







目录
一、sramc(sram_controller)的总框架和模块划分
一、sramc(sram_controller)的总框架和模块划分
sram因为其高读写速度常常作为CPU和嵌入式IC的缓存,是一个数字系统中必不可少的存在,因此能够支持各种总线协议的sram控制器也是必不可少的。本系列文章将完成一个支持AHB总线协议的sram控制器的Verilog实现,并对Verilog代码进行详细分析。本篇文章主要完成了sramc的一个子模块——sram_core的Verilog实现。
Features of sramc
思路清晰,先说功能:
- 能按照AHB协议的读写时序进行数据传输;
- 能够实现流水线形式的单周期读写;
- 支持8、16、32位数据传输;
- 对于一次传输中用不到的sram块,不对其使能;
结构框图和信号描述
将sramc划分为两个子模块:ahb_sramc_if和sram_core。ahb_sramc_if是sram与AHB总线的接口,负责根据协议时序为sram_core提供使能读写控制信号,并对总线地址haddr进行处理提供给sram_core;sram_core负责管理各sram bank的使能信号,并处理写入数据和读出数据。
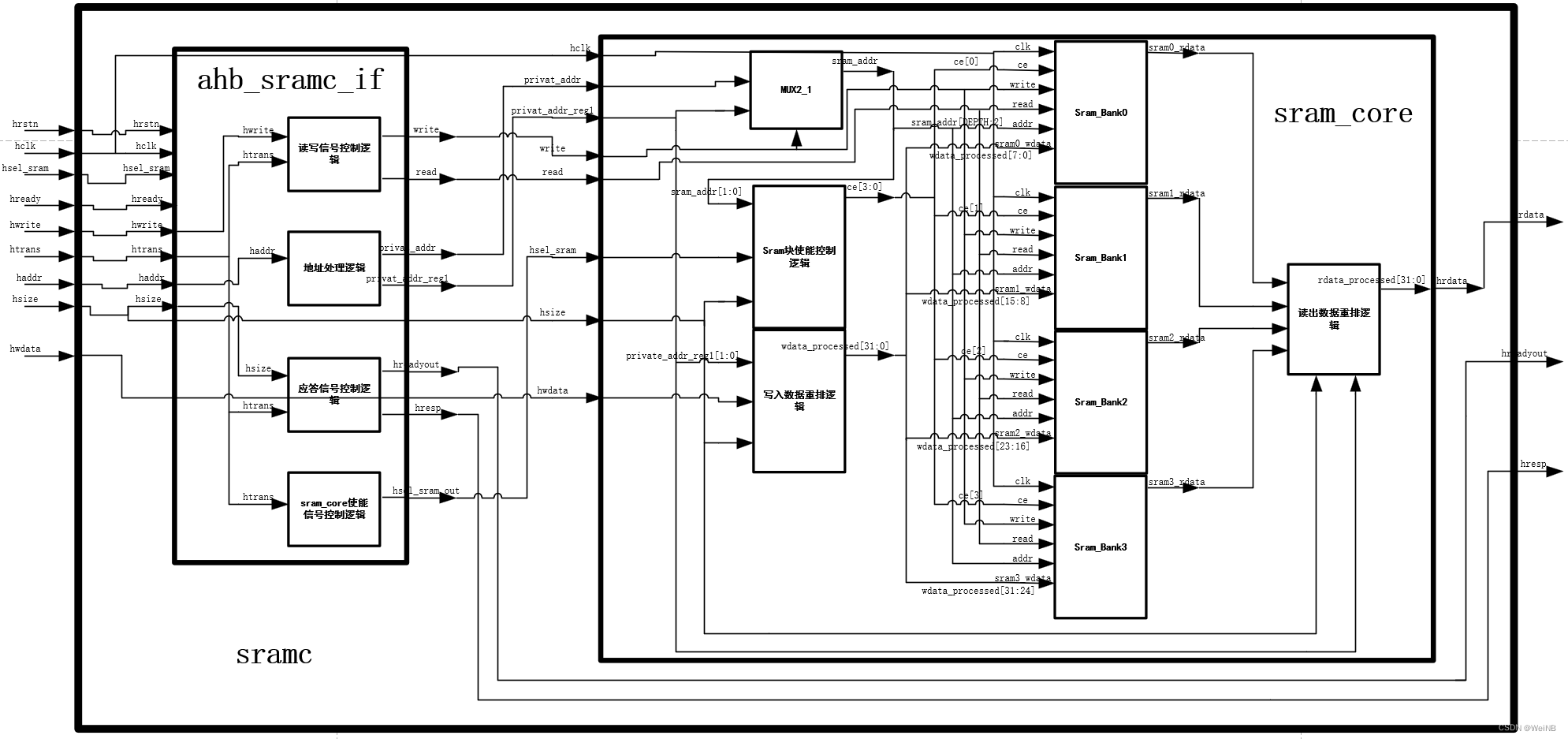
| signal | I/O | width | descriptions |
| hrstn | input | 1 | 总线复位信号,同步复位,低有效 |
| hclk | input | 1 | 总线时钟 |
| hsel_sram | input | 1 | sramc选中信号 |
| hready | input | 1 | 总线可用信号,从机只能在hready为1时从总线采样 |
| hwrite | input | 1 | 读写控制信号1写0读 |
| htrans | input | 2 | 传输类型,详见AHB协议 |
| hsize | input | 3 | 传输位宽,详见AHB协议 |
| haddr | input | AHB_ADDR_WIDTH | 总线地址 |
| hwdata | input | AHB_DATA_WIDTH | 总线写数据 |
| hreadyout | output | 1 | 从机传输是否完成 |
| hresp | output | 1 | 从机传输状态应答信号 |
| hrdata | output | AHB_DATA_WIDTH | 读数据 |
二、sram_core的Verilog实现
首先要进一步细化sram_core要实现的功能:
- 支持8、16、32位的数据传输;
- 对于一次传输中用不到的sram块,不对其使能;
- 对sramc的私有地址(private_addr)进行处理,确保每个sram bank收到的地址是sram bank中与private_addr对应的地址;
- 对要写入的数据进行位重排列,确保正确的数据写入正确的sram bank里;
- 对读出的数据进行位排列,确保从相应sram bank读出的数据位于输出hrdata的正确位上
乍一看可能会懵,不知道这些功能具体指什么。但听我说,先别急,后面我会尽可能的展开说明。
动手开敲前的构思
首先最多要支持32位的数据传输,并且要支持单周期传输 ,而sram一般是8位的,这就决定了sram_core最少要包含4个sram bank。出于设计难度的考虑,本设计决定使用了4个sram bank,但如果sram比较大,则需增加bank数,使得每个sram bank的大小不超过一定水平。
既然要使用多个sram bank,那就不得不考虑怎样对每个sram bank进行地址分配。同样由于最多要支持32位传输,所以会出现4个bank同时工作的情况,这就决定了只能按照这样的方式分配地址:private_addr 0是sram bank0的地址0,private_addr 1是sram bank1的地址0,private_addr 2是sram bank2的地址0,private_addr 3是sram bank3的地址0,private_addr 4是sram bank0的地址1,private_addr 5是sram bank1的地址1......以此类推。
