







一、MapReduce收尾
1、如果启动集群发现某个节点的服务没有启动,如何解决?
如果启动集群,发现某个节点比如bigdata02中的datanode没有启动,怎么办?
方案:查看日志,看错误是什么?

2、修改完成后,可以单独启动某个服务:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start secondarynamenode
hadoop-daemon.sh start datanode
yarn --daemon start resourcemanger
yarn --daemon start nodemanger3、main方法后面的 args数组有何作用?

package com.bigdata.day12.workcount;
import java.util.Arrays;
/**
* @Author laoyan
* @Description TODO
* @Date 2022/8/3 9:47
* @Version 1.0
*/
public class Demo01 {
public static void main(String[] args) {
System.out.println(Arrays.toString(args));
System.out.println(args[0]);
System.out.println(args[1]);
}
} 
服务器上怎么办?没有idea
需要使用jar命令:
hadoop jar wc.jar com.bigdata.day12.workcount.Demo01 /input /output
通过以上方式给args传递数据。4、常见端口,分别是什么?
306 mysql连接的端口
22 windows连接linux,进行sftp访问的端口
9870 hdfs页面访问的端口号 http://192.168.32.128:9870
9820 hdfs的通讯端口 hdfs://192.168.32.128:9820
两个地方见过:java操作hdfs的时候,昨天mapreduce访问hdfs的时候
8088 yarn平台通过web访问的端口号 http://192.168.32.128:8088二、Yarn介绍
1、理论
Apache YARN(Yet another Resource Negotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序。
YARN被引入Hadoop2,最初是为了改善MapReduce的实现,但是因为具有足够的通用性,同样可以支持其他的分布式计算模式,比如Spark,Tez等计算框架。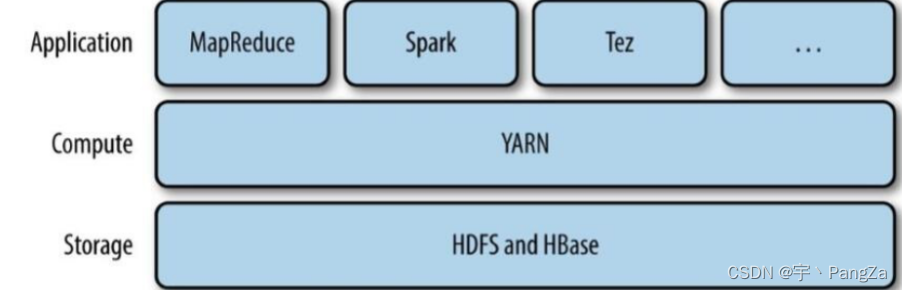
大数据技术大致分为四代:
1、MapReduce (淘汰)
2、MapReduce的升级版(Tez) (淘汰)
3、Spark(一系列的技术) 目前正在流行 运行比较快
4、Flink 正在悄悄的流行起来,代表未来(流行起来了,阿里巴巴购买的)2、组成部分

