






一、环境配置
- 下载Anaconda,进入conda ,利用conda create -n xxx创建自己的环
conda create -n yolov8 python=3.9 conda activate yolov8 - 装pytorch,进入pytorch官网,根据需要进行选择,后复制命令至conda
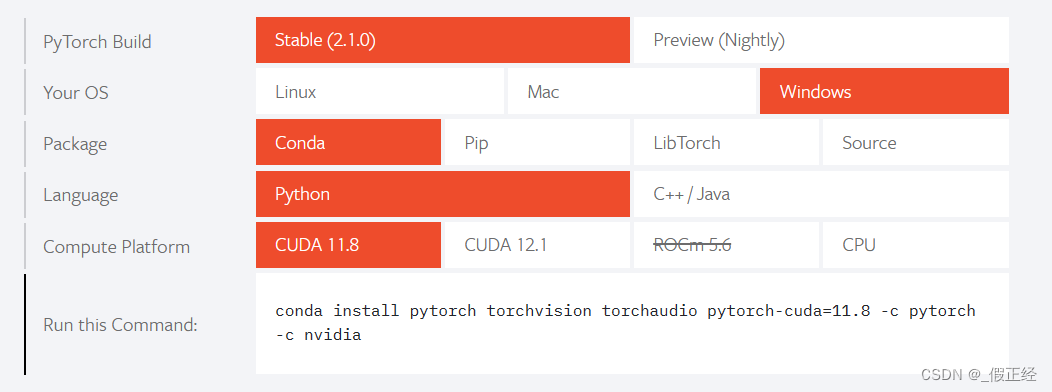

- 进入官网下载yolov8至指定文件夹
- 在conda中进入该文件夹

- 执行以下代码配置yolov8环境
pip install ultralytics pip install -r requirements.txt - 至此环境搭建完毕,在yolov8所在环境中执行以下conda命令,进行验证
二、数据集标注
参考以下内容
labelme的安装及使用_labelme安装-CSDN博客
三、训练
分配数据集
- 在yolov8中创建存放数据集文件夹 dataset
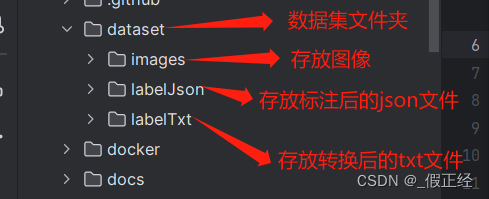
- 将labelme标注的json文件格式转为txt格式
-
# -*- coding: utf-8 -*- import json import os import argparse from tqdm import tqdm import glob import cv2 import numpy as np def convert_label_json(json_dir, save_dir, classes): json_paths = os.listdir(json_dir) classes = classes.split(',') for json_path in tqdm(json_paths): # for json_path in json_paths: path = os.path.join(json_dir, json_path) # print(path) with open(path, 'r') as load_f: print(load_f) json_dict = json.load(load_f, ) h, w = json_dict['imageHeight'], json_dict['imageWidth'] # save txt path txt_path = os.path.join(save_dir, json_path.replace('json', 'txt')) txt_file = open(txt_path, 'w') for shape_dict in json_dict['shapes']: label = shape_dict['label'] label_index = classes.index(label) points = shape_dict['points'] points_nor_list = [] for point in points: points_nor_list.append(point[0] / w) points_nor_list.append(point[1] / h) points_nor_list = list(map(lambda x: str(x), points_nor_list)) points_nor_str = ' '.join(points_nor_list) label_str = str(label_index) + ' ' + points_nor_str + '\n' txt_file.writelines(label_str) # 填写json文件地址 # 填写txt文件格式 # 填写类别名称 if __name__ == "__main__": parser = argparse.ArgumentParser(description='json convert to txt params') parser.add_argument('--json-dir', type=str, default='dataset/labelJson', help='json path dir') parser.add_argument('--save-dir', type=str, default='dataset/labelTxt', help='txt save dir') parser.add_argument('--classes', type=str, default='YL,DEFECT,TongXinYuan', help='classes') args = parser.parse_args() json_dir = args.json_dir save_dir = args.save_dir classes = args.classes convert_label_json(json_dir, save_dir, classes) - 在ultralytics下创建mydata文件夹存放训练和验证图像
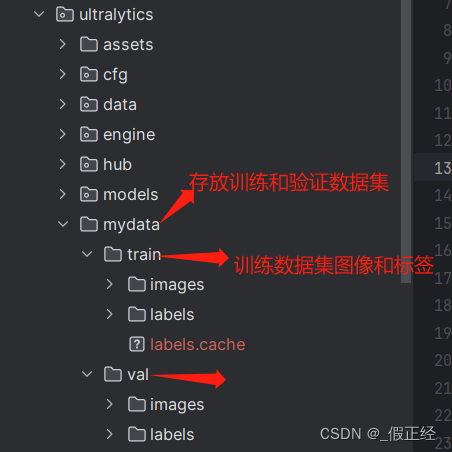
- 进行数据集的划分,splitData.py
# -*- coding:utf-8 -*
import os
import random
import os
import shutil
def data_split(full_list, ratio):
n_total = len(full_list)
offset = int(n_total * ratio)