既然要进行地址分配,那就不得不对private_addr进行处理,确保每个sram bank收到的地址是sram bank中按照上述地址分配方式与private_addr对应的地址。所以要有一个地址处理逻辑块。
由于要使用多个sram bank且要按照上述方式进行地址分配,所以不能将hwdata按照从高到低位直接接入到各sram bank=中,对于hrdata同样如此。考虑下这种情况:总线上传来了对地址2的16位的读请求,sram_core给出的正确数据应该是{16’h0,sram3, sram2},但如果将各sram bank的读出数据直接按照位从高到低接到hrdata上,那么sram_core给出的数据将会是{sram3,sram2,sram1,sram0}。所以要有写数据位重排逻辑和读数据位排列逻辑来处理hwdata和从各sram bank中读出的数据。
另外对于一次传输中用不到的sram块,不对其使能,所以还要有一个sram块使能控制逻辑。
经过以上构思可大致确定sram_core的框架,其框图和信号描述如下所示:
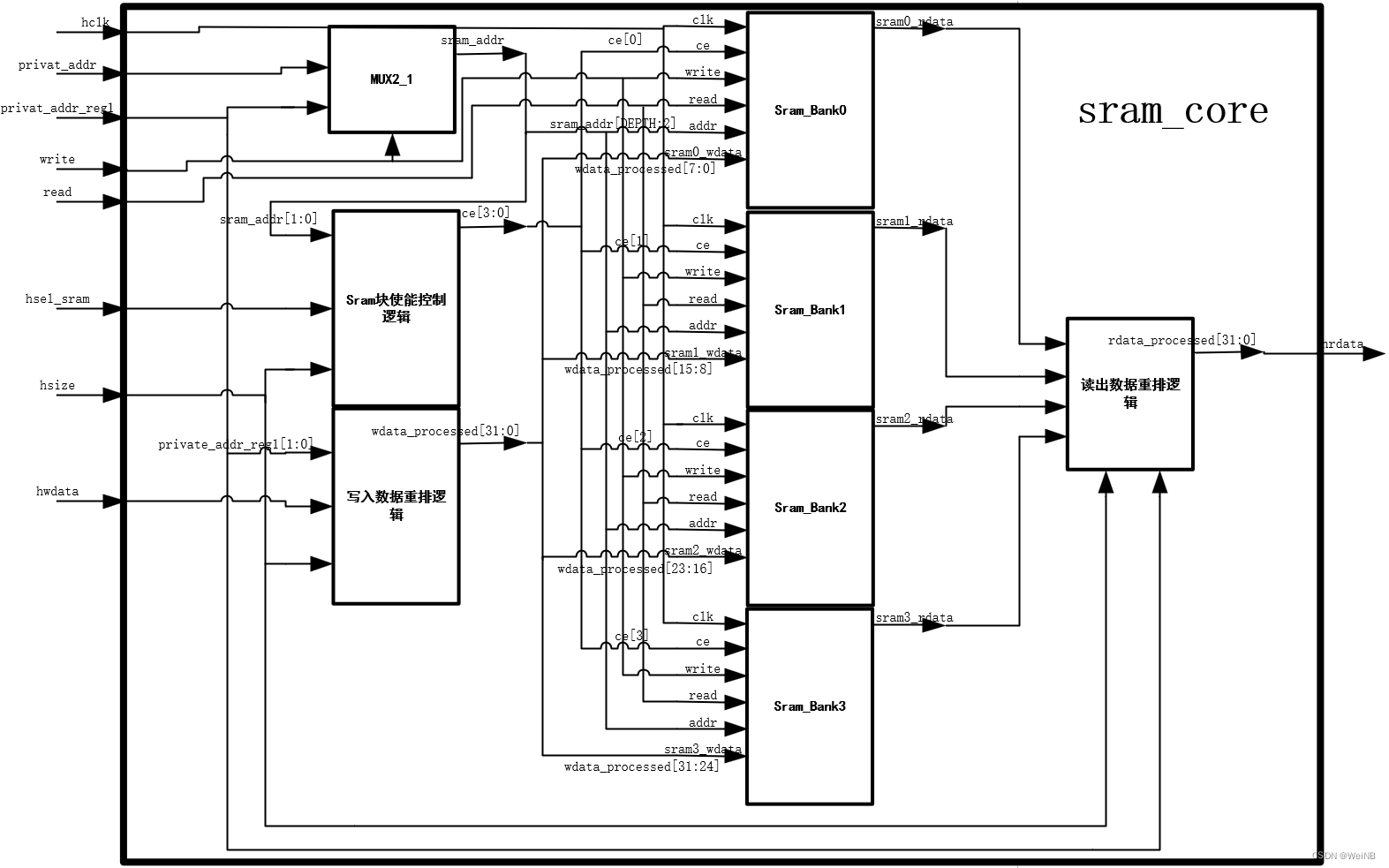
| signal | I/O | width | descriptions |
| hclk | input | 1 | 总线时钟 |
| hsel_sram | input | 1 | sram_core使能信号 |
| write | input | 1 | 写控制信号,1有效 |
| read | input | 1 | 读控制信号,1有效 |
| hsize | input | 3 | 传输位宽,详见AHB协议 |
| private_addr | input | PRIVATE_ADDR_WIDTH | sramc私有地址 |
| private_addr_reg1 | input | PRIVATE_ADDR_WIDTH | 寄存一拍的private_addr |
| hwdata | input | AHB_DATA_WIDTH | 总线写数据 |
| hrdata | output | AHB_DATA_WIDTH | 读数据 |
Verilog代码和代码分析
由于我搞不定Memory compiler所以我就自己写了个sram,对于Verilog行为级设计也够用了,虽然有write和read端,但是个单端口sram,不能同时读写。先附上sram.v:
`timescale 1 ns/1 ns
module sram
#(parameter SRAM_ADDR_WIDTH = 6)
(
clk,
ce,
write,
read,
addr,
wrdata,
rddata
);
localparam SRAM_DEPTH = 1 << SRAM_ADDR_WIDTH;
input clk;
input ce;
input write;
input read;
input[SRAM_ADDR_WIDTH-1:0] addr;
input[7:0] wrdata;
output reg[7:0] rddata;
reg[7:0] mem[0:SRAM_DEPTH-1];
always@(posedge clk) begin //写
if(ce&&write)
mem[addr] = wrdata;
end
always@(posedge clk) begin //读
if(ce&&read)
rddata = mem[addr];
end
endmodulesram_core.v如下所示:
`timescale 1 ns/1 ns
module sram_core