ResourceManager:
是在系统中的所有应用程序之间管理资源的最终权威,即管理整个集群上的所有资源分配,内部含有一个Scheduler(资源调度器)
NodeManager:
是每台机器的资源管理器,也就是单个节点的管理者,负责启动和监视容器(container)资源使用情况,并向ResourceManager及其 Scheduler报告使用情况.
container:
即集群上的可使用资源,包含cpu、内存、磁盘、网络等(虚拟机,或者Docker)
AppMaster(项目经理):
实际上是框架的特定的库,每启动一个应用程序,都会启动一个AM,它的任务是与ResourceManager协商资源,并与NodeManager一起执行和监视任务。3、Yarn的工作流程(重点)--重要程度和mr是一样的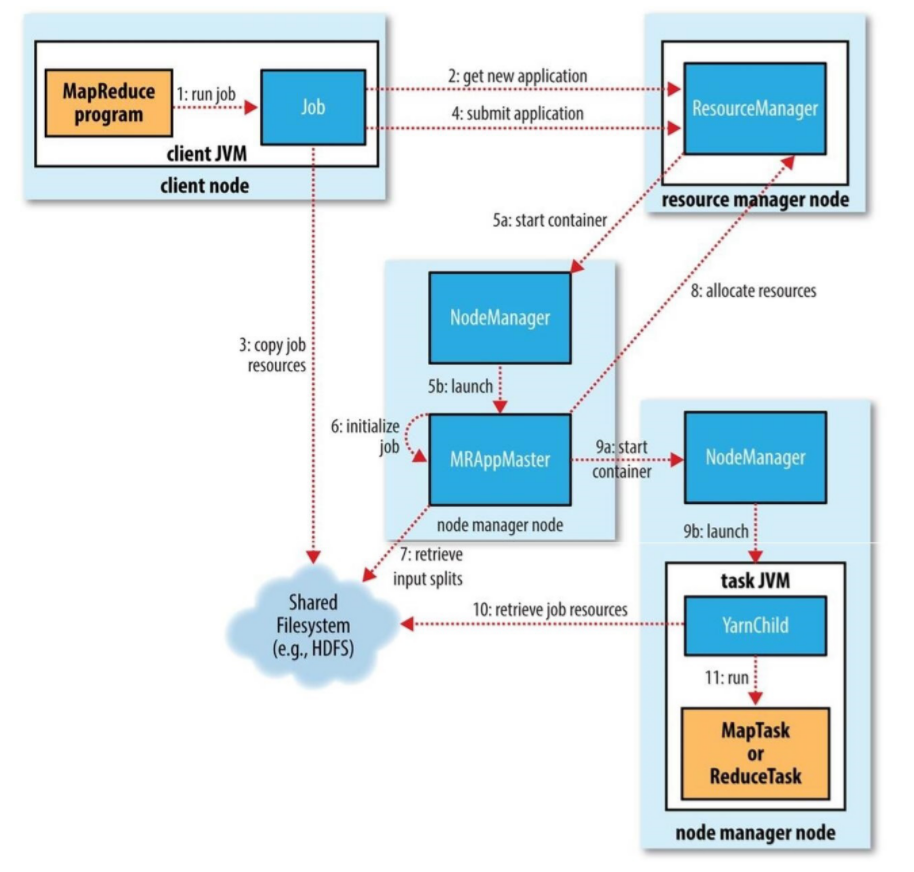
1. 调用waitForCompletion方法每秒轮询作业的进度,内部封装了submit()方法,用于创建JobCommiter实例,并且调用其的submitJobInternal方法。提交成功后,如果有状态改变,就会把进度报告到控制台。错误也会报告到控制台。
2. JobCommiter实例会向ResourceManager申请一个新应用ID,用于MapReduce作业ID。这期间JobCommiter也会进行检查输出路径的情况,以及计算输入分片。
3. 如果成功申请到ID,就会将运行作业所需要的资源(包括作业jar文件,配置文件和计算所得的输入分片元数据文件)上传到一个用ID命名的目录下的HDFS上。此时副本个数默认是10.
4. 准备工作已经做好,再通知ResourceManager调用submitApplication方法提交作业。
5. ResourceManager调用submitApplication方法后,会通知Yarn调度器(Scheduler),调度器分配一个容器,在节点管理器的管理下在容器中启动 application master进程。
6. application master的主类是MRAppMaster,其主要作用是初始化任务,并接受来自任务的进度和完成报告。
7. 然后从HDFS上接受资源,主要是split。然后为每一个split创建MapTask以及参数指定的ReduceTask,任务ID在此时分配
8. 然后Application Master会向资源管理器请求容器,首先为MapTask申请容器,然后再为ReduceTask申请容器。
9. 一旦ResourceManager中的调度器(Scheduler),为Task分配了一个特定节点上的容器,Application Master就会与NodeManager进行通信来启动容器。
10. 运行任务是由YarnChild来执行的,运行任务前,先将资源本地化(jar文件,配置文件,缓存文件)
11. 然后开始运行MapTask或ReduceTask。
12. 当收到最后一个任务已经完成的通知后,application master会把作业状态设置为success。然后Job轮询时,知道成功完成,就会通知客户端,并把统计信息输出到控制台三、Yarn的历史日志配置【可选项】
1、jobHistory
为什么要配置日志呢?原因是因为我们的任务不一定每次都是成功的,如果失败了,需要查阅日志,发现日志有没有配置。
我们在YARN运行MapReduce的程序的时候,任务会被分发到不同的节点,在不同的Container内去执行。如果一个程序执行结束后,我们想去查看这个程序的运行状态呢?每一个MapTask的执行细节?每一个ReduceTask的执行细节?这个时候我们是查看不到的,因此我们需要开启记录历史日志的服务。我的日志是分散在多台电脑上的,如果任务失败了,每个节点只记录自己的那一部分,我们需要去各个节点上查阅日志,效率太低了,将这些日志聚合在一起就好了。所以我们还需要配置日志聚合服务。
历史日志服务开启之后,Container在运行任务的过程中,会将日志记录下来,保存到当前的节点。例如: 在bigdata02节点上开启了一个Container去执行MapTask,那么此时就会在bigdata02的$HADOOP_HOME/logs/userlogs中记录下来日志。我们可以到不同的节点上去查看日志。虽然这样可以查看,但是很不方便!因此,我们一般还会开启另外的一个服务: 日志聚合。顾名思义,就是将不同节点的日志聚合到一起保存起来。mapred-site.xml
<!-- 添加如下配置 -->
<!-- 历史任务的内部通讯地址 -->
<property>
<name>MapReduce.jobhistory.address</name>
<value>bigdata01:10020</value>
</property>
<!--历史任务的外部监听页面-->
<property>
<name>MapReduce.jobhistory.webapp.address</name>
<value>bigdata01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/installs/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/installs/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/installs/hadoop</value>
</property>yarn-site.xml
<!-- 添加如下配置 -->
<!-- 是否需要开启日志聚合 -->
<!-- 开启日志聚合后,将会将各个Container的日志保存在yarn.nodemanager.remote-app-log-dir的位置 -->
<!-- 默认保存在/tmp/logs -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 历史日志在HDFS保存的时间,单位是秒 -->
<!-- 默认的是-1,表示永久保存 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:19888/jobhistory/logs</value>
</property>将mapred-site.xml 和yarn-site.xml 分发到其他两台上。
cd /usr/local/hadoop/etc/hadoop/
xsync.sh mapred-site.xml yarn-site.xml重启yarn服务:
stop-dfs.sh
start-dfs.sh
还要记得启动history服务:
mapred --daemon start historyserver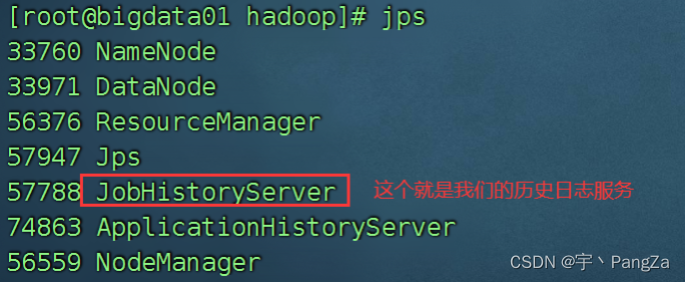
运行一个yarn的任务,随便一个即可:
hadoop jar /opt/installs/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /home/wc.txt /home/output4
访问yarn平台
会看到一个运行的任务,点击这个任务就可以查看日志了:
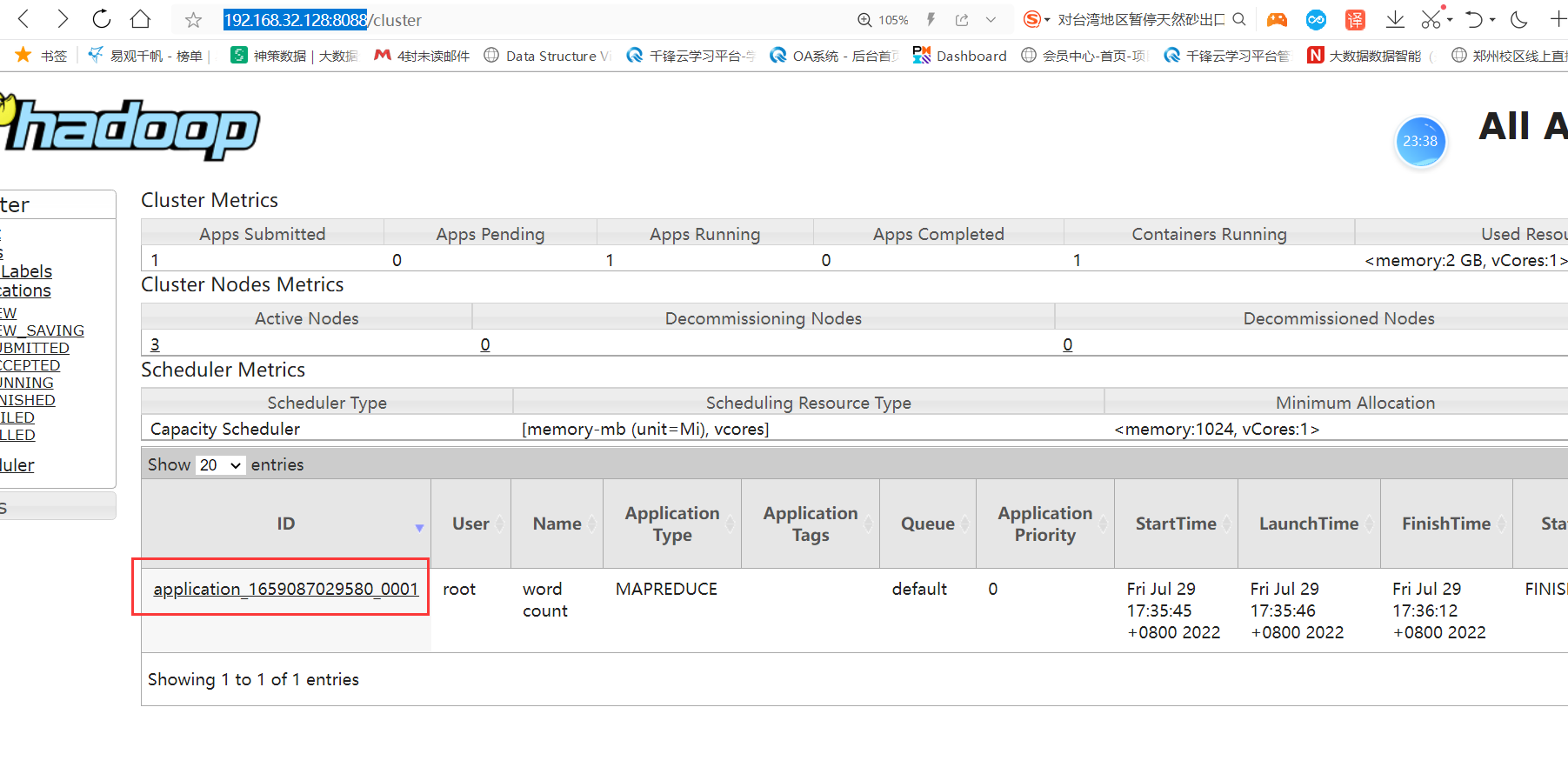

