









Kaggle Bike Sharing Demand 报告
一、问题定义
该问题来源于kaggle,这是一个关于共享单车租赁预测的题目,通过对数据的预测,可以观测到共享单车在某个时间段的租赁数量,如果预测值和实际租赁值存在很大差异,就应该去调查情况,从而保证共享单车的正常运营。训练集提供了一个月的前19天的数据和使用情况,提供的数据集包括日期、季节、节假日、工作日、天气、实际温度、体感温度、湿度、注册人数、未注册人数、租赁数目。测试集提供后面20号以后的数据,我们主要的任务就是预测20号以后的使用量。
二、获取数据
Bike Sharing Demand中提供了两组数据:train.csv和test.csv,分别是训练集和测试集. sampleSubmission为提交样本示例。
打开kaggle对应项目的数据栏

下载数据

train.csv

test.csv

sampleSubmission.csv
导入包

导入train.csv和test.csv

显示两个数据文件的相关信息

训练数据

测试数据

预览训练集

查看数据分布状态,可以更好的对数据进行分析,注意下面的mean均值,方差std

了解数据特征含义
| 特征 | 含义 |
|---|---|
| season | 1=春 2=夏 3=秋 4=冬 |
| holiday | 1=节假日 0=非节假日 |
| workingday | 1=工作日 0=周末 |
| weather | 1=晴天多云 2=雾天阴天 3=小雪小雨 4=大雨大雪大雾 |
| temp | 气温摄氏度 |
| atemp | 体感温度 |
| humidity | 湿度 |
| windspeed | 风速 |
| casual | 非注册用户个数 |
| registered | 注册用户个数 |
| count | 给定日期时间(每小时)总租车人数 |
三、研究数据
1、了解数据基本情况,
经过观察我们可知,数据集是完整的,没有缺失信息,测试集数据比训练集数据少了三列:count、registered、casual,count是后面要预测的数据。在train.info()中可以看出,用车量count是casual 和registered 的总和,所以之后可以删除casual和registered这两个没有用的信息。
在datatime中提取出月份、日期、时间、星期,将季节、天气、工作日、月份转换成对应的字符串,便于后面的可视化分析

预览一下处理之后的训练集

1.查看数据类型和缺失信息

可以看到训练数据共12列,没有数据缺失,测试数据共9列,也没有数据缺失。test数据比train数据少了三列:count、registered、casual,count是后面要预测的数据。
2.信息提取与处理
在datetime中可以提取出月份、日期、时间、星期

3.可视化分析
①不同时间段对使用量的影响

由上图可见,在一天中不同时间段,共享单车使用量差异明显,在8点和16-19点明显多于其他时间点,考虑到的原因是在这期间是上下班的高峰期;在0-5点明显低于其他时间点,考虑到的原因是在此期间为睡眠时间。
②不同月份对使用量的影响

由上图可知,11月-4月的共享单车使用量会比其他月份少一点,可能是季节原因,冬季和春季太冷导致使用量降低。所以接下来我们观察一下季节对使用量的影响进行验证。
③不同季节对使用量的影响

可以看到冬春相对夏秋使用量相对较少,与上面月份产生的结论相互印证。
④不同天气对使用量的影响

天气对单车的影响基本符合日常生活中的实际情况,下雨天单车使用量减少,下暴雨时基本没人使用共享单车。
⑤星期对使用量的影响

由上图可知星期对单车总使用量没有太大的影响。
⑥是否工作日对使用量的影响

由上图可知是否工作日对单车总使用量基本没有太大的影响。
⑦季节对不同时段单车使用量趋势的影响

由上图可以看出,对于一天中不同时段,共享单车的使用量出现了明显的趋势,出现了两个明显的高峰,对应于上下班高峰期,符合人们对早高峰和晚高峰的认识;四个季节的趋势一致,只是春季使用量相比其他三个季节较少一点。
⑧星期对不同时段单车使用量趋势的影响

由上图可知,周一到周五两个高峰使用时段明显,使用量趋势相近,而在周末,使用量的趋势与工作日完全不同,由双峰型变成了平缓的单峰型,使用高峰时段集中在11-17点。
⑨注册用户与非注册用户对单车使用量趋势的影响

由上图可以得知注册用户的使用量占据了单车总使用量的绝大多数,并且趋势与总使用量趋势一致,而非注册用户,一天中不同时段的使用量没有太大变化,这说明使用量主要注册用户决定,注册用户更有粘性。
⑩温度和体感温度对单车使用量的影响
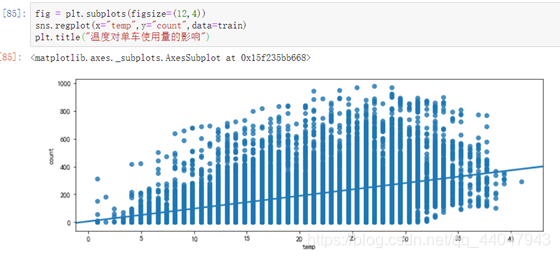
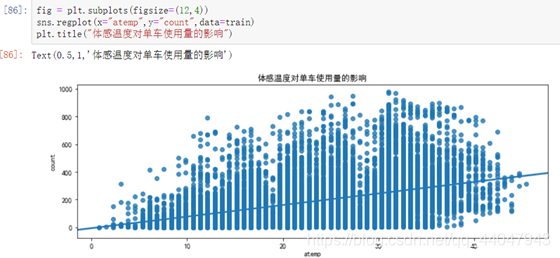
温度与体感温度对单车使用量的影响是一致的,当体感温度大于10度时,温度变化对单车使用量的影响不大;当体感温度低于10度时,单车使用量有明显减少。
⑪湿度对单车使用量的影响