#(parameter AHB_ADDR_WIDTH = 32, AHB_DATA_WIDTH = 32, BANK_NUM = 4, SRAM_ADDR_WIDTH = 6)
(
clk,
hsel_sram,
write,
read,
hsize,
private_addr,
private_addr_reg1,
hwdata,
hrdata
);
input clk;
input hsel_sram;
input write;
input read;
input[2:0] hsize;
input[AHB_ADDR_WIDTH-1:0] private_addr;
input[AHB_ADDR_WIDTH-1:0] private_addr_reg1;//对于写操作,写入是在地址周期的下一周期发生,另外读出的数据需要维持一个周期,所以地址要寄存一拍
input[AHB_DATA_WIDTH-1:0] hwdata;
output[AHB_DATA_WIDTH-1:0] hrdata;
wire[AHB_ADDR_WIDTH-1:0] sram_addr;
reg[BANK_NUM-1:0] ce; //各SRAM BANK的使能信号
wire[AHB_DATA_WIDTH-1:0] rddata_raw; //直接从各SRAM BANK中出来的读数据,其位顺序需要经过处理
reg[AHB_DATA_WIDTH-1:0] wrdata_processed; //由hwdata经过处理得到,可直接按照从高到低位写入各BANK
reg[AHB_DATA_WIDTH-1:0] rddata_processed; //由rddata_raw处理得到,直接作为输出读数据
assign hrdata = rddata_processed;
assign sram_addr = write ? private_addr_reg1 : private_addr;
/********************各BANK使能控制逻辑*******************/
always@(*) begin
if(!hsel_sram)
ce = 0;
else begin
case(hsize)
3'b000: begin //如果传输位宽是8位,一次只使能一个BANK
case(sram_addr[1:0])
2'b00: ce = 4'b0001;
2'b01: ce = 4'b0010;
2'b10: ce = 4'b0100;
2'b11: ce = 4'b1000;
endcase
end
3'b001: begin //如果传输位宽是16位,一次使能2个BANK
case(sram_addr[1:0])
2'b00: ce = 4'b0011;
2'b10: ce = 4'b1100;
default: ce = 4'b0000;
endcase
end
3'b010: ce = 4'b1111;//如果传输位宽是32位,一次使能4个BANK
default: ce = 4'b0000;
endcase
end
end
/********************写入数据和从各SRAM BANK读出的数据位重排列组合逻辑*******************/
always@(*) begin
if(hsel_sram) begin
case(hsize)
3'b000: begin
case(private_addr_reg1[1:0])//对于写操作,写入是在地址周期的下一周期发生,另外读出的数据需要维持一个周期,所以地址要寄存一拍
2'b00: begin
if(write)
wrdata_processed[7:0] = hwdata[7:0];
if(read)
rddata_processed = {24'd0 ,rddata_raw[7:0]};
end
2'b01: begin
if(write)