点完之后,发现不管用,你可以查看一下你的URL是什么?
![]()
因为windows电脑上,压根不知道bigdata01 对应的IP是多少。所以访问不了。
在Linux上我们知道bigdata01对应的IP是多少,因为我们配置了hosts文件
此时需要修改windows上的 hosts文件。为了更加方便的修改windows上的hosts,可以使用一个工具:
SwitchHosts。
先关闭电脑上的各种杀毒软件,因为有一种病毒是专门修改hosts文件的。
右键,以管理员身份运行这个软件。否则修改不了。


修改完之后,就可以点击logs 链接了。
也可以直接修改host文件,地址在:
C:\Windows\System32\drivers\etc
2、timeline(时间轴服务)--了解
配置日志信息。
JobHistory服务,只针对于MR应用程序,Spark,Tez等这样的服务,是无法看到日志的。
这个工具或者服务,不仅可以查看MapReduce,还可以查看Spark应用程序的日志。
目前位置,Timeline Server有V1、V1.5、V2三种版本,其中V2的版本正在测试中,功能尚不完善,且后端依赖HBase。所以目前我们以V1.5的版本为例。yarn-site.xml
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.generic-application-history.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>bigdata01</value>
</property>
<property>
<name>yarn.timeline-service.bind-host</name>
<value>bigdata01</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.ttl-enable</name>
<value>true</value>
</property>
<!-- 保存35天 -->
<property>
<name>yarn.timeline-service.ttl-ms</name>
<value>3024000000</value>
</property>
<!-- 设置log server地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:8188/applicationhistory/logs</value>
</property>将yarn-site.xml 分发到其他两台电脑上。
重启yarn服务:
stop-yarn.sh
start-yarn.sh
// 记得启动我们的时间轴服务:
yarn --daemon start timelineserver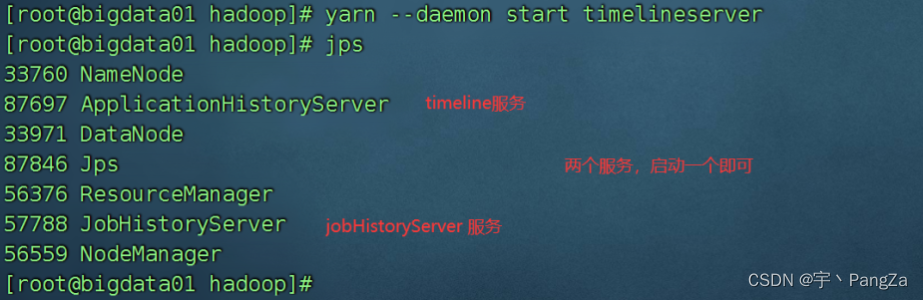
访问地址:http://192.168.32.128:8188

如何查看日志呢?
记得演示一个mapreduce任务


四、Yarn的三种调度器(面试题)
在我们的ResourceManager中,存在调度器。
所谓的调度器,其实就是协调各个任务之间的资源的。
job 1 job2 job3 每个任务都是有大有小,有些大任务可能需要运行几天,有些小任务,可能运行1分钟就结束。此时多个任务同时执行,资源如何协调,这就是调度器的作用。
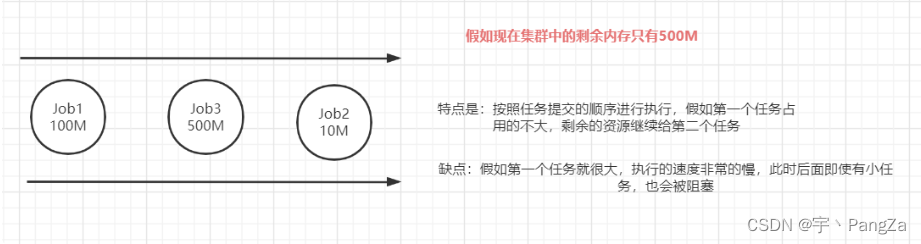
1、FIFO Scheduler(FIFO调度器)
FIFO = first input first output (先进先出)
FIFO 为 First Input First Output 的缩写,先进先出。FIFO 调度器将应用放在一个队列中,按照先 后顺序
 2、Capacity Scheduler(容量调度器,apache版本默认使用的调度器)
2、Capacity Scheduler(容量调度器,apache版本默认使用的调度器)


这个调度器是hadoop Apache版本默认的调度器:
优点是:不会因为某个任务特别的大,就导致后面的其他提交的任务执行不了。
缺点是:如果真遇到了大任务,执行的时间会稍微长一些。因为要时刻给小的任务预留资源。
专门留了一部分资源给小任务,可以在执行job1的同时,不会阻塞job2的执行,但是因为这部分资源是一直保留给其他任务的,所以就算只有一个任务,也无法为其分配全部资源,只能让这部分保留资源闲置着,有着一定的资源浪费问题。3、Fair Scheduler(公平调度器,CDH版本的hadoop默认使用的调度器)
hadoop版本有三种:第一种是Apache版本,CDH版本、HotonWorks版本。
公平调度器的目的就是为所有运行的应用公平分配资源。使用公平调度器时,不需要预留一定量的资源,因为调度器会在所有运行的作业之间动态平衡资源,第一个(大)作业启动时,它也是唯一运行的作业,因而获得集群中的所有资源,当第二个(小)作业启动时,它被分配到集群的一半资源,这样每个作业都能公平共享资源。
Yarn都学习了什么?
1)Yarn如何配置
2)编写的任务在yarn上如何运行
3)Yarn的工作原理
4)Yarn的历史日志配置
5)Yarn的三种调度器五、Zookeeper (简称 ZK)
1、简介

动物园管理员。
1. zookeeper是一个为分布式应用程序提供的一个分布式开源协调服务框架。是Google的Chubby的一个开源实现,是Hadoop和Hbase的重要组件。主要用于解决分布式集群中应用系统的一致性问题。
2. 提供了基于类似Unix系统的目录节点树方式的数据存储。
3. 可用于维护和监控存储的数据的状态的变化,通过监控这些数据状态的变化,从而达到基于数据的集群管理
4. 提供了一组原语(机器指令),提供了java和c语言的接口通俗的理解:
1、zk其实是一个小型的文件存储系统,可以存放少量的数据,这些数据不是什么正儿八经的数据,都是一些关于服务器的小数据。
2、它可以感知服务器是否上线,是否掉线。
3、我们为什么要学习这个东西?我们可以使用zk搭建集群环境。
比如:hadoop的高可用(HA),namenode 存在单节点故障。我们可以启用两个namenode,一个挂掉了,另一个自动启动。另一个namenode如何知道第一个namenode挂掉了?zk就可以做到。
包括:HBase也会使用到。
Java架构中: zk进行分布式锁等操作。各个版本下载界面:Apache ZooKeeper
2、特点
1. 也是一个分布式集群,一个领导者(leader),多个跟随者(follower).
2. 集群中只要有半数以上的节点存活,Zookeeper集群就能正常服务。
3. 全局数据一致性:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的。
4. 更新请求按顺序进行:来自同一个client的更新请求按其发送顺序依次执行
5. 数据更新的原子性:一次数据的更新要么成功,要么失败
6. 数据的实时性:在一定时间范围内,client能读到最新数据。
3、数据存储:
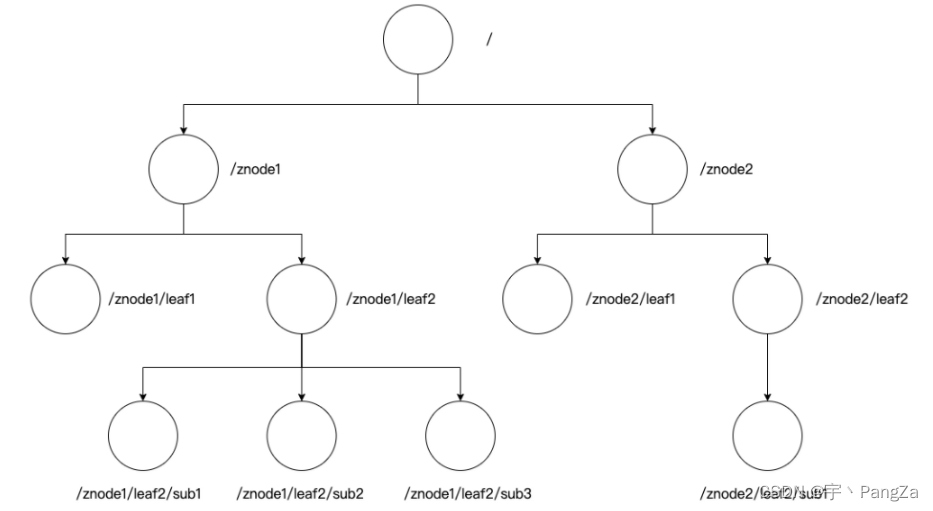
结构是从根节点开始的/
每一个子节点都可以有其他子节点,也可以在该节点上存放数据,这个来讲有点像Unix.4、安装zookeeper
1)上传 /opt/modules下面

