














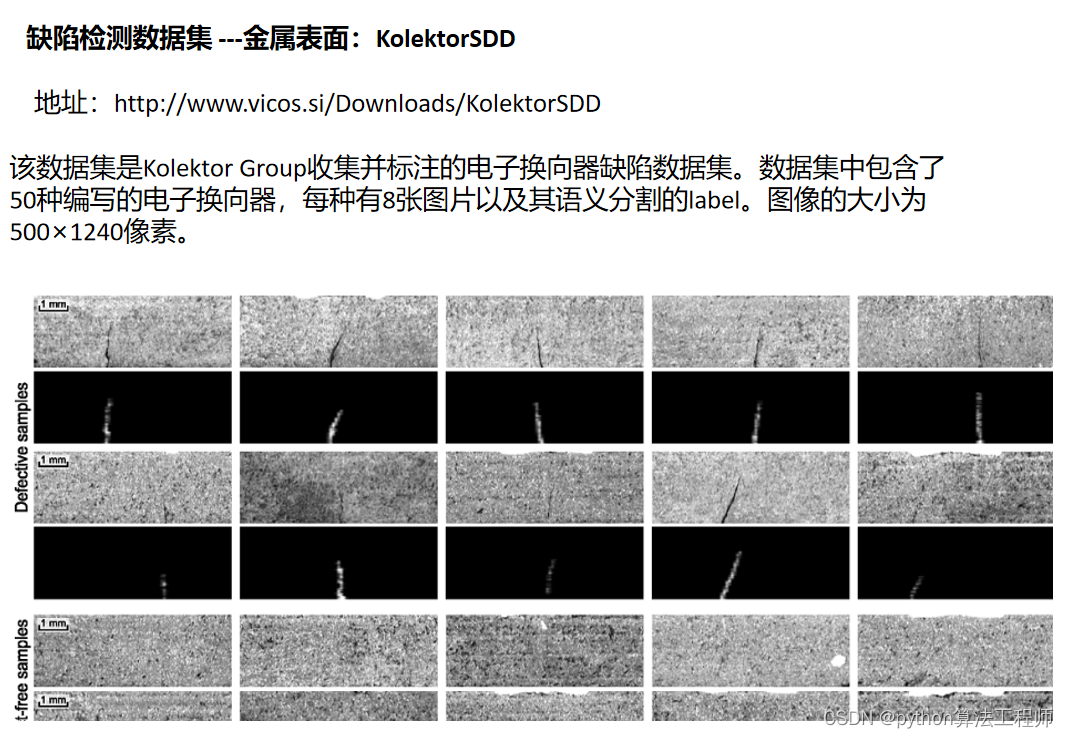


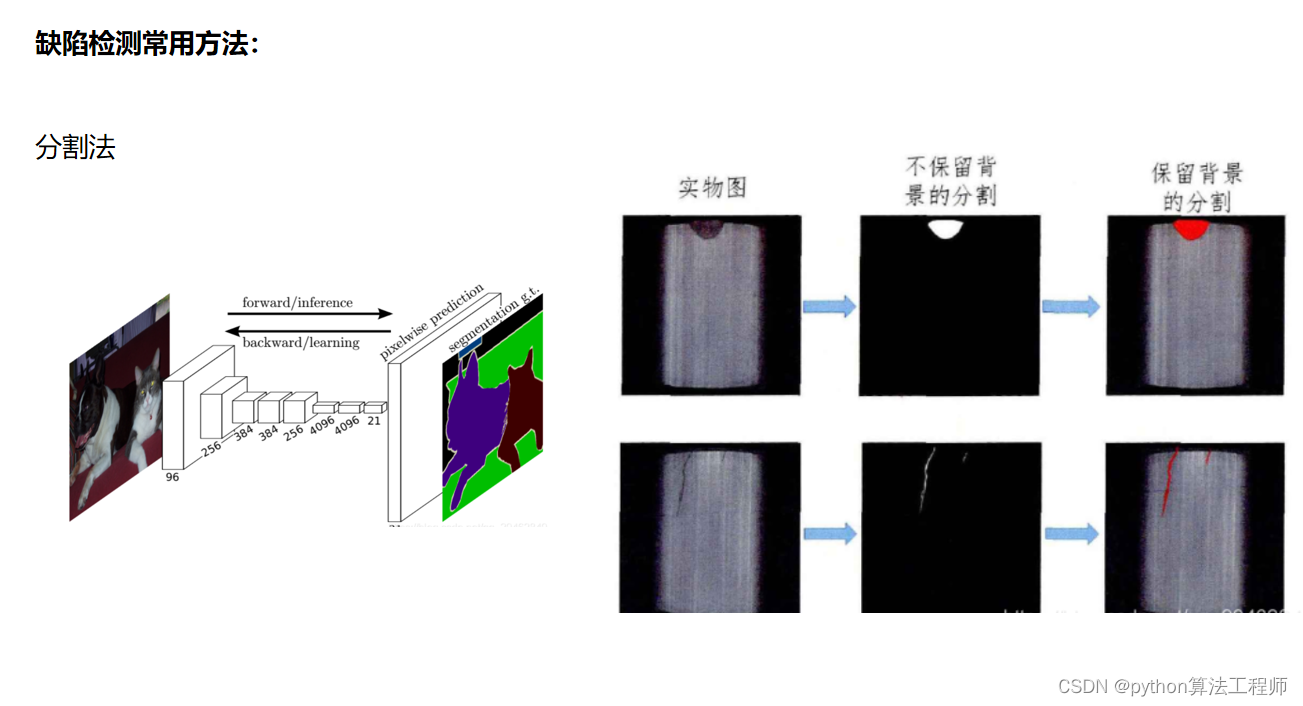
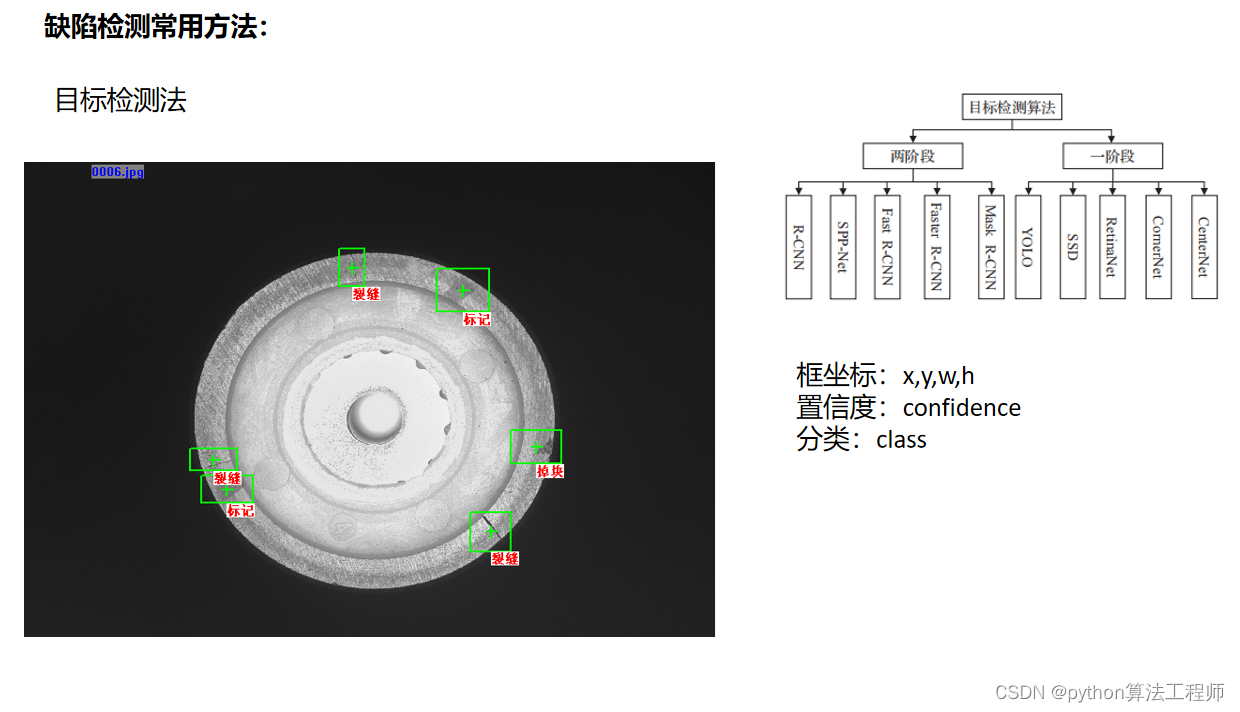
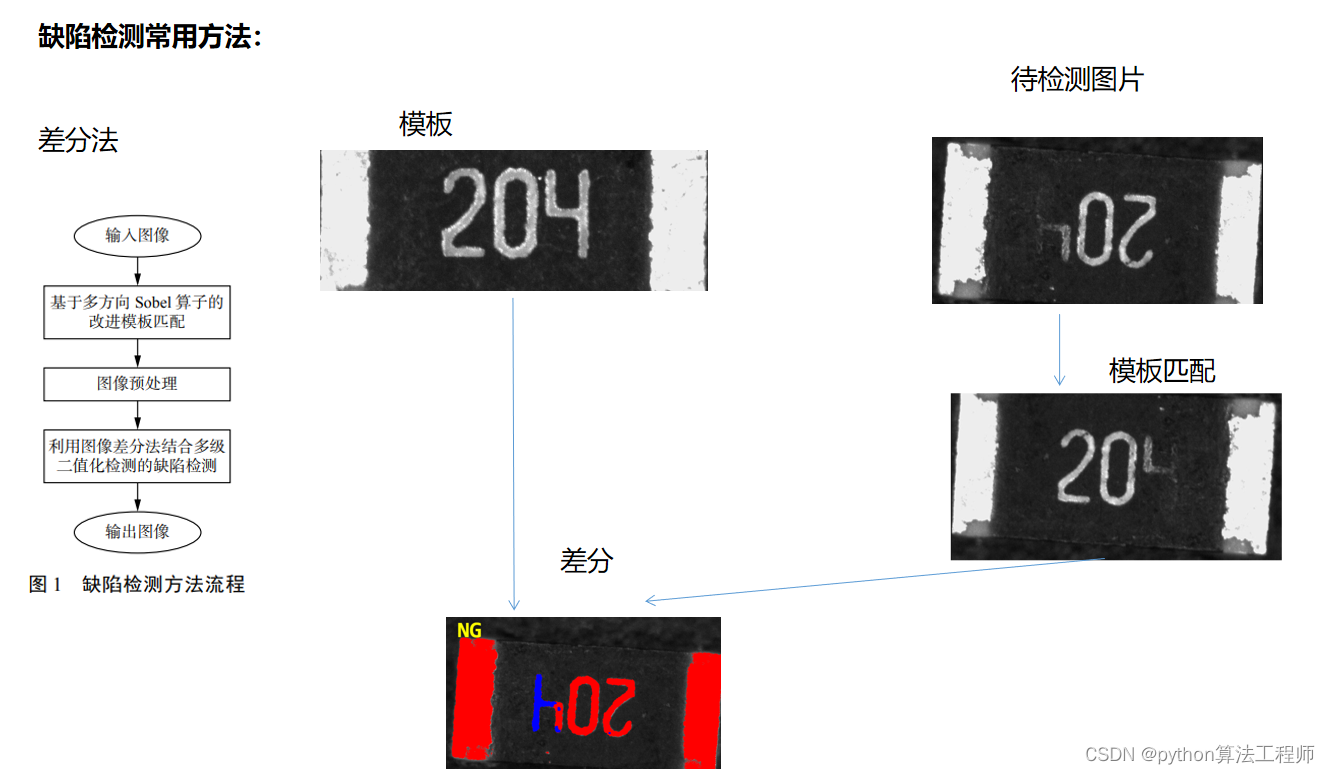


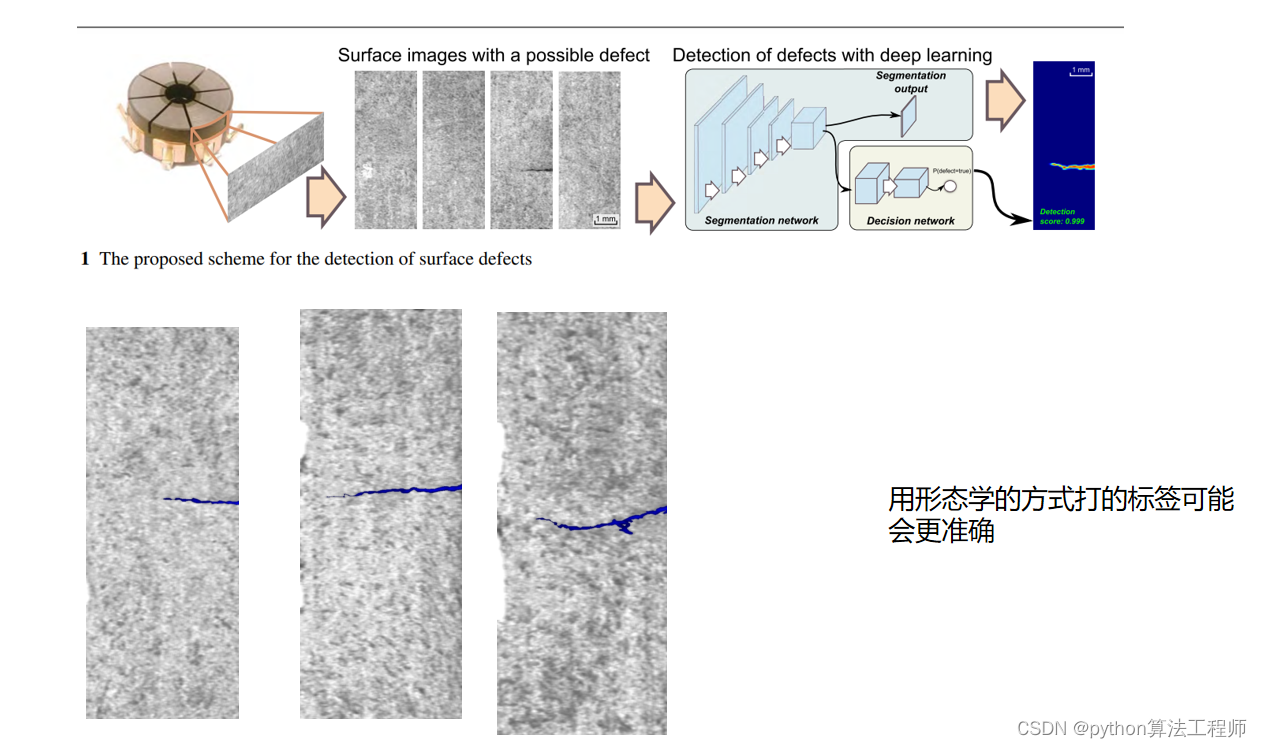



 把数据加载模块的代码跑一遍,以对数据集和数据加载更好的了解
把数据加载模块的代码跑一遍,以对数据集和数据加载更好的了解
RSSD_dataloader.py
import os,glob,cv2
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as data
import xml.dom.minidom
class kolektor_DATA(data.Dataset):
def __init__(self,root_dir):
self.root_dir=root_dir
self.image_dir=os.path.join(self.root_dir,'Rail_surface_images')
self.label_dir=os.path.join(self.root_dir,'GroundTruth')
self.images=glob.glob(self.image_dir+'\\*.jpg')
self.labels = glob.glob(self.label_dir + '\\*.jpg')
self.images.sort()
self.labels.sort()
def __getitem__(self, item):
image=cv2.imread(self.images[item])
label = cv2.imread(self.labels[item],0)
temp = np.zeros_like(label)
mask = np.ones_like(label) * 255 - label
mask[mask > 0] = 1
mask = cv2.merge([mask, mask, mask])
current_label = cv2.merge([label, temp, temp])
image = image * mask + image * current_label
return image
def __len__(self):
return len(self.images)
if __name__=="__main__":
root_dir=r"D:\BaiduNetdiskDownload\RSDDs\Type-IIRSDDsdataset"
ownData=kolektor_DATA(root_dir)
Dataloader=data.DataLoader(ownData,batch_size=1,shuffle=False)
for id,image in enumerate(Dataloader):
image=image[0].numpy()
image=np.array(image)
cv2.imwrite(str(id)+'.jpg',image)
# cv2.imshow("show",image)
# cv2.waitKey(300)
这段代码定义了一个自定义的 PyTorch 数据集类
kolektor_DATA,用于加载一个包含铁路图像的数据集。该数据集包含两个文件夹,一个包含图像,另一个包含相应的标签图像。在数据集类的构造函数中,定义了数据集的根目录、图像目录、标签目录,并使用 glob 模块获取所有图像和标签的文件路径,并进行排序。在
getitem 函数中,加载图像和标签,对标签进行处理,生成一个类似于二值掩模的图像,然后将其与原始图像相乘,最终返回处理后的图像。在代码的主函数中,首先定义了数据集对象 ownData,然后使用数据集对象创建了一个 PyTorch 的数据加载器
Dataloader,并设置了批量大小和是否随机打乱数据。最后,在一个 for 循环中,遍历数据加载器中的所有数据,并将其保存为图像文件。
NEU_DET_dataloader.py
import os,glob,cv2
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as data
import xml.dom.minidom
class NEU_DET_DATA(data.Dataset):
def __init__(self,root_dir):
self.root_dir=root_dir
self.label_dir=os.path.join(self.root_dir,'Annotations')
self.image_dir = os.path.join(self.root_dir, 'JPEGImages')
self.images=glob.glob(self.image_dir+'\\*.jpg')
self.labels = glob.glob(self.label_dir + '\\*.xml')
self.images.sort()
self.labels.sort()
def __getitem__(self, item):
current_image=self.images[item]
current_label=self.labels[item]
#exist=os.path.exists(current_image)
image=cv2.imread(current_image)
#读取xml格式的label
dom = xml.dom.minidom.parse(current_label)
# 得到文档元素对象
label = dom.documentElement
objects=label.getElementsByTagName('object')
for every_object in objects:
name=every_object.getElementsByTagName('name')[0].childNodes[0].nodeValue
pose=every_object.getElementsByTagName('pose')[0].childNodes[0].nodeValue
truncated=every_object.getElementsByTagName('truncated')[0].childNodes[0].nodeValue
difficult=every_object.getElementsByTagName('difficult')[0].childNodes[0].nodeValue
bndbox=every_object.getElementsByTagName('bndbox')[0]
#根据字段读取框的对应值(左上角xmin,ymin,右下角xmax,ymax)
xmin=int(bndbox.getElementsByTagName('xmin')[0].childNodes[0].nodeValue)
ymin=int(bndbox.getElementsByTagName('ymin')[0].childNodes[0].nodeValue)
xmax=int(bndbox.getElementsByTagName('xmax')[0].childNodes[0].nodeValue)
ymax=int(bndbox.getElementsByTagName('ymax')[0].childNodes[0].nodeValue)
cv2.rectangle(image,(xmin,ymin),(xmax,ymax),(255,0,0))
cv2.putText(image, name,(xmin,ymin),cv2.FONT_HERSHEY_COMPLEX,1,(0,0,255),2)
return image
def __len__(self):
return len(self.images)
if __name__=="__main__":
#NEU-DEF数据集的路径
root_dir=r"C:\Users\pc\Desktop\dataset\NEU-DEF"
ownData=NEU_DET_DATA(root_dir)
Dataloader=data.DataLoader(ownData,batch_size=1,shuffle=False)
for id,image in enumerate(Dataloader):
image=image[0].numpy()
image=np.array(image)
cv2.imwrite(str(id)+'.jpg',image)
这段代码定义了一个自定义的 PyTorch 数据集类 NEU_DET_DATA,用于加载一个包含 NEU-DET
数据集的图像和标注文件。该数据集包含两个文件夹,一个包含图像,另一个包含相应的 XML 标注文件。在数据集类的构造函数中,定义了数据集的根目录、标注文件目录和图像目录,并使用 glob 模块获取所有图像和标注文件的文件路径,并进行排序。在
getitem 函数中,加载图像和相应的 XML 标注文件,使用 xml.dom.minidom 模块解析 XML 标注文件,并遍历每个对象,获取其类别和边框坐标信息。然后,将类别和边框信息绘制在图像上,并返回处理后的图像。在代码的主函数中,首先定义了数据集对象 ownData,然后使用数据集对象创建了一个 PyTorch 的数据加载器
Dataloader,并设置了批量大小和是否随机打乱数据。最后,在一个 for 循环中,遍历数据加载器中的所有数据,并将其保存为图像文件。
kolektor_dataloader.py
import os,glob,cv2
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as data
import xml.dom.minidom
class kolektor_DATA(data.Dataset):
def __init__(self,root_dir):
self.root_dir=root_dir
self.files=os.listdir(self.root_dir)
self.new_dir_path_list=[]
for every_file in self.files:
new_dir_path=os.path.join(self.root_dir, every_file)
if(os.path.isdir(new_dir_path)):
self.new_dir_path_list.append(new_dir_path)
def __getitem__(self, item):
file_dir=self.new_dir_path_list[item]
labels_path=glob.glob(file_dir+'\\*_label.bmp')
for every_label_path in labels_path:
current_label=cv2.imread(every_label_path,0)
if(current_label.sum()==0):
continue
else:
#根据标签名称获取对应图片路径
image_path=every_label_path.rstrip('_label.bmp')+'.jpg'
#以下步骤为将image和mask进行叠加
#先把image里面对应有缺陷的位置根据mask置为0,在跟mask叠加
temp=np.zeros_like(current_label)
mask=np.ones_like(current_label)*255-current_label
mask[mask>0]=1
mask=cv2.merge([mask,mask,mask])
current_label=cv2.merge([current_label,temp,temp])
image=cv2.imread(image_path)
image=image*mask+image*current_label
return image
def __len__(self):
return len(self.new_dir_path_list)
if __name__=="__main__":
#kolektor数据集可视化
#kolektor数据集路径
root_dir=r"C:\Users\pc\Desktop\dataset\kolektor"
ownData=kolektor_DATA(root_dir)
Dataloader=data.DataLoader(ownData,batch_size=1,shuffle=False)
for id,image in enumerate(Dataloader):
image=image[0].numpy()
image=np.array(image)
cv2.imwrite(str(id)+'.jpg',image)
这段代码定义了一个自定义的 PyTorch 数据集类 kolektor_DATA,用于加载一个包含 Kolektor
数据集的图像和标注文件。该数据集包含多个文件夹,每个文件夹包含一组图像和相应的标注文件。在数据集类的构造函数中,定义了数据集的根目录,并使用 os.listdir 获取所有文件夹的文件路径,并将其存储在一个列表中。在
getitem 函数中,获取当前文件夹的路径,并使用 glob 模块获取该文件夹中所有标注文件的路径。使用循环遍历每个标注文件,读取该文件并将其转换为灰度图像。如果当前标注文件中不包含任何缺陷,则跳过该文件。否则,根据标注文件的名称获取相应的图像文件路径,并将图像和标注文件进行叠加,生成带有缺陷标记的图像。在代码的主函数中,首先定义了数据集对象 ownData,然后使用数据集对象创建了一个 PyTorch 的数据加载器
Dataloader,并设置了批量大小和是否随机打乱数据。最后,使用数据加载器迭代数据集中的每个图像,并将其保存到本地磁盘中。