wrdata_processed[15:8] = hwdata[7:0];
if(read)
rddata_processed = {24'd0, rddata_raw[15:8]};
end
2'b10: begin
if(write)
wrdata_processed[23:16] = hwdata[7:0];
if(read)
rddata_processed = {24'd0, rddata_raw[23:16]};
end
2'b11: begin
if(write)
wrdata_processed[31:24] = hwdata[7:0];
if(read)
rddata_processed = {24'd0, rddata_raw[31:24]};
end
endcase
end
3'b001: begin
case(private_addr_reg1[1:0])
2'b00: begin
if(write)
wrdata_processed[15:0] = hwdata[15:0];
if(read)
rddata_processed = {16'd0, rddata_raw[15:0]};
end
2'b10: begin
if(write)
wrdata_processed[31:16] = hwdata[15:0];
if(read)
rddata_processed = {16'd0, rddata_raw[31:16]};
end
endcase
end
3'b010: begin
if(write)
wrdata_processed = hwdata;
if(read)
rddata_processed = rddata_raw;
end
endcase
end
end
genvar i;
generate
for(i=0; i<BANK_NUM; i=i+1) begin: sram_instance
sram #(.SRAM_ADDR_WIDTH(SRAM_ADDR_WIDTH))
sram(
.clk(clk),
.ce(ce[i]),
.write(write),
.read(read),
.addr(sram_addr[SRAM_ADDR_WIDTH+1:2]),
//总共有4个BANK,且必须要采用开头描述的地址分配,另外ahb协议有硬性要求,
//传输地址必须与位宽对齐,所以总地址的去掉最低2位就可直接作为各BANK的地址
.wrdata(wrdata_processed[8*i+7:8*i]),
.rddata(rddata_raw[8*i+7:8*i])
);
end
endgenerate
endmodulesram.v就是一个很基础的memory,没啥好说的,直接来看sram_core。
input[AHB_ADDR_WIDTH-1:0] private_addr;
input[AHB_ADDR_WIDTH-1:0] private_addr_reg1;先说这两个地址信号,了解过微机原理都知道,一个单片机是需要对其上挂载的所有从机分配地址的,大部分情况下总线地址是不能直接用的,需要转化为从机的私有地址,private_addr就是sramc的私有地址,private_addr寄存一拍得到private_addr_reg1。这些工作决定交给ahb_sramc_if来做。
assign sram_addr = write ? private_addr_reg1 : private_addr; sram_addr是直接传给sram bank的地址,为什么写操作要用寄存一拍的地址呢?上时序图:

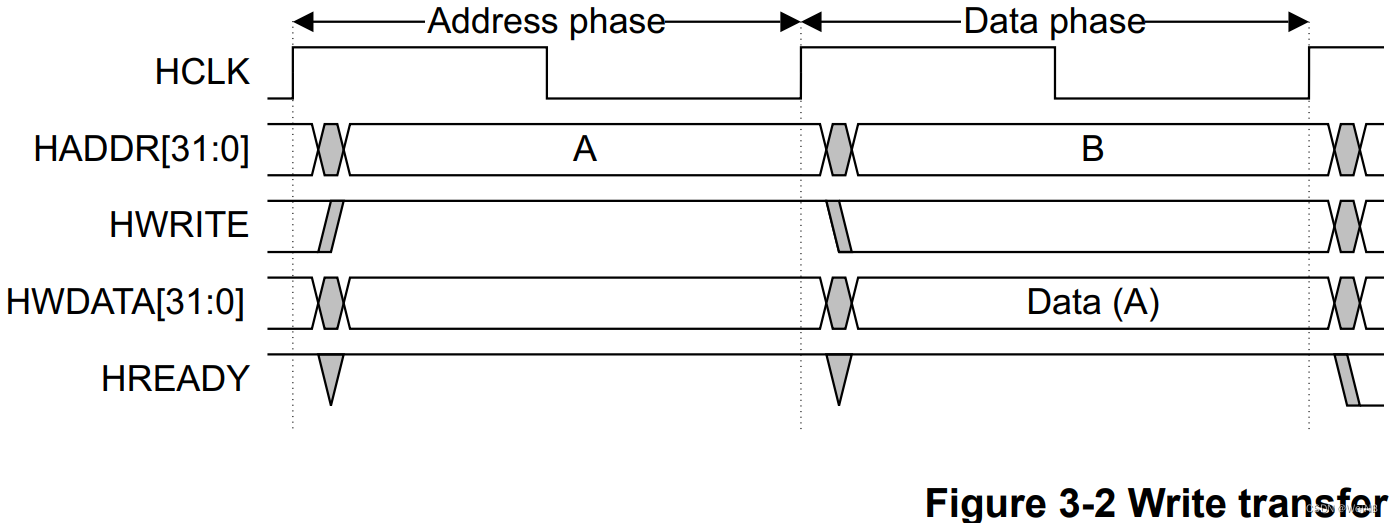
上图是ahb协议的基础的读写时序,可以看出ahb协议的数据传输是有两个阶段的:第一个地址周期要提供有效的控制和地址信号,第二个数据周期要进行数据采样。对于读操作,从机采样到数据和控制信号后就要立即开始给出并维持住数据,直到下一个上升沿总线采样完成,所以读操作直接用当前地址即可。而对于写操作,写入数据在从机采样地址的下一个周期才提供,写入操作真正发生在图中的第三个上升沿,而由于流水线工作方式,总线地址已经发生改变,所以写操作要用寄存一拍的地址。