2)解压 /opt/installs下面
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/installs/3) 重命名
mv zookeeper-3.4.10/ zookeeper4)修改配置文件

进入到/opt/installs/zookeeper/conf文件夹下,重命名zoo_sample.cfg
mv zoo_sample.cfg zoo.cfg使用nodepad++修改这个配置文件
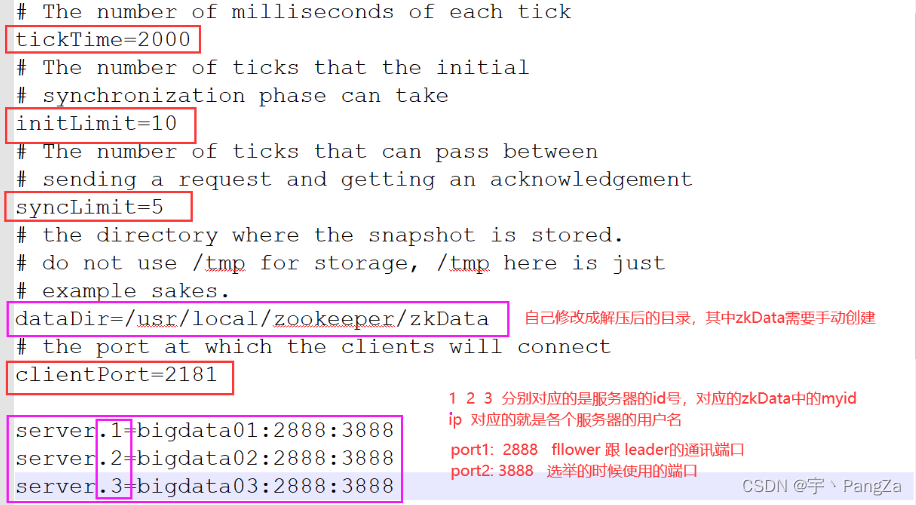
我的配置文件全部:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/installs/zookeeper/zkData
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=bigdata01:2888:3888
server.2=bigdata02:2888:3888
server.3=bigdata03:2888:3888记得在zookeeper中创建zkData文件夹,以及myid文件

配置环境变量:
/etc/profile
export ZOOKEEPER_HOME=/opt/installs/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin刷新一下环境变量:
source /etc/profile接着配置第二台和第三台:
xsync.sh /opt/installs/zookeeper
xsync.sh /etc/profile
xcall.sh source /etc/profile在bigdata02中,修改myid 为2
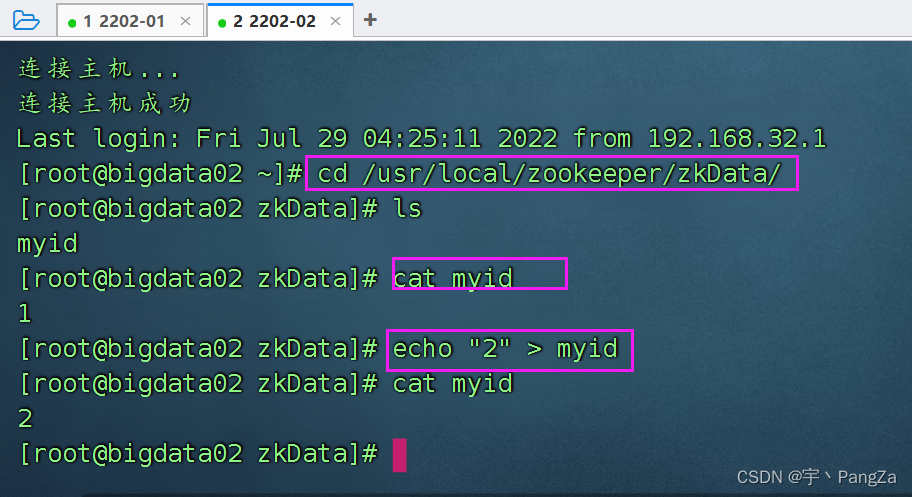
bigdata03中,修改myid为3

在每一台电脑上,都启动zkServer
zkServer.sh start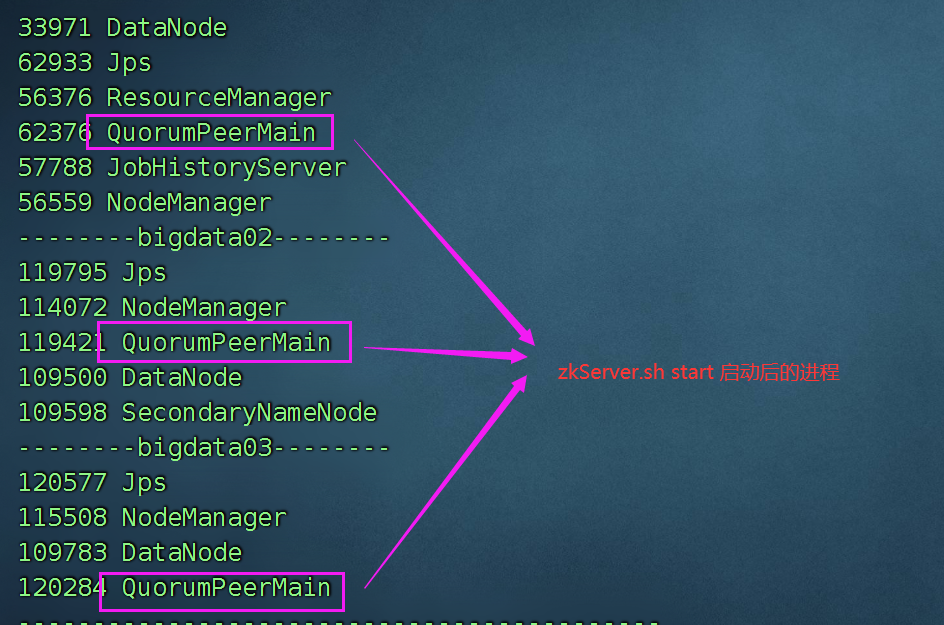
查看状态:
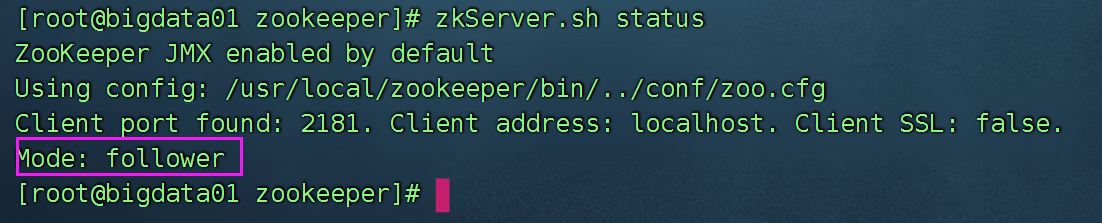


