







关于yolov8数据集中使用labelme标注的全过程(倒霉蛋自用版)
1. 第一步,先标注,得到小json
当然,首先是利用labelme进行标注,选用以下特征进行标注
1.playground
2.soil
3.lake
4.building
5.tree or grass
6.road
 你会得到对应的图像的一个个的json文件
你会得到对应的图像的一个个的json文件
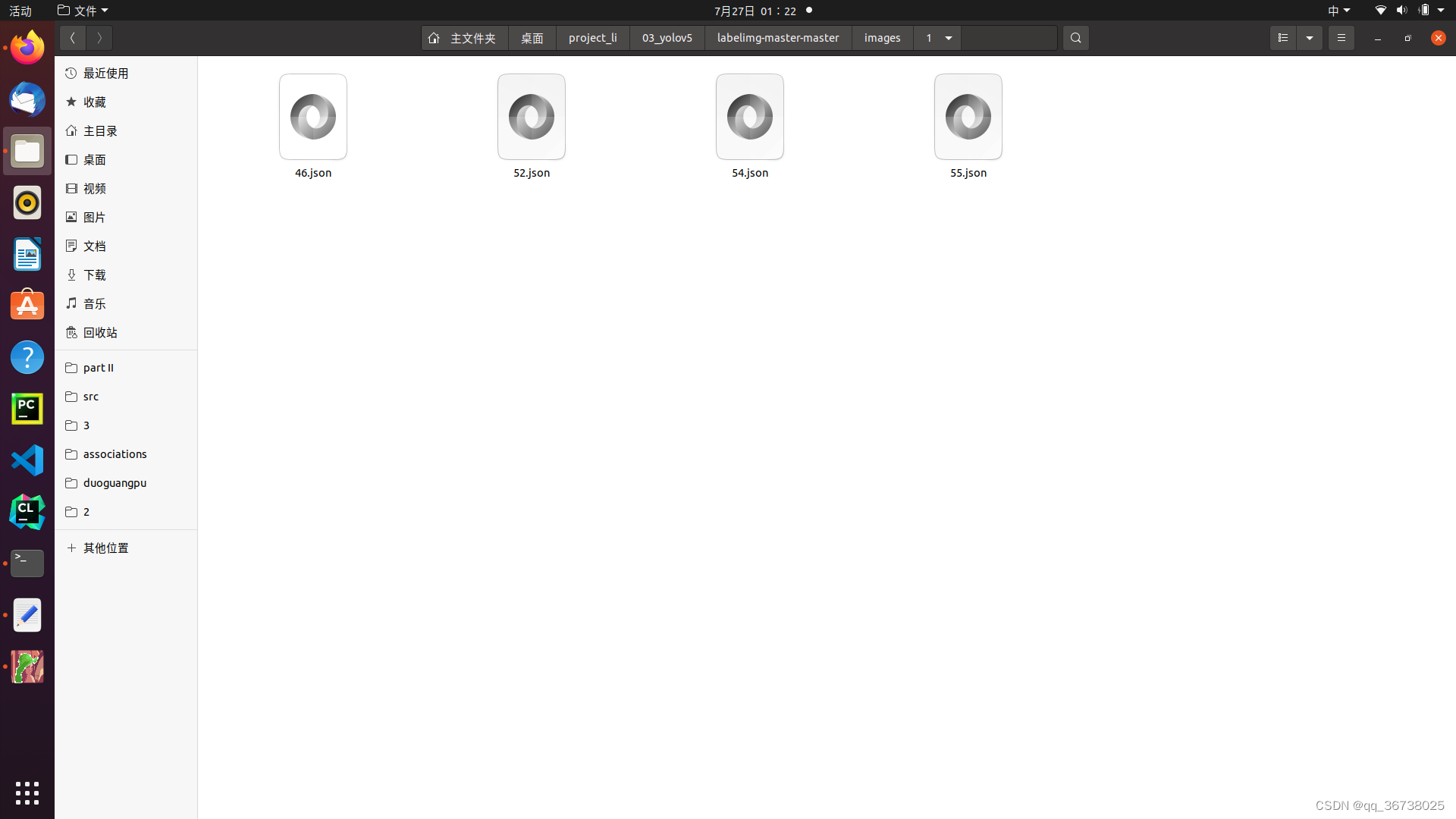
利用这样的标注进行,会得到json文件,但是json文件不能直接用于yolov8的训练,因此需要转成其他格式
2. json格式转coco格式
这一部曹了一天的坑
因为网上的其他哥们的代码有问题,导致转换后无法直接使用,训练时代码报错,所以我在这里给大家之一条名录
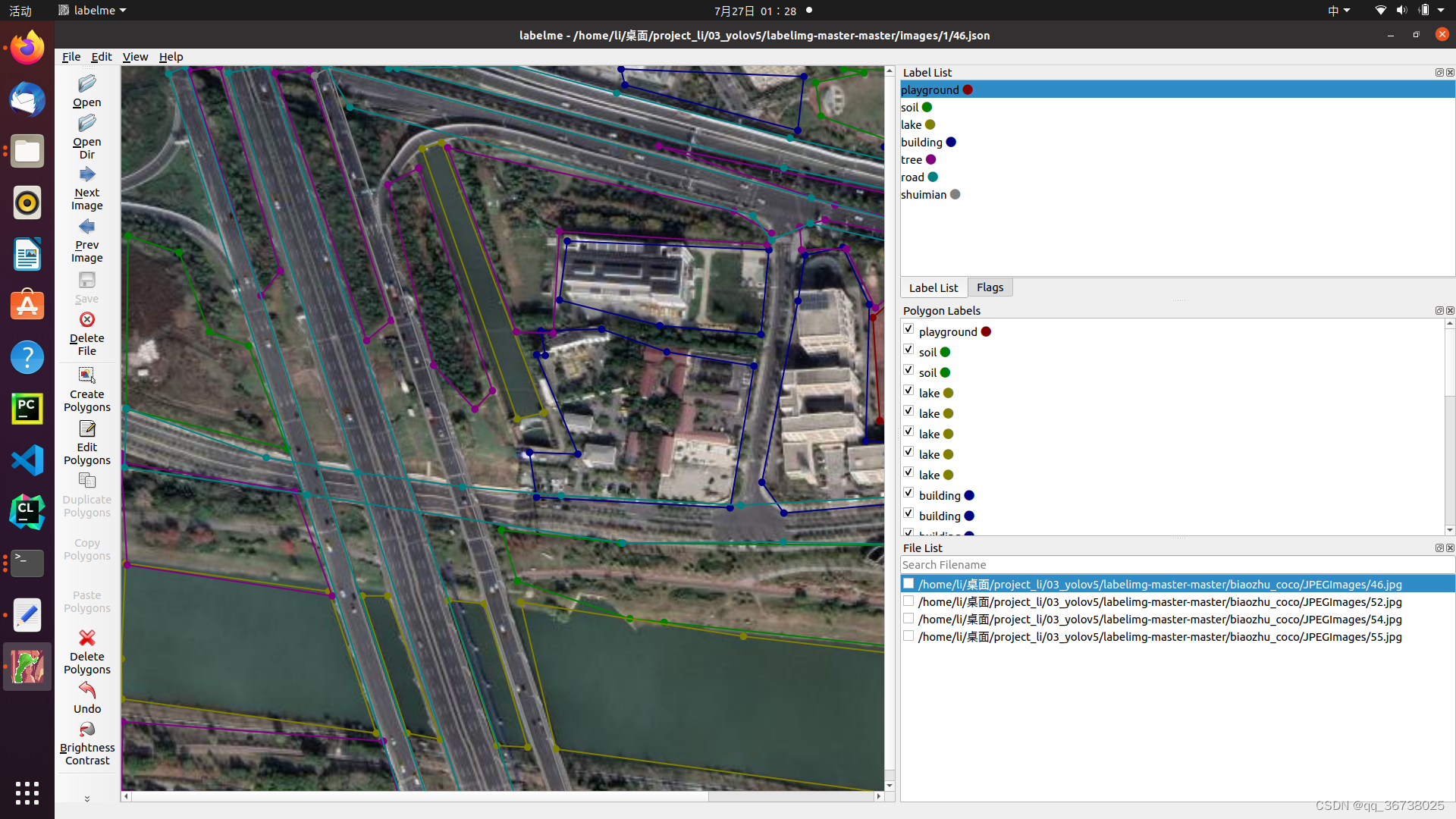
首先是根据你的label生成 一个txt文件
坑1
txt文件加以东西,就是最上面的背景
然后是坑2,网上的py程序有问题,我这里直接给大家代码了 ,和我 一样的文件夹名字就不用修改路径,直接运行 import argparse
import argparse
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuid
import imgviz
import numpy as np
import labelme
try:
import pycocotools.mask
except ImportError:
print(“Please install pycocotools:\n\n pip install pycocotools\n”)
sys.exit(1)
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument(“–input_dir”, default=“1”, help=“input annotated directory”)
parser.add_argument(“–output_dir”, default=“coco”, help=“output dataset directory”)
parser.add_argument(“–labels”, default=“label.txt”, help=“labels file”)
parser.add_argument(
“–noviz”, help=“no visualization”, action=“store_true”
)
args = parser.parse_args()
if not os.path.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
print("Creating dataset:", args.output_dir)
now = datetime.datetime.now()
data = dict(
info=dict(
description=None,
url=None,
version=None,
year=now.year,
contributor=None,
date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),
),
licenses=[dict(url=None, id=0, name=None, )],
images=[
# license, url, file_name, height, width, date_captured, id
],
type="instances",
annotations=[
# segmentation, area, iscrowd, image_id, bbox, category_id, id
],
categories=[
# supercategory, id, name
],
)
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
if class_id == -1:
assert class_name == "__ignore__"
continue
class_name_to_id[class_name] = class_id
data["categories"].append(
dict(supercategory=None, id=class_id, name=class_name, )
)
out_ann_file = osp.join(args.output_dir, "annotations.json")
label_files = glob.glob(osp.join(args.input_dir, "*.json"))
for image_id, filename in enumerate(label_files):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
print(label_file)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
data["images"].append(
dict(
license=0,
url=None,
file_name=osp.relpath( base + ".jpg"),
height=img.shape[0],