/********************各BANK使能控制逻辑*******************/
always@(*) begin
if(!hsel_sram)
ce = 0;
else begin
case(hsize)
3'b000: begin //如果传输位宽是8位,一次只使能一个BANK
case(sram_addr[1:0])
2'b00: ce = 4'b0001;
2'b01: ce = 4'b0010;
2'b10: ce = 4'b0100;
2'b11: ce = 4'b1000;
endcase
end
3'b001: begin //如果传输位宽是16位,一次使能2个BANK
case(sram_addr[1:0])
2'b00: ce = 4'b0011;
2'b10: ce = 4'b1100;
default: ce = 4'b0000;
endcase
end
3'b010: ce = 4'b1111;//如果传输位宽是32位,一次使能4个BANK
default: ce = 4'b0000;
endcase
end
end
接下来是各sram bank的使能控制逻辑,实现这个功能的思路简单直白,就是根据地址和传输位宽使能对应的sram bank,没什么好说的。注意这里只使用了sram_addr[1:0],因为只用了4个bank,所以只需地址的最低两位就足以判断此次传输要用到那些bank。
现在考虑一下这种情况:总线发起了一个对地址3的16位的传输请求。看一下我们的使能控制逻辑,发现在这种情况下竟然是所有sram bank都不使能,这岂不是一个大BUG?听我说,先别急,ahb协议里有这样一句话:

意思就是传输地址必须要与传输位宽对齐,比如说16位传输的传输地址的最低位必须是0。所以说上述情况是不应该出现的,如果出现的话应当视作错误来处理,这个任务应该交给ahb_sramc_if来处理。大家可以思考一下为什么ahb协议要这样规定。我在敲代码时的感受就是这个规定最起码简化了设计。
/********************写入数据和从各SRAM BANK读出的数据位重排列组合逻辑*******************/
always@(*) begin
if(hsel_sram) begin
case(hsize)
3'b000: begin
case(private_addr_reg1[1:0])//对于写操作,写入是在地址周期的下一周期发生,另外读出的数据需要维持一个周期,所以地址要寄存一拍
2'b00: begin
if(write)
wrdata_processed[7:0] = hwdata[7:0];
if(read)
rddata_processed = {24'd0 ,rddata_raw[7:0]};
end
2'b01: begin
if(write)
wrdata_processed[15:8] = hwdata[7:0];
if(read)
rddata_processed = {24'd0, rddata_raw[15:8]};
end
2'b10: begin
if(write)
wrdata_processed[23:16] = hwdata[7:0];
if(read)
rddata_processed = {24'd0, rddata_raw[23:16]};
end
2'b11: begin
if(write)
wrdata_processed[31:24] = hwdata[7:0];
if(read)
rddata_processed = {24'd0, rddata_raw[31:24]};
end
endcase
end
3'b001: begin