因为zookeeper安装的节点比较多,每一个一个个操作非常的繁琐,所以我们可以编写一个脚本,管理zookeeper集群。
在/usr/local/bin 下面,创建zk.sh
#!/bin/bash
# 获取参数
COMMAND=$1
if [ ! $COMMAND ]; then
echo "please input your option in [start | stop | status]"
exit -1
fi
if [ $COMMAND != "start" -a $COMMAND != "stop" -a $COMMAND != "status" ]; then
echo "please input your option in [start | stop | status]"
exit -1
fi
# 所有的服务器
HOSTS=( bigdata01 bigdata02 bigdata03 )
for HOST in ${HOSTS[*]}
do
ssh -T $HOST << TERMINATOR
echo "---------- $HOST ----------"
zkServer.sh $COMMAND 2> /dev/null | grep -ivh SSL
exit
TERMINATOR
donechmod u+x zk.sh使用:
zk.sh start
zk.sh stop
zk.sh status5、zookeeper的shell操作(新版本)-3.5以上
1)连接zkServer
zkCli.sh 直接回车,连接的是本机的节点create /bigdata
set /bigdata "我是数据" --修改数据
get /bigdatazkCli.sh -server bigdata02:2181
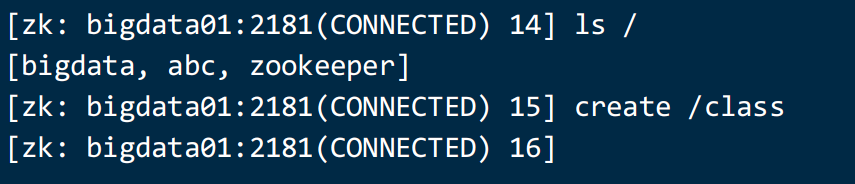
2) ls 查看某个路径下的子节点
ls /
ls /zookeeper
ls -s /zookeeper 可以查看某个节点的详细的信息 【版本不同命令不同】3)get 查看某个节点上的数据
get /bigdata01
get -s /bigdata01 【版本不同命令不同】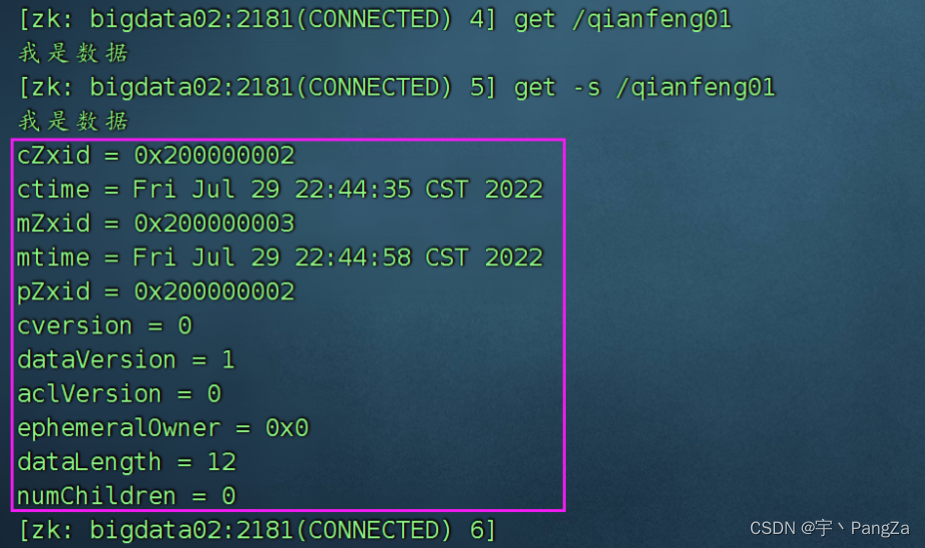
4) create 创建节点
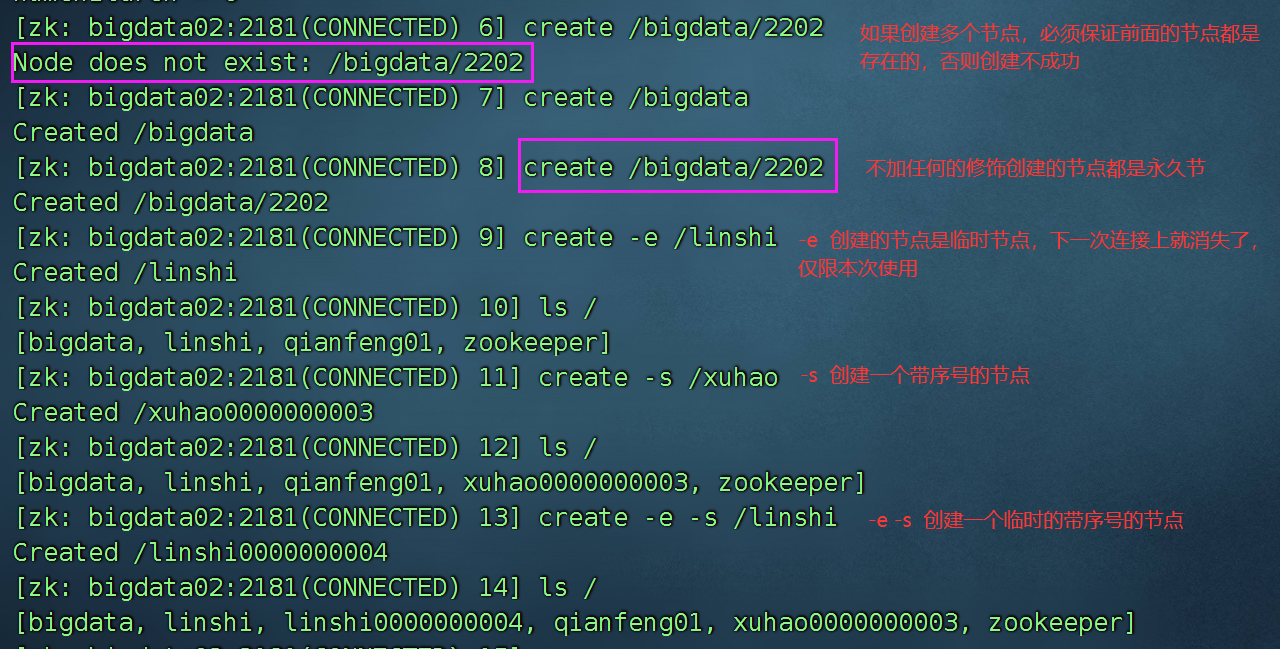