width=img.shape[1],
date_captured=None,
id=image_id,
)
)
masks = {} # for area
segmentations = collections.defaultdict(list) # for segmentation
for shape in label_file.shapes:
points = shape["points"]
label = shape["label"]
group_id = shape.get("group_id")
shape_type = shape.get("shape_type", "polygon")
mask = labelme.utils.shape_to_mask(
img.shape[:2], points, shape_type
)
if group_id is None:
group_id = uuid.uuid1()
instance = (label, group_id)
if instance in masks:
masks[instance] = masks[instance] | mask
else:
masks[instance] = mask
if shape_type == "rectangle":
(x1, y1), (x2, y2) = points
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
points = [x1, y1, x2, y1, x2, y2, x1, y2]
else:
points = np.asarray(points).flatten().tolist()
segmentations[instance].append(points)
segmentations = dict(segmentations)
for instance, mask in masks.items():
cls_name, group_id = instance
if cls_name not in class_name_to_id:
continue
cls_id = class_name_to_id[cls_name]
mask = np.asfortranarray(mask.astype(np.uint8))
mask = pycocotools.mask.encode(mask)
area = float(pycocotools.mask.area(mask))
bbox = pycocotools.mask.toBbox(mask).flatten().tolist()
data["annotations"].append(
dict(
id=len(data["annotations"]),
image_id=image_id,
category_id=cls_id,
segmentation=segmentations[instance],
area=area,
bbox=bbox,
iscrowd=0,
)
)
if not args.noviz:
labels, captions, masks = zip(
*[
(class_name_to_id[cnm], cnm, msk)
for (cnm, gid), msk in masks.items()
if cnm in class_name_to_id
]
)
viz = imgviz.instances2rgb(
image=img,
labels=labels,
masks=masks,
captions=captions,
font_size=15,
line_width=2,
)
out_viz_file = osp.join(
args.output_dir, "Visualization", base + ".jpg"
)
imgviz.io.imsave(out_viz_file, viz)
with open(out_ann_file, "w") as f:
json.dump(data, f)
if name == “main”:
main()
运行完了,你就能得到结果了
3. coco格式转yolo
把这两个文件放到该文件夹里面,直接执行g开头的那个就行
同理,直接方代码
import contextlib
import json
import cv2
import pandas as pd
from PIL import Image
from collections import defaultdict
from utils import *
Convert INFOLKS JSON file into YOLO-format labels ----------------------------
def convert_infolks_json(name, files, img_path):
# Create folders
path = make_dirs()
# Import json
data = []
for file in glob.glob(files):
with open(file) as f:
jdata = json.load(f)
jdata['json_file'] = file
data.append(jdata)
# Write images and shapes
name = path + os.sep + name
