







本文介绍我们在 Amazon AI lab 期间的工作,文章已被 ACL 2023 主会接收:Tailoring Instructions to Student's Learning Levels Boosts Knowledge Distillation,代码已开源。

文章链接:
https://arxiv.org/abs/2305.09651
代码链接:
https://github.com/twinkle0331/lgtm

简介
大规模预训练语言模型的参数量较大,直接将其部署到下游任务会带来高昂的计算和存储成本。知识蒸馏(Knowledge Distillation)是针对该问题的一种解决方案,通过训练一个小的学生模型,让其模仿教师模型在下游任务上的输出,从而达到和教师模型相近的效果,并降低了部署成本。
但现有的一些文献表明,一个效果更好的教师模型,不一定能教出更好的学生模型。这是由于效果更好的教师模型,往往和学生模型的规模差距更大,这在知识蒸馏的过程中容易产生优化困难的问题,继而导致教师学到的知识不能高效地传递给学生。
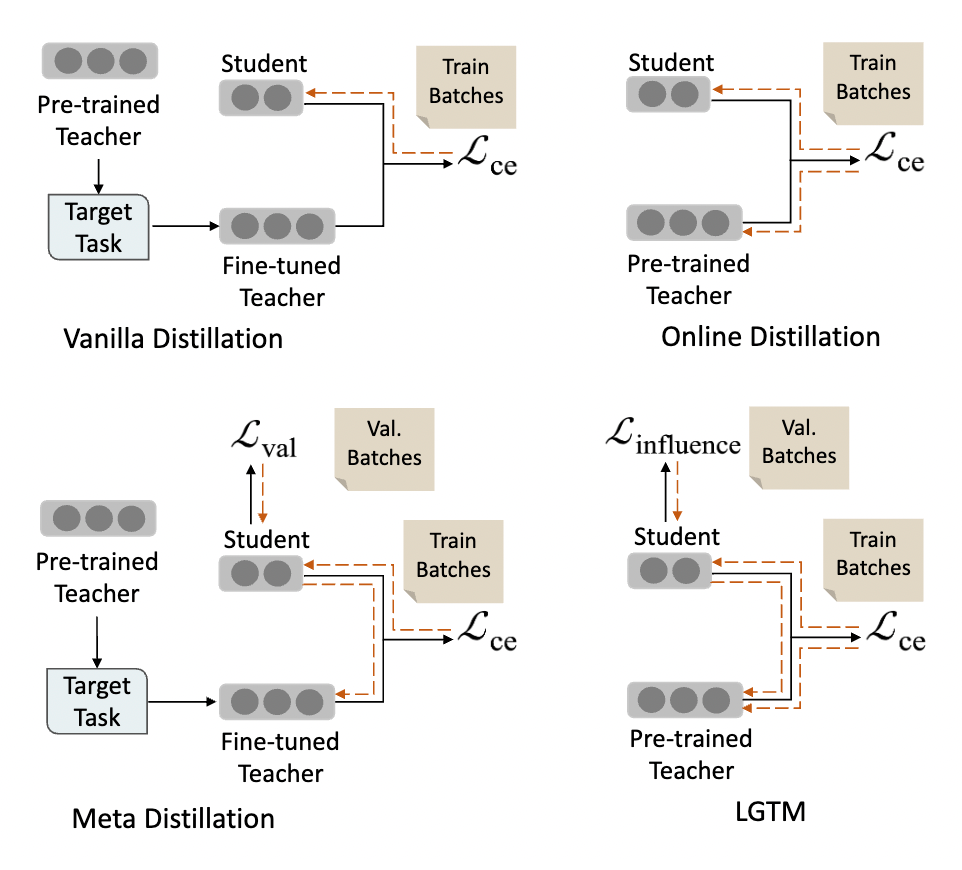
一种解决这种问题的方式是 learning to teach,通过学生的反馈来调整教师的输出。online distillation 和 meta distillation 是 learning to teach 两种有代表性的方法。然而,这两种方法都有不足之处。前者聚焦于学生在训练集上的反馈,而忽略了学生在验证集上的反馈,可能会削弱学生的泛化能力;后者虽然引入了学生在验证集上的反馈,但却忽略了教师自身在训练集上的学习,仅依靠学生的反馈调整教师的输出,容易导致教师的性能变差。
因此,我们提出了 LGTM(Learning Good Teacher Matters)模型,导出了 distillation influence 的概念,即通过学生在验证集上的输出,评估每个训练样本对其泛化能力的影响,从而动态地分配权重给不同的训练样本。学生难以泛化的样本,会被给予更低的权重。而教师通过学生的反馈,并结合自身在训练集上学习到的知识,能够动态地调整自身输出,从而给予学生更合适的监督信号。
下图可以直观地表示不同蒸馏方式间的差异:

方法
在下文的讲解中会用到的数学符号:
: 教师模型,学生模型。 和 分别表示教师和学生在第 m 个训练 step 时的模型参数。
: 训练集,验证集。
: 训练集的一个 batch,包含 个训练样本。 表示 batch 中的一个训练样本。
: 验证集的一个 batch。
: cross entropy loss。
2.1 Distillation influence
Influence function(Pruthi 等 [1];Koh 和 Liang 等 [2]),用来估计每个训练样本对模型预测结果的影响。而在知识蒸馏的场景下,我们可以通过计算每个训练样本和验证集 batch 的梯度相似度,来量化每个训练样本对模型泛化能力的影响。
因此,我们可以从 influence function,导出 distillation influence:
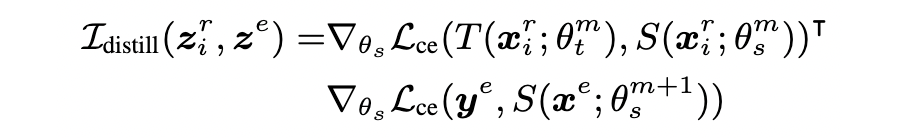
具体推导过程可参考文章的附录A。
为了将 distillation influence 引入教师的训练过程,我们提出了 influence loss:
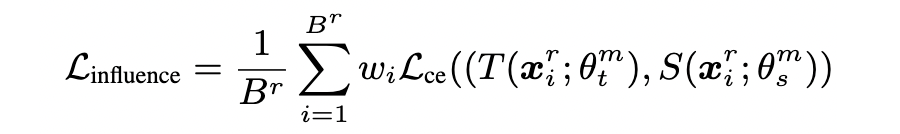
表示每个样本的 distillation influence,有助于增强学生泛化能力的样本,会被赋予更高的权重。
2.2 Finite difference approximation
然而,在计算 中的 distillation influence 时,需要逐一地对训练 batch 里的每个样本计算 这一项的梯度,对 需要计算 次 forward 和 backward,计算效率受限于训练 batch 的大小 。因此,我们可以利用 finite difference [3] 技巧,对 influence loss 进行近似:
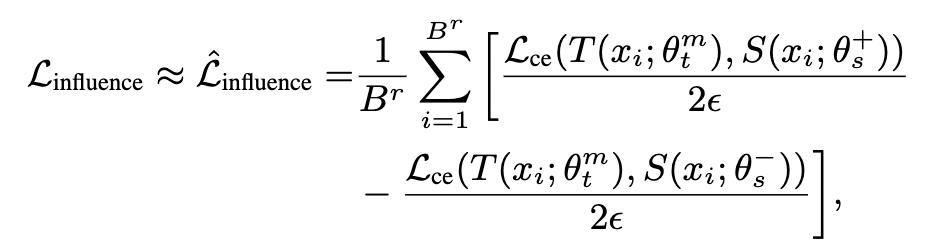
近似后,对于一个 batch 里的所有训练样本,只需对 计算两次 forward,对 计算一次 backward 即可,大大提高了计算效率。
具体推导过程可看文章的附录B。
2.3 Teacher's auxiliary loss
前文提到的 meta distillation 的一个缺陷是忽略了教师自身对训练样本的学习。因此,我们引入了 auxiliary loss。
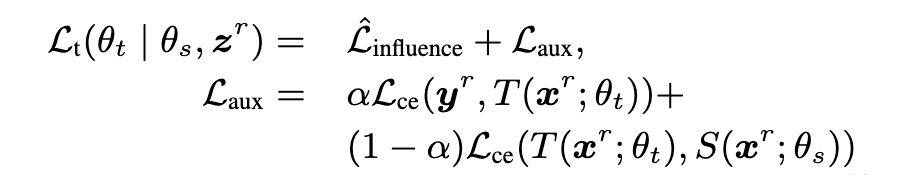
即为最终训练教师的目标函数。 和 的结合,表示教师能兼顾学生的反馈和自身的学习。
下面是我们的方法的总体算法图:


实验
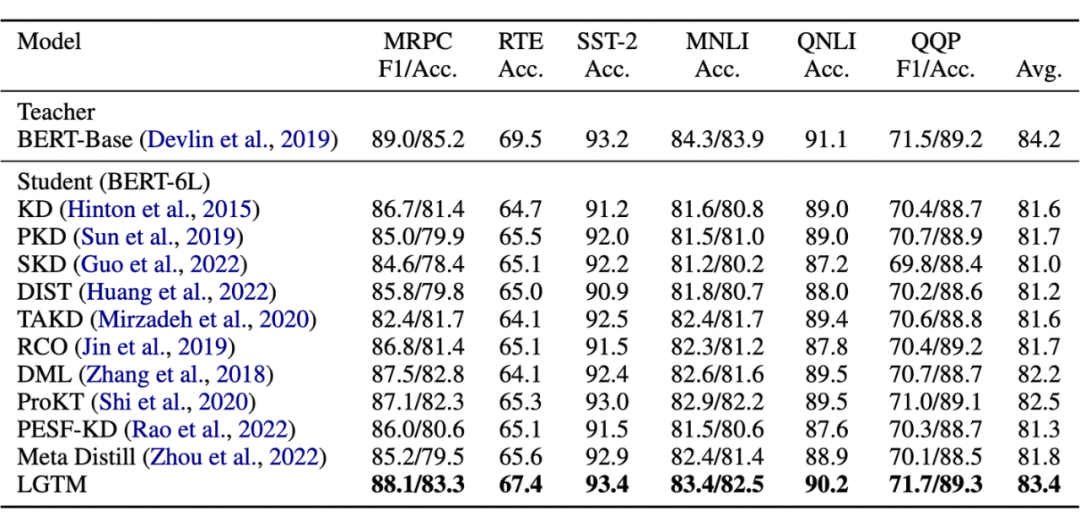
我们的 LGTM 模型,在 6 个文本分类数据集达到了 SOTA 效果,证明了我们方法的有效性:
为了进一步分析 distillation influence,我们选取了 MRPC 数据集中的两个典型样本,可视化了 distillation influence 在训练过程中的变化:
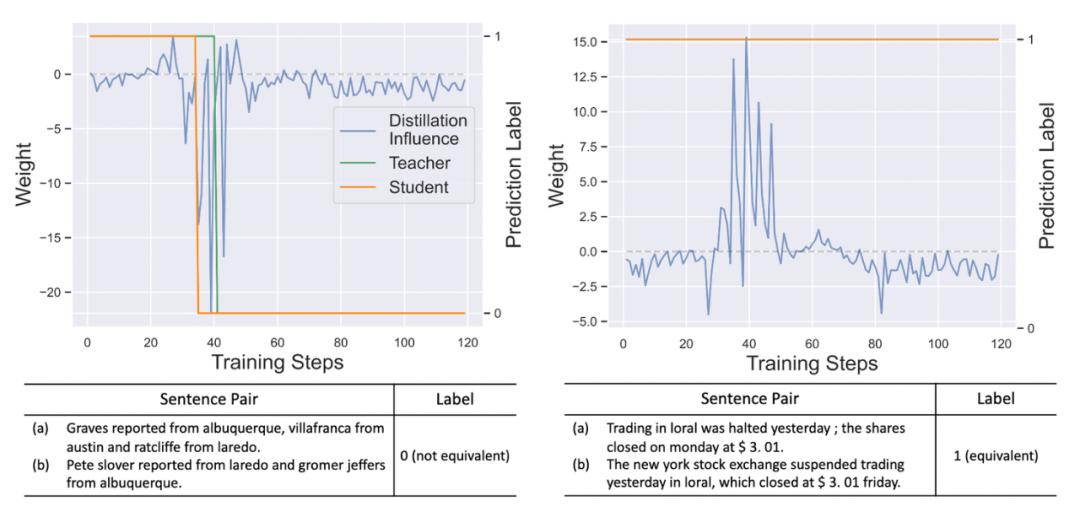
左图样本的 ground truth 标签是 0,然而教师和学生在一开始一直分类错误该样本,说明这个样本是难样本,如果过于关注对该样本的学习,可能会削弱学生的泛化能力。因此,该样本被赋予了负权重。右图样本的 ground truth 标签是 1,教师和学生都能分对该样本,说明该样本是较为简单的样本,有助于帮助学生建立决策边界,因此被赋予了正向权重。
我们也随机选取了 64 个样本,可视化了 distillation influence 的整体趋势图:
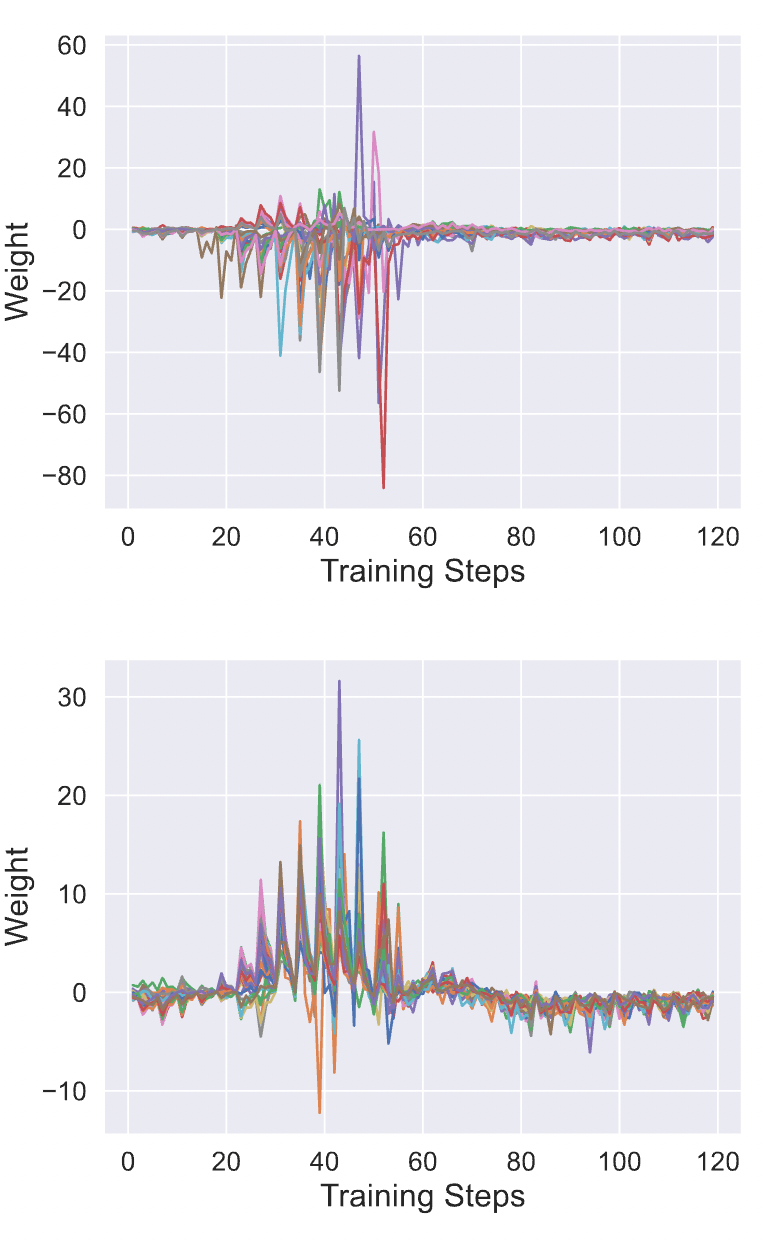
可以看出,无论样本被给予正权重还是负权重,distillaion influence 的变化趋势是相似的。在训练过程中,我们的方法能动态地赋予训练样本不同的权重。

总结与未来工作
我们的方法提出了 distillation influence,能够量化不同训练样本对学生泛化能力的影响,从而动态赋予这些样本不同的权重。通过实验,我们证明了这种根据学生的反馈动态调整训练样本权重的方式,能够有效地缓解过拟合现象,促进知识蒸馏的效果。
未来可以将我们的方法拓展到更复杂的任务,如文本生成任务。

参考文献
[1] https://proceedings.neurips.cc/paper/2020/hash/e6385d39ec9394f2f3a354d9d2b88eec-Abstract.html
[2] http://proceedings.mlr.press/v70/koh17a?ref=https://githubhelp.com
[3] https://www.cs.purdue.edu/homes/dgleich/publications/Gleich%202005%20-%20finite%20calculus.pdf
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
















 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