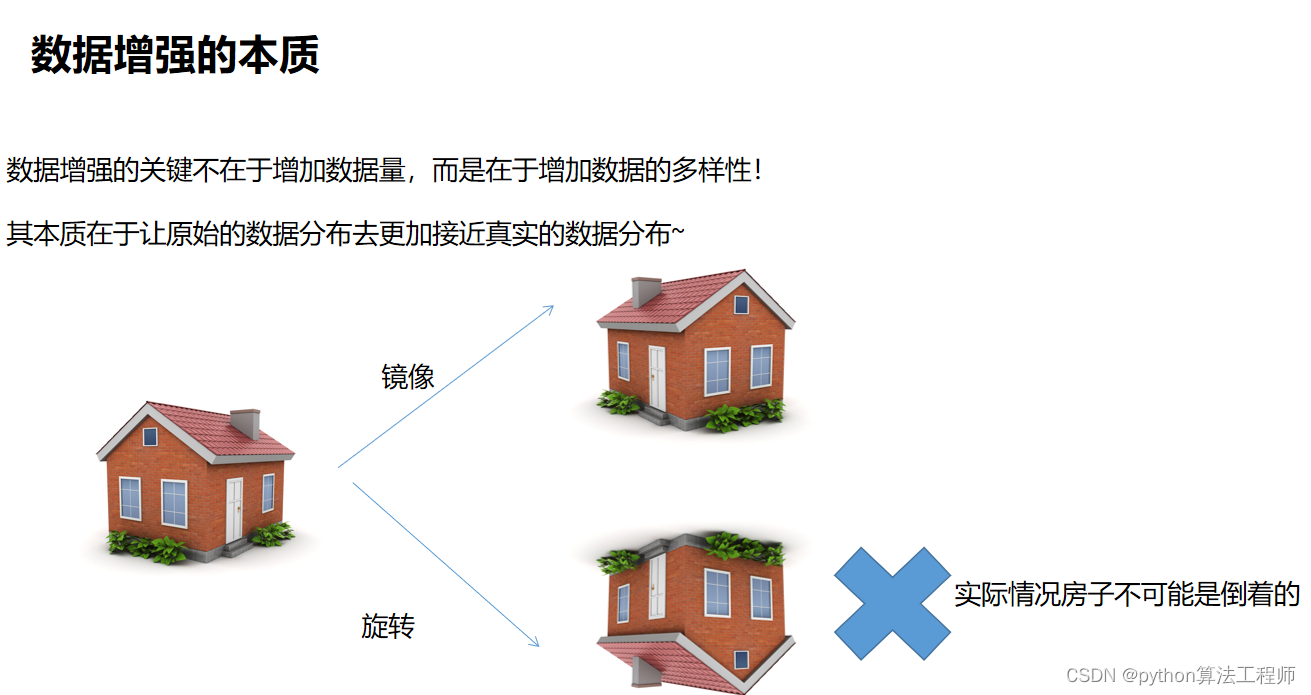
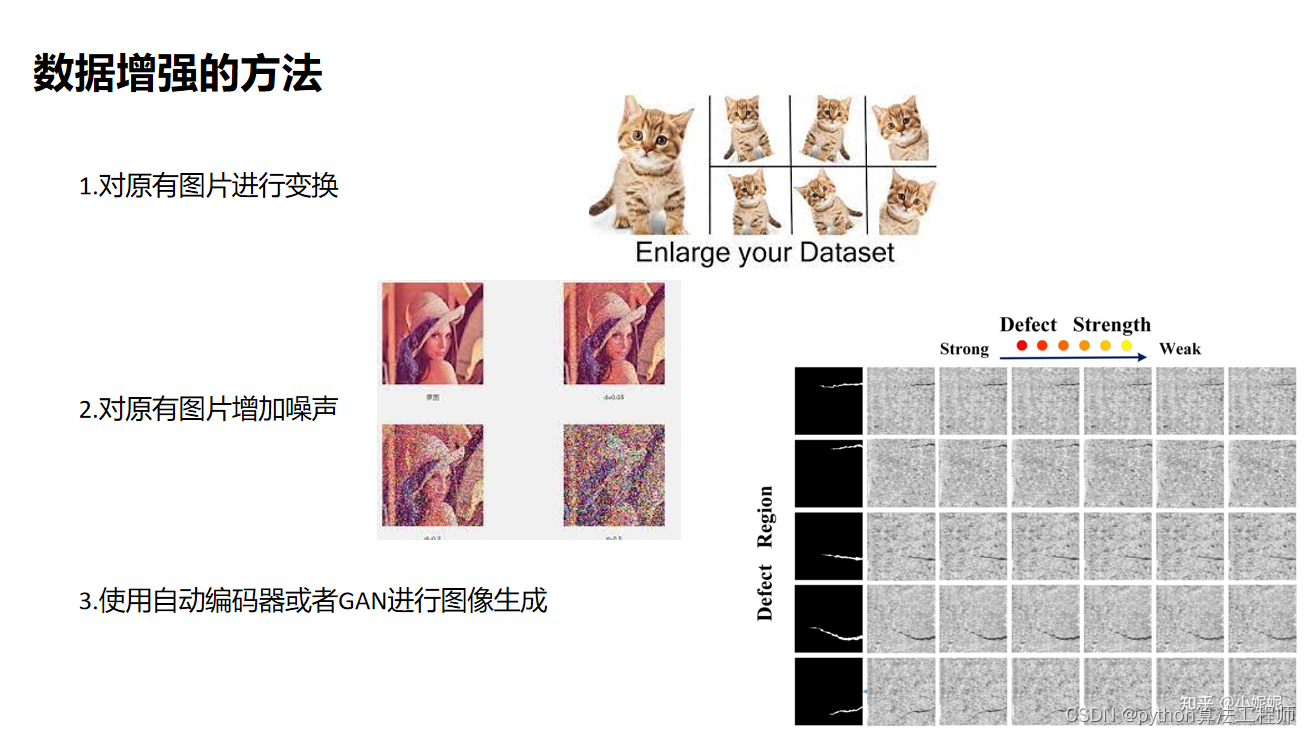



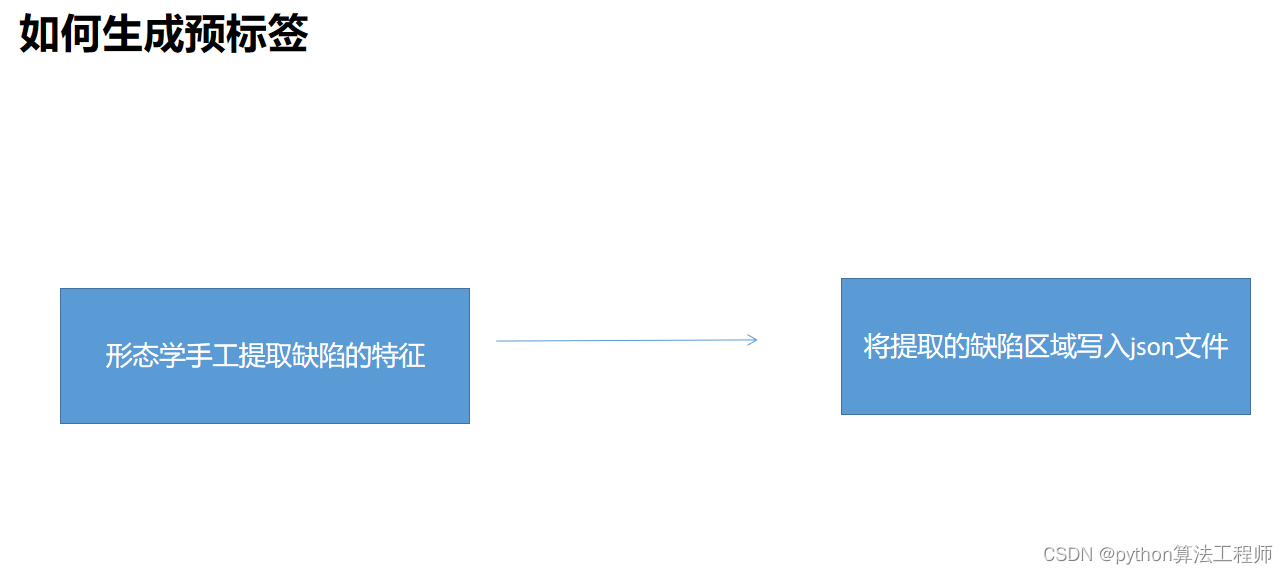
 1.对kolektor下所有数据集生成labelme格式的json预标签(可更改前处理)
1.对kolektor下所有数据集生成labelme格式的json预标签(可更改前处理)
2.安装labelme\CVAT标注工具
mix_up.py
import os,glob,cv2
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as data
def mixup_data(x, y, lam, use_cuda=True):
'''Returns mixed inputs, pairs of targets, and lambda'''
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size)
mixed_x = lam * x + (1 - lam) * x[index, :]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
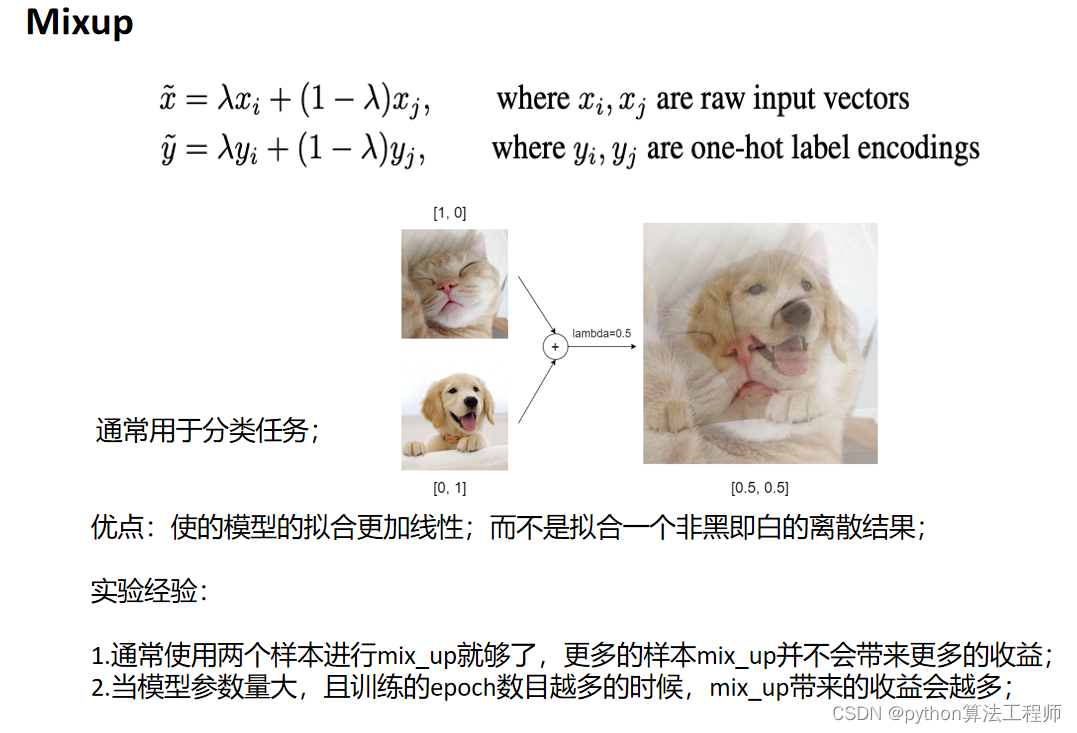
这段代码定义了两个函数 mixup_data 和 mixup_criterion,用于实现 Mixup 数据增强技术。
mixup_data 函数接受输入数据 x 和标签 y,以及一个参数 lam,该参数用于控制混合数据的比例。函数将数据和标签随机地混合,并返回混合后的输入数据、对应的标签、和 lam 值。
mixup_criterion 函数接受一个损失函数 criterion,网络的预测输出 pred,以及混合后的标签 y_a 和 y_b,以及 lam 值。函数计算混合后的损失,并返回混合后的损失值。Mixup 数据增强技术是一种常用的数据增强方法,它通过将两个随机选择的输入样本进行线性插值,生成一个新的训练样本,从而扩充训练数据集。使用Mixup 技术可以有效地增强网络的泛化能力,提高模型的鲁棒性。
generate_label.py
import os
import random
import math
import skimage.measure as sm
from PIL import Image
import cv2
import matplotlib.pyplot as plt
import numpy as np
import json
directory=r"D:\BaiduNetdiskDownload\kolektor_has_defect"
new_json_dir=r"new_json"
files=os.listdir(directory)
def process(image,file_name):
#canny提取边缘
canny_image=cv2.Canny(image,80,130)
# cv2.imshow("canny_image",canny_image)
# cv2.waitKey(0)
"""
num_labels:所有连通域的数目
labels:图像上每一像素的标记,用数字1、2、3…表示(不同的数字表示不同的连通域)
stats:每一个标记的统计信息,是一个5列的矩阵,每一行对应每个连通区域的外接矩形的x、y、width、height和面积
centroids:连通域的中心点
"""
retval, labels, stats, centroids = cv2.connectedComponentsWithStats(canny_image, connectivity=8)
print("labels.max():",labels.max())
for idx,(every_stats,every_centroid) in enumerate(zip(stats, centroids)):
if(every_stats[4]<80):
labels[np.where(labels==idx)]=0
labels[np.where(labels >0)] = 255
labels=np.uint8(labels)
# cv2.imshow("labels",labels)
# cv2.waitKey(0)
return labels
for every_file in files:
img_path=os.path.join(directory,every_file)
img = cv2.imread(img_path,0)
print(every_file)
json_dict={
"version": "4.5.10",
"flags": {},
"shapes": [],
"imagePath": "IMG_4358.jpg",
"imageData": None,
"imageHeight": -1,
"imageWidth":-1
}
json_dict["imageHeight"]=img.shape[0]
json_dict["imageWidth"] = img.shape[1]
json_dict["imagePath"] = every_file
image = img
labels = process(image.copy(),every_file)
#这里需要导入一个json的模板
#将结果写入json文件
dict={
'label': 'bottom_edge',
"points":[],
'group_id':None,
'shape_type':'linestrip',
'flags':{}
}
points=np.where(labels > 0)
# points=np.int(points)
result_points = np.column_stack([points[1],points[0]])
print(result_points)
dict['points']=result_points.tolist()
json_dict['shapes'].append(dict)
new_path=os.path.join(new_json_dir,every_file.rstrip('.jpg')+".json")
f_new=open(new_path,'w+')
json.dump(json_dict,f_new)
f_new.close()
这段代码的作用是对一个目录下的所有图片进行边缘检测,并将检测结果保存为对应的 JSON 文件。
代码首先定义了一个
process
函数,该函数接受一张图片和图片的文件名作为输入,对输入的图片进行边缘检测并返回检测结果。具体的边缘检测流程如下:
- 使用 Canny 算法提取图片的边缘;
- 使用
connectedComponentsWithStats函数对边缘进行连通域分析,得到每个连通域的统计信息和中心点;- 对于面积小于 80 的连通域,将其标记为背景;
- 将剩余的连通域标记为前景,返回标记结果。
然后,代码循环遍历目录下的所有图片,对每张图片进行边缘检测,并将检测结果保存为对应的 JSON 文件。具体的处理流程如下:
- 读取一张图片,并创建一个空的 JSON 字典;
- 将图片的宽度、高度、文件名等基本信息添加到 JSON 字典中;
- 对图片进行边缘检测,并将检测结果添加到 JSON 字典中;
- 将 JSON 字典保存为对应的 JSON 文件。
JSON 文件的格式如下:
version: 版本号,固定为 “4.5.10”;flags: 保留字段,暂未使用;shapes: 一个列表,包含所有检测到的边缘线段;imagePath: 图片文件名;imageData: 保留字段,暂未使用;imageHeight: 图片高度;imageWidth: 图片宽度。
shapes列表中的每个元素表示一条边缘线段,包含以下字段:
label: 边缘标签,固定为 “bottom_edge”;points: 一组点坐标,表示线段的起点和终点;group_id: 保留字段,暂未使用;shape_type: 形状类型,固定为 “linestrip”;flags: 保留字段,暂未使用。值得注意的是,这段代码只处理了一种边缘类型,即 “bottom_edge”,如果需要处理其他类型的边缘,需要修改代码中的相关部分。
DataAugmenytation.py
import os,glob,cv2
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as data
import xml.dom.minidom
class kolektor_DATA(data.Dataset):
def __init__(self,root_dir,aug_dir):
self.root_dir=root_dir
self.aug_dir=aug_dir
self.files=os.listdir(self.root_dir)
self.new_dir_path_list=[]
for every_file in self.files:
new_dir_path=os.path.join(self.root_dir, every_file)
if(os.path.isdir(new_dir_path)):
self.new_dir_path_list.append(new_dir_path)
def ChangeLightValue(self,image):
image_HSV = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 将亮度变为原来的2/3
image_HSV[:, :, 2] = np.uint8(image_HSV[:, :, 2] / 3 * 2)
image_HSV = cv2.cvtColor(image_HSV, cv2.COLOR_HSV2BGR)
return image_HSV
def rotation_H(self,image):
image_H = cv2.flip(image, 1, dst=None) # 水平镜像
return image_H
def rotation_V(self,image):
image_V = cv2.flip(image, 0, dst=None) # 垂直镜像
return image_V
def __getitem__(self, item):
file_dir=self.new_dir_path_list[item]
labels_path=glob.glob(file_dir+'\\*_label.bmp')
for every_label_path in labels_path:
current_label=cv2.imread(every_label_path,0)
if(current_label.sum()==0):
continue
else:
image_path=every_label_path.rstrip('_label.bmp')+'.jpg'
image=cv2.imread(image_path)
image_HSV=self.ChangeLightValue(image)
cv2.imwrite(os.path.join(self.aug_dir,str(item)+'HSV.jpg'),image_HSV)
cv2.imwrite(os.path.join(self.aug_dir, str(item) + 'HSV_label.bmp'), current_label)
image_H = self.rotation_H(image)
current_label_H = self.rotation_H(current_label)
cv2.imwrite(os.path.join(self.aug_dir, str(item) + 'H.jpg'), image_H)
cv2.imwrite(os.path.join(self.aug_dir, str(item) + 'H_label.bmp'), current_label_H)
image_V = self.rotation_V(image)
current_label_V = self.rotation_V(current_label)
cv2.imwrite(os.path.join(self.aug_dir, str(item) + 'V.jpg'), image_V)
cv2.imwrite(os.path.join(self.aug_dir, str(item) + 'V_label.bmp'), current_label_V)
return image
def __len__(self):
return len(self.new_dir_path_list)
if __name__=="__main__":
root_dir=r"D:\BaiduNetdiskDownload\kolektor"
aug_dir=r"aug_dir"
ownData=kolektor_DATA(root_dir,aug_dir)
Dataloader=data.DataLoader(ownData,batch_size=1,shuffle=False)
for id,image in enumerate(Dataloader):
print(id)
这是一个Python脚本,定义了一个名为
kolektor_DATA的自定义PyTorch数据集。该数据集用于对一组图像及其相应的标签进行数据增强。
__init__方法接受两个参数:root_dir和aug_dir。root_dir是存储图像及其标签的目录路径,aug_dir是增强图像及其标签将被保存的目录路径。
ChangeLightValue、rotation_H和rotation_V方法用于对图像执行不同类型的数据增强。ChangeLightValue减少图像的亮度,rotation_H执行水平翻转,rotation_V执行垂直翻转。
__getitem__方法从数据集中加载图像及其相应的标签,并通过调用上述方法执行数据增强。增强的图像和标签将保存在aug_dir中。
__len__方法返回数据集的长度。该脚本创建了一个
kolektor_DATA类的实例,并将其传递给PyTorch
DataLoader。DataLoader用于迭代数据集,并打印数据集中每个图像的ID。