file_id, file_name, wh, cat = [], [], [], []
for x in tqdm(data, desc='Files and Shapes'):
f = glob.glob(img_path + Path(x['json_file']).stem + '.*')[0]
file_name.append(f)
wh.append(exif_size(Image.open(f))) # (width, height)
cat.extend(a['classTitle'].lower() for a in x['output']['objects']) # categories
# filename
with open(name + '.txt', 'a') as file:
file.write('%s\n' % f)
# Write *.names file
names = sorted(np.unique(cat))
# names.pop(names.index('Missing product')) # remove
with open(name + '.names', 'a') as file:
[file.write('%s\n' % a) for a in names]
# Write labels file
for i, x in enumerate(tqdm(data, desc='Annotations')):
label_name = Path(file_name[i]).stem + '.txt'
with open(path + '/labels/' + label_name, 'a') as file:
for a in x['output']['objects']:
# if a['classTitle'] == 'Missing product':
# continue # skip
category_id = names.index(a['classTitle'].lower())
# The INFOLKS bounding box format is [x-min, y-min, x-max, y-max]
box = np.array(a['points']['exterior'], dtype=np.float32).ravel()
box[[0, 2]] /= wh[i][0] # normalize x by width
box[[1, 3]] /= wh[i][1] # normalize y by height
box = [box[[0, 2]].mean(), box[[1, 3]].mean(), box[2] - box[0], box[3] - box[1]] # xywh
if (box[2] > 0.) and (box[3] > 0.): # if w > 0 and h > 0
file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))
# Split data into train, test, and validate files
split_files(name, file_name)
write_data_data(name + '.data', nc=len(names))
print(f'Done. Output saved to {os.getcwd() + os.sep + path}')
Convert vott JSON file into YOLO-format labels -------------------------------
def convert_vott_json(name, files, img_path):
# Create folders
path = make_dirs()
name = path + os.sep + name
# Import json
data = []
for file in glob.glob(files):
with open(file) as f:
jdata = json.load(f)
jdata['json_file'] = file
data.append(jdata)
# Get all categories
file_name, wh, cat = [], [], []
for i, x in enumerate(tqdm(data, desc='Files and Shapes')):
with contextlib.suppress(Exception):
cat.extend(a['tags'][0] for a in x['regions']) # categories
# Write *.names file
names = sorted(pd.unique(cat))
with open(name + '.names', 'a') as file:
[file.write('%s\n' % a) for a in names]
# Write labels file
n1, n2 = 0, 0
missing_images = []
for i, x in enumerate(tqdm(data, desc='Annotations')):
f = glob.glob(img_path + x['asset']['name'] + '.jpg')
if len(f):
f = f[0]
file_name.append(f)
