







论文:http://arxiv.org/abs/2007.02442
code:https://github.com/autonomousvision/graf
摘要
2D生成对抗网络可以实现高分辨率图像合成,但不能很好地应用在3D图像合成。为解决这个问题,出现了基于中间体素的表示与可区分渲染相结合的几种方法,但这些方法存在几个问题:1)合成的图像分辨率低;2)在分离相机和场景属性方面存在不足。
本文提出了一个辐射场的生成模型,该模型已被证明在单一场景的新型视图合成中是成功的。与基于体素的表征相比,辐射场并不局限于三维空间的粗略离散,而是允许分解相机和场景属性,同时在重建模糊性的情况下优雅地退化。通过引入一个基于多尺度patch-based的判别器,仅通过未处理的二维图像训练本文中的模型,也能实现高分辨率图像的合成。
1 Introduction
尽管convolutional GANs 可以实现从无序的图像集合中合成高分辨率图像,但最先进的模型仍难以正确地分解包括三维形状和视点在内的基本生成因素。相比之下,人类具有推理世界的三维结构和从新的视角想象物体的能力。
由于三维推理是机器人、虚拟现实或数据增强应用的基础,便出现了考虑三维感知图像合成的任务,目的是通过明确控制摄像机的姿势来生成逼真的图像。与2D GANs相比,用于三维感知图像合成的方法学习一个三维场景表示,该表示使用可区分的渲染技术明确地映射到图像上,因此提供对场景内容和视角的控制。
但三维监督或摆放的图像在实践中往往很难获得,于是考虑只用二维监督来解决这一任务,现有的方法使用离散的三维表示,如代表完整的3D物体的 voxel-grid 或者intermediate 3D features来实现这一目标,如下图1所示:
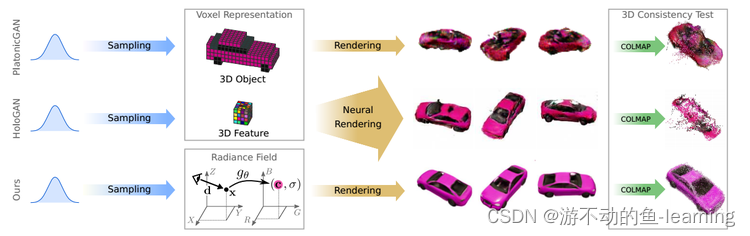
"图 1 Motivation"
虽然在色彩空间中对三维物体进行建模可以利用微分渲染,但基于体素的表示法的cubic memory growth的限制使得只能合成低分辨率图像,并导致了可见的伪影。intermediate 3D features更加紧凑,并且有更好的图像分辨率。但这需要学习3D到2D的映射,用于将抽象特征解码为RGB值,这会导致高分辨率下视图之间不一致。
1.1 本文的贡献
- GRAF设计了一种NeRF表示的条件变体,展示了如何从一组未设定pose的2D图像中学习出丰富的生成模型。除了viewpoint操作,还允许修改生成物体的形状和外观。
- 引入一个patch-based的判别器,它在多个尺度上对图像采样,这是有效学习高分辨率生成性NeRF的关键。
2 Related Work
2.1 图像合成
GANs显著提升了照片级真实感图像合成的显著水平。但2D图像是作为3D世界的投影获得的,虽然有一些方法表明disentangled factors在一定程度上抓住 了一些3D属性,但使用2D卷积网络对图像流形建模仍十分困难,特别是多视图一致以及寻求能可靠地将视点变化与物体appearance和identity分离的表示。因此,本文采取生成3D表示并明确地对图像形成过程进行建模的方法。
2.2 3D感知的图像合成
2.3 隐式表示
3D 几何的隐式表示在learning-based的3D重建中得到了普及,与基于体素或网格的方法相比,其主要优点是不离散空间,不受拓扑结构的限制。NeRF将场景表示为神经辐射场,这允许从posed 2D图像中对更复杂的真实世界场景进行多视角一致的新视角合成。本文受NeRF启发,设计了一种NeRF表示的条件变体GRAF,并展示了如何从一组未设定pose的2D图像中学习丰富的生成模型作为输入。
3 Method
3.1 Neural Radiance Fields(NeRF)
详细内容参考博客:https://blog.csdn.net/KeepLearning1/article/details/129923446
3.2 Generative Radiance Fields
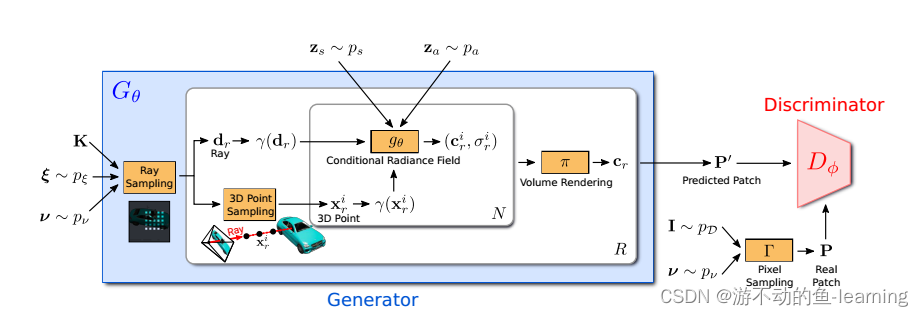
"图 2 GRAF的整体框架"
GRAF的整体框架如图2所示,和GAN类似,GRAF分成Generator G θ G_{\theta} Gθ和Discriminator D ϕ D_{ \phi } Dϕ两个部分。generator部分将相机矩阵 K K K ,相机位姿 ξ \xi ξ,2D采样模板 v \mathcal{v} v 和形状/外观编码 z s ∈ R m / z a ∈ R n z_s ∈ R^m/z_a ∈ R^n zs∈Rm/za∈Rn作为输入, 并预测一个图像patch P ′ P^′ P′ ,其中每个Ray由 K , ξ , v K,\xi,v K,ξ,v 三个输入决定,conditional radiance field是generator唯一可学习的部分。discriminator对预测合成的patch P ′ P^′ P′ 和真实图片采样得到真实patch P P P进行判断。训练阶段,GRAF使用稀疏的 K × K K \times K K×K个像素点的fixed patch进行高效优化,测试阶段,预测出目标图片的每个像素的颜色值。(训练时如果也对每个像素值的颜色值进行预测,这个成本太高了)
3.2.1 Generator
从姿态分布 p ξ p_{\xi} pξ中采样相机姿态(pose) ξ = [ R ∣ t ] \xi=[R|t] ξ=[R∣t],在本文实验中,采用半球的均匀分布作为相机位置,相机面向坐标系的原点。根据数据集的不同,均匀地改变相机到原点的距离。同时选择K使得主点在图像的中心。
ν = ( u , s ) ν = (u,s) ν=(u,s)决定了 K × K K × K K×K个patch P ( u , s ) P(u,s) P(u,s)的中心位置 u = ( u , v ) ∈ R 2 u = (u,v)∈R ^ 2 u=(u,v)∈R2和尺度 s ∈ R + s ∈ R ^+ s∈
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1284
1284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