if n_total == 0 or offset < 1:
return [], full_list
random.shuffle(full_list)
sublist_1 = full_list[:offset]
sublist_2 = full_list[offset:]
return sublist_1, sublist_2
train_p="ultralytics/mydata/train" #训练集路径
val_p="ultralytics/mydata/val" #验证集路径
imgs_p="images" #存放图像的文件夹名称
labels_p="labels" #存放标签的文件夹名称
#创建训练集
if not os.path.exists(train_p):#指定要创建的目录
os.mkdir(train_p)
tp1=os.path.join(train_p,imgs_p)
tp2=os.path.join(train_p,labels_p)
print(tp1,tp2)
if not os.path.exists(tp1):#指定要创建的目录
os.mkdir(tp1)
if not os.path.exists(tp2): # 指定要创建的目录
os.mkdir(tp2)
#创建测试集文件夹
if not os.path.exists(val_p):#指定要创建的目录
os.mkdir(val_p)
vp1=os.path.join(val_p,imgs_p)
vp2=os.path.join(val_p,labels_p)
print(vp1,vp2)
if not os.path.exists(vp1):#指定要创建的目录
os.mkdir(vp1)
if not os.path.exists(vp2): # 指定要创建的目录
os.mkdir(vp2)
#数据集路径
images_dir="dataset/images"
labels_dir="dataset/labelTxt"
#划分数据集,设置数据集数量占比
proportion_ = 0.9 #训练集占比
total_file = os.listdir(images_dir)
num = len(total_file) # 统计所有的标注文件
list_=[]
for i in range(0,num):
list_.append(i)
list1,list2=data_split(list_,proportion_)
for i in range(0,num):
file=total_file[i]
print(i,' - ',total_file[i])
name=file.split('.')[0]
if i in list1:
jpg_1 = os.path.join(images_dir, file)
jpg_2 = os.path.join(train_p, imgs_p, file)
txt_1 = os.path.join(labels_dir, name + '.txt')
txt_2 = os.path.join(train_p, labels_p, name + '.txt')
if os.path.exists(txt_1) and os.path.exists(jpg_1):
shutil.copyfile(jpg_1, jpg_2)
shutil.copyfile(txt_1, txt_2)
elif os.path.exists(txt_1):
print(txt_1)
else:
print(jpg_1)
elif i in list2:
jpg_1 = os.path.join(images_dir, file)
jpg_2 = os.path.join(val_p, imgs_p, file)
txt_1 = os.path.join(labels_dir, name + '.txt')
txt_2 = os.path.join(val_p, labels_p, name + '.txt')
shutil.copyfile(jpg_1, jpg_2)
shutil.copyfile(txt_1, txt_2)
print("数据集划分完成: 总数量:",num," 训练集数量:",len(list1)," 验证集数量:",len(list2))
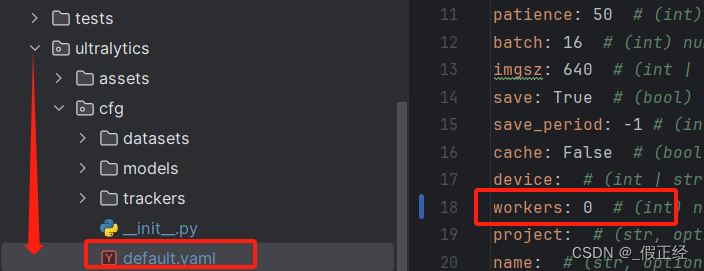
参数配置修改
- deault.yaml中有各种训练、验证、测试的默认配置参数,所在位置如图所示。使用windows进行训练的将文件中的workers改为0,否则报错
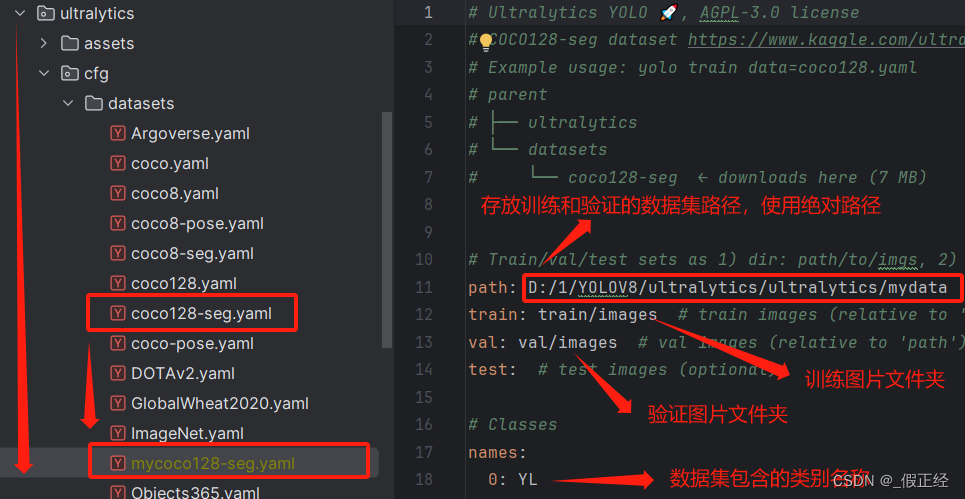
- 创建数据配置文件mycoco128-seg.yaml,该文件由coco128-seg.yaml修改得来
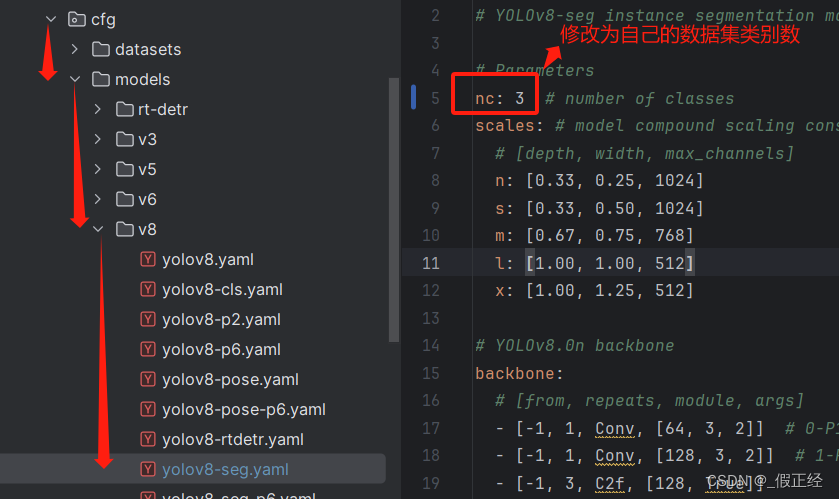
- 修改yolov-seg.yaml中的nc
训练
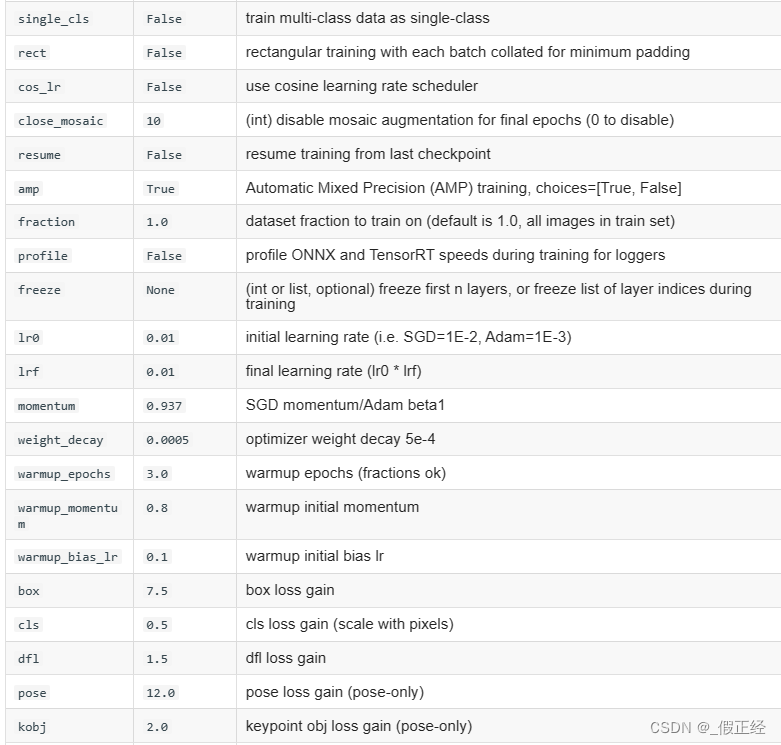
- 创建一个python文件myTrain,并对参数进行设置否则采用默认,运行该文件即可开始训练,其参数如下表
from ultralytics import YOLO
# Load a model
model = YOLO('ultralytics/cfg/models/v8/yolov8-seg.yaml') # build a new model from YAML
