









 本文提出了一种扩散后验采样方法,适用于处理一般有噪声的线性和非线性逆问题。通过VP-SDE,文章扩展了扩散求解器,无需严格的一致性投影步骤,能在高斯和泊松噪声环境中有效工作。该方法利用神经网络近似分数函数,解决了傅里叶相位恢复和非均匀去模糊等挑战。实验表明,这种方法在不同类型的图像修复和重建任务中表现出色。
本文提出了一种扩散后验采样方法,适用于处理一般有噪声的线性和非线性逆问题。通过VP-SDE,文章扩展了扩散求解器,无需严格的一致性投影步骤,能在高斯和泊松噪声环境中有效工作。该方法利用神经网络近似分数函数,解决了傅里叶相位恢复和非均匀去模糊等挑战。实验表明,这种方法在不同类型的图像修复和重建任务中表现出色。
DIFFUSION POSTERIOR SAMPLING FOR GENERALNOISY INVERSE PROBLEMS
Hyungjin Chung, Kim Jae Chul Graduate School of AI, ICLR 2023 spotlight, Cited:10, Code, Paper.
1. 前言
大多数工作都集中在在无噪声环境中解决简单的线性逆问题,这显著低估了真实世界问题的复杂性。在这项工作中,通过近似后验采样来扩展扩散求解器,有效的处理了一般的有噪声(非)线性逆问题。有趣的是,得到的后验采样方案是扩散采样与流形约束梯度的混合版本,而没有严格的测量一致性投影步骤,在有噪声环境中相比于之前的研究产生了更理想的生成路径。我们的方法展示了扩散模型可以结合各种测量噪声统计,如高斯和泊松,并且也能有效地处理有噪声非线性逆问题,如傅里叶相位恢复和非均匀去模糊。
2. 整体思想
本文的整体思想就是条件扩散模型,与Guided Diffusion是类似的思想,但是本文是从VP-SDE的角度来解决问题的。同样这是一篇非盲求解逆问题的工作。
3. 方法
VP-SDE形势如下,推导过程间Score-Based Generative Modeling Through Stochastic Differential Equations (Paper reading):
d
x
=
−
β
(
t
)
2
x
d
t
+
β
(
t
)
d
w
\begin{equation} d \boldsymbol{x}=-\frac{\beta(t)}{2} \boldsymbol{x} d t+\sqrt{\beta(t)} d \boldsymbol{w} \end{equation}
dx=−2β(t)xdt+β(t)dw
目标是从可追踪分布开始恢复数据生成分布,这可以通过下面相应的反向SDE来实现:
d
x
=
[
−
β
(
t
)
2
x
−
β
(
t
)
∇
x
t
log
p
t
(
x
t
)
]
d
t
+
β
(
t
)
d
w
‾
\begin{equation} d \boldsymbol{x}=\left[-\frac{\beta(t)}{2} \boldsymbol{x}-\beta(t) \nabla_{\boldsymbol{x}_{t}} \log p_{t}\left(\boldsymbol{x}_{t}\right)\right] d t+\sqrt{\beta(t)} d \overline{\boldsymbol{w}} \end{equation}
dx=[−2β(t)x−β(t)∇xtlogpt(xt)]dt+β(t)dw
漂移函数
f
(
x
t
,
t
)
f(x_{t},t)
f(xt,t)取决于时间相关的分数函数
∇
x
t
log
p
t
(
x
t
)
\nabla_{\boldsymbol{x}_{t}} \log p_{t}(\boldsymbol{x}_{t})
∇xtlogpt(xt),该函数由经过去噪分数匹配训练的神经网络
s
θ
s_{\theta}
sθ近似。对于逆问题,我们有一个由
x
x
x 导出的部分测量
y
y
y。当映射
x
→
y
x \to y
x→y多对一时,我们得到一个ill-posed问题,我们无法精确检索
x
x
x。在贝叶斯框架中,利用
p
(
x
)
p(x)
p(x)作为先验,来自后验
p
(
x
∣
y
)
p(x|y)
p(x∣y)的样本,其中关系用贝叶斯规则建立:
p
(
x
∣
y
)
=
p
(
y
∣
x
)
p
(
x
)
/
p
(
y
)
p(x|y) =p(y|x)p(x)/p(y)
p(x∣y)=p(y∣x)p(x)/p(y)。利用扩散模型作为先验,可以直接修改(2)获得反向扩散采样器,从后验分布中采样:
d
x
=
[
−
β
(
t
)
2
x
−
β
(
t
)
(
∇
x
t
log
p
t
(
x
t
)
+
∇
x
t
log
p
t
(
y
∣
x
t
)
)
]
d
t
+
β
(
t
)
d
w
‾