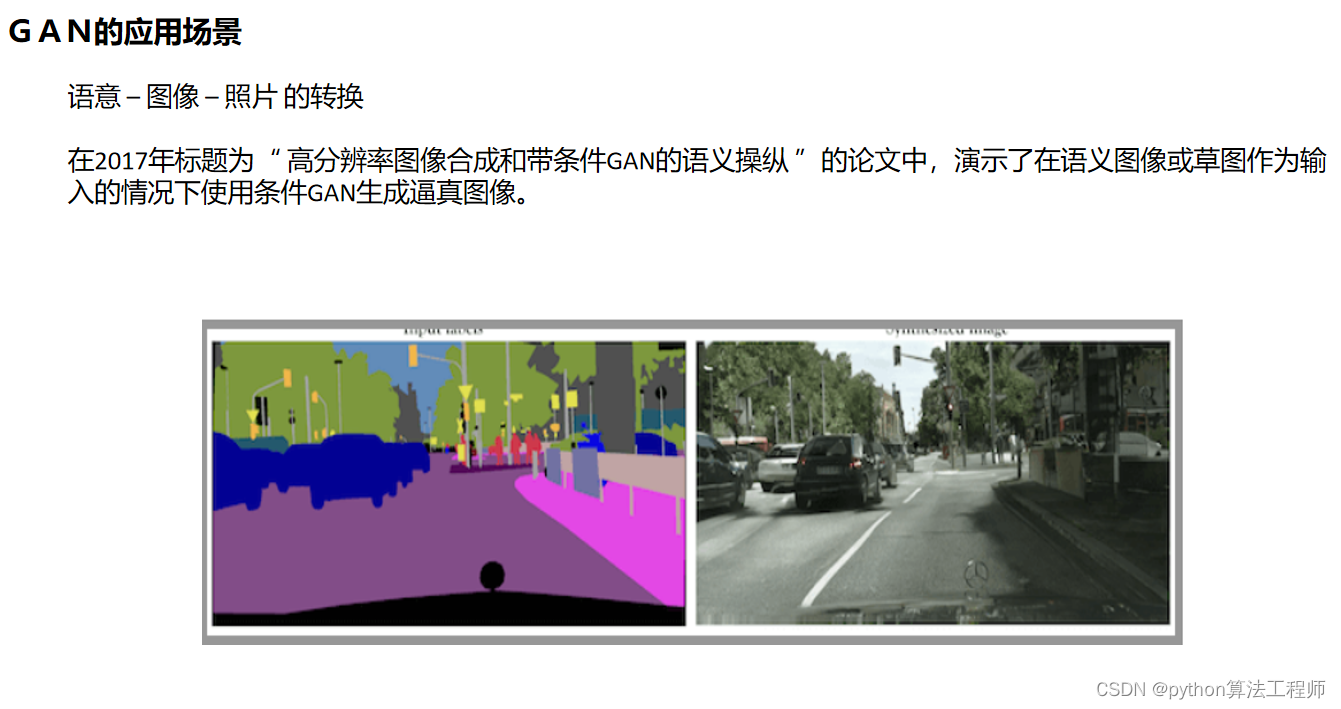






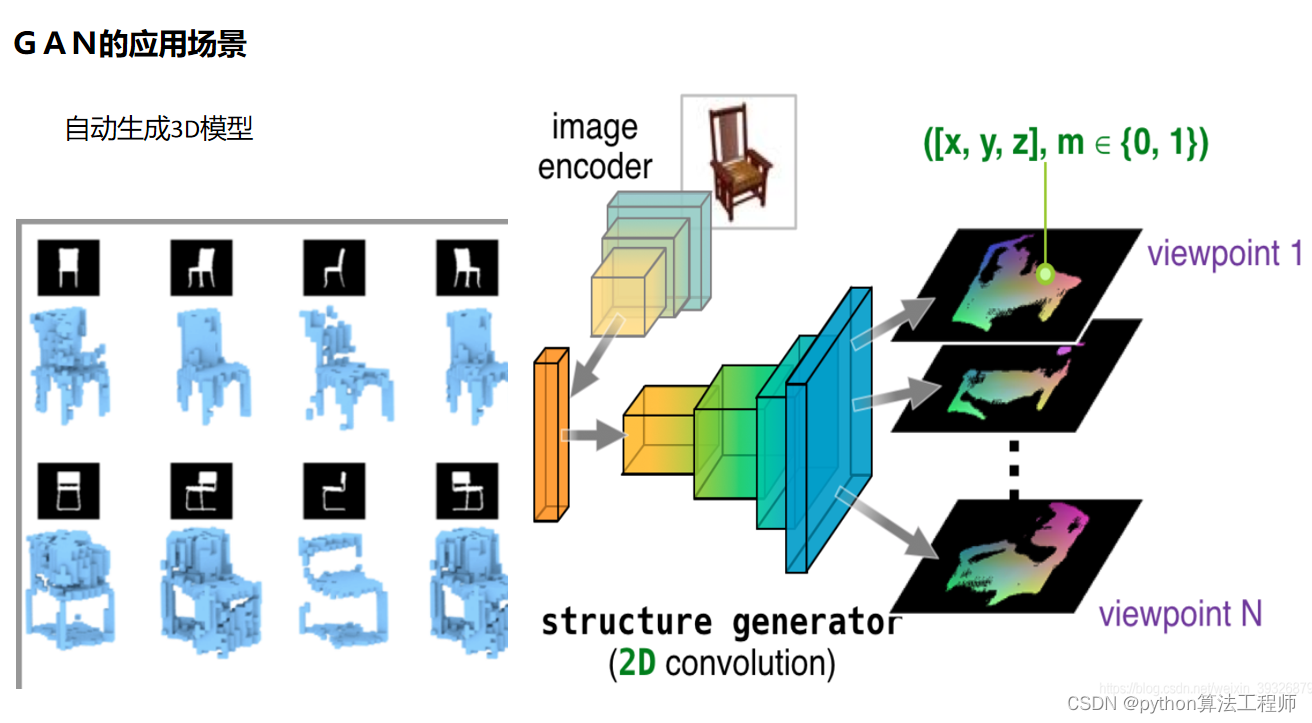

阅读
f-AnoGAN-master\mvtec_ad\train_wgangp.py
f-AnoGAN是一种用于异常检测的GAN。该GAN的特点之一是分别训练了两个对抗网络(生成器和判别器)和编码器。此外,通过判别器特征残差误差和图像重构误差计算异常分数。
该算法的引用包括一篇论文和三个GitHub链接,其中包含用于训练和测试数据集的代码和模型文件。在使用该算法之前,需要安装Python 3.6或更高版本,以及PyTorch 1.x和其他一些Python库。
对于MNIST数据集,需要按照一定的顺序运行多个Python脚本,包括训练生成器、判别器和编码器,测试异常检测以及保存比较图像。对于其他数据集,需要将自己的数据集添加到相应目录下,并更改训练、测试和保存比较图像的Python脚本中的数据集路径。
此外,该算法还提供了一个Colaboratory的notebook以帮助可视化数据。
import os
import sys
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
from fanogan.train_wgangp import train_wgangp
def main(opt):
if type(opt.seed) is int:
torch.manual_seed(opt.seed)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
pipeline = [transforms.Resize([opt.img_size]*2),
transforms.RandomHorizontalFlip()]
if opt.channels == 1:
pipeline.append(transforms.Grayscale())
pipeline.extend([transforms.ToTensor(),
transforms.Normalize([0.5]*opt.channels, [0.5]*opt.channels)])
transform = transforms.Compose(pipeline)
dataset = ImageFolder(opt.train_root, transform=transform)
train_dataloader = DataLoader(dataset, batch_size=opt.batch_size,
shuffle=True)
sys.path.append(os.path.join(os.path.dirname(__file__), ".."))
from mvtec_ad.model import Generator, Discriminator
generator = Generator(opt)
discriminator = Discriminator(opt)
train_wgangp(opt, generator, discriminator, train_dataloader, device)
"""
The code below is:
Copyright (c) 2018 Erik Linder-Norén
Licensed under MIT
(https://github.com/eriklindernoren/PyTorch-GAN/blob/master/LICENSE)
"""
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("train_root", type=str,
help="root name of your dataset in train mode")
parser.add_argument("--force_download", "-f", action="store_true",
help="flag of force download")
parser.add_argument("--n_epochs", type=int, default=300,
help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=32,
help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002,
help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5,
help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999,
help="adam: decay of first order momentum of gradient")
parser.add_argument("--latent_dim", type=int, default=100,
help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=64,
help="size of each image dimension")
parser.add_argument("--channels", type=int, default=3,
help="number of image channels (If set to 1, convert image to grayscale)")
parser.add_argument("--n_critic", type=int, default=5,
help="number of training steps for "
"discriminator per iter")
parser.add_argument("--sample_interval", type=int, default=400,
help="interval betwen image samples")
parser.add_argument("--seed", type=int, default=None,
help="value of a random seed")
opt = parser.parse_args()
main(opt)
这是一个使用PyTorch训练Wasserstein GAN with gradient penalty
(WGAN-GP)的Python脚本。脚本定义了一个main函数,使用argparse接收命令行参数,使用train_wgangp函数从fanogan.train_wgangp模块训练给定数据集上的WGAN-GP模型。main函数首先如果提供了种子值,则设置随机种子值。然后将设备设置为GPU(如果可用)或CPU。它接着使用torchvision.transforms模块定义了一个图像变换的管道,使用torchvision.datasets.ImageFolder类加载数据集,并创建一个PyTorch
DataLoader来在训练期间迭代数据集。接着,脚本从mvtec_ad.model模块导入Generator和Discriminator类,并创建这些类的实例。最后,使用提供的参数、生成器、鉴别器、数据加载器和设备调用train_wgangp函数。
argparse参数包括训练数据集的根目录、训练轮数、批量大小、学习率、动量参数、潜在空间的维度、图像大小、图像通道数、每次迭代训练鉴别器的步数、每隔多少轮保存模型和样本图像等。
import torch.nn as nn
"""
The code is:
Copyright (c) 2018 Erik Linder-Norén
Licensed under MIT
(https://github.com/eriklindernoren/PyTorch-GAN/blob/master/LICENSE)
"""
class Generator(nn.Module):
def __init__(self, opt):
super().__init__()
self.init_size = opt.img_size // 4
self.l1 = nn.Sequential(nn.Linear(opt.latent_dim,
128 * self.init_size ** 2))
self.conv_blocks = nn.Sequential(
nn.BatchNorm2d(128),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, 3, stride=1, padding=1),
nn.BatchNorm2d(128, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64, 0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),
nn.Tanh(),
)
def forward(self, z):
out = self.l1(z)
out = out.view(out.shape[0], 128, self.init_size, self.init_size)
img = self.conv_blocks(out)
return img
class Discriminator(nn.Module):
def __init__(self, opt):
super().__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1),
nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*discriminator_block(opt.channels, 16, bn=False),
*discriminator_block(16, 32),
*discriminator_block(32, 64),
*discriminator_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1))
def forward(self, img):
features = self.forward_features(img)
validity = self.adv_layer(features)
return validity
def forward_features(self, img):
features = self.model(img)
