







什么是hook函数
在计算机编程中,hook函数是指在特定的事件发生时被调用的函数,用于在事件发生前或后进行一些特定的操作。通常,hook函数作为回调函数被注册到事件处理器中,当事件发生时,事件处理器会自动调用相应的hook函数。
hook函数通常用于实现程序的扩展性和可定制性,允许用户在程序运行时添加自定义的操作或修改程序的行为。在很多框架和库中,hook函数被广泛应用于实现特定的功能和操作,例如在深度学习框架中,hook函数可以用于记录指标、可视化网络结构、保存模型和优化器状态等。
一些常见的hook函数包括:
pre-hook:在函数或方法执行前被调用,用于修改或拦截函数的输入参数或返回值。post-hook:在函数或方法执行后被调用,用于修改或拦截函数的返回值。exception-hook:在函数或方法抛出异常时被调用,用于处理或记录异常信息。event-hook:在特定事件发生时被调用,例如程序启动、程序结束、网络连接、文件读写等。
总的来说,hook函数是一种非常有用的编程技术,可以增强程序的灵活性和可扩展性,同时也可以帮助程序员更好地理解程序的运行行为和调试程序的错误。
mmlab中hook函数
OpenMMLab 中的 Hook 机制其实是面向切面编程 (Aspect Oriented Program, AOP) 编程思想的一种体现。
在mmlab中,hook函数是指在模型训练过程中插入的一些回调函数,用于在训练过程中进行一些特定的操作,例如记录和可视化训练指标、保存模型和优化器状态等。hook函数可以通过继承mmcv.runner.Hook类来实现。
以下是一些常见的hook函数:
CheckpointHook:用于保存模型和优化器状态,以便在训练过程中进行断点续训。可以使用CheckpointHook来定期保存模型和优化器状态,例如:
from mmcv.runner import CheckpointHook
checkpoint_hook = CheckpointHook(interval=1, save_optimizer=True, out_dir='checkpoints')
其中,interval参数表示保存模型和优化器状态的间隔(单位为epoch),save_optimizer参数表示是否保存优化器状态,out_dir参数表示保存路径。
DistSamplerSeedHook:用于设置分布式训练中的随机种子,以保证不同进程的随机数生成一致。可以使用DistSamplerSeedHook来设置随机种子,例如:
from mmcv.runner import DistSamplerSeedHook
dist_sampler_seed_hook = DistSamplerSeedHook()
EMAHook:用于计算指数移动平均值(EMA)并更新模型参数,以提高模型的鲁棒性。可以使用EMAHook来计算EMA并更新模型参数,例如:
from mmcv.runner import EMAHook
ema_hook = EMAHook(0.99, interval=1, optimizer_momentum_based=True)
其中,0.99是EMA的衰减率,interval是EMA更新的间隔(单位为epoch),optimizer_momentum_based表示是否使用优化器的动量来计算EMA。
LoggerHook:用于记录和可视化训练指标,例如损失和准确率。可以使用LoggerHook来记录和可视化训练指标,例如:
from mmcv.runner import LoggerHook
logger_hook = LoggerHook(interval=10)
其中,interval参数表示记录和可视化训练指标的间隔(单位为iteration)。
除了上述hook函数外,mmlab还提供了许多其他的hook函数,例如CheckpointLoaderHook、LrUpdaterHook、OptimizerHook等,可以根据具体需求选择使用。这些hook函数可以方便地插入到模型训练过程中,以实现特定的功能和操作。
https://zhuanlan.zhihu.com/p/387483425
https://zhuanlan.zhihu.com/p/355272220
Hook 技术应用非常广泛,可以随便找一个简单例子来说明其用途。在软件编程的设计模式中,有一种设计模式叫做观察者设计模式,该设计模式实现的功能是:对于被观察者的一举一动,观察者都能够立即观测到,其内部实现机制可以简单通过 hook 机制实现
观察者设计模式是一种常用的设计模式,它用于实现对象间的一对多依赖关系。在观察者设计模式中,当被观察者对象的状态发生改变时,所有观察者对象都能够接收到通知并立即做出相应的响应。
