







本章主要讲解了矢量量化(Vector Quantization)这种信号压缩方法,并介绍了如何通过K-Means这种聚类算法构建矢量的码书(code-book vectors)。
矢量量化Vector Quantization
线性矢量量化
如下图所示,沿着输入仿真信号analog voltage的值域[0-1]进行线性划分,我们可以对每段划分进行区分标记,这里选择了一个8bit的值进行标记。最终通过这个序号,我们就能得到对应的voltage大小段。

多维矢量量化
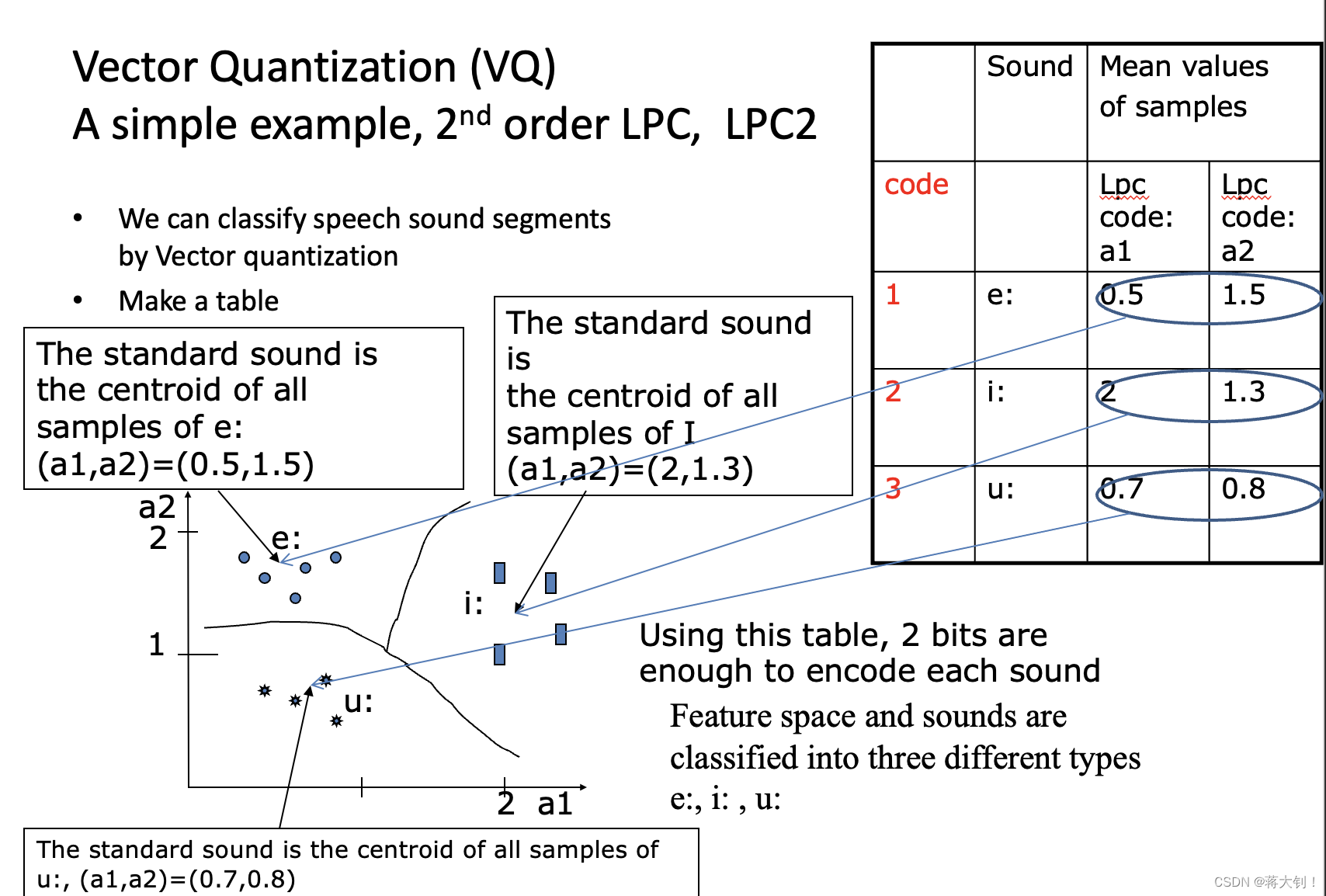