wh = exif_size(Image.open(f)) # (width, height)
n1 += 1
if (len(f) > 0) and (wh[0] > 0) and (wh[1] > 0):
n2 += 1
# append filename to list
with open(name + '.txt', 'a') as file:
file.write('%s\n' % f)
# write labelsfile
label_name = Path(f).stem + '.txt'
with open(path + '/labels/' + label_name, 'a') as file:
for a in x['regions']:
category_id = names.index(a['tags'][0])
# The INFOLKS bounding box format is [x-min, y-min, x-max, y-max]
box = a['boundingBox']
box = np.array([box['left'], box['top'], box['width'], box['height']]).ravel()
box[[0, 2]] /= wh[0] # normalize x by width
box[[1, 3]] /= wh[1] # normalize y by height
box = [box[0] + box[2] / 2, box[1] + box[3] / 2, box[2], box[3]] # xywh
if (box[2] > 0.) and (box[3] > 0.): # if w > 0 and h > 0
file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))
else:
missing_images.append(x['asset']['name'])
print('Attempted %g json imports, found %g images, imported %g annotations successfully' % (i, n1, n2))
if len(missing_images):
print('WARNING, missing images:', missing_images)
# Split data into train, test, and validate files
split_files(name, file_name)
print(f'Done. Output saved to {os.getcwd() + os.sep + path}')
Convert ath JSON file into YOLO-format labels --------------------------------
def convert_ath_json(json_dir): # dir contains json annotations and images
# Create folders
dir = make_dirs() # output directory
jsons = []
for dirpath, dirnames, filenames in os.walk(json_dir):
jsons.extend(
os.path.join(dirpath, filename)
for filename in [
f for f in filenames if f.lower().endswith('.json')
]
)
# Import json
n1, n2, n3 = 0, 0, 0
missing_images, file_name = [], []
for json_file in sorted(jsons):
with open(json_file) as f:
data = json.load(f)
# # Get classes
# try:
# classes = list(data['_via_attributes']['region']['class']['options'].values()) # classes
# except:
# classes = list(data['_via_attributes']['region']['Class']['options'].values()) # classes
# # Write *.names file
# names = pd.unique(classes) # preserves sort order
# with open(dir + 'data.names', 'w') as f:
# [f.write('%s\n' % a) for a in names]
# Write labels file
for x in tqdm(data['_via_img_metadata'].values(), desc=f'Processing {json_file}'):
image_file = str(Path(json_file).parent / x['filename'])
f = glob.glob(image_file) # image file
if len(f):
f = f[0]
file_name.append(f)
wh = exif_size(Image.open(f)) # (width, height)