\begin{equation} d \boldsymbol{x}=\left[-\frac{\beta(t)}{2} \boldsymbol{x}-\beta(t)\left(\nabla_{\boldsymbol{x}_{t}} \log p_{t}\left(\boldsymbol{x}_{t}\right)+\nabla_{x_{t}} \log p_{t}\left(\boldsymbol{y} \mid \boldsymbol{x}_{t}\right)\right)\right] d t+\sqrt{\beta(t)} d \overline{\boldsymbol{w}} \end{equation}
dx=[−2β(t)x−β(t)(∇xtlogpt(xt)+∇xtlogpt(y∣xt))]dt+β(t)dw
其中
∇
x
t
log
p
t
(
x
t
∣
y
)
\nabla_{\boldsymbol{x}_{t}} \log p_{t}(\boldsymbol{x}_{t} \mid \boldsymbol{y})
∇xtlogpt(xt∣y)根据这篇文章Guided Diffusion/Diffusion Models Beat GANs on Image Synthesis (Paper reading)得到:
∇
x
t
log
p
t
(
x
t
∣
y
)
=
∇
x
t
log
p
t
(
x
t
)
+
∇
x
t
log
p
t
(
y
∣
x
t
)
\begin{equation} \nabla_{\boldsymbol{x}_{t}} \log p_{t}\left(\boldsymbol{x}_{t} \mid \boldsymbol{y}\right)=\nabla_{\boldsymbol{x}_{t}} \log p_{t}\left(\boldsymbol{x}_{t}\right)+\nabla_{\boldsymbol{x}_{t}} \log p_{t}\left(\boldsymbol{y} \mid \boldsymbol{x}_{t}\right) \end{equation}
∇xtlogpt(xt∣y)=∇xtlogpt(xt)+∇xtlogpt(y∣xt)
为了计算涉前一个项,我们可以简单地使用预训练的得分函数
s
θ
∗
s_{\theta^{*}}
sθ∗。然而,由于对时间
t
t
t的依赖,后一项很难以封闭形式获得,因为
y
y
y只有和
x
0
x_{0}
x0之间明确的依赖性。通常的噪声模型可以表示为:
y
=
A
(
x
0
)
+
n
,
y
,
n
∈
R
n
,
x
∈
R
d
\begin{equation} \boldsymbol{y}=\mathcal{A}\left(\boldsymbol{x}_{0}\right)+\boldsymbol{n}, \quad \boldsymbol{y}, \boldsymbol{n} \in \mathbb{R}^{n}, \boldsymbol{x} \in \mathbb{R}^{d} \end{equation}
y=A(x0)+n,y,n∈Rn,x∈Rd
其中,
A
(
⋅
)
:
R
d
→
R
n
\mathcal{A}(·):\mathbb{R}^{d}\to\mathbb{R}^{n}
A(⋅):Rd→Rn是前向算子,
n
∼
N
(
0
,
σ
2
I
)
n \sim N(0, \sigma^{2}I)
n∼N(0,σ2I)是高斯白噪声。
因为不存在
p
(
y
∣
x
t
)
p(y|x_{t})
p(y∣xt)的解析公式。为了利用测量模型
p
(
y
∣
x
0
)
p(y|x_{0})
p(y∣x0),我们将
p
(
y
∣
x
t
)
p(y|x_{t})
p(y∣xt)分解如下:
p
(
y
∣
x
t
)
=
∫
p
(
y
∣
x
0
,
x
t
)
p
(
x
0
∣
x
t
)
d
x
0
=
∫
p
(
y
∣
x
0
)
p
(
x
0
∣
x
t
)
d
x
0
\begin{align} p(y|x_{t}) &= \int p(y|x_{0},x_{t})p(x_{0}|x_{t})dx_{0} \\ &= \int p(y|x_{0})p(x_{0}|x_{t})dx_{0} \end{align}
p(y∣xt)=∫p(y∣x0,xt)p(x0∣xt)dx0=∫p(y∣x0)p(x0∣xt)dx0
因为,
y
y
y和
x
t
x_{t}
xt是独立的,且
y
y
y和
x
t
x_{t}
xt是条件独立与
x
0
x_{0}
x0的,因此,如下图,给定
x
t
x_{t}
xt求
y
y
y等价于给定
x
t
x_{t}
xt求
x
0
x_{0}
x0的概率乘上给定
x
0
x_{0}
x0求
y
y
y的概率。而
y
y
y和
x
t
x_{t}
xt之间有一个隐含的变量
x
0
x_{0}
x0,它可能取不同的值。为了把所有可能的
x
0
x_{0}
x0都考虑进去,我们就需要对
x
0
x_{0}
x0进行积分。

由(7)证明了 p ( y ∣ x t ) ≈ p ( y ∣ x ^ 0 ) p(y|x_{t}) \approx p(y| \hat x_{0}) p(y∣xt)≈p(y∣x^0),我是没太看懂!!