case(private_addr_reg1[1:0])
2'b00: begin
if(write)
wrdata_processed[15:0] = hwdata[15:0];
if(read)
rddata_processed = {16'd0, rddata_raw[15:0]};
end
2'b10: begin
if(write)
wrdata_processed[31:16] = hwdata[15:0];
if(read)
rddata_processed = {16'd0, rddata_raw[31:16]};
end
endcase
end
3'b010: begin
if(write)
wrdata_processed = hwdata;
if(read)
rddata_processed = rddata_raw;
end
endcase
end
end
接下来是写入数据和读出数据处理逻辑,看着很长一段,但其实同样简单直白,就是根据地址和传输位宽将对应数据放到对应位置上。需要注意的是,这里直接就使用了寄存一拍的地址private_addr_reg1而不是sram_addr,对于写操作这样处理可以理解,为什么读操作也要这样呢?还记得前面在分析ahb读写时序时说过:读数据要维持到总线数据采样结束。如果在这里使用sram_addr我们看看会发生什么:

可以看到,本应该维持一个周期的正确hrdata竟然变成了一闪而过的毛刺,观察此时的private_addr可找到原因:在110时刻的上升沿地址是0,数据处理逻辑按照地址0来处理数据,但由于流水线机制,这个上升沿之后地址变成了1,而数据处理逻辑是个组合逻辑,会马上按照地址1处理数据,所以地址0的hrdata就会一闪而过。使用private_addr_reg1就能避免这种情况。
genvar i;
generate
for(i=0; i<BANK_NUM; i=i+1) begin: sram_instance
sram #(.SRAM_ADDR_WIDTH(SRAM_ADDR_WIDTH))
sram(
.clk(clk),
.ce(ce[i]),
.write(write),
.read(read),
.addr(sram_addr[SRAM_ADDR_WIDTH+1:2]),
//总共有4个BANK,且必须要采用开头描述的地址分配,另外ahb协议有硬性要求,
//传输地址必须与位宽对齐,所以总地址的去掉最低2位就可直接作为各BANK的地址
.wrdata(wrdata_processed[8*i+7:8*i]),
.rddata(rddata_raw[8*i+7:8*i])
);
end
endgenerate最后是sram的例化,此处还有一点要说明:注意传给sram的addr是sram_addr去掉了最低两位。还记得我们采用的地址分配方式吗,因为有4个bank,所以每个sram bank中与私有地址对应的地址就是sram_addr1掉最低两位。
三、sram_core的仿真验证
先附上仿真代码:
`timescale 1 ns/1 ns
module sram_core_test();
parameter ADDR_WIDTH = 32, DATA_WIDTH = 32;
reg clk, hsel_sram, write, read;
reg[2:0] hsize;
reg[ADDR_WIDTH-1:0] private_addr;
reg[ADDR_WIDTH-1:0] private_addr_reg1;
reg[DATA_WIDTH-1:0] hwdata;
wire[DATA_WIDTH-1:0] hrdata;
integer i;
sram_core sram_core1 (
.clk(clk),
.hsel_sram(hsel_sram),
.write(write),
.read(read),
.hsize(hsize),
.private_addr(private_addr),