model = YOLO('yolov8s-seg.pt') # load a pretrained model (recommended for training)
model = YOLO('ultralytics/cfg/models/v8/yolov8-seg.yaml').load('yolov8s-seg.pt') # build from YAML and transfer weights
# Train the model
results = model.train(data='ultralytics/cfg/datasets/mycoco128-seg.yaml', epochs=100, batch=4, imgsz=640, workers=0)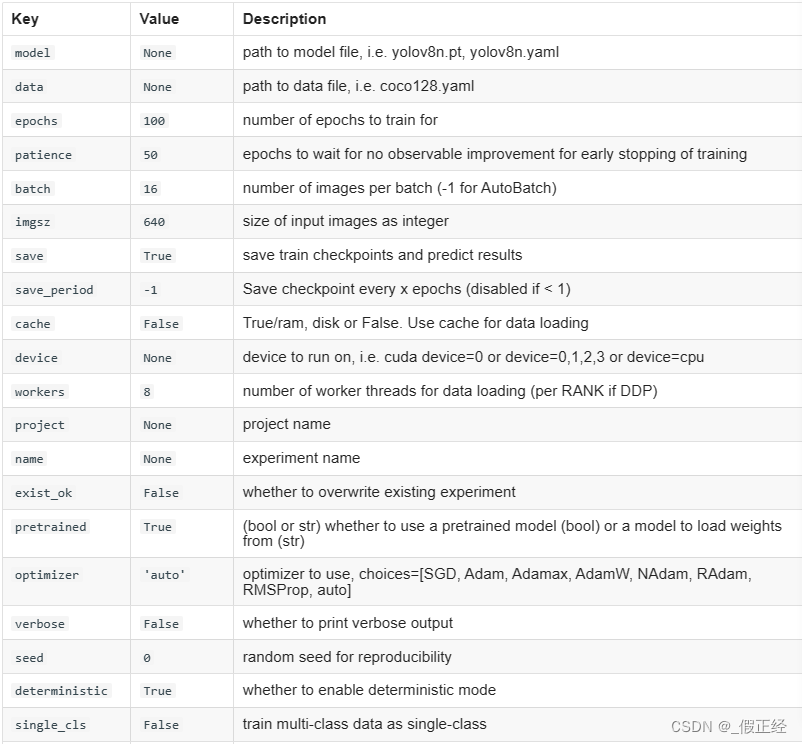

验证
创建一个python文件myVal,对训练模型进行验证,参数如下表,不进行设置则采用默认
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8s-seg.pt') # load an official model
model = YOLO('runs/segment/train8/weights/best.pt') # load a custom model
# Validate the model
metrics = model.val(batch=16, conf=0.01, iou=0.5) # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category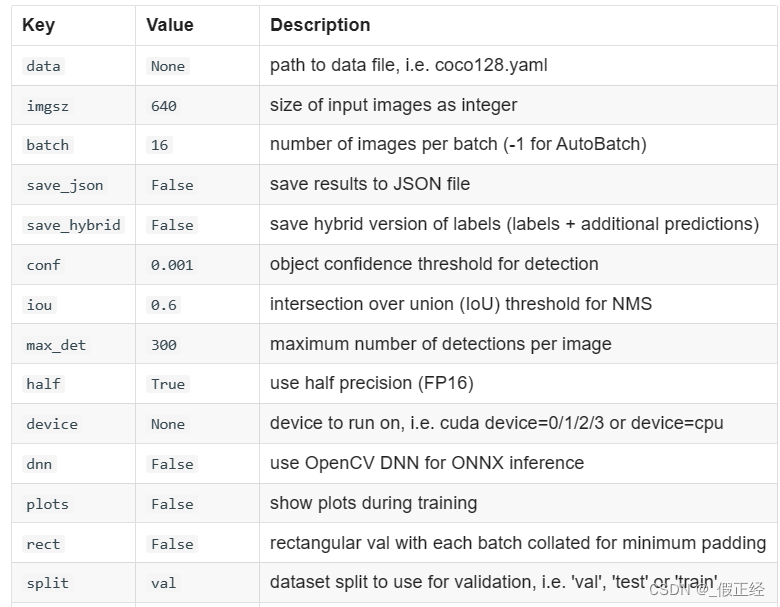
预测
创建一个python文件myPredict,对参数进行设置后运行该文件即可
from ultralytics import YOLO
# Load a pretrained YOLOv8n model
model = YOLO('runs/segment/train8/weights/best.pt')
# Run inference on 'bus.jpg' with arguments
model.predict('ultralytics/mydata/val/images', save=True,conf=0.25, iou=0.7)
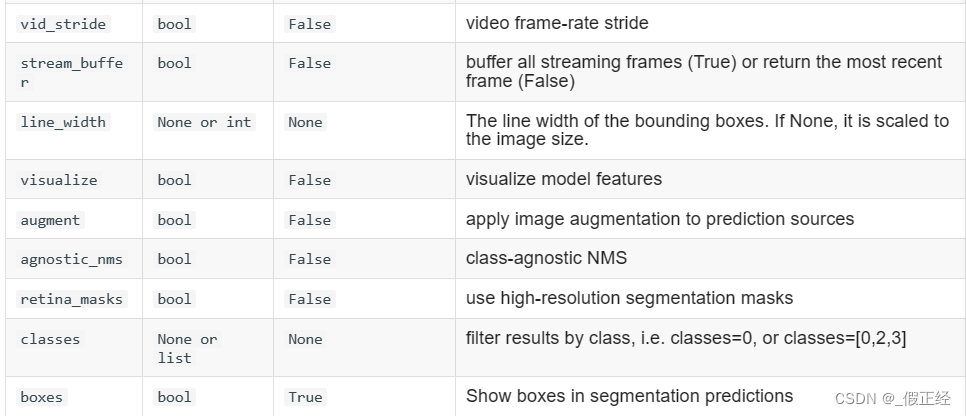
其他具体操作可看官方文档Home - Ultralytics YOLOv8 Docs















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