n1 += 1 # all images
if len(f) > 0 and wh[0] > 0 and wh[1] > 0:
label_file = dir + 'labels/' + Path(f).stem + '.txt'
nlabels = 0
try:
with open(label_file, 'a') as file: # write labelsfile
# try:
# category_id = int(a['region_attributes']['class'])
# except:
# category_id = int(a['region_attributes']['Class'])
category_id = 0 # single-class
for a in x['regions']:
# bounding box format is [x-min, y-min, x-max, y-max]
box = a['shape_attributes']
box = np.array([box['x'], box['y'], box['width'], box['height']],
dtype=np.float32).ravel()
box[[0, 2]] /= wh[0] # normalize x by width
box[[1, 3]] /= wh[1] # normalize y by height
box = [box[0] + box[2] / 2, box[1] + box[3] / 2, box[2],
box[3]] # xywh (left-top to center x-y)
if box[2] > 0. and box[3] > 0.: # if w > 0 and h > 0
file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))
n3 += 1
nlabels += 1
if nlabels == 0: # remove non-labelled images from dataset
os.system(f'rm {label_file}')
# print('no labels for %s' % f)
continue # next file
# write image
img_size = 4096 # resize to maximum
img = cv2.imread(f) # BGR
assert img is not None, 'Image Not Found ' + f
r = img_size / max(img.shape) # size ratio
if r < 1: # downsize if necessary
h, w, _ = img.shape
img = cv2.resize(img, (int(w * r), int(h * r)), interpolation=cv2.INTER_AREA)
ifile = dir + 'images/' + Path(f).name
if cv2.imwrite(ifile, img): # if success append image to list
with open(dir + 'data.txt', 'a') as file:
file.write('%s\n' % ifile)
n2 += 1 # correct images
except Exception:
os.system(f'rm {label_file}')
print(f'problem with {f}')
else:
missing_images.append(image_file)
nm = len(missing_images) # number missing
print('\nFound %g JSONs with %g labels over %g images. Found %g images, labelled %g images successfully' %
(len(jsons), n3, n1, n1 - nm, n2))
if len(missing_images):
print('WARNING, missing images:', missing_images)
# Write *.names file
names = ['knife'] # preserves sort order
with open(dir + 'data.names', 'w') as f:
[f.write('%s\n' % a) for a in names]
# Split data into train, test, and validate files
split_rows_simple(dir + 'data.txt')
write_data_data(dir + 'data.data', nc=1)
print(f'Done. Output saved to {Path(dir).absolute()}')
def convert_coco_json(json_dir=‘…/coco/annotations/’, use_segments=False, cls91to80=False):
save_dir = make_dirs() # output directory
coco80 = coco91_to_coco80_class()
