






最终我用出来的效果如下。
可惜数据量太大,不然搞个饼图挺好看的。
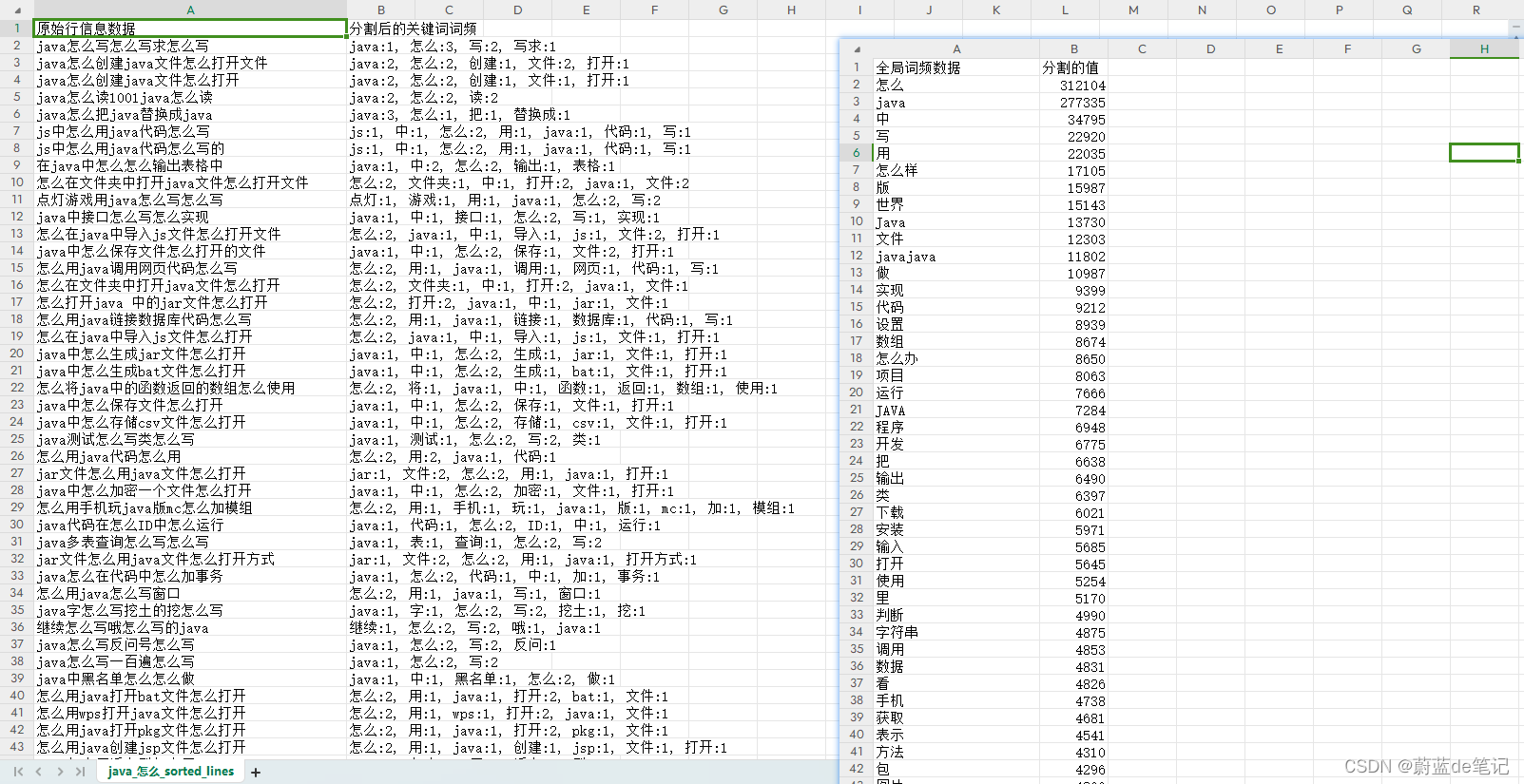
附件里面包含了五十万Java怎么相关的数据。
逻辑相关的部分代码。
from _init_ import *
from fileUtool import *
# 使用jieba分词
def jieba_cut(content):
words = jieba.cut(content)
return words
# 使用jieba分词并标注词性
def jieba_cut_with_pos(content):
words = pseg.cut(content)
return [(word, flag) for word, flag in words]
# 计算词频
def get_word_freq(words):
word_freq = Counter(words)
return word_freq
def add_word_set(setData):
for word in setData:
jieba.add_word(word, freq=jieba.suggest_freq(word, True))
if __name__ == '__main__':
# 过滤条件
not_flag = set(['w', 'y', 'm'])
not_word = set(['的', '了', '是', '我', '你', '他', '她', '它', '有', '在', '这', '那', '么', '好', '啊',' '])
# not_keyword = set(['祝福文案', '祝福语', '祝福短信', '祝福语大全', '祝福语网', '祝福语语录'])
not_keyword = set()
add_keyword = set()
add_word_set(add_keyword)
outFileName = "file/java_怎么"
# 读取文件内容
fileName = "file/java_怎么--长尾词_1703583673.csv"
word_list, content = read_file_csv_5118(fileName)
# 获取全局词频
global_words = jieba_cut_with_pos(content)
global_filtered_words = [word for word, flag in global_words if word not in not_word and flag not in not_flag]
global_word_freq = get_word_freq(global_filtered_words)
# 对每一行进行分词并获取词频
keyword_list = defaultdict(list)
for line in word_list:
words = jieba_cut_with_pos(line)
filtered_words = [word for word, flag in words if word not in not_word and flag not in not_flag ]
line_word_freq = get_word_freq(filtered_words)
keyword_list[line] = (filtered_words, line_word_freq)
# 对每一行根据包含的高频词进行排序
sorted_lines = sorted(word_list, key=lambda line: sum(global_word_freq[word] for word in keyword_list[line][0] if word in global_word_freq), reverse=True)
# 打开一个文件用于写入
with open(f'{outFileName}_sorted_lines.csv', 'w', newline='', encoding='utf-8-sig') as csvfile:
# 创建一个 csv 写入对象
csv_writer = csv.writer(csvfile)
# 写入标题行
csv_writer.writerow(['原始行信息数据', '分割后的关键词词频'])
# 遍历排序后的结果并写入到 CSV 文件
for line in sorted_lines:
filtered_words, line_word_freq = keyword_list[line]
# 过滤掉关键词数量小于等于6的词 基本上小于6的词是垃圾词
# 小于6的词看了也没太大作用
if len(line) <= 6:
continue
# 将词频字典转换为字符串形式
word_freq_str = ', '.join([f"{word}:{freq}" for word, freq in line_word_freq.items()])
# 写入一行数据
# csv_writer.writerow([line, ' '.join(filtered_words), word_freq_str])
csv_writer.writerow([line, word_freq_str])
# 打开一个文件用于写入
with open(f'{outFileName}_sorted_key.csv', 'w', newline='', encoding='utf-8-sig') as csvfile:
# 创建一个 csv 写入对象
csv_writer = csv.writer(csvfile)
csv_writer.writerow(['全局词频数据','分割的值'])
# 写入全局词频数据
for word, freq in global_word_freq.most_common():
# 词性小于等于2的词也是垃圾词
if freq <= 2:
continue
csv_writer.writerow([word, freq])
















 2339
2339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