对于前面有两个未知数的线性预测表示法LPC2,如果我们有多种声音sound segments需要区分,对其进行矢量表示,相当于就是在一个二维空间里进行了二维划分,如下图所示。对三种声音e、i、u对应的LPC2进行划分,构建了一个码表(code table),通过码表中的code,我们就能得到对应声音的LPC coefficients,也就能重建其音帧的声波图。
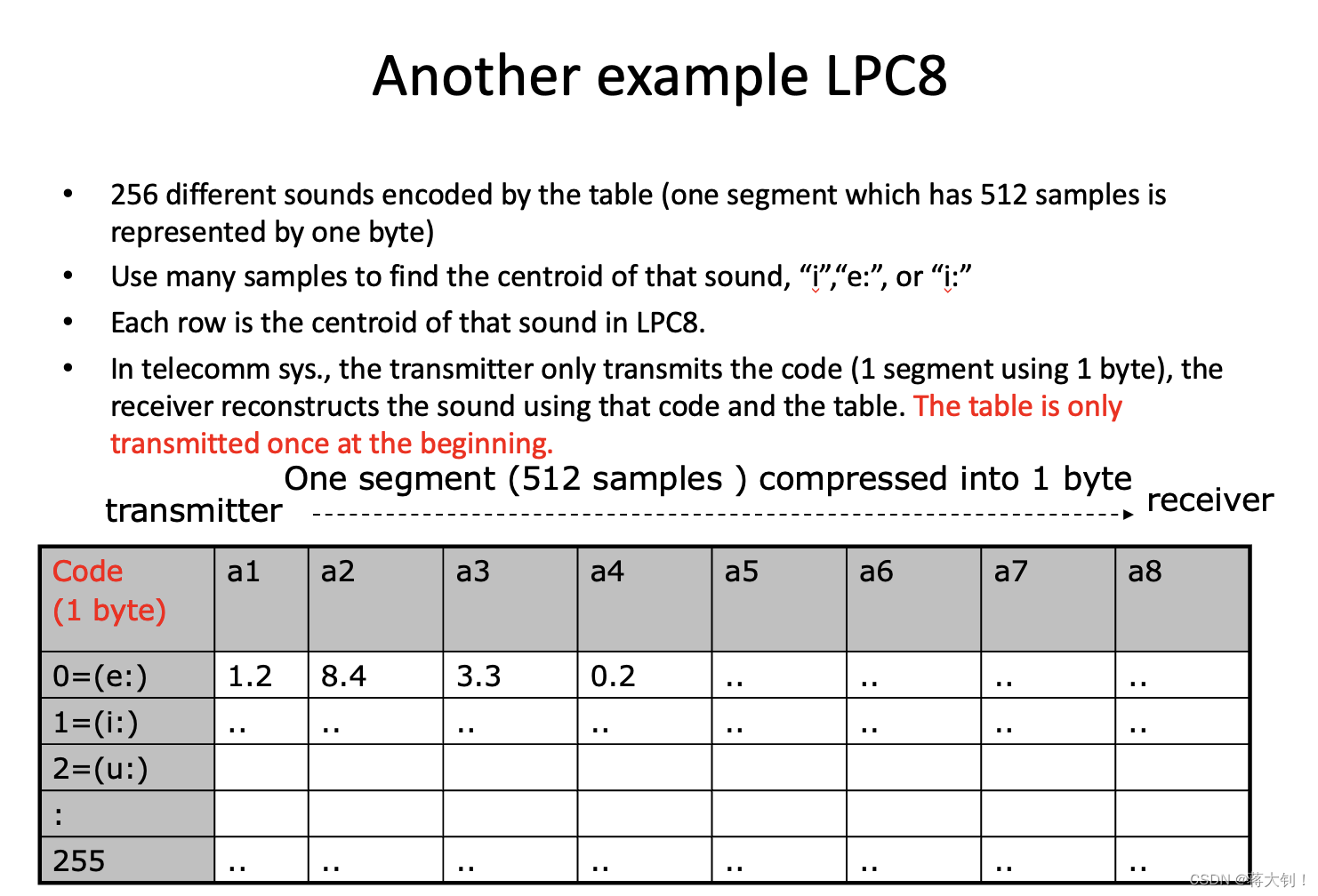
更进一步地,在一个LPC8的例子中,如下,有256种声音,一种声音sound采样了512个样本点,这512个采样点构成一