






1.下载文件
在github上下载YOLOV8模型的文件,搜索yolov8,star最多这个就是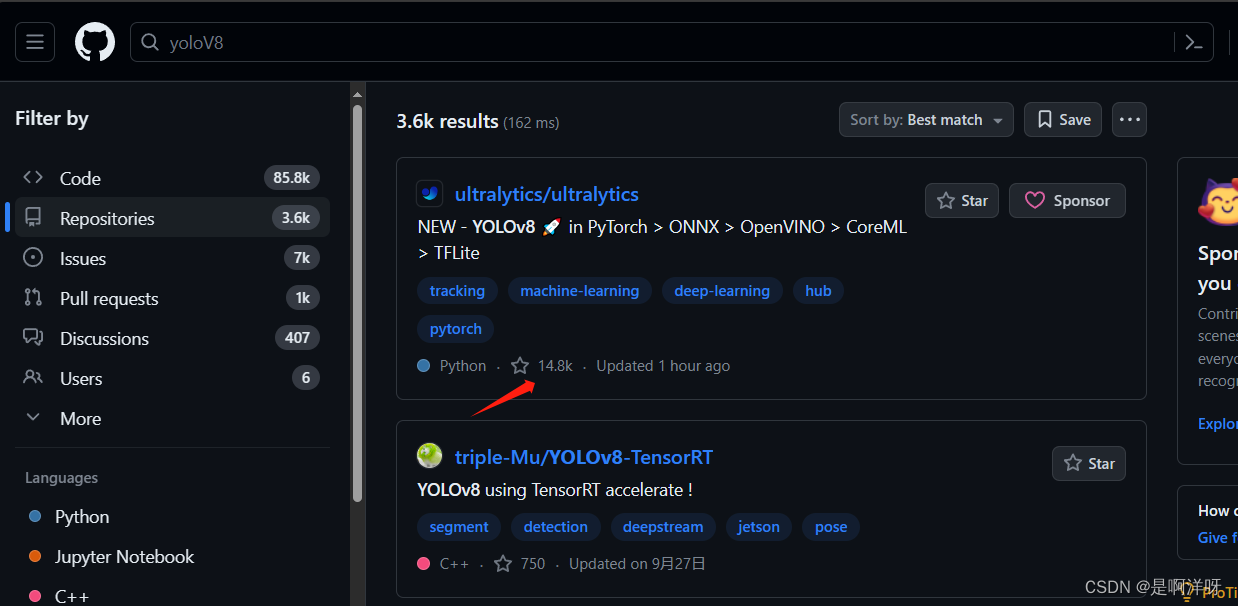
2. 准备环境
环境要求python>=3.8,PyTorch>=1.8,自行安装ptyorch环境即可

2. 制作数据集
制作数据集,需要使用labelme这个包,安装命令为
pip install labelme -i https://pypi.tuna.tsinghua.edu.cn/simple
然后启动labelme,在终端输入labelme这个命令即可