features = features.view(features.shape[0], -1)
return features
class Encoder(nn.Module):
def __init__(self, opt):
super().__init__()
def encoder_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1),
nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
return block
self.model = nn.Sequential(
*encoder_block(opt.channels, 16, bn=False),
*encoder_block(16, 32),
*encoder_block(32, 64),
*encoder_block(64, 128),
)
# The height and width of downsampled image
ds_size = opt.img_size // 2 ** 4
self.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2,
opt.latent_dim),
nn.Tanh())
def forward(self, img):
features = self.model(img)
features = features.view(features.shape[0], -1)
validity = self.adv_layer(features)
return validity
这段代码定义了三个 PyTorch
神经网络模型:Generator(生成器)、Discriminator(判别器)和Encoder(编码器)。这些模型通常用于生成对抗网络(GAN)和变分自编码器(VAE)中的图像生成和表示学习。Generator 模型接受一个随机噪声向量 z 并生成一张图像。模型由两部分组成:线性层将噪声向量映射到高维空间,卷积层生成最终的图像。
Discriminator
模型接受一张图像并预测它是真实图像还是伪造图像。模型由一系列卷积层提取输入图像的特征和一个线性层输出最终的预测组成。Encoder 模型接受一张图像并将其编码为低维潜在空间。模型由一系列卷积层提取输入图像的特征和一个线性层输出编码表示组成。
这三个模型都使用类似的卷积块,具有 LeakyReLU 激活函数、批归一化和 Dropout 层。Discriminator 和
Encoder 模型还使用线性层输出最终的预测或编码表示。Generator 模型在生成图像之前使用线性层将噪声向量映射到高维空间。这些模型接受一个 opt 对象作为输入,其中包含各种超参数,例如图像大小、通道数和潜在空间的维度。
Colaboratory
f-AnoGAN_MNIST.ipynb
f-AnoGAN_MVTecAD.ipynb
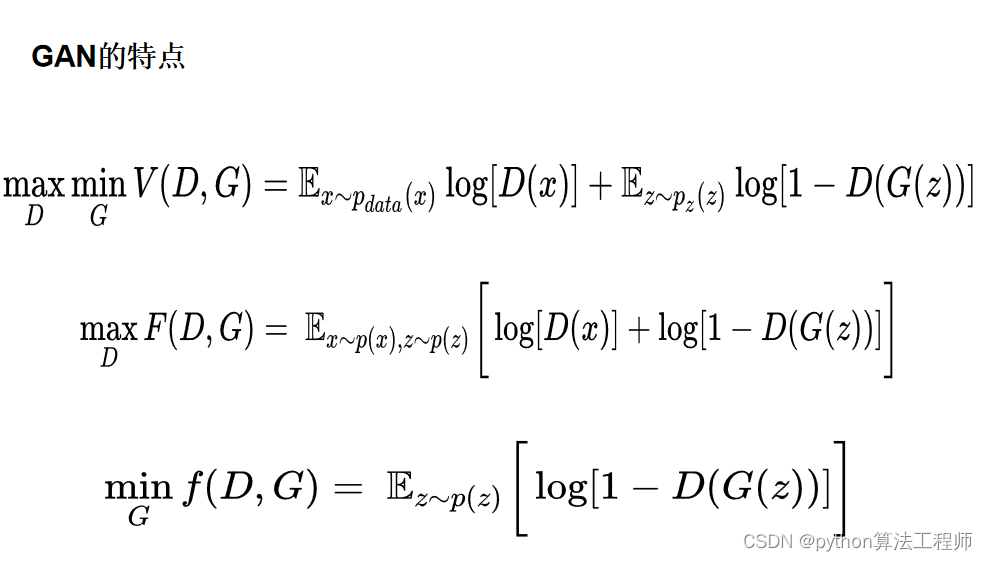 这是WGAN(Wasserstein GAN)的损失函数,其中D表示判别器,G表示生成器,x表示真实数据样本,z表示从先验分布p(z)中采样的随机噪声。
这是WGAN(Wasserstein GAN)的损失函数,其中D表示判别器,G表示生成器,x表示真实数据样本,z表示从先验分布p(z)中采样的随机噪声。
该损失函数可表示为:
max_D min_G F(D,G) = E_xp_data(x) [D(x)] - E_zp(z) [D(G(z))] + λ * E_z~p(z) [(||∇_z D(G(z))||_2 - 1)^2]
其中,第一项表示判别器对真实数据样本的预测结果,第二项表示判别器对生成器生成的虚假数据样本的预测结果,λ是一个超参数,第三项是梯度惩罚项,用于强制判别器的梯度范数保持在一个合理的范围内。
对于生成器而言,其损失函数为:
min_G F(D,G) = E_z~p(z) [-D(G(z))]
生成器的目标是最小化判别器对其生成的虚假数据的预测结果,以此鼓励生成器生成更逼真的数据。
该损失函数的意义是,通过最大化真实数据和虚假数据之间的距离,让生成器生成的虚假数据尽可能地逼真,以此骗过判别器的预测。同时,判别器需要尽可能准确地区分真实数据和生成数据,以此提高自己的预测能力。梯度惩罚项的作用是使判别器的梯度范数不要过大,从而保证模型的稳定性和收敛性。
这是GAN(Generative Adversarial Networks)的损失函数,其中D表示判别器,G表示生成器,z表示从先验分布p(z)中采样的随机噪声,x表示真实数据样本,l1表示真实数据样本的数量。
该损失函数可表示为:
max_D min_G V(D,G) = E_xp_data(x) [log D(x)] + E_zp(z) [log(1 - D(G(z)))]
其中,第一项表示判别器对真实数据样本的预测结果,第二项表示判别器对生成器生成的虚假数据样本的预测结果。对于生成器而言,其损失函数为:
min_G V(D,G) = E_z~p(z) [log(1 - D(G(z)))]
生成器的目标是最小化判别器对其生成的虚假数据的预测结果,以此鼓励生成器生成更逼真的数据。
该损失函数的意义是,通过博弈的方式,让生成器生成的虚假数据尽可能地逼真,以骗过判别器的预测。同时,判别器也需要尽可能准确地区分真实数据和生成数据,以此提高自己的预测能力。
需要注意的是,由于GAN的训练是一种对抗学习的过程,模型的训练过程相对来说比较不稳定,需要仔细调参并监控模型的训练过程,避免模型崩溃或者梯度爆炸等问题。
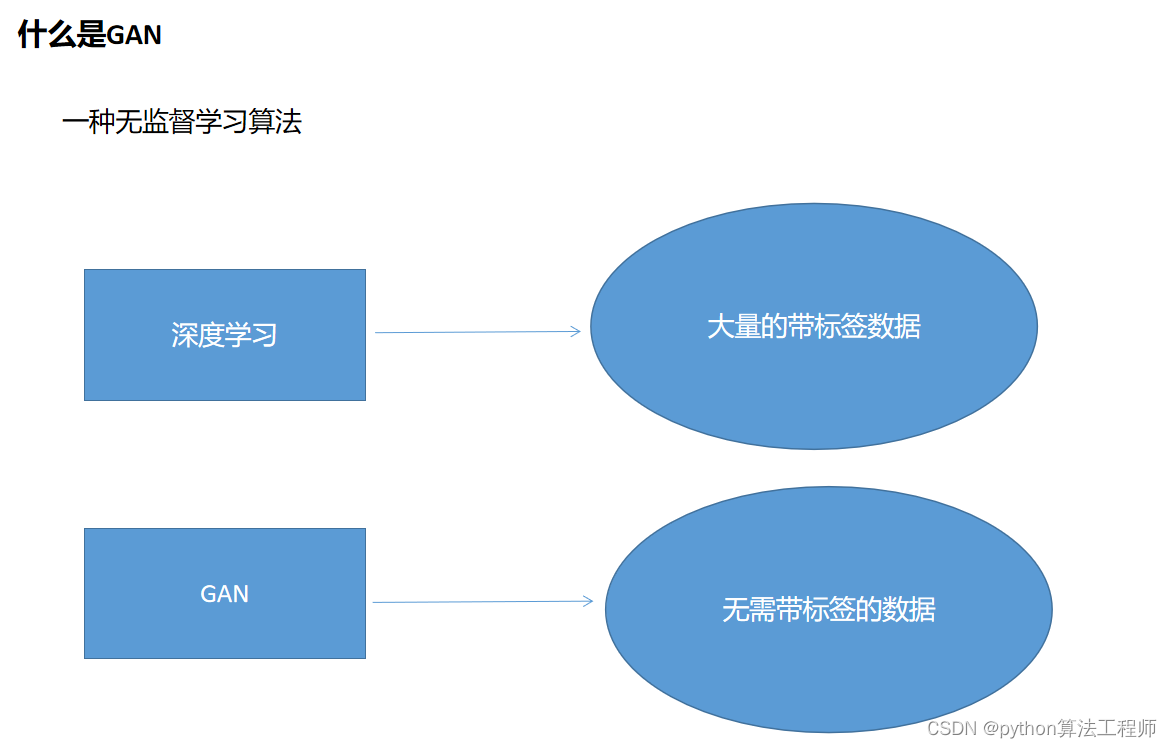
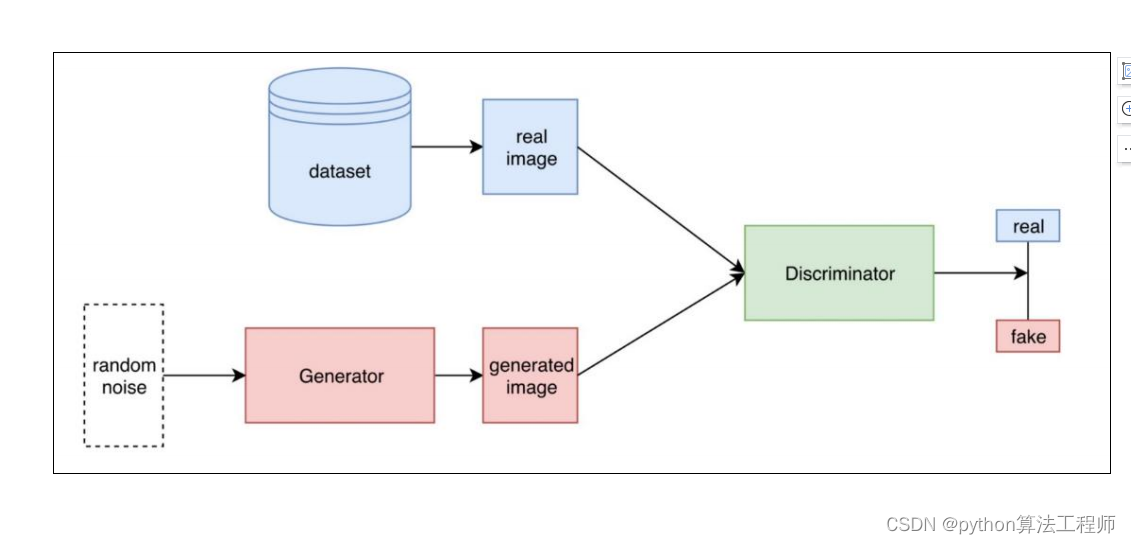
GAN(Generative Adversarial Networks)是一种深度学习模型,其特点包括:
生成能力:GAN可以生成高质量的、逼真的图像、音频、文本等各种数据类型,具有较强的生成能力。
对抗训练:GAN的训练过程采用对抗训练的方式,通过两个神经网络进行对抗学习,生成器网络生成虚假数据,判别器网络判断真假,两个网络相互博弈,最终生成器网络通过不断学习生成更加逼真的数据。
无监督学习:GAN可以进行无监督学习,不需要标注数据,只需要给定数据的分布即可进行训练。
可扩展性:GAN可以扩展到多个生成器和判别器,以及多个数据类型的生成任务。
创造性:GAN不仅可以生成逼真的数据,还可以生成新颖的、具有创造性的数据,如艺术作品、音乐等。
潜在空间:GAN的生成器网络可以将输入的随机噪声转化为潜在空间中的向量表示,这个向量表示可以被用于各种应用,如图像编辑、图像转换等。
模型轻量:相对于一些基于卷积神经网络的生成模型,GAN的模型轻量,可以用较小的模型大小生成高质量的数据。
总的来说,GAN以其强大的生成能力和无监督学习的特点,在图像、音频、文本等各种领域得到了广泛的应用。
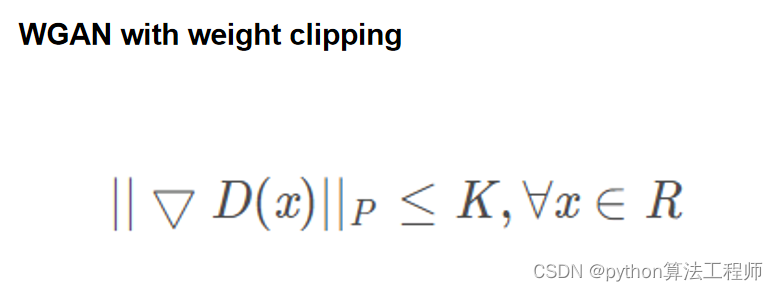 WGAN with weight clipping是一种使用Wasserstein距离作为损失函数的GAN变体,其核心思想是通过限制判别器的权重范围来约束判别器的预测结果,以此提高模型的稳定性和收敛速度。
WGAN with weight clipping是一种使用Wasserstein距离作为损失函数的GAN变体,其核心思想是通过限制判别器的权重范围来约束判别器的预测结果,以此提高模型的稳定性和收敛速度。
具体来说,WGAN with weight clipping的损失函数可表示为:
max_D min_G V(D,G) = E_xp_data(x) [D(x)] - E_zp(z) [D(G(z))] + λ * (||w_D||_2 - c)^2
其中,第一项表示判别器对真实数据样本的预测结果,第二项表示判别器对生成器生成的虚假数据样本的预测结果,λ是一个超参数,第三项是权重裁剪项,用于限制判别器的权重范围,c是一个固定的超参数,w_D表示判别器的权重。
对于生成器而言,其损失函数为:
min_G V(D,G) = -E_z~p(z) [D(G(z))]
生成器的目标是最小化判别器对其生成的虚假数据的预测结果,以此鼓励生成器生成更逼真的数据。
WGAN with weight clipping的核心思想是通过限制判别器的权重范围来约束判别器的预测结果,从而提高模型的稳定性和收敛速度。但是,权重裁剪也存在一些问题,如对模型的性能和收敛质量有一定的影响,因为裁剪操作可能会破坏模型的平衡性和梯度的连续性。
因此,近年来也有一些新的方法提出,如WGAN-GP(Wasserstein GAN with Gradient Penalty),使用梯度惩罚代替权重裁剪,从而更好地解决GAN训练中的稳定性问题。
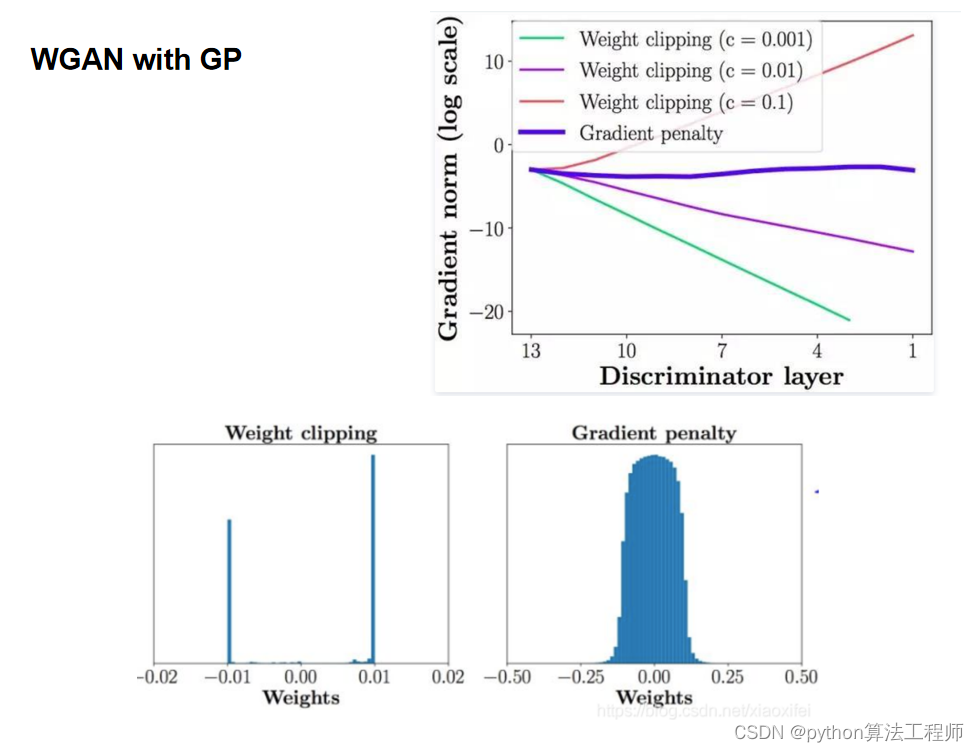 WGAN-GP(Wasserstein GAN with Gradient Penalty)是一种改进的Wasserstein GAN(WGAN),它通过梯度惩罚代替了WGAN中的权重裁剪,从而更好地解决了GAN训练中的稳定性问题。
WGAN-GP(Wasserstein GAN with Gradient Penalty)是一种改进的Wasserstein GAN(WGAN),它通过梯度惩罚代替了WGAN中的权重裁剪,从而更好地解决了GAN训练中的稳定性问题。
WGAN-GP的损失函数可表示为:
max_D min_G V(D,G) = E_x~p_data(x) [D(x)] - E_z~p(z) [D(G(z))] + λ * E_~p_g(x) [(||∇_x D(x)||_2 - 1)^2]
其中,第一项表示判别器对真实数据样本的预测结果,第二项表示判别器对生成器生成的虚假数据样本的预测结果,λ是一个超参数,第三项是梯度惩罚项,用于强制判别器的梯度范数保持在一个合理的范围内,p_g(x)是判别器在生成数据样本x处的分布。
对于生成器而言,其损失函数为:
min_G V(D,G) = -E_z~p(z) [D(G(z))]
生成器的目标是最小化判别器对其生成的虚假数据的预测结果,以此鼓励生成器生成更逼真的数据。
WGAN-GP的核心思想是通过梯度惩罚代替权重裁剪,从而更好地解决GAN训练中的稳定性问题。梯度惩罚项的作用是使判别器在生成数据分布的每个点处的梯度范数保持在一个合理的范围内,即保证了梯度的连续性和平滑性,从而提高了模型的收敛速度和稳定性。
需要注意的是,WGAN-GP相对于传统的GAN和WGAN而言,需要更多的计算资源和训练时间,但是在实验中表现出了更好的性能和稳定性。