那么就可以用这个近似估计(4)中的梯度了,其中,推导过程见Score-Based Generative Modeling Through Stochastic Differential Equations (Paper reading):
x
^
0
:
=
E
[
x
0
∣
x
t
]
=
1
α
ˉ
(
t
)
(
x
t
+
(
1
−
α
ˉ
(
t
)
)
∇
x
t
log
p
t
(
x
t
)
)
≈
1
α
ˉ
(
t
)
(
x
t
+
(
1
−
α
ˉ
(
t
)
)
s
θ
∗
(
x
t
,
t
)
\begin{align} \hat{\boldsymbol{x}}_{0}:=\mathbb{E}\left[\boldsymbol{x}_{0} \mid \boldsymbol{x}_{t}\right]&=\frac{1}{\sqrt{\bar{\alpha}(t)}}\left(\boldsymbol{x}_{t}+(1-\bar{\alpha}(t)) \nabla_{\boldsymbol{x}_{t}} \log p_{t}\left(\boldsymbol{x}_{t}\right)\right) \\ &\approx \frac{1}{\sqrt{\bar{\alpha}(t)}}(\boldsymbol{x}_{t}+(1-\bar{\alpha}(t))s_{\theta^{*}}(\boldsymbol{x}_{t},t) \end{align}
x^0:=E[x0∣xt]=αˉ(t)1(xt+(1−αˉ(t))∇xtlogpt(xt))≈αˉ(t)1(xt+(1−αˉ(t))sθ∗(xt,t)
对于不同噪声的任务具有不同的测量模型
p
(
y
∣
x
0
)
p(y|x_{0})
p(y∣x0)。逆问题中最常见的两个情况是高斯噪声和泊松噪声。在这里,我们探讨了如何适应上述扩散后验采样,高斯噪声的似然函数为:
p
(
y
∣
x
0
)
=
1
(
2
π
)
n
σ
2
n
exp
[
−
∥
y
−
A
(
x
0
)
∥
2
2
2
σ
2
]
\begin{equation} p\left(\boldsymbol{y} \mid \boldsymbol{x}_{0}\right)=\frac{1}{\sqrt{(2 \pi)^{n} \sigma^{2 n}}} \exp \left[-\frac{\left\|\boldsymbol{y}-\mathcal{A}\left(\boldsymbol{x}_{0}\right)\right\|_{2}^{2}}{2 \sigma^{2}}\right] \end{equation}
p(y∣x0)=(2π)nσ2n1exp[−2σ2∥y−A(x0)∥22]