临时节点,只要客户端和服务器端断开连接,临时节点就会被删除
永久节点:断开连接,不会删除。 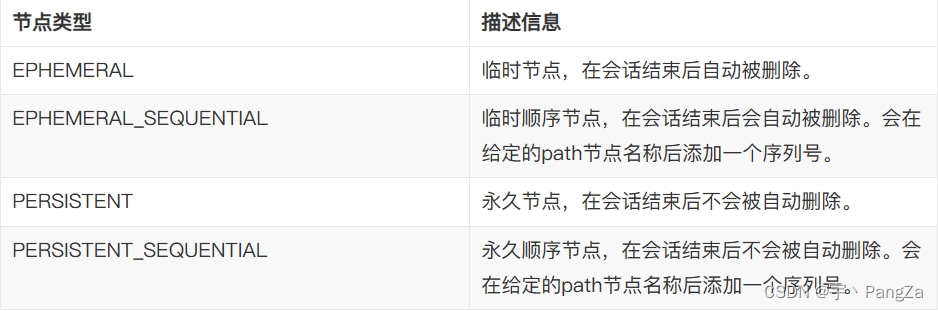
5)set 在节点上设置数据
set /bigdata01 "HelloWorld"6) delete 删除节点
它只能删除没有子节点的数据
deleteall 可以删除整个节点,包含下面的子节点

7) watch 监听

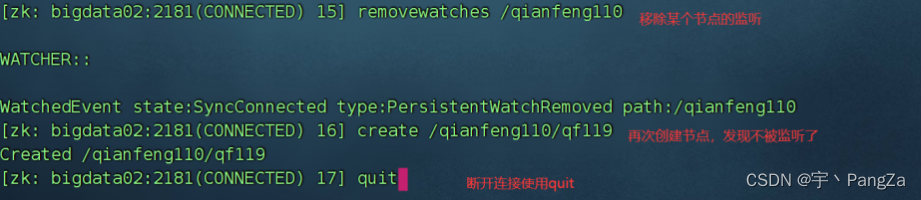
6、老版本的shell的用法
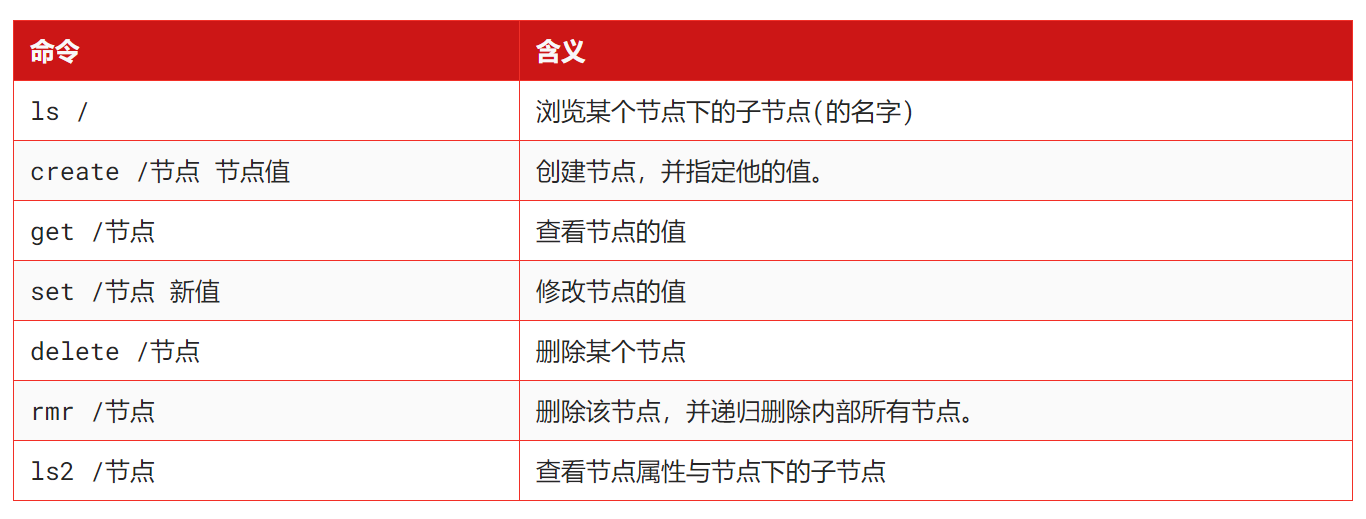
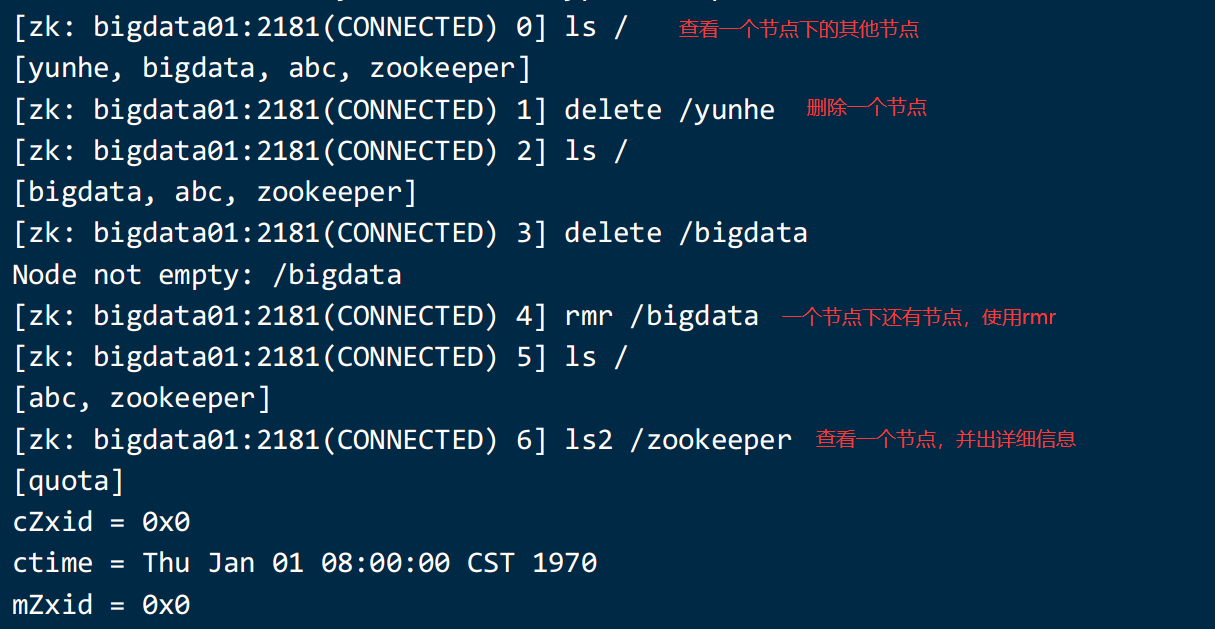

演示一下:



zookeeper 可以进行数据的监听:

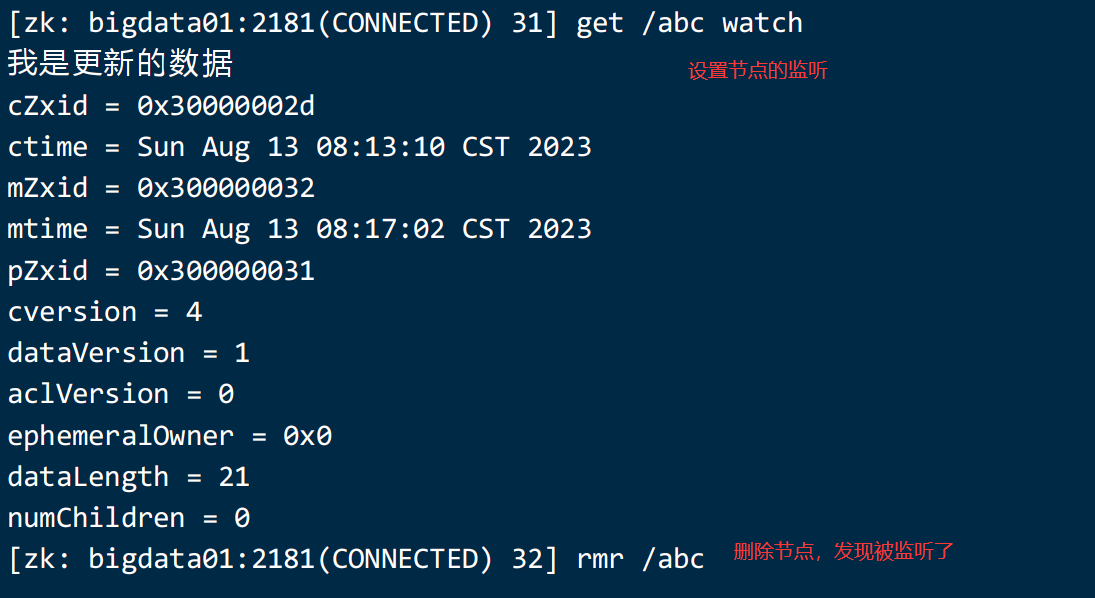
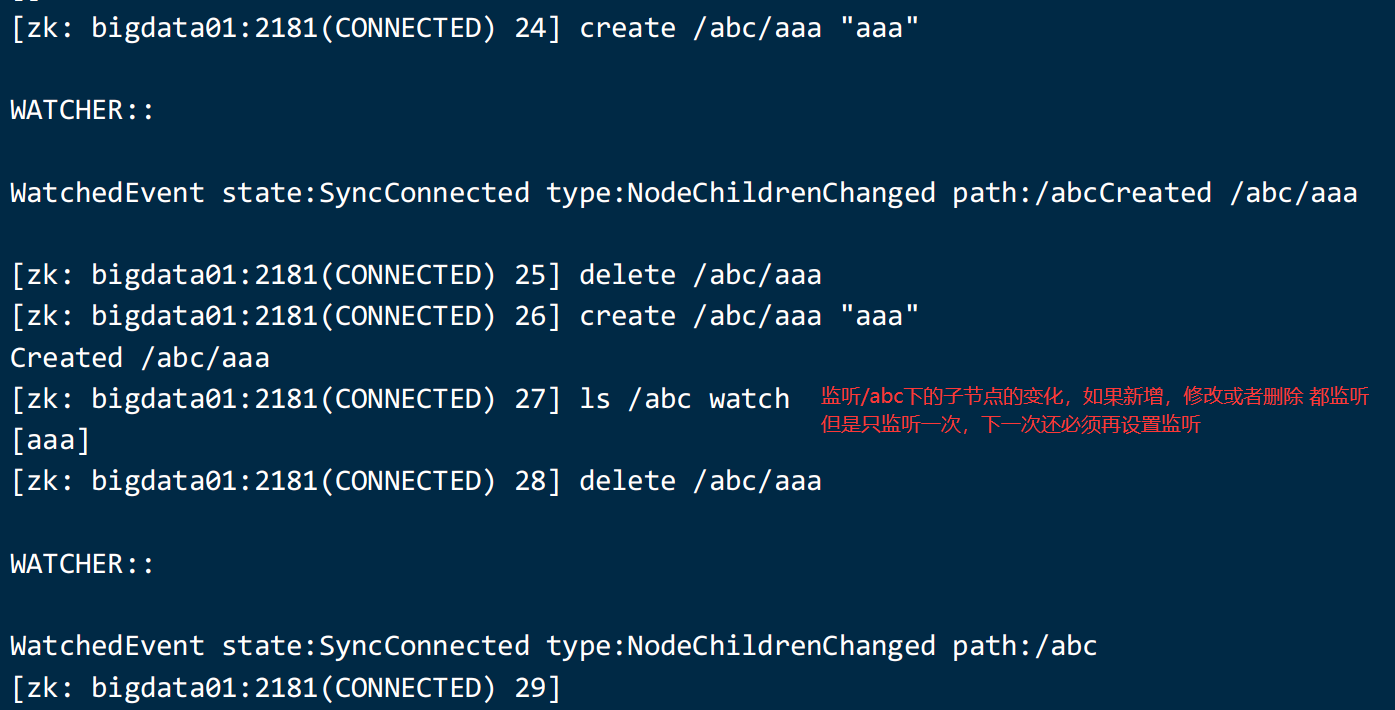
7、安装一个客户端
推荐两个客户端的工具,prettyZoo(漂亮的zoo) ,另一个是花瓣
1)使用漂亮的zoo