在实现观察者设计模式时,可以使用hook技术来实现被观察者对象和观察者对象之间的通信。具体来说,可以将观察者对象的方法作为hook函数,注册到被观察者对象中。当被观察者对象的状态发生改变时,它会自动调用所有注册的hook函数,从而通知所有的观察者对象。
例如,假设我们要实现一个简单的观察者设计模式,用于监控一个温度传感器的温度变化。可以定义一个TemperatureSensor类作为被观察者对象,和一个Observer类作为观察者对象。在TemperatureSensor类中,可以定义一个add_observer方法,用于注册观察者对象的update方法作为hook函数。在TemperatureSensor类中,可以使用hook技术来通知所有观察者对象当前的温度值。
class TemperatureSensor:
def __init__(self):
self.observers = []
def add_observer(self, observer):
self.observers.append(observer.update)
def remove_observer(self, observer):
self.observers.remove(observer.update)
def set_temperature(self, temperature):
# 更新温度值
self.temperature = temperature
# 调用所有观察者对象的 update 方法
for observer in self.observers:
observer(self.temperature)
class Observer:
def update(self, temperature):
# 处理温度变化的通知
pass
在上述代码中,TemperatureSensor类是被观察者对象,它有一个add_observer方法,用于注册观察者对象的update方法作为hook函数。Observer类是观察者对象,它有一个update方法,用于处理被观察者对象传递的温度变化通知。在TemperatureSensor类的set_temperature方法中,调用所有注册的hook函数来通知所有观察者对象当前的温度值。
因此,通过使用hook技术,可以很方便地实现观察者设计模式,从而实现对象间的一对多依赖关系,并且能够在被观察者对象的状态发生改变时自动通知所有观察者对象。
python如何实现hook函数
在Python中,可以通过定义函数或类来实现hook函数。以下是两种实现hook函数的方法:
- 定义函数
可以定义一个函数来实现hook函数,然后将该函数注册到事件处理器中。例如:
def my_hook(*args, **kwargs):
# 在事件发生时执行特定的操作
pass
# 注册函数到事件处理器中
event_handler.register(my_hook)
在上述代码中,my_hook函数是一个hook函数,可以在事件发生时执行特定的操作。通过将my_hook函数注册到事件处理器中,就可以在相应的事件发生时自动调用该函数。
- 定义类
可以定义一个类来实现hook函数,然后将该类实例化并注册到事件处理器中。例如:
class MyHook:
def __init__(self, *args, **kwargs):
pass
def __call__(self, *args, **kwargs):
# 在事件发生时执行特定的操作
pass
# 实例化类并注册到事件处理器中
my_hook = MyHook()
event_handler.register(my_hook)
在上述代码中,MyHook类是一个hook函数的实现,可以在事件发生时执行特定的操作。通过实例化MyHook类并将其注册到事件处理器中,就可以在相应的事件发生时自动调用该类的__call__方法。
总的来说,Python中的hook函数实现方法可以根据具体的场景和需求来选择,可以通过定义函数或类来实现hook函数,并将其注册到事件处理器中以实现特定的功能和操作。
pytoch中的hook函数
在PyTorch中,hook函数是一种非常有用的工具,可以在模型训练过程中获取模型的中间输出结果、梯度信息等,从而进行进一步的分析和处理。PyTorch中的hook函数可以通过注册hook到模型的某一层中来实现。
具体来说,PyTorch中的hook函数可以通过register_forward_hook和register_backward_hook方法来注册到模型的某一层中。其中,register_forward_hook方法可以在模型前向传递过程中获取该层的中间输出结果,register_backward_hook方法可以在模型反向传递过程中获取该层的梯度信息。
例如,以下代码展示了如何在模型的某一层中注册hook函数:
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3, 1, 1)