打开后是这样,我这个是汉化过的了,正常打开是英文的
然后点击labelme界面的打开文件夹,打开你准备标的图片
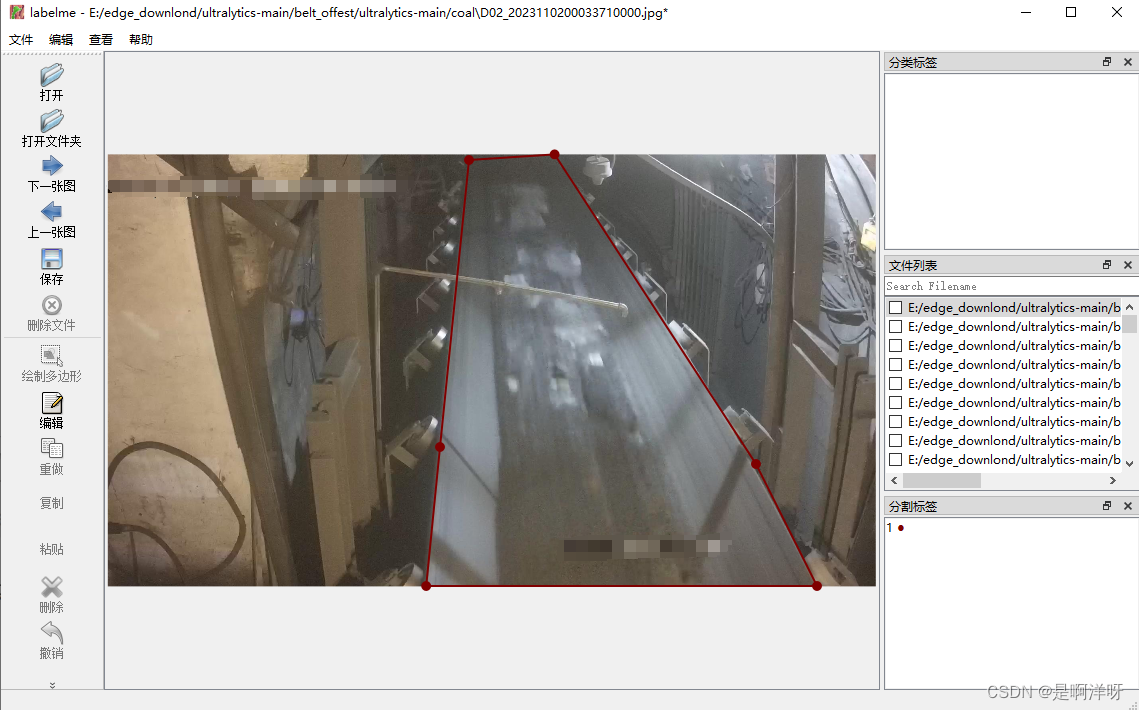
正常标即可,标完后,你会在文件夹下看到很多.json格式的文件,正常时一张图片,对应一个.json文件。
到现在数据集还不能用,需要把标好的数据集转化称YOLOv8能用的数据集,这里需要下载一个包,叫做labelme2yolo,直接pip命令下载即可
pip install labelme2yolo
然后输入命令,改变数据集格式
labelme2yolo --json_dir /path/to/labelme_json_dir/ --val_size 0.15 --test_size 0.15
这里的 –val_size 0.15 --test_size 0.15表示,划分数据集,其中70%用来训练,15%评估,15%测试
完成后,你会看到文件夹下的数据集,名称为YOLODataset,YOLODataset问价下有两个文件夹,分别是images和labels,和一个dataset.yaml文件
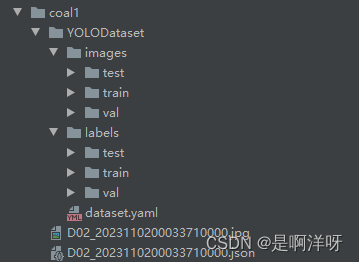
3.训练模型
训练模型,首先需要准备训练文件
from ultralytics import YOLO
# Load a model
#
model = YOLO('yolov8n-seg.yaml').load('yolov8n-seg.pt') # build from YAML and transfer weights
# Train the model
#这里需的dataset.yaml文件,是第二步使用labelme2yolo自动生成的
model.train(data='E:\\edge_downlond\\ultralytics-main\\ultralytics-main_9_7\\datasets\\YOLODataset\\dataset.yaml' , epochs=300)
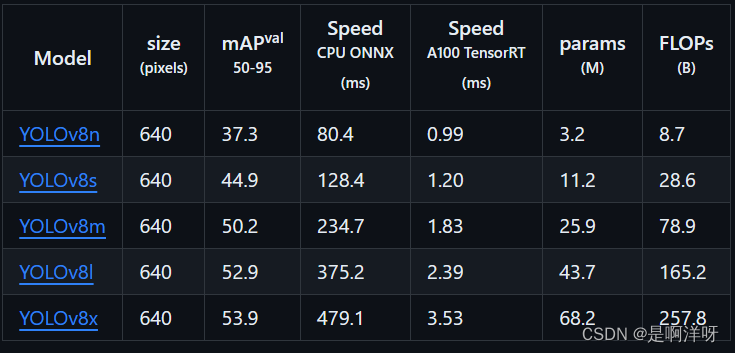
如果第一次运行,这里需要下载预训练文件,需要梯子下载,没有的话需要手动去github下载,预训练文件有不同大小的,这里根据需求选择即可,一般来说,大模型效果更好,但是花费的时间也更多,速度慢
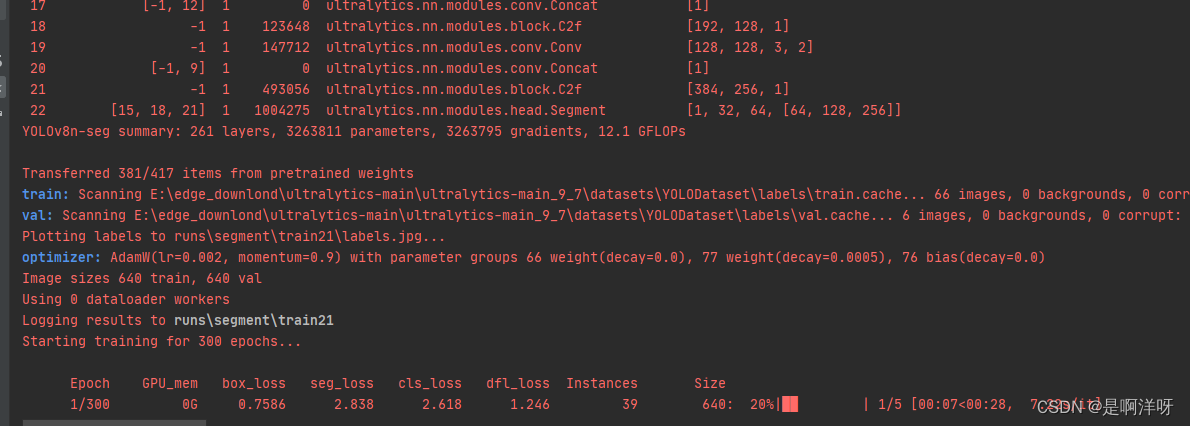
启动训练文件,运行即可,这样就是成功训练了
训练完成后,会生成权重文件,保存在runs文件夹下

3.运行模型
创建一个运行模型的文件
from ultralytics import YOLO
model = YOLO('runs/segment/train5/weights/best.pt') # load a custom model
#改成自己的权重文件路径
results = model(source="./6.mp4", save=True )
#source的路径改成自己需要分割的,图片视频均可
点击文件运行即可,运行的结果保存在runs文件夹下面















 665
665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