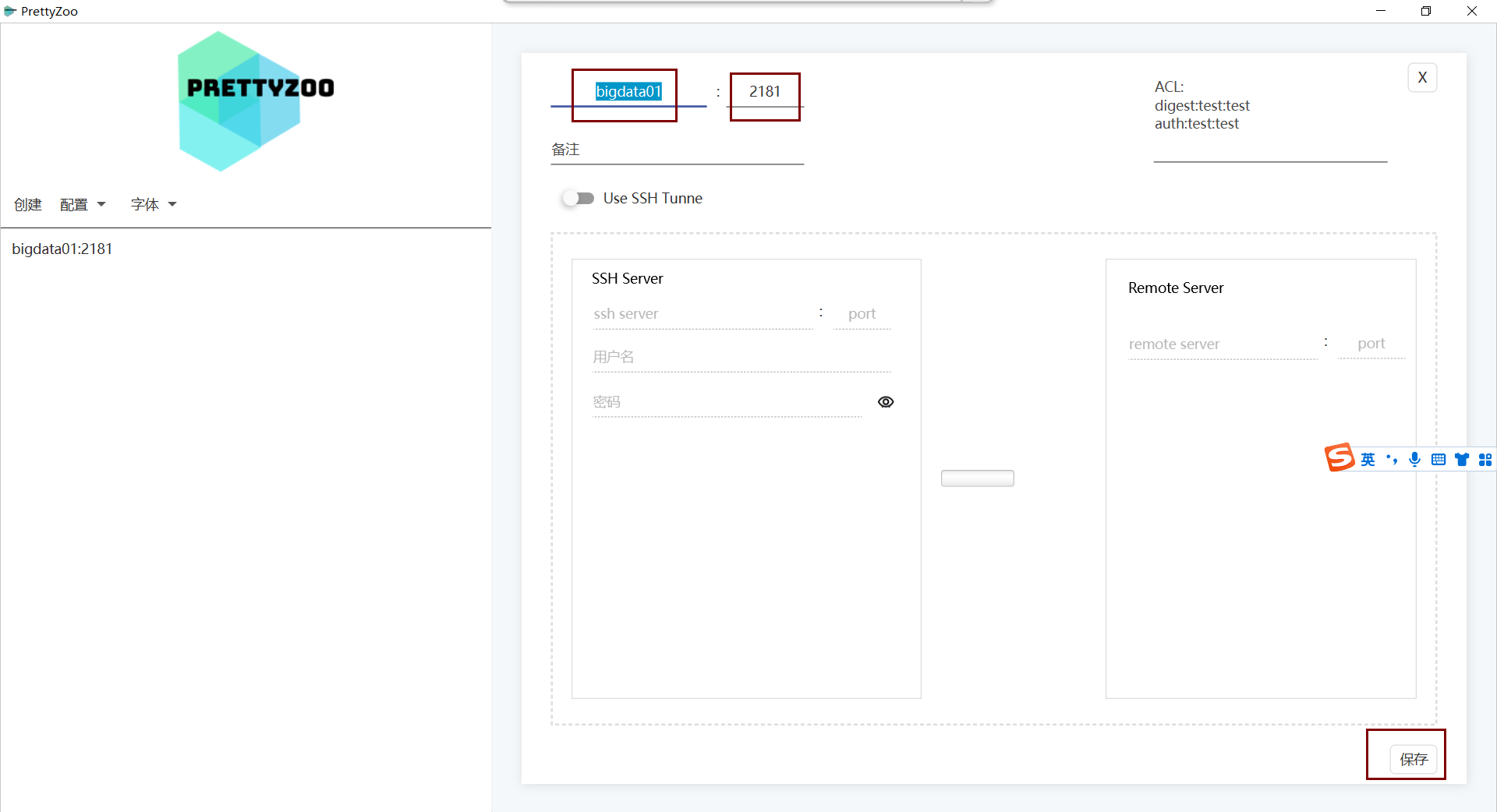

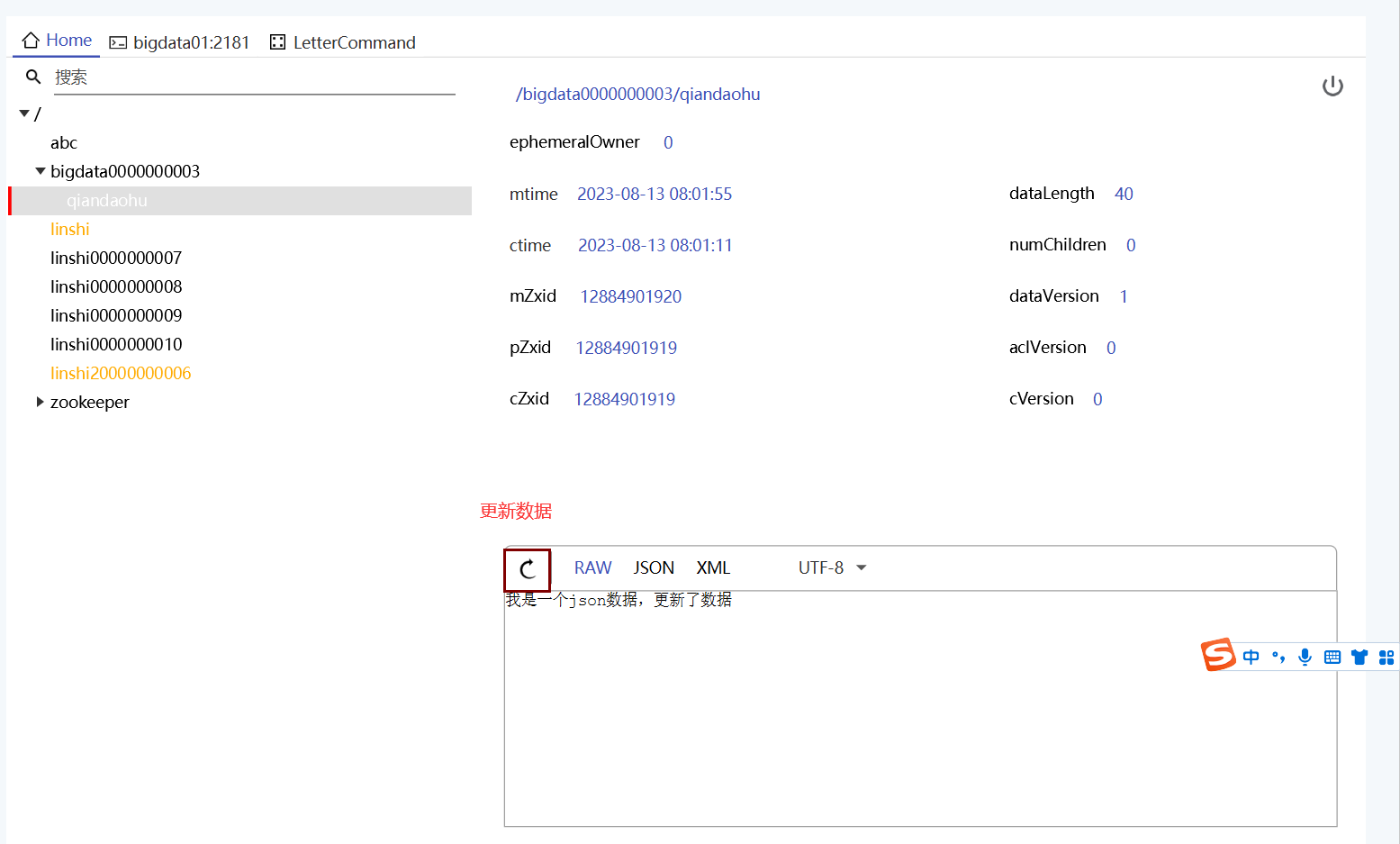
删除数据:

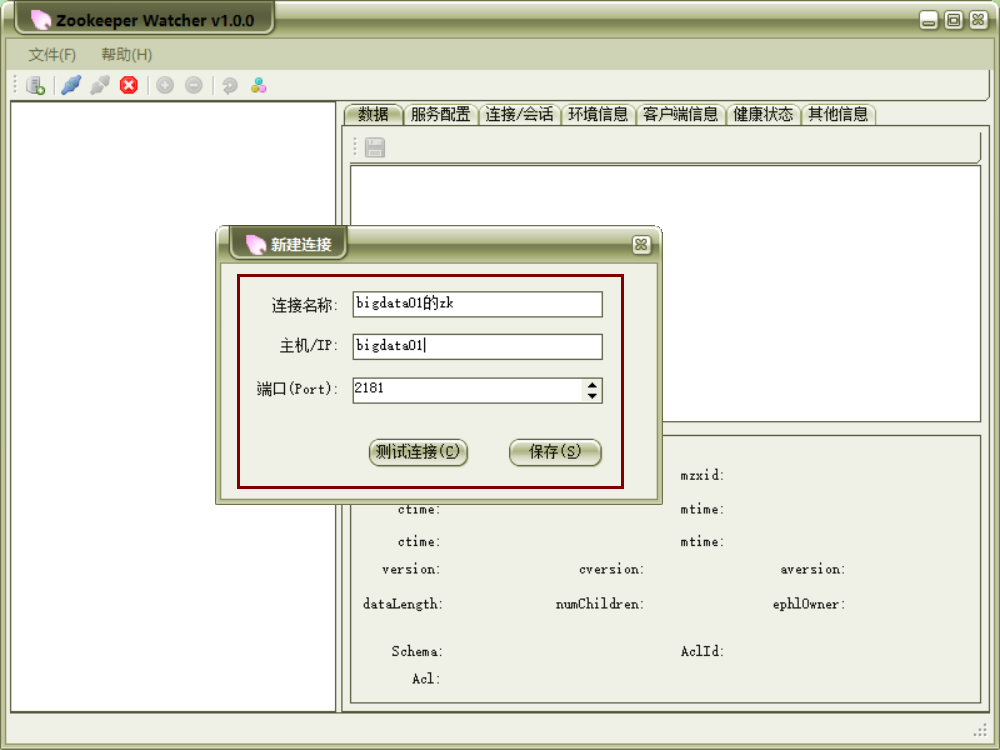
2)花瓣客户端
















 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