# Import json
for json_file in sorted(Path(json_dir).resolve().glob('*.json')):
fn = Path(save_dir) / 'labels' / json_file.stem.replace('instances_', '') # folder name
fn.mkdir()
with open(json_file) as f:
data = json.load(f)
# Create image dict
images = {'%g' % x['id']: x for x in data['images']}
# Create image-annotations dict
imgToAnns = defaultdict(list)
for ann in data['annotations']:
imgToAnns[ann['image_id']].append(ann)
# Write labels file
for img_id, anns in tqdm(imgToAnns.items(), desc=f'Annotations {json_file}'):
img = images['%g' % img_id]
h, w, f = img['height'], img['width'], img['file_name']
bboxes = []
segments = []
for ann in anns:
if ann['iscrowd']:
continue
# The COCO box format is [top left x, top left y, width, height]
box = np.array(ann['bbox'], dtype=np.float64)
box[:2] += box[2:] / 2 # xy top-left corner to center
box[[0, 2]] /= w # normalize x
box[[1, 3]] /= h # normalize y
if box[2] <= 0 or box[3] <= 0: # if w <= 0 and h <= 0
continue
cls = coco80[ann['category_id'] - 1] if cls91to80 else ann['category_id'] - 1 # class
box = [cls] + box.tolist()
if box not in bboxes:
bboxes.append(box)
# Segments
if use_segments:
if len(ann['segmentation']) > 1:
s = merge_multi_segment(ann['segmentation'])
s = (np.concatenate(s, axis=0) / np.array([w, h])).reshape(-1).tolist()
else:
s = [j for i in ann['segmentation'] for j in i] # all segments concatenated
s = (np.array(s).reshape(-1, 2) / np.array([w, h])).reshape(-1).tolist()
s = [cls] + s
if s not in segments:
segments.append(s)
# Write
with open((fn / f).with_suffix('.txt'), 'a') as file:
for i in range(len(bboxes)):
line = *(segments[i] if use_segments else bboxes[i]), # cls, box or segments
file.write(('%g ' * len(line)).rstrip() % line + '\n')
def min_index(arr1, arr2):
“”“Find a pair of indexes with the shortest distance.
Args:
arr1: (N, 2).
arr2: (M, 2).
Return:
a pair of indexes(tuple).
“””
dis = ((arr1[:, None, :] - arr2[None, :, :]) ** 2).sum(-1)
return np.unravel_index(np.argmin(dis, axis=None), dis.shape)
def merge_multi_segment(segments):
“”"Merge multi segments to one list.
Find the coordinates with min distance between each segment,
then connect these coordinates with one thin line to merge all
segments into one.
Args:
segments(List(List)): original segmentations in coco's json file.
like [segmentation1, segmentation2,...],
each segmentation is a list of coordinates.
