillation influence 的概念,即通过学生在验证集上的输出,评估每个训练样本对其泛化能力的影响,从而动态地分配权重给不同的训练样本。学生难以泛化的样本,会被给予更低的权重。而教师通过学生的反馈,并结合自身在训练集上学习到的知识,能够动态地调整自身输出,从而给予学生更合适的监督信号。
本文贡献:
- 我们提出了蒸馏影响,以量化每个训练样本的蒸馏如何影响学生的泛化能力
- 我们引入了有限差分近似,以有效地将蒸馏影响纳入教师的学习过程
- 与 10 个常见的 KD 基线相比,我们提出的 LGTM 在 GLUE 基准测试中的 6 个文本分类任务上表现出一致的更好性能。
METHOD
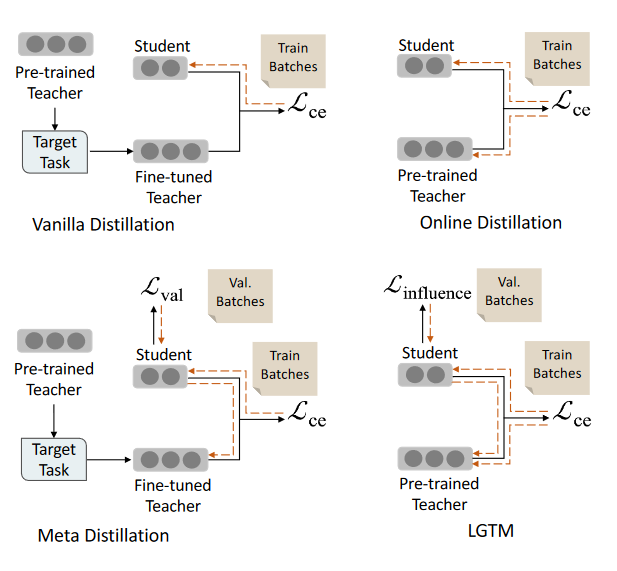
LGTM为one-stage蒸馏,跟online distillation相比,考虑了学生模型dev batches的反馈(ref: meta distillation)。
算法伪代码