self.conv2 = nn.Conv2d(64, 128, 3, 1, 1)
self.fc = nn.Linear(128 * 28 * 28, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(-1, 128 * 28 * 28)
x = self.fc(x)
return x
model = MyModel()
# 定义 hook 函数
def my_hook_fn(module, input, output):
print(f"Module: {module}")
print(f"Input: {input}")
print(f"Output: {output}")
# 注册 hook 函数到模型中的某一层
layer = model.conv1
hook_handle = layer.register_forward_hook(my_hook_fn)
在上述代码中,我们定义了一个名为my_hook_fn的hook函数,该函数用于在模型前向传递过程中获取该层的中间输出结果。然后,我们将该hook函数注册到模型的第一层卷积层中。通过调用register_forward_hook方法并传入my_hook_fn函数,我们可以将my_hook_fn函数注册到模型的第一层卷积层中,并返回一个hook handle,该hook handle可以用于删除该hook函数。
在训练过程中,每当模型前向传递到第一层卷积层时,my_hook_fn函数就会被调用并输出该层的中间输出结果。通过注册hook函数,我们可以方便地获取模型的中间输出结果,并进行进一步的分析和处理。
为了节省显存(内存),PyTorch会自动舍弃图计算的中间结果,所以想要获取这些数值就需要使用hook函数。hook函数在使用后应及时删除(remove),以避免每次都运行钩子增加运行负载。
这里总结一下并给出实际用法和注意点。hook方法有4种:
1、Tensor.register_hook()
2、torch.nn.Module.register_forward_hook()
3、torch.nn.Module.register_backward_hook()
4、torch.nn.Module.register_forward_pre_hook()
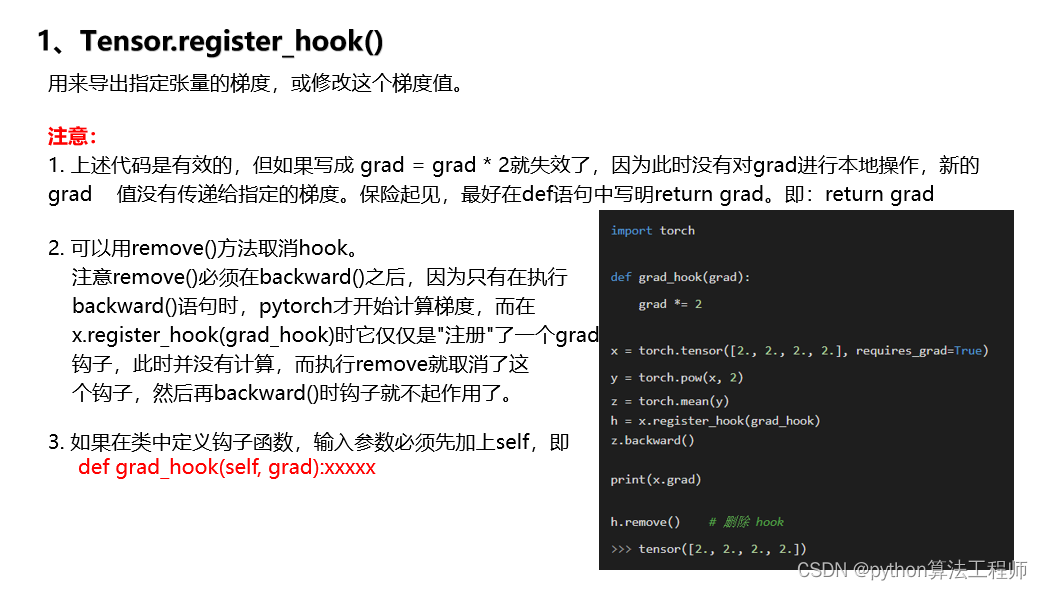
1.Tensor.register_hook(hook):对于单个张量,可以使用register_hook()方法注册一个hook。该方法将一个函数(即hook)注册到张量上,在张量被计算时调用该函数。这个函数可以用来获取张量的梯度或值,或者对张量进行其他操作。例如,以下代码演示了如何使用register_hook()方法获取张量的梯度:
import torch
x = torch.randn(2, 2, requires_grad=True)
def print_grad(grad):
print(grad)
hook_handle = x.register_hook(print_grad)
y = x.sum()
y.backward()
hook_handle.remove()
在这个例子中,我们创建了一个包含梯度的张量x,并使用register_hook()方法注册了一个打印梯度的hook函数print_grad()。在计算y的梯度时,hook函数被调用并打印梯度。最后,我们使用hook_handle.remove()方法从张量中删除hook函数。

2.torch.nn.Module.register_forward_hook(hook):对于模型中的每个层,可以使用register_forward_hook()方法注册一个hook函数。这个函数将在模型的前向传递中被调用,并可以用来获取层的输出。例如,以下代码演示了如何使用register_forward_hook()方法获取模型的某一层的输出:
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.avgpool(x)
return x
def hook(module, input, output):
print(output.shape)
model = MyModel()
handle = model.conv2.register_forward_hook(hook)
x = torch.randn(1, 3, 224, 224)
output = model(x)
handle.remove()
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.conv1(x)