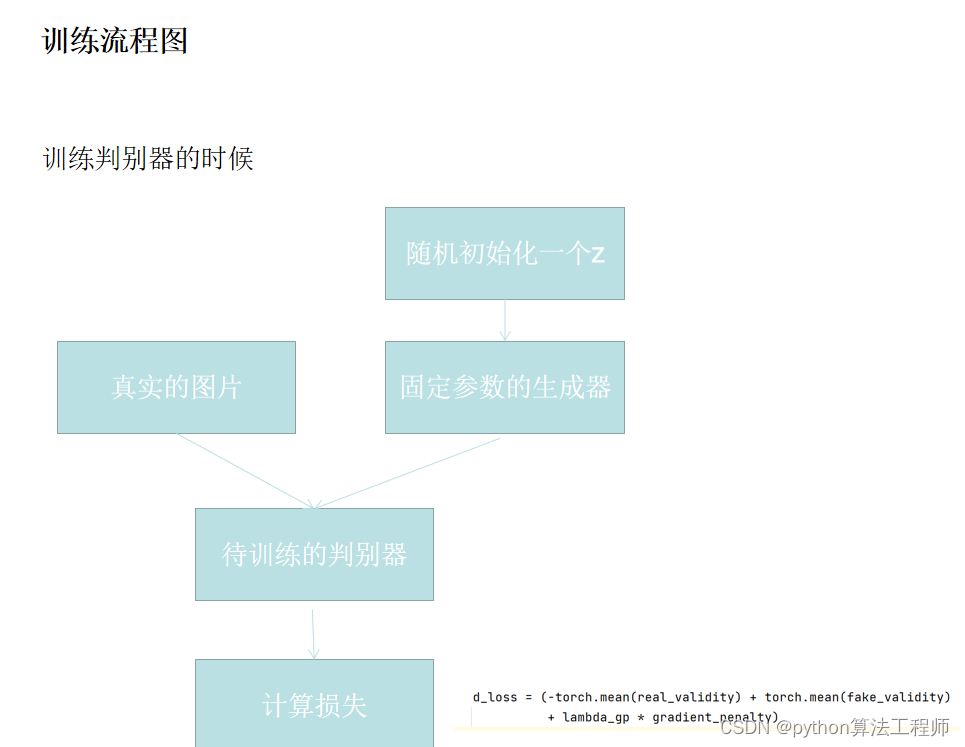
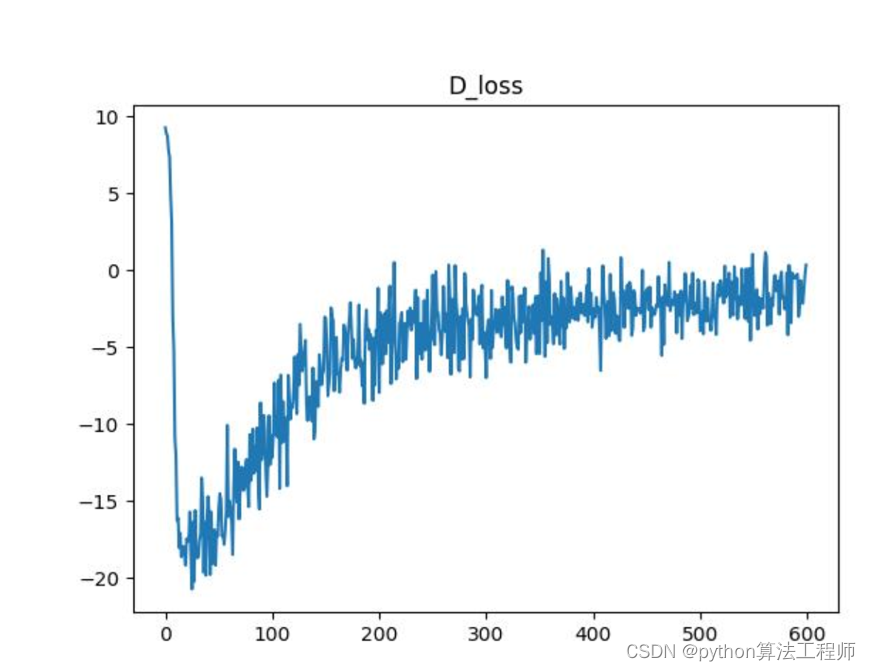 D_loss是指GAN(Generative Adversarial Networks)中判别器的损失函数,用于衡量判别器对真实数据和生成数据的预测结果的准确程度。
D_loss是指GAN(Generative Adversarial Networks)中判别器的损失函数,用于衡量判别器对真实数据和生成数据的预测结果的准确程度。
在原始的GAN中,判别器的损失函数可以表示为:
min_D V(D,G) = - E_x~p_data(x) [log D(x)] - E_z~p(z) [log(1 - D(G(z)))]
其中,第一项表示真实数据样本的预测结果,第二项表示生成数据样本的预测结果。
在Wasserstein GAN(WGAN)中,判别器的损失函数可以表示为:
max_D min_G F(D,G) = E_x~p_data(x) [D(x)] - E_z~p(z) [D(G(z))]
其中,第一项表示判别器对真实数据样本的预测结果,第二项表示判别器对生成器生成的虚假数据样本的预测结果。
在WGAN-GP(Wasserstein GAN with Gradient Penalty)中,判别器的损失函数可以表示为:
max_D min_G V(D,G) = E_x~p_data(x) [D(x)] - E_z~p(z) [D(G(z))] + λ * E_~p_g(x) [(||∇_x D(x)||_2 - 1)^2]
其中,第一项表示判别器对真实数据样本的预测结果,第二项表示判别器对生成器生成的虚假数据样本的预测结果,第三项是梯度惩罚项,用于强制判别器的梯度范数保持在一个合理的范围内,λ是一个超参数。
需要注意的是,在训练GAN时,判别器的目标是最小化其自身的损失函数,而生成器的目标是最小化判别器对其生成的虚假数据的预测结果。因此,GAN的训练过程是一个博弈论的过程,判别器和生成器相互竞争,直到达到纳什均衡。
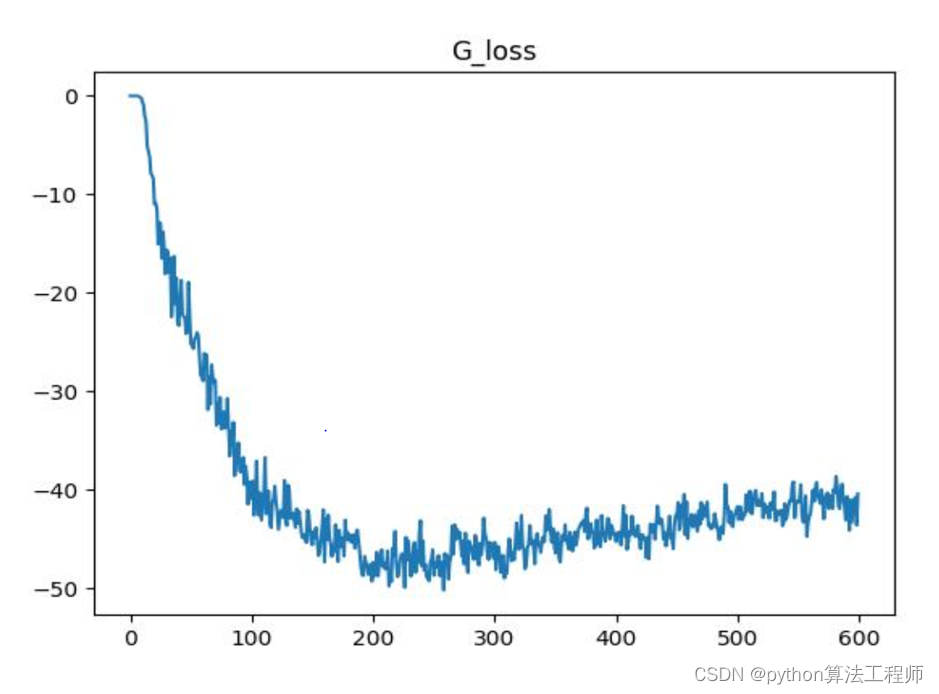
G_loss是指GAN(Generative Adversarial Networks)中生成器的损失函数,用于衡量生成器生成的虚假数据与真实数据的相似程度。
在原始的GAN中,生成器的损失函数可以表示为:
min_G V(D,G) = - E_z~p(z) [log(1 - D(G(z)))]
其中,D(G(z))表示判别器对生成器G生成的虚假数据样本的预测结果。
在Wasserstein GAN(WGAN)中,生成器的损失函数可以表示为:
min_G F(D,G) = - E_z~p(z) [D(G(z))]
其中,D(G(z))表示判别器对生成器G生成的虚假数据样本的预测结果。
在WGAN-GP(Wasserstein GAN with Gradient Penalty)中,生成器的损失函数可以表示为:
min_G V(D,G) = - E_z~p(z) [D(G(z))]
其中,D(G(z))表示判别器对生成器G生成的虚假数据样本的预测结果。
需要注意的是,在训练GAN时,判别器和生成器是相互竞争的关系,判别器的目标是最小化其自身的损失函数,而生成器的目标是最小化判别器对其生成的虚假数据的预测结果。因此,GAN的训练过程是一个博弈论的过程,判别器和生成器相互竞争,直到达到纳什均衡。在这个过程中,生成器的损失函数是由判别器的损失函数所决定的。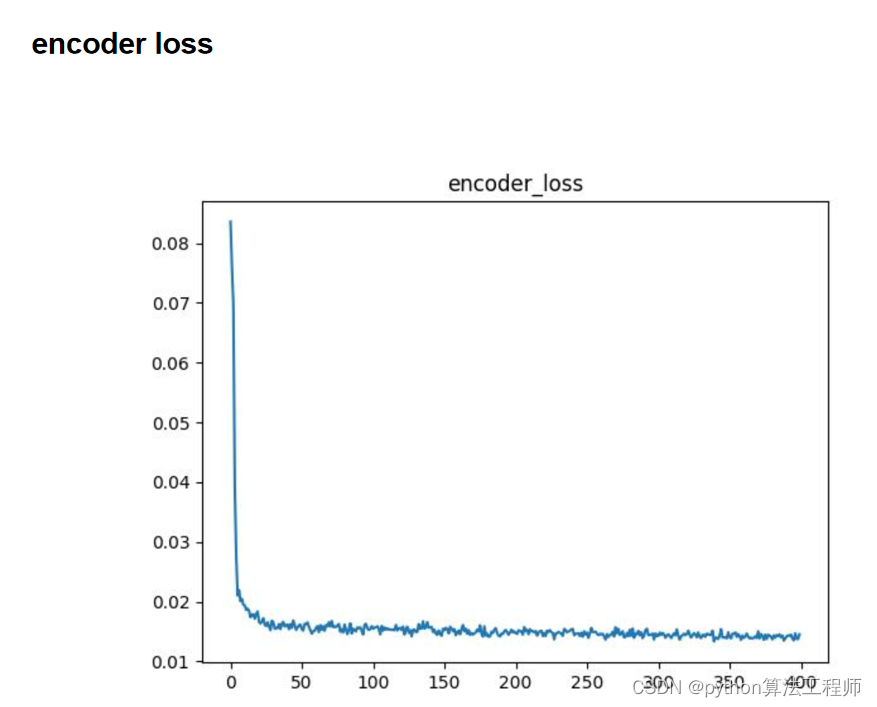
Encoder loss通常指的是自编码(Autoencoder)中的损失函数,用于衡量解码器重构出的图像与原始图像之间的差异程度。
自编码器是一种无监督学习的神经网络模型,其主要目的是将输入数据压缩到一个低维空间中,并通过解码器将其重构回原始空间。自编码器通常由编码器和解码器两部分组成,其中编码器将输入数据压缩到一个低维空间中,解码器将低维空间的表示解码回原始空间。
自编码器的损失函数通常表示为重构误差(Reconstruction Error),即解码器重构出的图像与原始图像之间的差异程度。常见的自编码器损失函数包括均方误差(Mean Square Error,MSE)、交叉熵(Cross-Entropy)等,具体选择哪种损失函数取决于所需的任务和数据的特点。
以均方误差为例,自编码器的损失函数可以表示为:
L ( x , x ^ ) = 1 n ∑ i = 1 n ( x i − x ^ i ) 2 L(x, \hat{x}) = \frac{1}{n} \sum_{i=1}^{n} (x_i - \hat{x}_i)^2 L(x,x^)=n1∑i=1n(xi−x^i)2
其中,x表示原始图像,\hat{x}表示解码器重构出的图像,n表示图像的像素数。
需要注意的是,在训练自编码器时,通常使用反向传播算法来更新模型参数,以最小化损失函数。在训练完成后,编码器的输出可以被用作数据的低维表示,具有降维和特征提取的作用。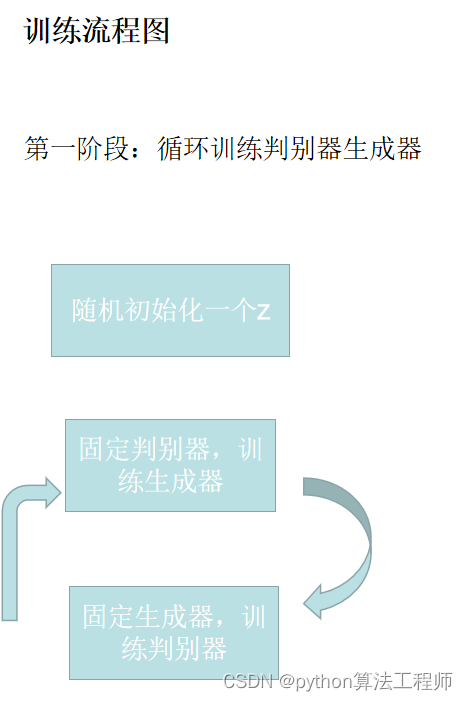


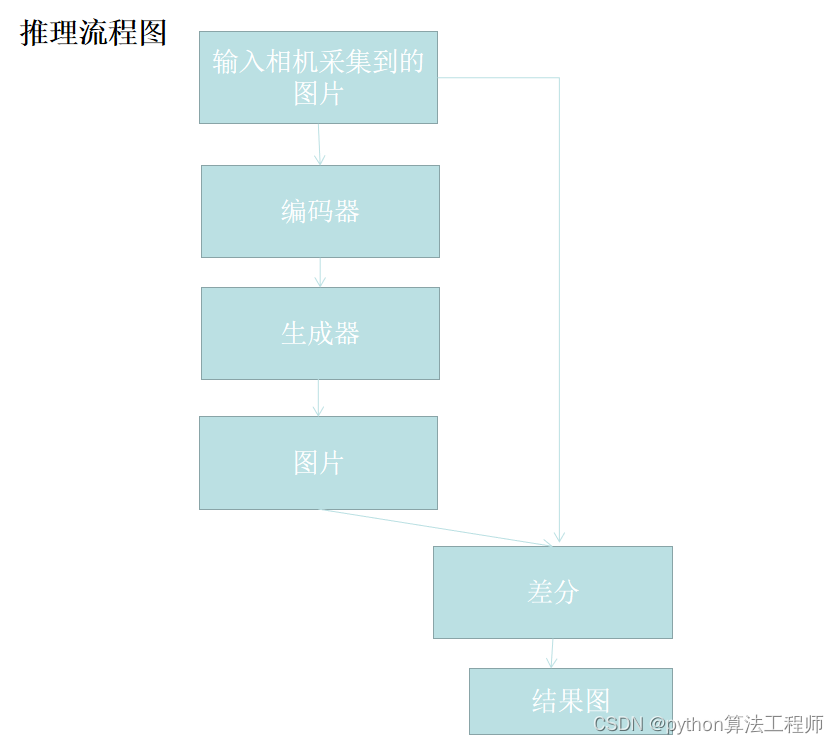
 使用bottle数据集,跑一下GAN的生成器、编码器的训练,以及encoder的训练,
使用bottle数据集,跑一下GAN的生成器、编码器的训练,以及encoder的训练,
然后跑一下推理部分的代码
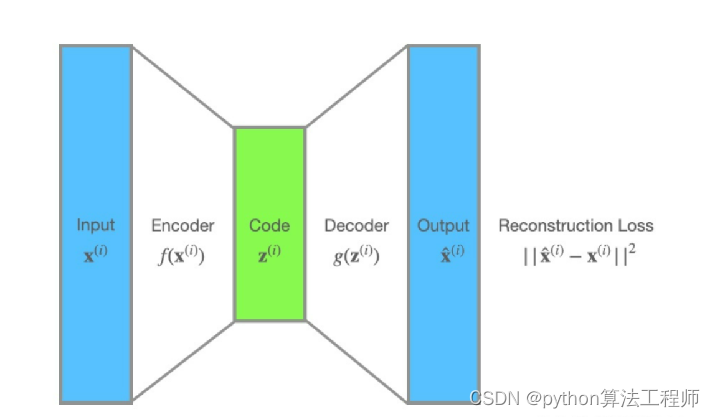
自编码器
自编码器(Autoencoder)是一种无监督学习的神经网络模型,其主要目的是将输入数据压缩到一个低维空间中,并通过解码器将其重构回原始空间。自编码器通常由编码器和解码器两部分组成,其中编码器将输入数据压缩到一个低维空间中,解码器将低维空间的表示解码回原始空间。
自编码器的训练过程包括两个阶段:编码器的训练和解码器的训练。在编码器的训练阶段,输入数据通过编码器被压缩到一个低维空间中,损失函数通常表示为重构误差(Reconstruction Error),即解码器重构出的图像与原始图像之间的差异程度。在解码器的训练阶段,低维空间的表示通过解码器被解码回原始空间,损失函数同样表示为重构误差。
自编码器的主要应用包括数据压缩、特征提取、数据去噪、图像生成等领域。其中,由于自编码器的编码器部分可以将输入数据压缩到一个低维空间中,因此自编码器常常被用于数据降维和特征提取。此外,由于自编码器可以从损坏的数据中恢复出原始数据,因此自编码器还可以被用于数据去噪。另外,变分自编码器(Variational Autoencoder,VAE)等自编码器的变体还可以用于图像生成等任务。
总的来说,自编码器是一种非常灵活的模型,可以在许多领域中发挥作用。
 CelebA数据集
CelebA数据集
CelebA是CelebFaces Attribute的缩写,意即名人人脸属性数据集,其包含10,177个名人身份的202,599张人脸图片,每张图片都做好了特征标记,包含人脸bbox标注框、5个人脸特征点坐标以及40个属性标记,CelebA由香港中文大学开放提供,广泛用于人脸相关的计算机视觉训练任务,可用于人脸属性标识训练、人脸检测训练以及landmark标记等
 40多个属性
40多个属性