.private_addr_reg1(private_addr_reg1),
.hwdata(hwdata),
.hrdata(hrdata)
);
always #5 clk = ~clk;
always@(posedge clk)
private_addr_reg1 <= private_addr;
initial begin
clk=1; write=1; read=0; hsel_sram=1; hsize=3'd0;
#11 write=1; read=0; hsel_sram=1; hsize=0;
private_addr=32'h0000_0000; hwdata=32'h0000_0000;
for(i=0; i<8; i=i+1) begin: write_8bytes_0
#10 private_addr = private_addr + 1; hwdata = hwdata + 1;
end
#10 write=0; read=1; hsel_sram=1; hsize=3'd0;
private_addr=32'h0000_0000;
for(i=0; i<8; i=i+1) begin: read_8bytes
#10 private_addr = private_addr + 1;
end
#10 write=1; read=0; hsel_sram=1; hsize=3'd1;
private_addr=32'd0000_0000; hwdata=32'h0000_ffff;
for(i=0; i<4; i=i+1) begin: write_4halfwords_1
#10 private_addr = private_addr + 2; hwdata = hwdata + 1;
end
#10 write=0; read=1; hsel_sram=1; hsize=3'd1;
private_addr=32'h0000_0000;
for(i=0; i<4; i=i+1) begin: read_4halfwords
#10 private_addr = private_addr + 2;
end
#10 write=1; read=0; hsel_sram=1; hsize=3'd2;
private_addr=32'h0000_0000; hwdata=32'h0000_0000;
for(i=0; i<2; i=i+1) begin: write_2words_0
#10 private_addr = private_addr + 4; hwdata = hwdata + 1;
end
#10 write=0; read=1; hsel_sram=1; hsize=3'd2;
private_addr=32'h0000_0000;
for(i=0; i<2; i=i+1) begin: read_2words
#10 private_addr = private_addr + 4;
end
#100 $finish;
end
initial begin
$fsdbDumpfile("sramc_test.fsdb");
$fsdbDumpvars(0);
end
endmodule仿真代码就是地址从0开始,先依次进行8个8位的写操作,然后再依次进行8个8位的读操作,接着是16位先写后读,最后是32位的先写后读。这一个验证肯定不够,我其实做了很多仿真,但没有保存仿真代码,另外我没深入学习过验证,仿真代码不成体系,可以看到我连个task都没写,所以就不班门弄斧的讲仿真代码了。

这是仿真结果,你们看起来可能会迷,但我很清楚是没问题的。
下载链接
最后附上代码和ahb协议手册下载链接,在设计基于ahb协议的模块时,一定要先仔细看协议手册














 2560
2560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