"""
s = []
segments = [np.array(i).reshape(-1, 2) for i in segments]
idx_list = [[] for _ in range(len(segments))]
# record the indexes with min distance between each segment
for i in range(1, len(segments)):
idx1, idx2 = min_index(segments[i - 1], segments[i])
idx_list[i - 1].append(idx1)
idx_list[i].append(idx2)
# use two round to connect all the segments
for k in range(2):
# forward connection
if k == 0:
for i, idx in enumerate(idx_list):
# middle segments have two indexes
# reverse the index of middle segments
if len(idx) == 2 and idx[0] > idx[1]:
idx = idx[::-1]
segments[i] = segments[i][::-1, :]
segments[i] = np.roll(segments[i], -idx[0], axis=0)
segments[i] = np.concatenate([segments[i], segments[i][:1]])
# deal with the first segment and the last one
if i in [0, len(idx_list) - 1]:
s.append(segments[i])
else:
idx = [0, idx[1] - idx[0]]
s.append(segments[i][idx[0]:idx[1] + 1])
else:
for i in range(len(idx_list) - 1, -1, -1):
if i not in [0, len(idx_list) - 1]:
idx = idx_list[i]
nidx = abs(idx[1] - idx[0])
s.append(segments[i][nidx:])
return s
def delete_dsstore(path=‘…/datasets’):
# Delete apple .DS_store files
from pathlib import Path
files = list(Path(path).rglob(‘.DS_store’))
print(files)
for f in files:
f.unlink()
if name == ‘main’:
source = ‘COCO’
if source == 'COCO':
convert_coco_json('./', # directory with *.json
use_segments=True,
cls91to80=True)
elif source == 'infolks': # Infolks https://infolks.info/
convert_infolks_json(name='out',
files='../data/sm4/json/*.json',
img_path='../data/sm4/images/')
elif source == 'vott': # VoTT https://github.com/microsoft/VoTT
convert_vott_json(name='data',
files='../../Downloads/athena_day/20190715/*.json',
img_path='../../Downloads/athena_day/20190715/') # images folder
elif source == 'ath': # ath format
convert_ath_json(json_dir='../../Downloads/athena/') # images folder
# zip results
# os.system('zip -r ../coco.zip ../coco')
第二个
import glob
import os
import shutil
from pathlib import Path
import numpy as np
from PIL import ExifTags
from tqdm import tqdm
Parameters
img_formats = [‘bmp’, ‘jpg’, ‘jpeg’, ‘png’, ‘tif’, ‘tiff’, ‘dng’] # acceptable image suffixes
vid_formats = [‘mov’, ‘avi’, ‘mp4’, ‘mpg’, ‘mpeg’, ‘m4v’, ‘wmv’, ‘mkv’] # acceptable video suffixes
Get orientation exif tag
for orientation in ExifTags.TAGS.keys():
if ExifTags.TAGS[orientation] == ‘Orientation’:
break
def exif_size(img):
# Returns exif-corrected PIL size
s = img.size # (width, height)
try:
rotation = dict(img._getexif().items())[orientation]
if rotation in [6, 8]: # rotation 270
s = (s[1], s[0])
except:
pass
return s
def split_rows_simple(file=‘…/data/sm4/out.txt’): # from utils import *; split_rows_simple()
# splits one textfile into 3 smaller ones based upon train, test, val ratios
with open(file) as f:
lines = f.readlines()
s = Path(file).suffix
lines = sorted(list(filter(lambda x: len(x) > 0, lines)))
i, j, k = split_indices(lines, train=0.9, test=0.1, validate=0.0)
for k, v in {'train': i, 'test': j, 'val': k}.items(): # key, value pairs
if v.any():
new_file = file.replace(s, f'_{k}{s}')
with open(new_file, 'w') as f:
f.writelines([lines[i] for i in v])
def split_files(out_path, file_name, prefix_path=‘’): # split training data
file_name = list(filter(lambda x: len(x) > 0, file_name))
file_name = sorted(file_name)
i, j, k = split_indices(file_name, train=0.9, test=0.1, validate=0.0)
datasets = {‘train’: i, ‘test’: j, ‘val’: k}
for key, item in datasets.items():
if item.any():
with open(f’{out_path}_{key}.txt’, ‘a’) as file:
for i in item:
file.write(‘%s%s\n’ % (prefix_path, file_name[i]))