变分自编码器(VAE)和条件变分自编码器(CVAE)是一种基于神经网络的生成模型,用于生成高维数据,例如图像。VAE和CVAE都是一种自动编码器的扩展,它们可以学习数据的潜在表示,并用这些表示来生成新的样本。
VAE和CVAE的主要区别在于,CVAE可以生成特定类别的样本,而不仅仅是从整个数据集中生成样本。这是通过在输入中提供类别信息来实现的,使得模型能够学习将特定类别的样本映射到特定的潜在空间区域中。
在训练过程中,VAE和CVAE都利用了变分推理来估计潜在变量的后验分布,并最大化训练数据的边缘似然。VAE和CVAE的主要区别在于它们如何计算KL散度项,这是用于惩罚潜在变量的后验分布与先验分布之间的差异的一种方法。在CVAE中,KL散度项还包括一个附加项,用于惩罚类别信息与潜在变量之间的差异。
在MNIST数据集上训练VAE和CVAE,可以看到它们都能够学习到有效的数据表示,并生成具有可信度的新样本。通过比较VAE和CVAE的结果,可以发现CVAE能够更好地控制生成的样本的类别。不过,需要注意的是,这些结果是使用默认超参数设置和未经过调整的,因此可以进一步优化性能。
VAE paper: Auto-Encoding Variational Bayes
CVAE paper: Learning Structured Output Representation using Deep Conditional Generative Models
使用minist训练VAE网络,了解VAE的模型结构和损失函数;
可以尝试调整KL损失和重建损失的占比,观察对生成效果的影响
models.py
import torch
import torch.nn as nn
from utils import idx2onehot
class VAE(nn.Module):
def __init__(self, encoder_layer_sizes, latent_size, decoder_layer_sizes,
conditional=False, num_labels=0):
super().__init__()
if conditional:
assert num_labels > 0
assert type(encoder_layer_sizes) == list
assert type(latent_size) == int
assert type(decoder_layer_sizes) == list
self.latent_size = latent_size
self.encoder = Encoder(
encoder_layer_sizes, latent_size, conditional, num_labels)
self.decoder = Decoder(
decoder_layer_sizes, latent_size, conditional, num_labels)
def forward(self, x, c=None):
if x.dim() > 2:
x = x.view(-1, 28*28)
means, log_var = self.encoder(x, c)
z = self.reparameterize(means, log_var)
recon_x = self.decoder(z, c)
return recon_x, means, log_var, z
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
def inference(self, z, c=None):
recon_x = self.decoder(z, c)
return recon_x
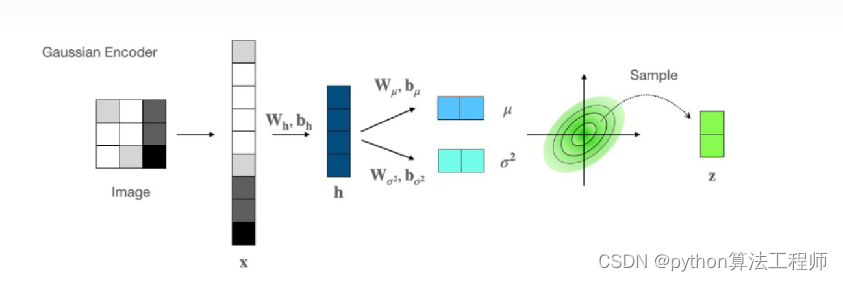
class Encoder(nn.Module):
def __init__(self, layer_sizes, latent_size, conditional, num_labels):
super().__init__()
self.conditional = conditional
if self.conditional:
layer_sizes[0] += num_labels
self.MLP = nn.Sequential()
for i, (in_size, out_size) in enumerate(zip(layer_sizes[:-1], layer_sizes[1:])):
self.MLP.add_module(
name="L{:d}".format(i), module=nn.Linear(in_size, out_size))
self.MLP.add_module(name="A{:d}".format(i), module=nn.ReLU())
self.linear_means = nn.Linear(layer_sizes[-1], latent_size)
self.linear_log_var = nn.Linear(layer_sizes[-1], latent_size)
def forward(self, x, c=None):
if self.conditional:
c = idx2onehot(c, n=10)
x = torch.cat((x, c), dim=-1)
x = self.MLP(x)
means = self.linear_means(x)
log_vars = self.linear_log_var(x)
return means, log_vars
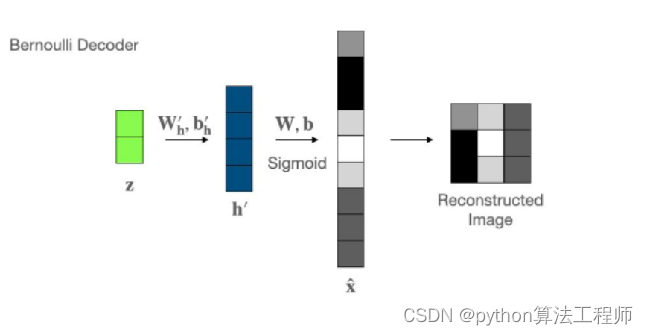
class Decoder(nn.Module):
def __init__(self, layer_sizes, latent_size, conditional, num_labels):
super().__init__()
self.MLP = nn.Sequential()
self.conditional = conditional
if self.conditional:
input_size = latent_size + num_labels
else:
input_size = latent_size
for i, (in_size, out_size) in enumerate(zip([input_size]+layer_sizes[:-1], layer_sizes)):
self.MLP.add_module(
name="L{:d}".format(i), module=nn.Linear(in_size, out_size))
if i+1 < len(layer_sizes):
self.MLP.add_module(name="A{:d}".format(i), module=nn.ReLU())
else:
self.MLP.add_module(name="sigmoid", module=nn.Sigmoid())
def forward(self, z, c):
if self.conditional:
c = idx2onehot(c, n=10)
z = torch.cat((z, c), dim=-1)
x = self.MLP(z)
return x
这是一个用于实现变分自编码器(VAE)和条件变分自编码器(CVAE)的PyTorch模型类。VAE和CVAE都有一个编码器和一个解码器,分别用于将输入数据映射到潜在空间(编码器)和将潜在表示映射回原始数据空间(解码器)。VAE和CVAE的主要区别在于编码器如何处理条件信息(如果有的话),以及如何计算KL散度项。
在这个模型类中,编码器和解码器都是用多层感知机(MLP)来实现的。编码器将输入数据和条件信息(如果有的话)映射到均值和方差,用于计算KL散度项,而解码器则将潜在表示和条件信息(如果有的话)映射回原始数据空间。
需要注意的是,这个模型类是用于处理MNIST数据集的,因此输入和输出的形状都是28x28的图像。如果要使用它来处理其他类型的数据,可能需要对MLP的结构进行调整。
此外,这个模型类还有几个重要的方法:
forward(x, c=None): 这个方法用于计算模型的前向传播,给定输入x(和条件信息c,如果有的话),它返回重构的数据recon_x、均值means、方差log_var和潜在表示z。
reparameterize(mu, log_var): 这个方法用于从均值mu和方差log_var中采样一个潜在表示z。由于反向传播无法通过随机采样进行传递,因此这个方法使用了“重参数化技巧”(reparameterization trick)来将随机性从潜在表示中分离出来。
inference(z, c=None): 这个方法用于生成给定潜在表示z(和条件信息c,如果有的话)的重构数据recon_x。
在模型的构造函数中,encoder_layer_sizes、decoder_layer_sizes和latent_size分别指定了编码器和解码器的MLP层的大小和潜在空间的维度。conditional和num_labels指定了模型是否是条件的,以及条件信息的大小。如果是条件的,则num_labels指定了条件信息的大小,例如在本例中,num_labels是10,因为MNIST数据集有10个类别。
最后,这个模型类还假设了一个辅助函数idx2onehot,用于将整数标签转换为one-hot编码。这个函数没有在代码中给出,但可以根据需要轻松实现。
总的来说,这个模型类提供了实现VAE和CVAE所需的基本组件,并可以通过调整MLP的结构和调整latent_size等超参数来进行个性化的修改。例如,可以通过增加或减少MLP层的数量和大小来调整模型的复杂度,或者通过改变latent_size的大小来控制潜在表示的维度。需要注意的是,VAE和CVAE是一种强大的生成模型,但也有一些限制。例如,它们假设输入数据是连续的,并且对于离散数据(如文本),需要进行一些特殊的处理。此外,它们还面临着训练和推断的挑战,例如如何有效地计算KL散度项和如何在潜在空间中进行插值和采样等问题。因此,在实践中,需要仔细调整超参数和选择合适的优化器和学习率等参数来获得最佳的性能和效果。
train.py
import os
import time
import torch
import argparse
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from collections import defaultdict
from models import VAE
def main(args):
torch.manual_seed(args.seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(args.seed)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
ts = time.time()
dataset = MNIST(
root=r'D:\BaiduNetdiskDownload\mnist', train=True, transform=transforms.ToTensor(),
download=True)
data_loader = DataLoader(
dataset=dataset, batch_size=args.batch_size, shuffle=True)
def loss_fn(recon_x, x, mean, log_var):
BCE = torch.nn.functional.binary_cross_entropy(
recon_x.view(-1, 28*28), x.view(-1, 28*28), reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mean.pow(2) - log_var.exp())
return (BCE + KLD) / x.size(0)
vae = VAE(
encoder_layer_sizes=args.encoder_layer_sizes,
latent_size=args.latent_size,
decoder_layer_sizes=args.decoder_layer_sizes,
conditional=args.conditional,
num_labels=10 if args.conditional else 0).to(device)
optimizer = torch.optim.Adam(vae.parameters(), lr=args.learning_rate)
logs = defaultdict(list)
for epoch in range(args.epochs):
tracker_epoch = defaultdict(lambda: defaultdict(dict))
for iteration, (x, y) in enumerate(data_loader):
x, y = x.to(device), y.to(device)
if args.conditional:
recon_x, mean, log_var, z = vae(x, y)
else:
recon_x, mean, log_var, z = vae(x)
for i, yi in enumerate(y):
id = len(tracker_epoch)
tracker_epoch[id]['x'] = z[i, 0].item()
tracker_epoch[id]['y'] = z[i, 1].item()
tracker_epoch[id]['label'] = yi.item()
loss = loss_fn(recon_x, x, mean, log_var)
optimizer.zero_grad()
loss.backward()
optimizer.step()
logs['loss'].append(loss.item())
if iteration % args.print_every == 0 or iteration == len(data_loader)-1:
print("Epoch {:02d}/{:02d} Batch {:04d}/{:d}, Loss {:9.4f}".format(
epoch, args.epochs, iteration, len(data_loader)-1, loss.item()))
if args.conditional:
c = torch.arange(0, 10).long().unsqueeze(1).to(device)
z = torch.randn([c.size(0), args.latent_size]).to(device)
x = vae.inference(z, c=c)
else:
z = torch.randn([10, args.latent_size]).to(device)
x = vae.inference(z)
plt.figure()
plt.figure(figsize=(5, 10))
for p in range(10):
plt.subplot(5, 2, p+1)
if args.conditional:
plt.text(
0, 0, "c={:d}".format(c[p].item()), color='black',
backgroundcolor='white', fontsize=8)
plt.imshow(x[p].view(28, 28).cpu().data.numpy())
plt.axis('off')
if not os.path.exists(os.path.join(args.fig_root, str(ts))):
if not(os.path.exists(os.path.join(args.fig_root))):
os.mkdir(os.path.join(args.fig_root))
os.mkdir(os.path.join(args.fig_root, str(ts)))
plt.savefig(
os.path.join(args.fig_root, str(ts),
"E{:d}I{:d}.png".format(epoch, iteration)),
dpi=300)
plt.clf()
plt.close('all')
df = pd.DataFrame.from_dict(tracker_epoch, orient='index')
g = sns.lmplot(
x='x', y='y', hue='label', data=df.groupby('label').head(100),
fit_reg=False, legend=True)
g.savefig(os.path.join(
args.fig_root, str(ts), "E{:d}-Dist.png".format(epoch)),
dpi=300)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--seed", type=int, default=0)
parser.add_argument("--epochs", type=int, default=10)
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--learning_rate", type=float, default=0.001)
parser.add_argument("--encoder_layer_sizes", type=list, default=[784, 256])
parser.add_argument("--decoder_layer_sizes", type=list, default=[256, 784])
parser.add_argument("--latent_size", type=int, default=2)
parser.add_argument("--print_every", type=int, default=100)
parser.add_argument("--fig_root", type=str, default='figs')
parser.add_argument("--conditional", action='store_true')
args = parser.parse_args()
main(args)
这段代码实现了一个基于PyTorch的VAE模型,并使用MNIST数据集进行训练和可视化。其中,VAE模型的结构定义在models.py文件中,包括encoder和decoder的MLP层大小、潜在表示的维度大小以及是否是条件VAE。在训练过程中,使用Adam优化器和二次重建误差加上KL散度项的损失函数进行优化。同时,每隔一定的迭代次数或者每个epoch结束时,会输出当前epoch和batch的loss,并生成一些随机样本图片和潜在空间分布图,保存在fig_root路径下。
需要注意的是,这段代码中的VAE模型是在CPU或GPU上进行训练的,具体取决于设备的可用性。如果当前设备支持GPU,那么代码会自动将模型和数据移动到GPU上进行计算,从而加速训练过程。此外,该代码还包含了一些超参数,例如learning_rate、batch_size等,可以根据实际情况进行调整。
在训练过程中,每个batch的数据会被加载到data_loader中,然后传递给VAE模型进行前向计算和反向传播更新梯度。同时,也会记录下每个样本的潜在表示和类别信息,用于可视化潜在空间分布图。在每个epoch结束时,会使用生成器(inference)生成一些随机的样本图片,用于直观地观察模型的生成效果。此外,还会绘制每个类别在潜在空间中的分布图,用于分析模型对不同类别的区分能力。
总的来说,这段代码提供了一个基本的VAE模型训练和可视化的框架,可以用于MNIST数据集的实验和其他类似的应用。同时,也可以根据需要进行扩展和修改,例如使用其他数据集、调整模型结构等。
utils.py
import torch
def idx2onehot(idx, n):
assert torch.max(idx).item() < n
if idx.dim() == 1:
idx = idx.unsqueeze(1)
onehot = torch.zeros(idx.size(0), n).to(idx.device)
onehot.scatter_(1, idx, 1)
return onehot
这段代码定义了一个函数
idx2onehot,用于将一个包含类别索引的张量转换为对应的one-hot编码张量。具体实现过程如下:
首先,使用
assert语句确保输入的类别索引张量中的最大值小于n,即类别总数。如果输入的类别索引张量是一维的,那么使用
unsqueeze函数将其转换为二维张量(行数为原来的长度,列数为1)。创建一个大小为
(idx.size(0), n)的全零张量onehot,其中idx.size(0)表示输入张量的行数,即样本数量。使用
scatter_函数将onehot中的每一行对应到输入张量中的一个元素上,将该元素的值赋为1,其他位置保持为0。具体来说,scatter_(1, idx, 1)表示在第1个维度(即列)上根据idx中的值进行索引,将对应位置上的值赋为1。返回转换后的one-hot编码张量
onehot。这个函数的主要作用是将类别索引转换为对应的one-hot编码,可以用于训练分类模型时将标签转换为模型可以处理的形式。


 最大后验概率
最大后验概率
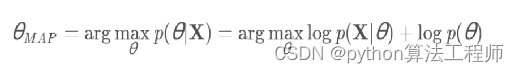
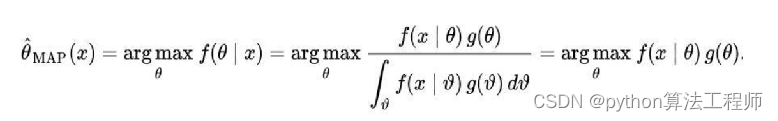

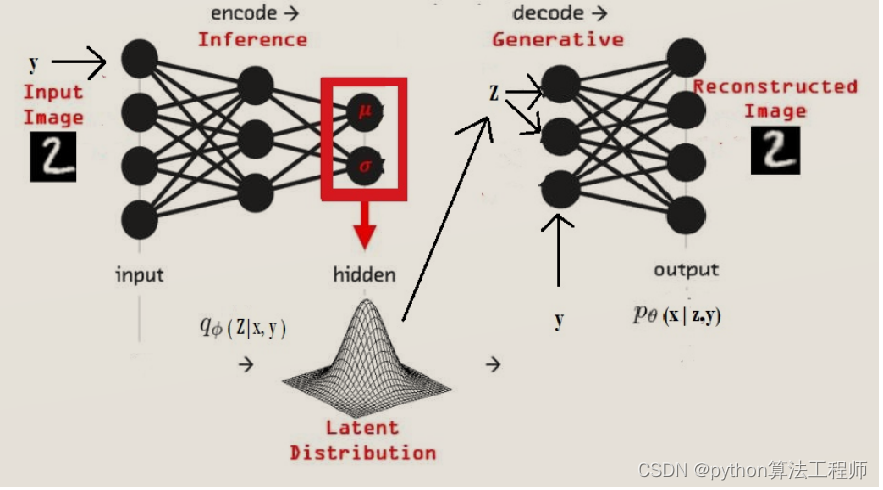
VAE网络结构图
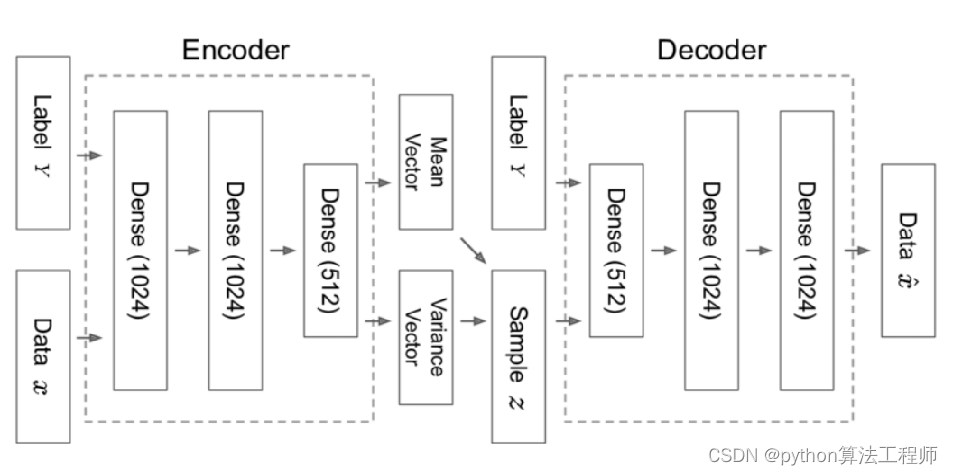
CVAE网络结构图
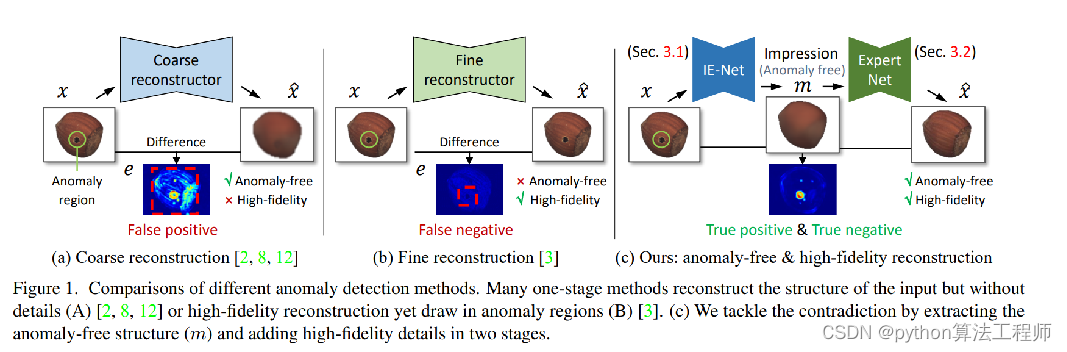
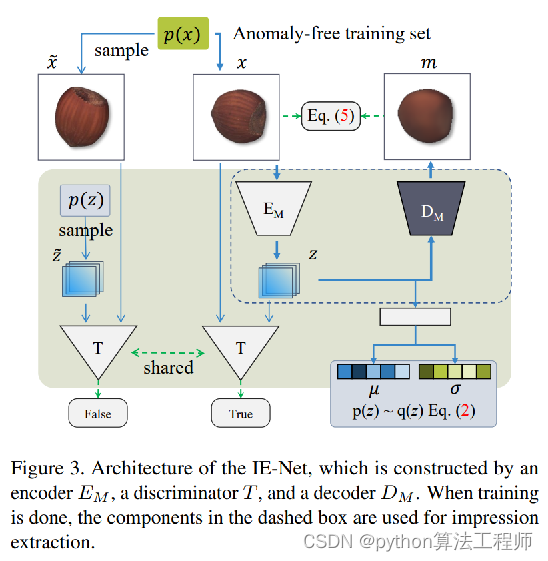
Unsupervised Two-Stage Anomaly Detection
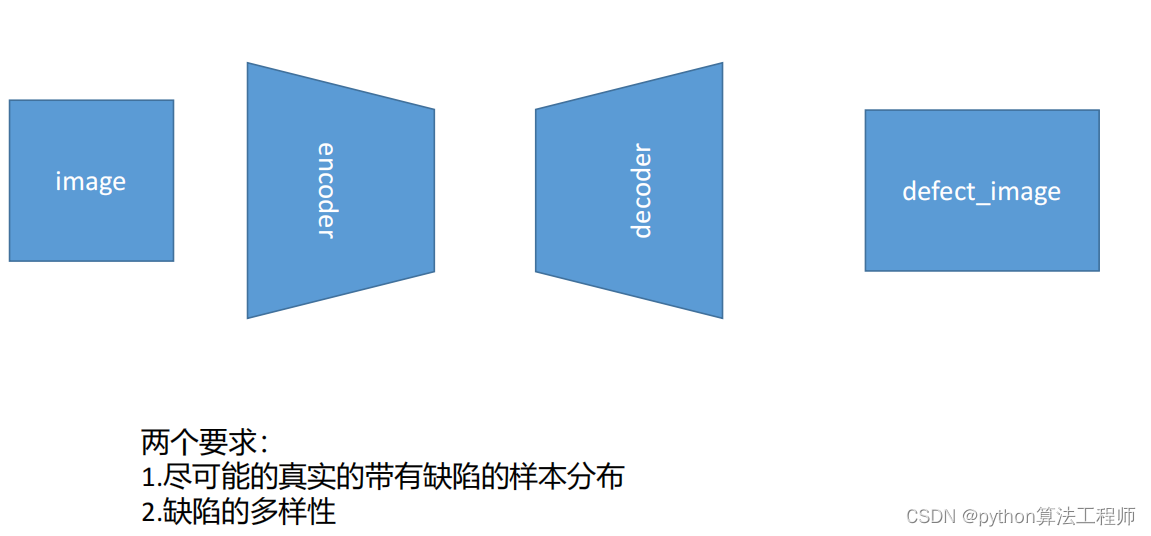
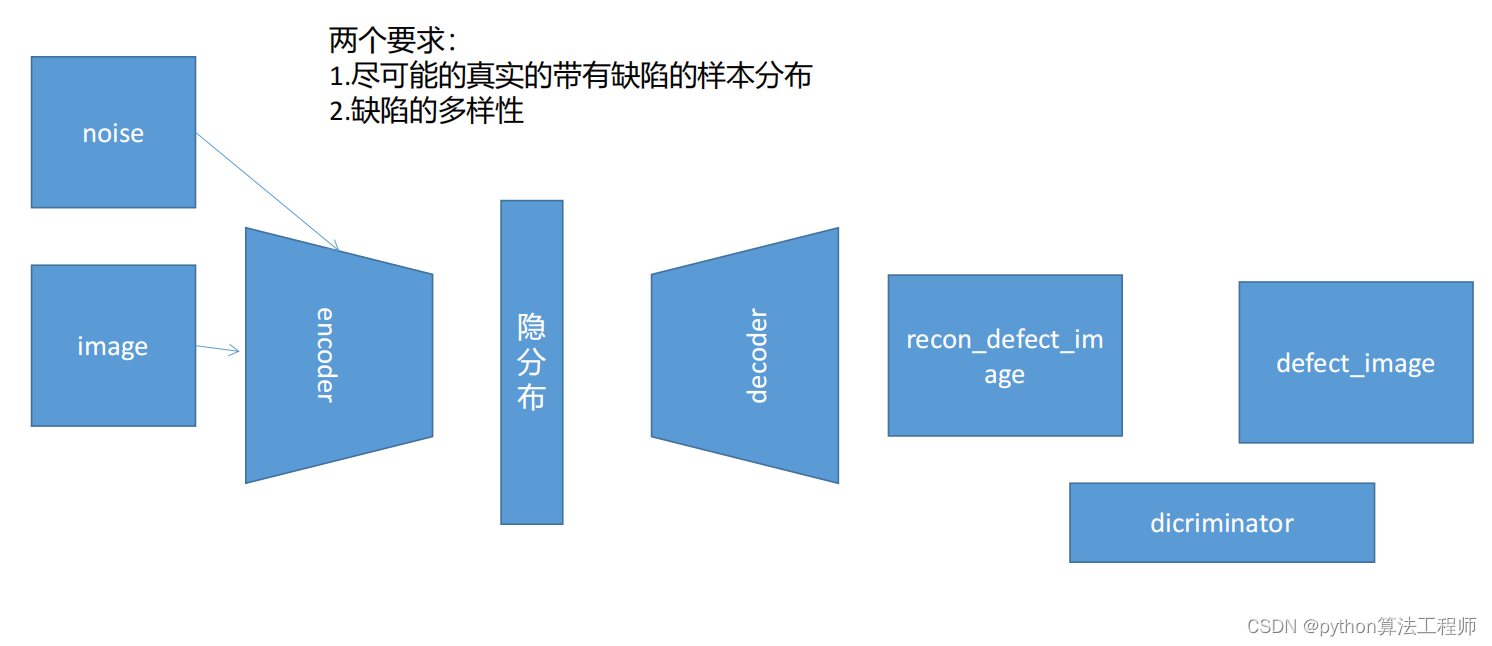
目前多数异常检测存在的问题:
1.如果是粗略重建,可能会引入额外的图片差异导致缺陷的误检;
2.在一些从参数量大,高精度的重建当中,可能会引入异常或者丢失异常相关的不同;
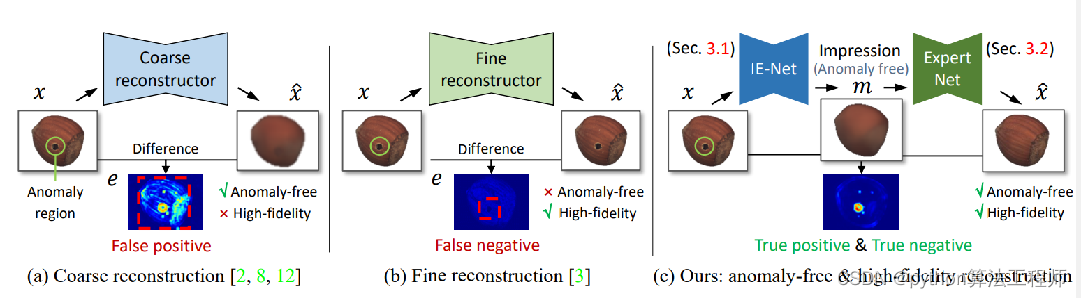
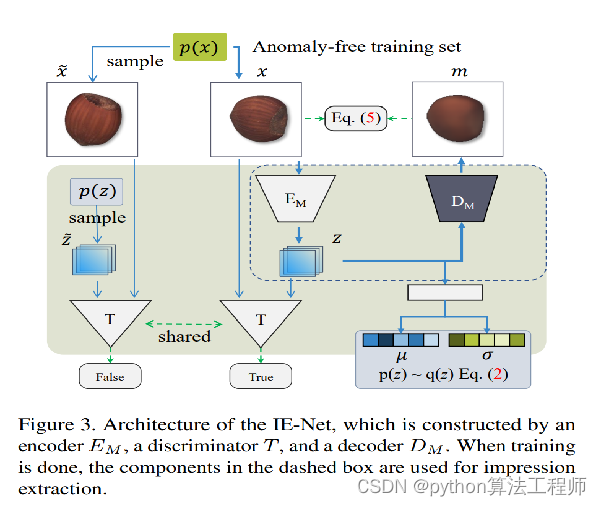