公式
1. 蒸馏影响
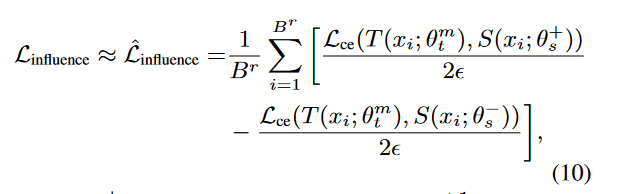
此处使用了有限差分近似(Finite difference approximation),可以看附录A,B了解蒸馏影响及其近似方法
2. 教师模型辅助损失函数
meta distillation的一个缺陷就是忽略教师自身对训练样本的学习,因此引入辅助损失函数。
如下所示, L t L_t Lt 为训练教师模型的目标函数,兼顾学生的反馈和自身学习。
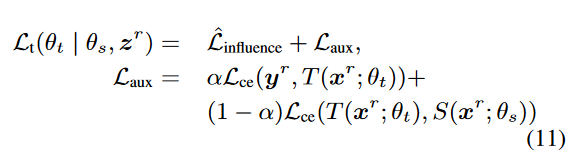
Experiments
与Meta Distillation对比:
LGTM 与元蒸馏工作线密切相关,因此先将LGTM 与特定的元蒸馏方法Meta Distill(Zhou 等人,2022 年)进行比较,以证明采用蒸馏影响的好处。
-
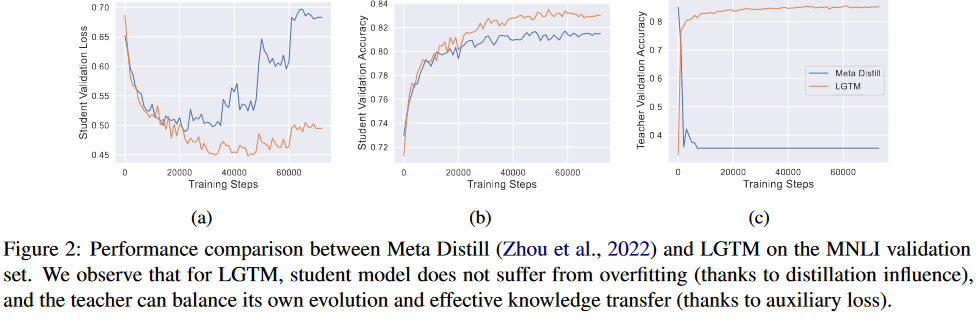
如图Fig2.a.b 学生模型的验证损失在以后的迭代中逐渐增加,而验证准确性不断提高,直到趋于稳定。这清楚地表明学生模型正在经历过度拟合。一种可能的原因是,Meta Distillation过分强调某些产生高loss的训练样本,例如硬样本或异常值。这些会对学生模型的泛化能力产生负面影响,从而导致过度拟合。
-
引入逐个样本的蒸馏影响的有效性: LGTM计算每个训练样本的蒸馏影响,Meta Distillation计算每个batch的所有训练样本的影响。LGTM计算每个样本的方法有助于过滤掉对学生模型泛化能力有损害样本,因此有Fig2.a中更低的验证集损失以及Fig2.b更高的准确率。
-
**教师辅助损失函数的有效性:**如图Fig2.c 教师模型的验证准确性在 LGTM 中不断提高,但在 Meta Distill中迅速下降。
对比BASELINES
- KD with desgining training pipelines or loss functions
- PKD
- SKD
- DIST
- TAKD
- RCO
- online distillation
- DML
- ProKT
- PESF-KD
- meta distillation
- Meta Distill
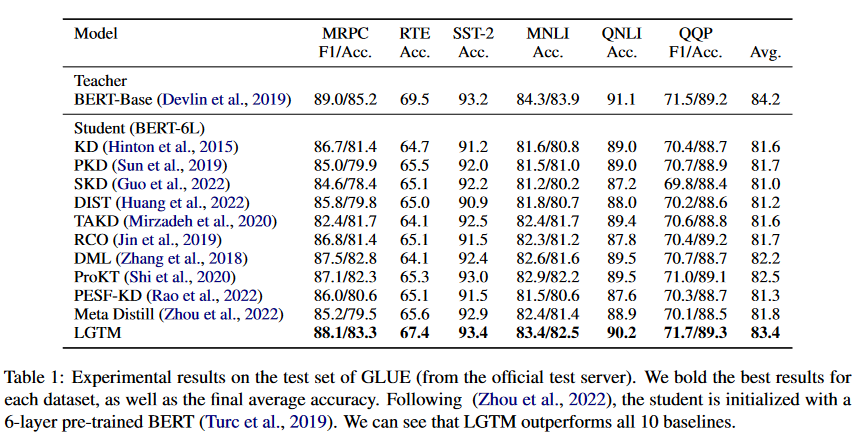
蒸馏影响的分析
如下图展示MRPC两个有代表性的样本,左图是困难样本(教师模型和学生模型初始都分类错误),蒸馏影响值加大,其训练的损失权重调整为负,LGTM会过滤掉该训练样本使模型学习的更快。最终学生模型会先预测正确,通过学生对验证集的反馈,教师模型也学会做出正确的预测。
右图为简单样本,同样给这个样本一个高的正权重,以形成一个对学生模型友好的决策边界。
道德声明
在训练过程中,教师和学生模型从预先训练的模型初始化。然而,正如 Bommasani 等人 (2021) 和 Weidinger 等人 (2021) 所提到的,预先训练的语言模型容易受到潜在的道德和社会风险的影响。因此,教师和学生模型可能会面临与大语言模型类似的社会风险。
这部分是我少见的内容,很少有人声明道德问题,因此我也少有关注。
- Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. 2021. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258.
- Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, et al. 2021. Ethical and social risks of harm from language models. arXiv preprint arXiv:2112.04359.
















 99
99

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











