






最近在用python分布式跑代码,出现了如下的问题,有相同问题的小伙伴可以参考一下:
成功解决error:unrecognized argument: --local-rank=0
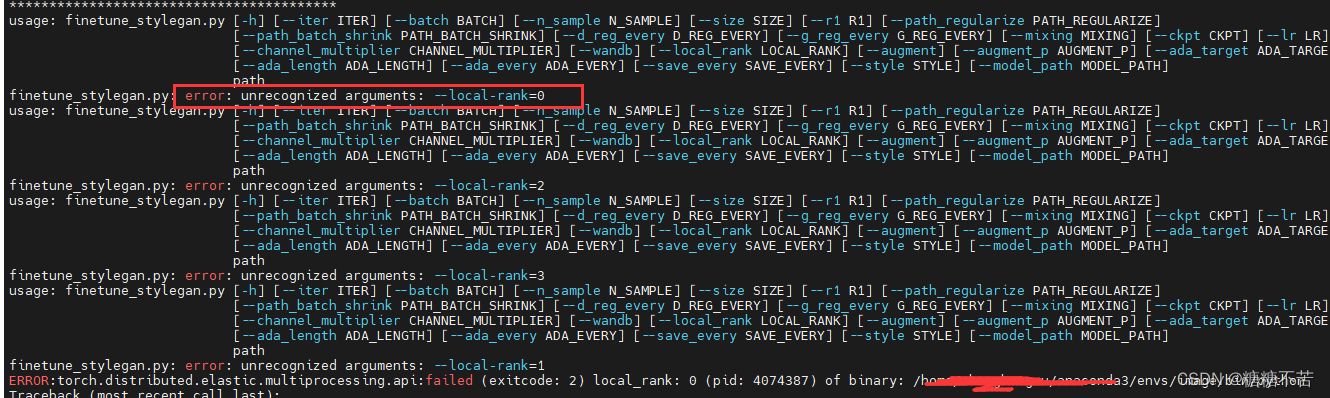
出现上述原因执行命令之前加上 --use-env即可,如
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --master_port=8675 --use_env finetune_stylegan.py --iter 600 --batch 4 --ckpt ./checkpoint/stylegan2-ffhq-config-f.pt --style cartoon --augment ./data/cartoon/lmdb/
然后就能正常运行了,之前看了网上好多的解决方法,在我这里都不管用,自己琢磨了好几天终于能够正常运行了。
仅用于日常排错,希望有同样问题的小伙伴能够参考一下。
有小伙伴反应,用了上面的方法也没办法解决问题,所以这里做了一下修改,因为部分小伙伴出现了不一样的问题,我也研究了一下,其实我恰巧也遇见了,在这里补充一下。
有些小伙伴加上了–usen-env 还是会报同样的错误,这里是因为你的训练文件中没有–local-rank这个参数。这是因为torch2.0版本中的所有的参数都换成了–local-rank,有些版本比较老的代码中参数还是–local_rank,这种情况下,可以降低torch版本,但是如果更换了torch版本环境也需要重新配置,并比较麻烦,还有一种比较好的方法,大家可以参考一下,就是将torch.distribution.launch 换成torch.distriution.run
如下面的命令:
python -m torch.distributed.run --nproc_per_node=4 --master_port=8675 finetune_stylegan.py --iter 600 --batch 4 --ckpt ./checkpoint/stylegan2-ffhq-config-f.pt --style cartoon --augment ./data/cartoon/lmdb/
目前这是我遇到的问题,可能还有其他的小伙伴的问题无法解决,欢迎大家讨论一下,相互进步。














 2797
2797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