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.conv1(x)
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.conv1(x)
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.conv1(
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
pass
在这个例子中,我们定义了一个包含两个卷积层和一个全局平均池化层的模型,并使用register_forward_hook()方法在第二个卷积层上注册了一个hook函数。当模型进行前向传递时,hook函数将被调用并打印输出张量的形状。最后,我们使用handle.remove()方法从模型中删除hook函数。
torch.nn.Module.register_backward_hook(hook):对于模型中的每个层,可以使用register_backward_hook()方法注册一个hook函数。这个函数将在模型的反向传递中被调用,并可以用来获取梯度或其他信息。例如,以下代码演示了如何使用register_backward_hook()方法获取某一层的梯度
:
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.avgpool(x)
return x
def hook(module, grad_input, grad_output):
print(grad_input[0].shape, grad_output[0].shape)
model = MyModel()
handle = model.conv2.register_backward_hook(hook)
x = torch.randn(1, 3, 224,
output = model(x)
output.sum().backward()
handle.remove()
在这个例子中,我们定义了一个包含两个卷积层和一个全局平均池化层的模型,并使用register_backward_hook()方法在第二个卷积层上注册了一个hook函数。当模型进行反向传递时,hook函数将被调用并打印输入梯度和输出梯度张量的形状。最后,我们使用handle.remove()方法从模型中删除hook函数。

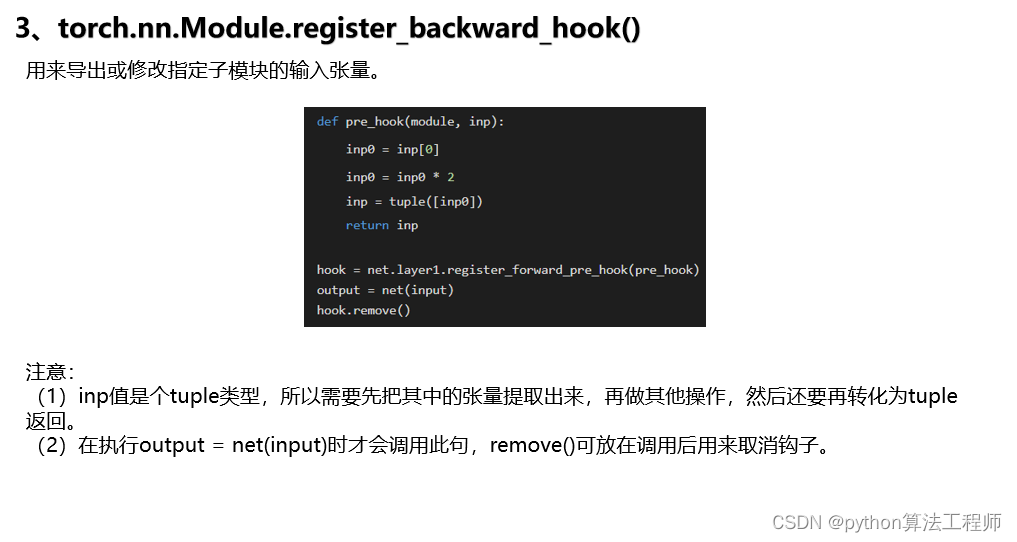
- torch.nn.Module.register_forward_pre_hook(hook):对于模型中的每个层,可以使用register_forward_pre_hook()方法注册一个hook函数。这个函数将在模型的前向传递之前被调用,并可以用来获取输入张量或其他信息。例如,以下代码演示了如何使用register_forward_pre_hook()方法获取模型的输入张量:
import torch.nn as nn
class MyModel(nn.Module):
def init(self):
super(MyModel, self).init()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x)
x = self.avgpool(x)
[return x](poe://www.poe.com/_api/key_phrase?phrase=return%20x&prompt=Tell%20me%20more%20about%20return%20x.)
def hook(module, input):
print(input[0].shape)
model = MyModel()
handle = model.conv1.register_forward_pre_hook(hook)
x = torch.randn(1, 3, 224, 224)
output = model(x)
handle.remove()
在这个例子中,我们定义了一个包含两个卷积层和一个全局平均池化层的模型,并使用register_forward_pre_hook()方法在第一个卷积层上注册了一个hook函数。当模型进行前向传递时,hook函数将被调用并打印输入张量的形状。最后,我们使用handle.remove()方法从模型中删除hook函数。
需要注意的是,hook函数应该尽可能快地执行,以避免对模型的计算时间造成过多的影响。此外,如果注册了太多的hook函数,会导致额外的内存占用和计算负担。因此,应该仔细考虑何时需要注册hook函数,并在使用后及时删除它们。

















 2438
2438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