def split_indices(x, train=0.9, test=0.1, validate=0.0, shuffle=True): # split training data
n = len(x)
v = np.arange(n)
if shuffle:
np.random.shuffle(v)
i = round(n * train) # train
j = round(n * test) + i # test
k = round(n * validate) + j # validate
return v[:i], v[i:j], v[j:k] # return indices
def make_dirs(dir=‘new_dir/’):
# Create folders
dir = Path(dir)
if dir.exists():
shutil.rmtree(dir) # delete dir
for p in dir, dir / ‘labels’, dir / ‘images’:
p.mkdir(parents=True, exist_ok=True) # make dir
return dir
def write_data_data(fname=‘data.data’, nc=80):
# write darknet *.data file
lines = [‘classes = %g\n’ % nc,
‘train =…/out/data_train.txt\n’,
‘valid =…/out/data_test.txt\n’,
‘names =…/out/data.names\n’,
‘backup = backup/\n’,
‘eval = coco\n’]
with open(fname, 'a') as f:
f.writelines(lines)
def image_folder2file(folder=‘images/’): # from utils import ; image_folder2file()
# write a txt file listing all imaged in folder
s = glob.glob(f’{folder}.*‘)
with open(f’{folder[:-1]}.txt’, ‘w’) as file:
for l in s:
file.write(l + ‘\n’) # write image list
def add_coco_background(path=‘…/data/sm4/’, n=1000): # from utils import *; add_coco_background()
# add coco background to sm4 in outb.txt
p = f’{path}background’
if os.path.exists§:
shutil.rmtree§ # delete output folder
os.makedirs§ # make new output folder
# copy images
for image in glob.glob('../coco/images/train2014/*.*')[:n]:
os.system(f'cp {image} {p}')
# add to outb.txt and make train, test.txt files
f = f'{path}out.txt'
fb = f'{path}outb.txt'
os.system(f'cp {f} {fb}')
with open(fb, 'a') as file:
file.writelines(i + '\n' for i in glob.glob(f'{p}/*.*'))
split_rows_simple(file=fb)
def create_single_class_dataset(path=‘…/data/sm3’): # from utils import *; create_single_class_dataset(‘…/data/sm3/’)
# creates a single-class version of an existing dataset
os.system(f’mkdir {path}_1cls’)
def flatten_recursive_folders(path=‘…/…/Downloads/data/sm4/’): # from utils import *; flatten_recursive_folders()
# flattens nested folders in path/images and path/JSON into single folders
idir, jdir = f’{path}images/‘, f’{path}json/’
nidir, njdir = Path(f’{path}images_flat/‘), Path(f’{path}json_flat/')
n = 0
# Create output folders
for p in [nidir, njdir]:
if os.path.exists(p):
shutil.rmtree(p) # delete output folder
os.makedirs(p) # make new output folder
for parent, dirs, files in os.walk(idir):
for f in tqdm(files, desc=parent):
f = Path(f)
stem, suffix = f.stem, f.suffix
if suffix.lower()[1:] in img_formats:
n += 1
stem_new = '%g_' % n + stem
image_new = nidir / (stem_new + suffix) # converts all formats to *.jpg
json_new = njdir / f'{stem_new}.json'
image = parent / f
json = Path(parent.replace('images', 'json')) / str(f).replace(suffix, '.json')
os.system("cp '%s' '%s'" % (json, json_new))
os.system("cp '%s' '%s'" % (image, image_new))
# cv2.imwrite(str(image_new), cv2.imread(str(image)))
print('Flattening complete: %g jsons and images' % n)
def coco91_to_coco80_class(): # converts 80-index (val2014) to 91-index (paper)
# https://tech.amikelive.com/node-718/what-object-categories-labels-are-in-coco-dataset/
x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, None, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, None, 24, 25, None,
None, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, None, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
51, 52, 53, 54, 55, 56, 57, 58, 59, None, 60, None, None, 61, None, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72,
None, 73, 74, 75, 76, 77, 78, 79, None]
return x
ok,大功告成,
label文件夹里的txt文件就是最后训练的时候使用的
终于写完了,睡觉睡觉















 2118
2118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