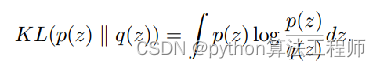

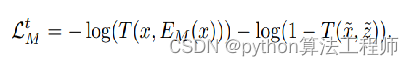
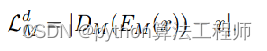
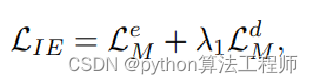
任务:
以课授VAE代码为原始基础,用CVAE训练瓶口和电缆数据集,
让CVAE训练好的decoder可以根据输入0还是1分别生成瓶口或者电缆
备注:
必要步骤:
1.需要编写数据加载模块,需要加载图片和label
可以让瓶口label=>1
电缆label=>2
可尝试的其他步骤:
2.可以尝试更改latent_size更改高斯分布的个数
3.可以尝试修改主干网络的MLP=>CNN增加网络复杂度提升拟合性能
数据集:AD_dataset
原始的基准代码:VAE-CVAE-MNIST-master
可以参考的代码:refer_code
AD_dataset.py
import os
import torch
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
import glob
import cv2
class AD_data(Dataset):
def __init__(self):
bottle_root=r"D:\BaiduNetdiskDownload\mvtec_anomaly_detection\bottle\train\good"
cable_root=r"D:\BaiduNetdiskDownload\mvtec_anomaly_detection\cable\train\good"
bottle_image_list=glob.glob(bottle_root+'\*.png')
bottle_label=np.zeros(len(bottle_image_list))
cable_image_list = glob.glob(cable_root + '\*.png')
cable_label = np.ones(len(cable_image_list))
bottle_image_list.extend(cable_image_list)
self.image_list=bottle_image_list
self.label_list=np.hstack((bottle_label,cable_label))
self.label_list=np.int32(self.label_list)
def __getitem__(self, item):
image_path=self.image_list[item]
label=self.label_list[item]
image=cv2.imread(image_path,0)
image=cv2.resize(image,(28,28))
image=(image/255.0-0.5)/0.5
image_Tensor=torch.from_numpy(image)
image_Tensor=image_Tensor.unsqueeze(0)
label=np.array([label])
label=np.int64(label)
label=torch.from_numpy(label)
return image_Tensor.float(),torch.LongTensor(label)
def __len__(self):
return len(self.image_list)
train_cvae_AD.py
import os
import time
import torch
import argparse
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from collections import defaultdict
from AD_dataset import AD_data
from models import VAE
def main(args):
torch.manual_seed(args.seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(args.seed)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
ts = time.time()
dataset = AD_data()
data_loader = DataLoader(
dataset=dataset, batch_size=args.batch_size, shuffle=True)
def loss_fn(recon_x, x, mean, log_var):
BCE = torch.nn.functional.binary_cross_entropy(
recon_x.view(-1, 28*28), x.view(-1, 28*28), reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mean.pow(2) - log_var.exp())
return (BCE + KLD) / x.size(0)
vae = VAE(
encoder_layer_sizes=args.encoder_layer_sizes,
latent_size=args.latent_size,
decoder_layer_sizes=args.decoder_layer_sizes,
conditional=args.conditional,
num_labels=10 if args.conditional else 0).to(device)
optimizer = torch.optim.Adam(vae.parameters(), lr=args.learning_rate)
logs = defaultdict(list)
for epoch in range(args.epochs):
tracker_epoch = defaultdict(lambda: defaultdict(dict))
for iteration, (x, y) in enumerate(data_loader):
x, y = x.to(device), y.to(device)
if args.conditional:
recon_x, mean, log_var, z = vae(x, y)
else:
recon_x, mean, log_var, z = vae(x)
#记录每个样本采样出来的z值和对应的标签
for i, yi in enumerate(y):
id = len(tracker_epoch)
tracker_epoch[id]['x'] = z[i, 0].item()
tracker_epoch[id]['y'] = z[i, 1].item()
tracker_epoch[id]['label'] = yi.item()
loss = loss_fn(recon_x, x, mean, log_var)
optimizer.zero_grad()
loss.backward()
optimizer.step()
logs['loss'].append(loss.item())
#每经过100次迭代就记录以下日志
if iteration % args.print_every == 0 or iteration == len(data_loader)-1:
print("Epoch {:02d}/{:02d} Batch {:04d}/{:d}, Loss {:9.4f}".format(
epoch, args.epochs, iteration, len(data_loader)-1, loss.item()))
if args.conditional:
c = torch.arange(0, 10).long().unsqueeze(1).to(device)
z = torch.randn([c.size(0), args.latent_size]).to(device)
x = vae.inference(z, c=c)
else:
z = torch.randn([10, args.latent_size]).to(device)
x = vae.inference(z)
plt.figure()
plt.figure(figsize=(5, 10))
for p in range(10):
plt.subplot(5, 2, p+1)
if args.conditional:
plt.text(
0, 0, "c={:d}".format(c[p].item()), color='black',
backgroundcolor='white', fontsize=8)
plt.imshow(x[p].view(28, 28).cpu().data.numpy())
plt.axis('off')
if not os.path.exists(os.path.join(args.fig_root, str(ts))):
if not(os.path.exists(os.path.join(args.fig_root))):
os.mkdir(os.path.join(args.fig_root))
os.mkdir(os.path.join(args.fig_root, str(ts)))
plt.savefig(
os.path.join(args.fig_root, str(ts),
"E{:d}I{:d}.png".format(epoch, iteration)),
dpi=300)
plt.clf()
plt.close('all')
torch.save(vae.state_dict(),str(epoch)+'.pth')
df = pd.DataFrame.from_dict(tracker_epoch, orient='index')
g = sns.lmplot(
x='x', y='y', hue='label', data=df.groupby('label').head(100),
fit_reg=False, legend=True)
g.savefig(os.path.join(
args.fig_root, str(ts), "E{:d}-Dist.png".format(epoch)),
dpi=300)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--seed", type=int, default=0)
parser.add_argument("--epochs", type=int, default=10)
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--learning_rate", type=float, default=0.001)
parser.add_argument("--encoder_layer_sizes", type=list, default=[784, 256])
parser.add_argument("--decoder_layer_sizes", type=list, default=[256, 784])
parser.add_argument("--latent_size", type=int, default=6)
parser.add_argument("--print_every", type=int, default=100)
parser.add_argument("--fig_root", type=str, default='figs')
parser.add_argument("--conditional",default=True, action='store_true')
args = parser.parse_args()
main(args)
test_cvae_AD.py
import os
import time
import torch
import argparse
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from collections import defaultdict
from AD_dataset import AD_data
from models import VAE
def main(args):
torch.manual_seed(args.seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(args.seed)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
vae = VAE(
encoder_layer_sizes=args.encoder_layer_sizes,
latent_size=args.latent_size,
decoder_layer_sizes=args.decoder_layer_sizes,
conditional=args.conditional,
num_labels=10 if args.conditional else 0).to(device)
vae.load_state_dict(torch.load(r'AD_weights_four_gaussian/9.pth'))
vae.eval()
for i in range(10):
with torch.no_grad():
c = torch.arange(0, 2).long().unsqueeze(1).to(device)
z = torch.randn([c.size(0), args.latent_size]).to(device)
x = vae.inference(z, c=c)
for p in range(2):
plt.figure()
if args.conditional:
plt.text(
0, 0, "c={:d}".format(c[p].item()), color='black',
backgroundcolor='white', fontsize=8)
plt.imshow(x[p].view(28, 28).cpu().data.numpy())
plt.axis('off')
plt.savefig(str(i)+"-"+str(c[p].item())+'.png')
# if not os.path.exists(os.path.join(args.fig_root, str(ts))):
# if not(os.path.exists(os.path.join(args.fig_root))):
# os.mkdir(os.path.join(args.fig_root))
# os.mkdir(os.path.join(args.fig_root, str(ts)))
plt.clf()
plt.close('all')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--seed", type=int, default=0)
parser.add_argument("--epochs", type=int, default=10)
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--learning_rate", type=float, default=0.001)
parser.add_argument("--encoder_layer_sizes", type=list, default=[784, 256])
parser.add_argument("--decoder_layer_sizes", type=list, default=[256, 784])
parser.add_argument("--latent_size", type=int, default=6)
parser.add_argument("--print_every", type=int, default=100)
parser.add_argument("--fig_root", type=str, default='figs')
parser.add_argument("--conditional",default=True, action='store_true')
args = parser.parse_args()
main(args)
任务:
以课授VAE代码为原始基础,用CVAE训练瓶口和电缆数据集,
让CVAE训练好的decoder可以根据输入0还是1分别生成瓶口或者电缆
备注:
必要步骤:
1.需要编写数据加载模块,需要加载图片和label
可以让瓶口label=>1
电缆label=>2
可尝试的其他步骤:
2.可以尝试更改latent_size更改高斯分布的个数
3.可以尝试修改主干网络的MLP=>CNN增加网络复杂度提升拟合性能
数据集:AD_dataset
原始的基准代码:VAE-CVAE-MNIST-master
可以参考的代码:refer_code
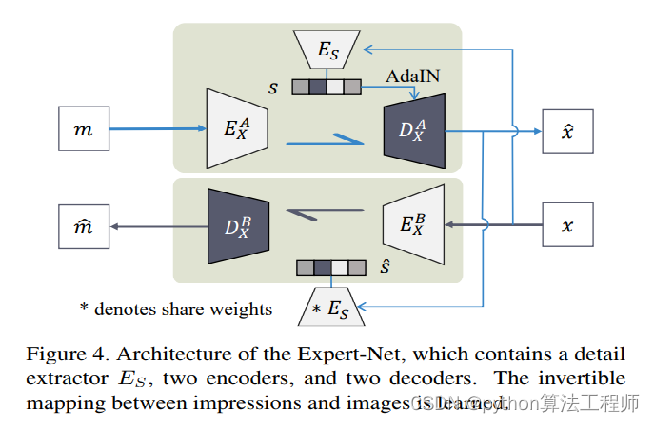
pytorch-AdaIN
BatchNormlization
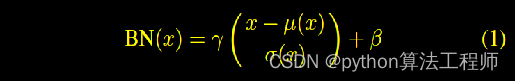
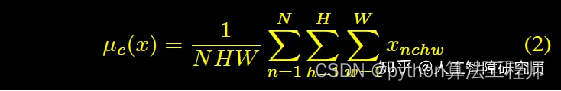
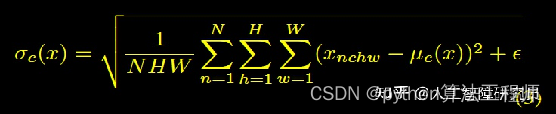

InstanceNormlization
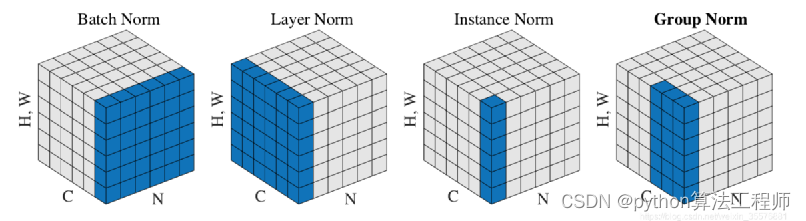
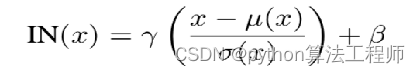
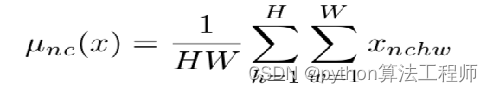
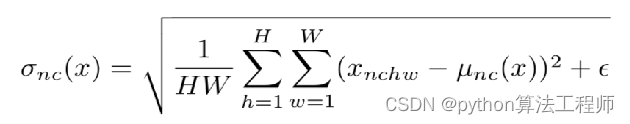
AdaIN:Adaptive Instance Normalization
AdaIN和IN的不同在于仿射参数来自于样本,即作为条件的样本,也就是说AadIN没有需要学习的参数,这和BN,IN,LN,GN都不同。
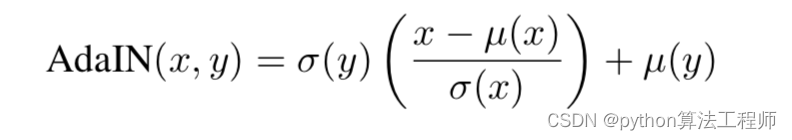