整体来看,湿度对单车使用量的影响不是很大,湿度高于90%时使用量有所减少,可能因为湿度达到90%的时候已经是下雨的天气了。
⑫风速对单车使用量的影响

整体来看,风速对单车使用量也没有太大影响,风速接近40及以上的情况下,单车使用量减少,而风速超过50的数据点也比较少,风速为0的时候,使用量偏高可能是由于null填充导致的。
⑬各个特征之间的相关系数

由图可知和使用量最相关的特征是用户是否注册,可以看到湿度和使用量成负相关,温度和使用量正相关,同时使用量貌似和风速无关,相关系数很小,只有0.1;温度和体感温度相关性很高,达到0.98。
四、准备数据
- 因为前面对训练数据进行了信息提取等处理,这里对预测数据进行同样的操作:

- 将训练数据中的标签拿出来

- 训练数据删掉没用的信息,保留其他所有特征

五、模型研究
- 评价标准是:均方根对数误差(Root Mean Squared Logarithmic Error)

-
可能的模型有如下16个:RandomForestRegressor,LGBMRegressor,Ridge,LinearRegression ,LogisticRegression,SVC,SVR, Lasso,ElasticNetCV,ExtraTreesRegressor,AdaBoostRegressor,KernelRidge,BayesianRidge,DecisionTreeRegressor,BaggingClassifier,KNeighborsClassifier,BaggingRegressor,KNeighborsRegressor,XGBRegressor,GradientBoostingRegressor,HistGradientBoostingClassifier。
-
分别测试了它们在训练集上的训练损失,测试集上的损失,测试集上的精确度。得到的数据和关键代码如下图所示。
| 模型 | train_loss | test_loss | accuracy | 结论 |
|---|---|---|---|---|
| RandomForestRegressor | 0.1502495818035963 | 0.3245243769644619 | 0.9443891454063094 | 正好 |
| LGBMRegressor | 0.4141670013430686 | 0.4223871364140003 | 0.9514839253691025 | 正好 |
| Ridge | 1.311414055518029 | 1.2701931290804094 | 0.392963851064691 | 欠拟合 |
| LinearRegression | 1.3114844027054773 | 1.2702532803160975 | 0.3929604125401881 | 欠拟合 |
| LogisticRegression | 2.711752674124804 | 2.704664686280972 | 0.01652892561983471 | 欠拟合 |
| SVC | 3.1289891937106553 | 3.1780241219879937 | 0.011937557392102846 | 欠拟合 |
| SVR | 1.476143470393201 | 1.4258388153580734 | 0.08664872013719416 | 欠拟合 |
| Lasso | 1.3032523765265092 | 1.2653444651661558 | 0.39317265905828447 | 欠拟合 |
| ElasticNetCV | 1.2635566403185872 | 1.2508898341010983 | 0.356013103753264 | 欠拟合 |
| ExtraTreesRegressor | 3.895923750427822e-07 | 0.3243198594168834 | 0.9482777012303725 | 正好 |
| AdaBoostRegressor | 0.9619847405409279 | 0.9254556644691063 | 0.6618837583053567 | 欠拟合 |
| KernelRidge | 1.279287333047933 | 1.2652489351779304 | 0.3391852372083133 | 欠拟合 |
| BayesianRidge | 1.3095766542950287 | 1.268255309579916 | 0.3930466225718855 | 欠拟合 |
| DecisionTreeRegressor | 0.0 | 0.41190891307682076 | 0.8902910300403369 | 过拟合 |
| BaggingClassifier | 0.06514070326976322 | 0.6427652019151783 | 0.018824609733700644 | 欠拟合 |
| KNeighborsClassifier | 1.3006639642808215 | 1.4143596381526977 | 0.010560146923783287 | 欠拟合 |
| BaggingRegressor | 0.16604755849708408 | 0.33067189060937674 | 0.9391717888905984 | 正好 |
| KNeighborsRegressor | 1.1184185237161755 | 1.1035461968653164 | 0.4837701852106041 | 欠拟合 |
| XGBRegressor | 0.38847587695686847 | 0.5030087981800025 | 0.9502832608691594 | 正好 |
| GradientBoostingRegressor | 0.7200261691586097 | 0.7140488878421117 | 0.8631403861942198 | 正好 |
| HistGradientBoostingClassifier | 3.237633443428011 | 3.2756771475356588 | 0.011937557392102846 | 欠拟合 |
| StackingRegressor | 0.19062172084845336 | 0.30854677270194264 | 0.9546884373722129 | 正好 |

以xgboost为例训练模型得到训练集测试极得RMSLE。

- 最终结合这三种数据(训练集和测试集上的损失值,, 测试集上的精度)我们最终选则了4种模型,分别是LGBMRegressor, ExtraTreesRegressor,BaggingRegressor,XGBRegressor。
六、模型融合
-
集成模型:将表现最好的模型组合起来
采用stacking将模型融合。关键代码如下:

-
融合之后的模型表现:
训练集:0.19062172084845336
测试集:0.30854677270194264
精确度:0.9546884373722129
可以看出融合之后的效果比任何一个单个模型都要好。
-
效果:
由于比赛已经停止了,我们不能提交我们的结果来观察在排行榜上的结果,但是我们是将训练数据集分割成训练集和测试集,测试集在测试之前没有干扰到训练过程,那么我们的测试分数就应该和最终测试分数是差不多一样的。所以我们的最终分数可以认为是0.30854,这样来看这个模型的表现还是非常好的。下面是这个比赛的Public Leaderboard 和 Private Leaderboard。
Public Leaderboard:

Private Leaderboard:


















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