个段segement,一个段可以用8个数字的coefficients进行重建,因此可以将8个coefficients当作一种声音的一段音帧。我们事先构建码表,并在开始前由传送方transmitter向接收方receiver传送一次,以后每次transmitter只需要传送1 byte的code,接收方就能够找到对应的LPC系数。
上面这个例子的矢量量化极大地压缩了传输数据,假设原来用8 bits描述每个采样点,原来传输512个样本需要512bytes数据量;如果变为传输LPC8系数,需要8个float,需要32bytes的数据量;进一步压缩,如果在之前传好code-book的前提下,每次只需要传送1byte的code,receiver就能找到对应的声音特征。
K-Means
在对状态空间进行矢量量化的时候,K-Means是一种很好的聚类方法,能将状态空间划分成相对独立的区域。
传统K-Means
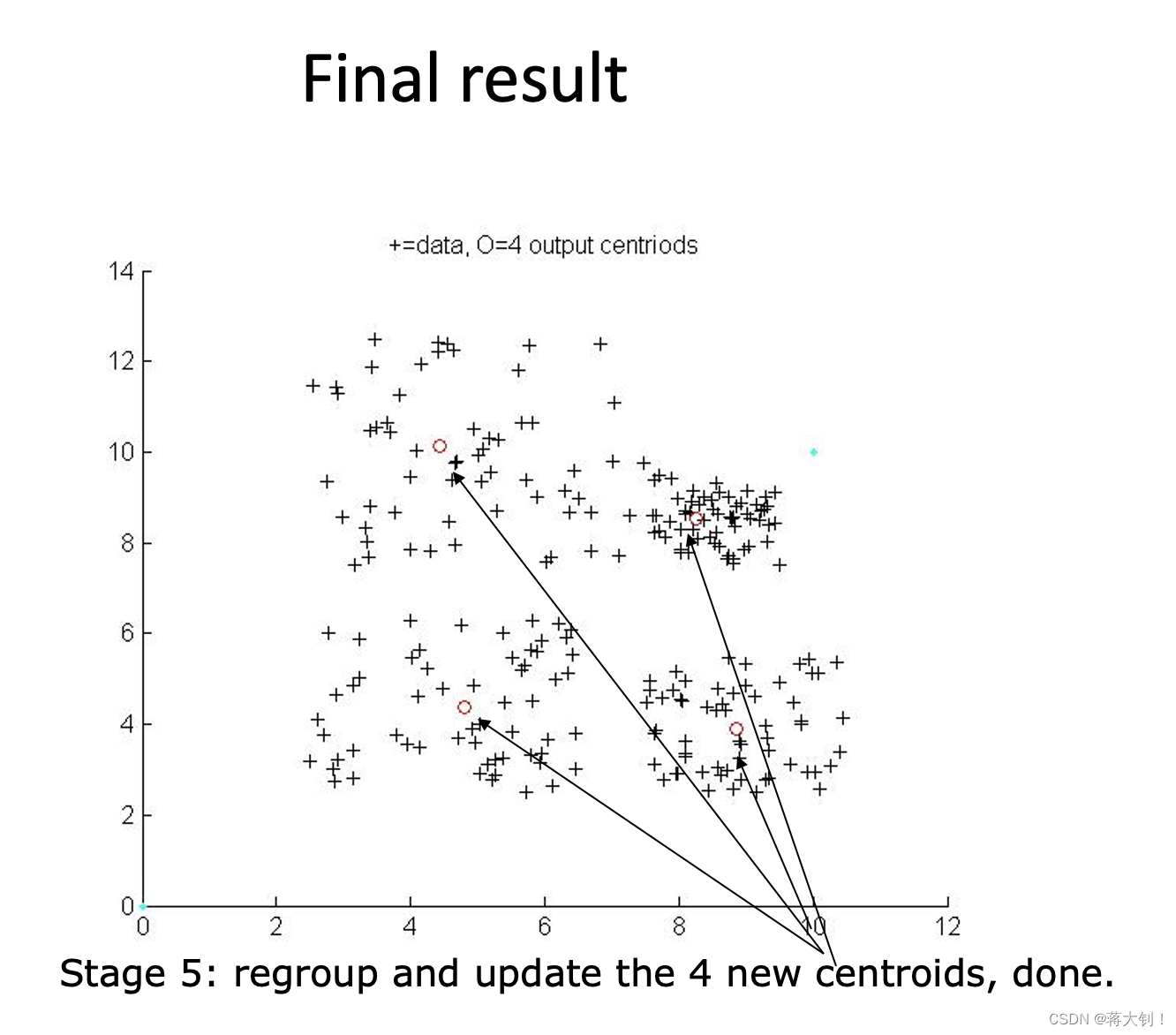
其基本步骤为:1.随取选取样本中心初始化簇,2. 将所有样本划分到对应的簇上,3.更新所有簇的新样本中心,4.重复以上过程直至中心变化小于某个阈值

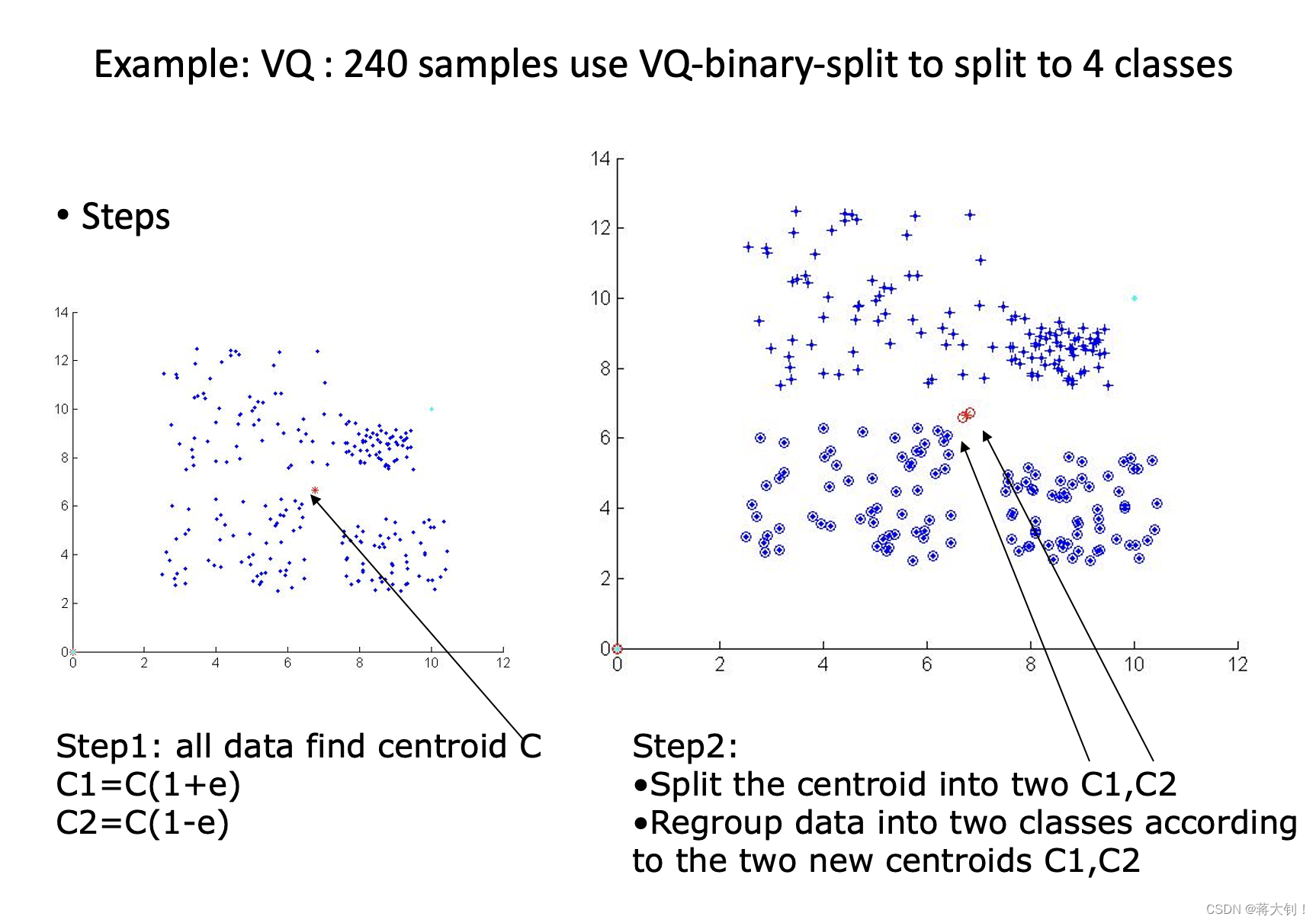