对其取log再求梯度得:
∇
x
t
log
p
(
y
∣
x
t
)
≃
−
1
σ
2
∇
x
t
∥
y
−
A
(
x
^
0
(
x
t
)
)
∥
2
2
\begin{equation} \nabla_{\boldsymbol{x}_{t}} \log p\left(\boldsymbol{y} \mid \boldsymbol{x}_{t}\right) \simeq-\frac{1}{\sigma^{2}} \nabla_{\boldsymbol{x}_{t}}\left\|\boldsymbol{y}-\mathcal{A}\left(\hat{\boldsymbol{x}}_{0}\left(\boldsymbol{x}_{t}\right)\right)\right\|_{2}^{2} \end{equation}
∇xtlogp(y∣xt)≃−σ21∇xt∥y−A(x^0(xt))∥22
算法流程如下,添加Possion噪声的过程基于同样的原理。说实话这种思想已经有很多了,比如Guided Diffusion/Diffusion Models Beat GANs on Image Synthesis (Paper reading)和ADIR: Adaptive Diffusion for Image Reconstruction (Paper reading)这两篇文章都是这种思想,值得注意的是本文是以VP-SDE的角度。所以和这两篇文章仅仅差了一个负号。

实验
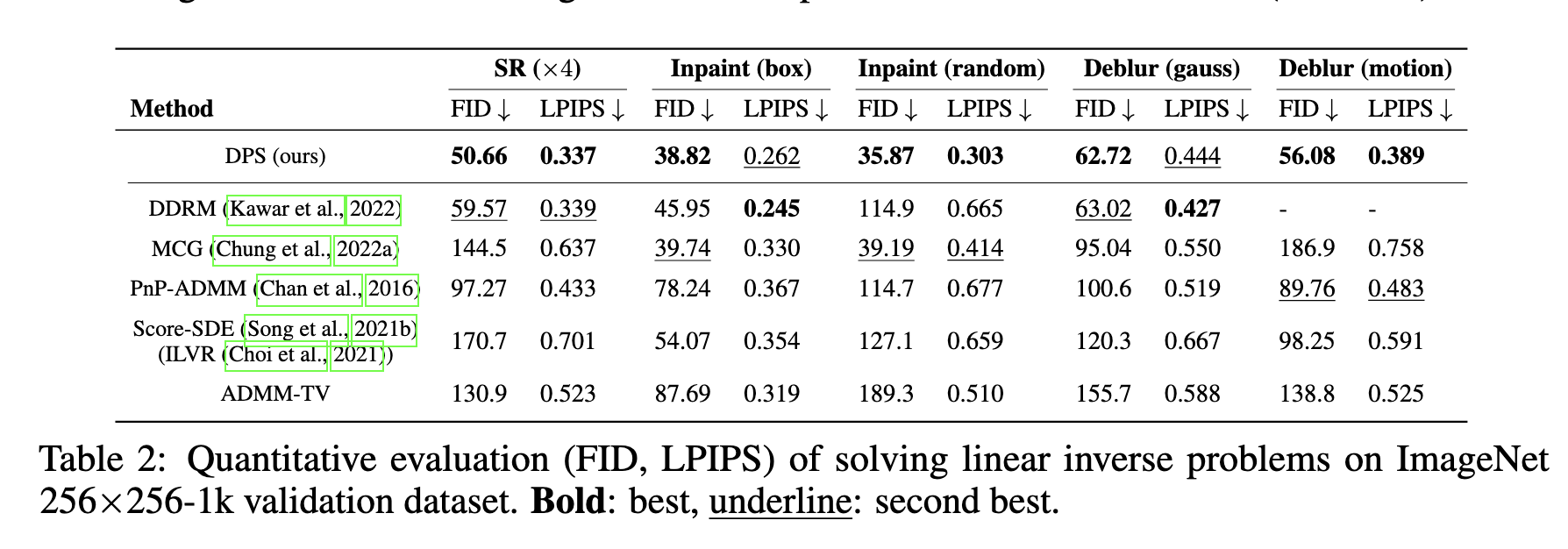
在两个具有不同特征FFHQ 256×256和Imagenet 256×256的数据集上测试了我们的实验,每个数据集有1k个验证图像。ImageNet 的预训练扩散模型取自Guided Diffusion,并直接用于针对特定任务进行微调。FFHQ 的扩散模型使用 49k 训练数据(排除 1k 验证集)从头开始训练 1M 步。所有图像都归一化为 [0, 1] 范围。前向测量算子指定如下:(i)对于框类型修复,我们在 屏蔽了 128×128 框区域。 对于随机类型,我们屏蔽了总像素的 92%(所有 RGB 通道)。(ii) 对于超分辨率,执行双三次下采样。(iii) 高斯模糊核的大小为 61×61,标准差为 3.0,运动模糊是使用代码 6 随机生成的,大小为 61 × 61,强度值为 0.5。内核与地面实况图像进行卷积以产生测量。(iv) 对于相位检索,对图像进行傅里叶变换,只取傅里叶幅值作为测量值。所有高斯噪声都被添加到σ = 0.05的测量域中。泊松噪声水平设置为λ = 1.0。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