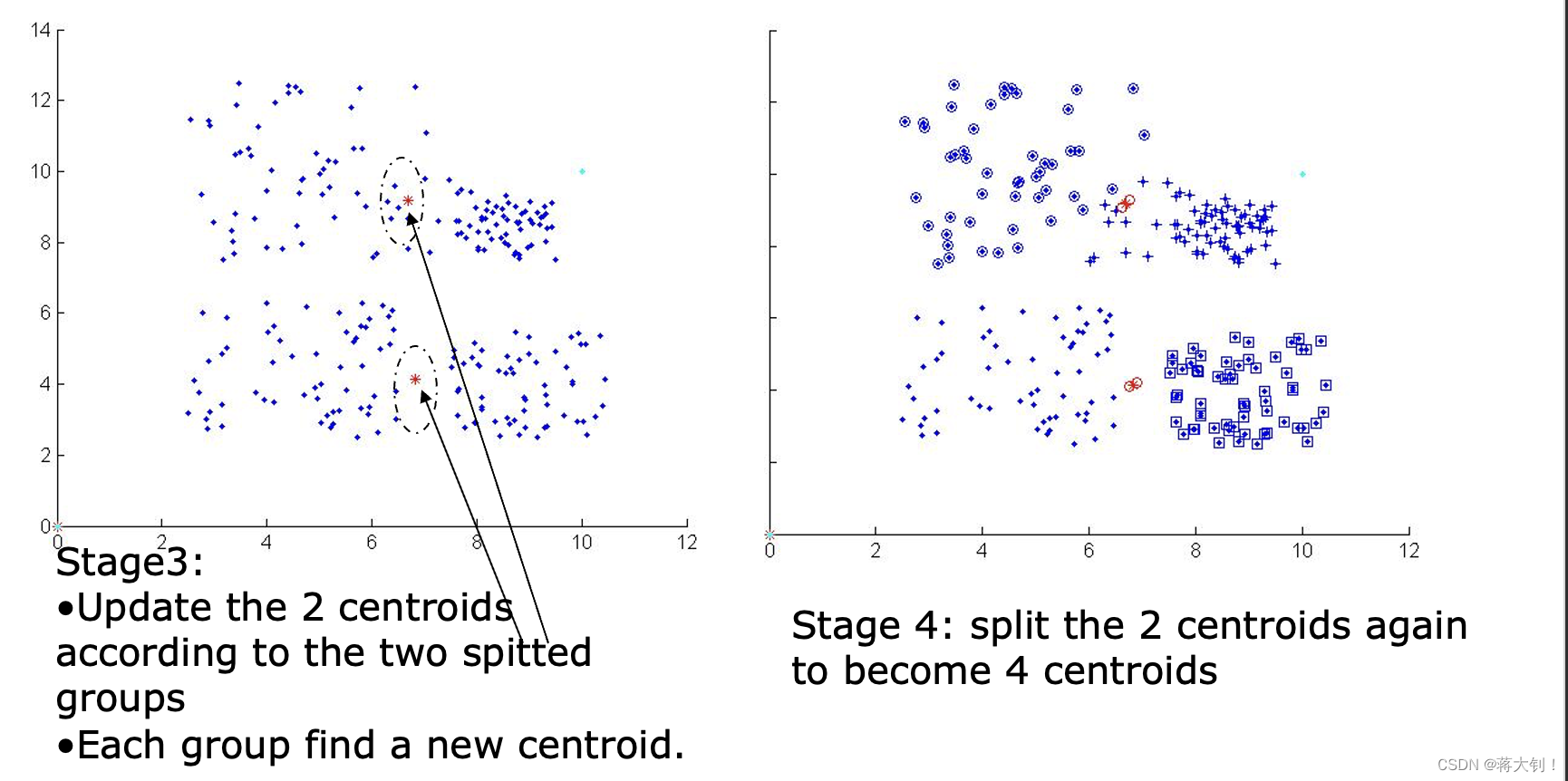
二分Binary split K-Means
二分K-Means算法步骤为:1.先找到一个中心点,这个点的坐标是所有点的平均值;2. 然后从这个点开始split划分出两个点,作为新簇的中心点,以这两个点为中心在进行一次K-means聚类分组,找到了2个新的中心点。3. 重复以上过程直到满足分簇数量。

习题1:


















 1794
1794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