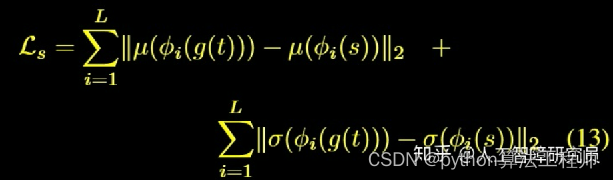
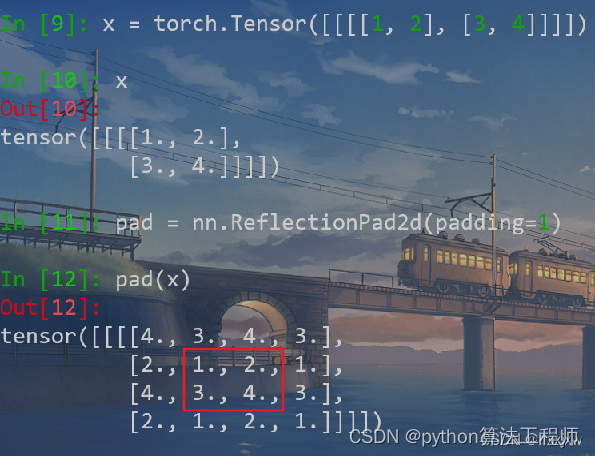
镜像填充nn.ReflectionPad2d
 常用于风格迁移
常用于风格迁移
预测边界区域的时候就提供了上下文信息
Unsupervised Two-Stage Anomaly Detection(UTAD)
IENet
ExpertNet
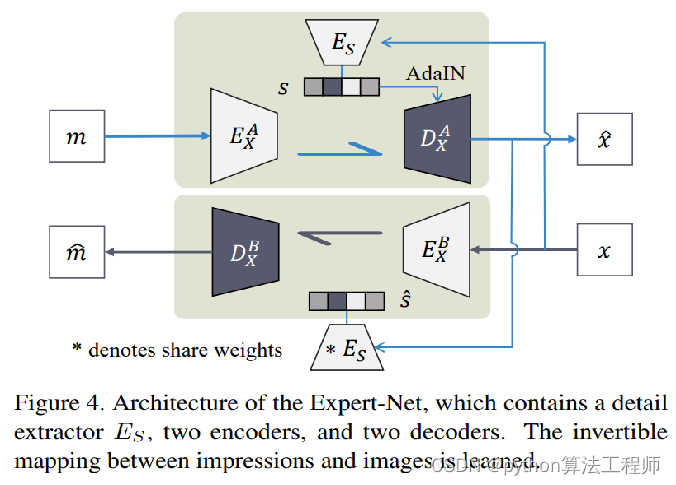
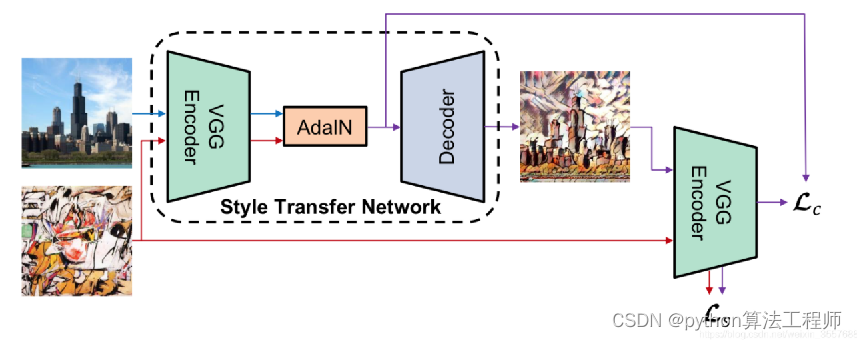
跑一下代码,debug出Adain train.py的流程,并绘制网络训练的结构图,
帮助自己更好地理解该网络;
https://github.com/xunhuang1995/AdaIN-style
感谢分享这个非官方的 PyTorch 实现 Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization [Huang+, ICCV2017]。这是一种非常有用的技术,可以将一张图片的风格转移到另一张图片的内容上。
要使用这个实现,首先需要安装 requirements.txt 文件中列出的所需软件包。您还需要下载预训练的模型:decoder.pth 和 vgg_normalized.pth,并将它们保存在 models/ 目录下。
要在单个内容图像和单个风格图像上测试模型,您可以使用 test.py 脚本。使用 --content 和 --style 选项提供内容和风格图像的路径。例如:
CUDA_VISIBLE_DEVICES=<gpu_id> python test.py --content input/content/cornell.jpg --style input/style/woman_with_hat_matisse.jpg
要在内容图像和风格图像的目录上测试模型,您可以使用 --content_dir 和 --style_dir 选项。这将保存每个内容图像和风格图像组合到输出目录中。例如:
CUDA_VISIBLE_DEVICES=<gpu_id> python test.py --content_dir input/content --style_dir input/style
您还可以通过指定 --style 和 --style_interpolation_weights 选项来混合多个风格。例如:
CUDA_VISIBLE_DEVICES=<gpu_id> python test.py --content input/content/avril.jpg --style input/style/picasso_self_portrait.jpg,input/style/impronte_d_artista.jpg,input/style/trial.jpg,input/style/antimonocromatismo.jpg --style_interpolation_weights 1,1,1,1 --content_size 512 --style_size 512 --crop
还有其他选项可以使用,例如 --content_size、–style_size、–alpha 和 --preserve_color。您可以参考 --help 选项获取更多详细信息和参数。
如果您想训练自己的模型,可以使用 train.py 脚本。使用 --content_dir 和 --style_dir 选项提供内容和风格图像的目录。例如:
CUDA_VISIBLE_DEVICES=<gpu_id> python train.py --content_dir <content_dir> --style_dir <style_dir>
感谢您分享这个实现!这是一个有用的工具,对于任何对使用 AdaIN 进行风格转移感兴趣的人来说都是有用的。
Semi-Supervised Adversarial Variational Autoencoder 半监督对抗变分自编码器
们提出了一种提高重建和生成性能的方法
通过注入对抗性学习的变分自动编码器(VAE)。而不是比较
用原始数据重建来计算重建损失,我们使用一致性原则
对于深层特征。主要贡献有三方面。首先,我们的方法完美地结合了
两种模型,即GAN和VAE,从而提高了生成和重建性能
VAE 的。其次,VAE 训练分两步完成,允许分离约束
一方面用于构建潜在空间,另一方面用于训练
解码器。通过使用这个两步学习过程,我们的方法可以更广泛地应用于应用
除了图像处理。在训练编码器时,将标签信息集成到
以监督的方式更好地构建潜在空间。第三个贡献是使用经过训练的
用于从隐藏层提取的深层特征的一致性原则的编码器。我们提出
实验结果表明,我们的方法比原始 VAE 具有更好的性能。
结果表明,对抗性约束允许解码器生成图像
比传统的 VAE 更加真实和真实。

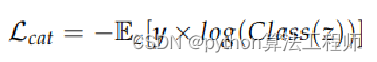
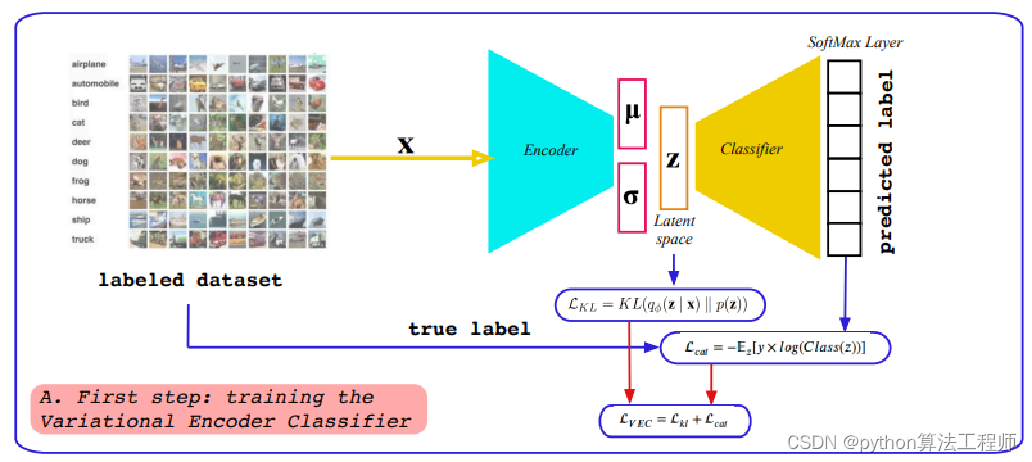 在以往的CVAE当中,仅仅是对z的隐分布进行了KL散度限制,在这里,我们希望通过classifier进行z进行上采样可以获取分类的信息
在以往的CVAE当中,仅仅是对z的隐分布进行了KL散度限制,在这里,我们希望通过classifier进行z进行上采样可以获取分类的信息
Encoder的损失是两个:KL散度损失+分类的损失
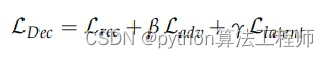
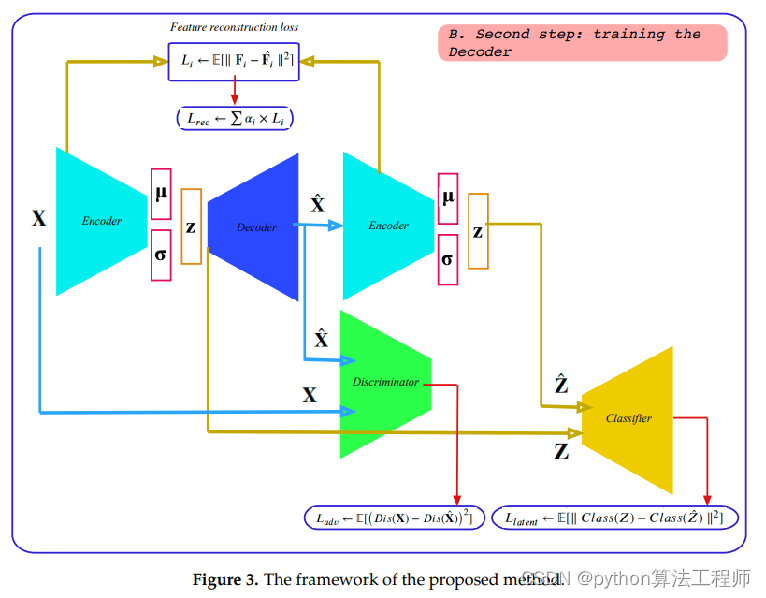
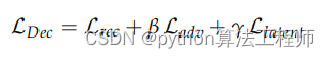

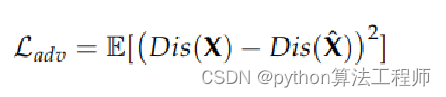
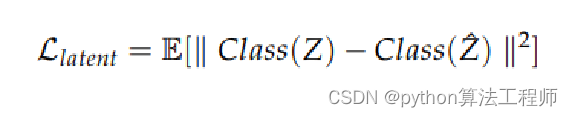
将重建损失巧妙地体现在判别器的损失上;
然后z分布和重建后的z分布也是体现在classifier的输出上


TULIP

KLA
 https://www.kla.com/products/instruments/defect-inspectors/candela-8420
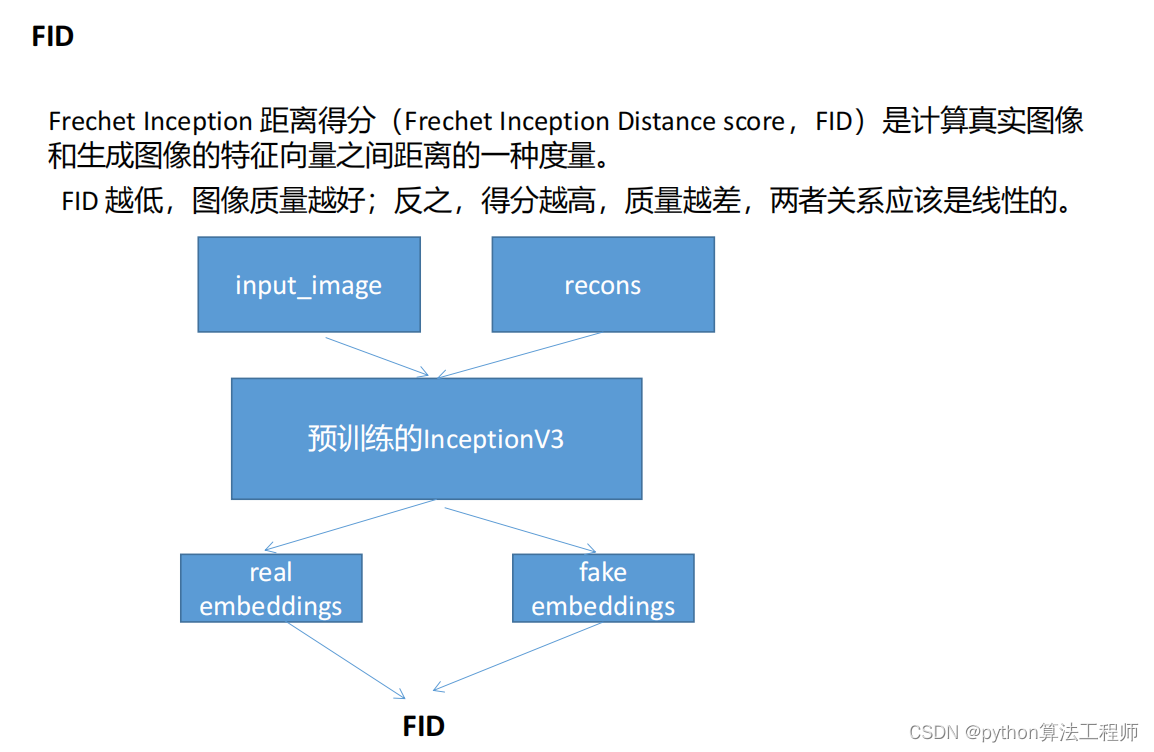
https://www.kla.com/products/instruments/defect-inspectors/candela-8420

 运行风格迁移test.py脚本
运行风格迁移test.py脚本








dataset.py
import torch
import torch.nn as nn
from torch.utils.model_zoo import tqdm
import cv2
import matplotlib.pyplot as plt
import numpy as np
import os,glob
import torch.optim as optim
import torchvision
class Dataset(nn.Module):
def __init__(self):
self.data_root=r"D:\BaiduNetdiskDownload\dongbeiData\NEU-CLS\NEU-CLS\C6_scratches"
self.files=glob.glob(self.data_root+"\*")
def __getitem__(self, item):
image_path=self.files[item]
image=cv2.imread(image_path)
image=cv2.resize(image,(128,128))
image_tensor=torch.from_numpy(image)
image_tensor = (image_tensor / 255 - 0.5) / 0.5
image_tensor=image_tensor.permute(2,1,0)
return image_tensor
def __len__(self):
return len(self.files)
train.py
import torch
import torch.nn as nn
from torch.utils.model_zoo import tqdm
import cv2
import matplotlib.pyplot as plt
import numpy as np
import os
import torch.optim as optim
import torchvision
from discriminator import Discriminator
from generate import Generator
from dataset import Dataset
from torch.utils.data import DataLoader
def force_cudnn_initialization():
s = 32
dev = torch.device('cuda')
torch.nn.functional.conv2d(torch.zeros(s, s, s, s, device=dev), torch.zeros(s, s, s, s, device=dev))
#训练的超参设计
#force_cudnn_initialization()
batch_size = 12
generator_depth = 64
discriminator_depth = 128
loss_function=nn.BCELoss().cpu()
number_of_epochs = 128
#---加载数据集
Neu_dataset=Dataset()
Neu_dataloader=DataLoader(Neu_dataset,batch_size,shuffle=True)
#网络构建
discriminator=Discriminator(1).cpu()
generator=Generator(1).cpu()
device = torch.device("cpu")#("cuda:0" if torch.cuda.is_available() else "cpu")
discriminator_optimizer = optim.Adam(discriminator.parameters(), lr=0.0004, betas=(0.5,0.999))
generator_optimizer = optim.Adam(generator.parameters(), lr=0.0001, betas=(0.5,0.999))
##---------begin train------------
for i in range(number_of_epochs):
for idx,batch in enumerate(Neu_dataloader):
# 训练判别器
#Training the discriminator with real images:
discriminator_optimizer.zero_grad()
prediction = discriminator(batch.cpu())
labels_for_dataset_images = torch.ones((batch_size,), device=device).view(-1)
loss_discriminator = loss_function(prediction.cpu().view(-1), labels_for_dataset_images)
loss_discriminator.backward()
print("D_real_loss:", loss_discriminator.item())
#Training the discriminator with the generated images from the generator:
random_noise = torch.randn(batch_size,100,1,1, device=device)
generated_image = generator(random_noise)
labels_for_generated_images = torch.zeros(np.prod(prediction.size()), device=device)
prediction = discriminator(generated_image.detach())
loss_generator = loss_function(prediction.view(-1), labels_for_generated_images)
loss_generator.backward()
print("D_fake_loss:",loss_generator.item())
discriminator_optimizer.step()
# 训练生成器
# Training the generator:
generator.zero_grad()
prediction = discriminator(generated_image).view(-1)
loss_generator = loss_function(prediction, labels_for_dataset_images)
loss_generator.backward()
generator_optimizer.step()
print("G_loss:", loss_generator.item())
print("epoch:",i,"iteration:",idx)
if(i%20==0):
torch.save(generator.state_dict(), str(i)+'generator.pt')
torch.save(discriminator.state_dict(), str(i)+'discriminator.pt')
generate.py
import torch
import torch.nn as nn
from torch.utils.model_zoo import tqdm
import cv2
import matplotlib.pyplot as plt
import numpy as np
import os
import torchvision
class Generator(nn.Module):
'''
The Generator Network. It is mostly a reversed discriminator with a random input noise which outputs an image.
'''
def __init__(self, number_of_gpus):
super(Generator, self).__init__()
self.ngpu = number_of_gpus
generator_depth = 64
self.layer1 = nn.Sequential(
nn.ConvTranspose2d(in_channels=100, out_channels=generator_depth * 16,
kernel_size=(4, 4), stride=1, padding=0, bias=False),
nn.BatchNorm2d(num_features=generator_depth * 16),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Sequential(
nn.ConvTranspose2d(in_channels=generator_depth * 16, out_channels=generator_depth * 8,
kernel_size=(4, 4), stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_features=generator_depth * 8),
nn.ReLU(inplace=True)
)
self.layer3 = nn.Sequential(
nn.ConvTranspose2d(in_channels=generator_depth * 8, out_channels=generator_depth * 4,
kernel_size=(4, 4), stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_features=generator_depth * 4),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.ConvTranspose2d(in_channels=generator_depth * 4, out_channels=generator_depth * 2,
kernel_size=(4, 4), stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_features=generator_depth * 2),
nn.ReLU(inplace=True)
)
self.layer5 = nn.Sequential(
nn.ConvTranspose2d(in_channels=generator_depth * 2, out_channels=generator_depth,
kernel_size=(4, 4), stride=2, padding=1, bias=False),
nn.BatchNorm2d(num_features=generator_depth),
nn.ReLU(inplace=True)
)
self.output_layer = nn.Sequential(
nn.ConvTranspose2d(in_channels=generator_depth, out_channels=3,
kernel_size=(4, 4), stride=2, padding=1, bias=False),
nn.Tanh()
)
def forward(self, input_noise):
layer1 = self.layer1(input_noise)
layer2 = self.layer2(layer1)
layer3 = self.layer3(layer2)
layer4 = self.layer4(layer3)
layer5 = self.layer5(layer4)
return self.output_layer(layer5)
discriminator.py
import torch
import torch.nn as nn
from torch.utils.model_zoo import tqdm
import cv2
import matplotlib.pyplot as plt
import numpy as np
import os
import torchvision
import torch.nn.utils.spectral_norm as spectral_norm
class Discriminator(nn.Module):
'''
The Discriminator that shall distinguish between dataset images and the ones generated by the generator.
'''
def __init__(self, number_of_gpus):
super(Discriminator, self).__init__()
self.ngpu = number_of_gpus
discriminator_depth=128
self.layer1 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=3, out_channels=discriminator_depth,
kernel_size=(4, 4), stride=2, padding=1, bias=False)),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer2 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=discriminator_depth, out_channels=discriminator_depth * 2,
kernel_size=(4, 4), stride=2, padding=1, bias=False)),
nn.BatchNorm2d(discriminator_depth * 2),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer3 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=discriminator_depth * 2, out_channels=discriminator_depth * 4,
kernel_size=(4, 4), stride=2, padding=1, bias=False)),
nn.BatchNorm2d(discriminator_depth * 4),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer4 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=discriminator_depth * 4, out_channels=discriminator_depth * 8,
kernel_size=(4, 4), stride=2, padding=1, bias=False)),
nn.BatchNorm2d(discriminator_depth * 8),
nn.LeakyReLU(0.2, inplace=True)
)
self.layer5 = nn.Sequential(
spectral_norm(nn.Conv2d(in_channels=discriminator_depth * 8, out_channels=discriminator_depth * 16,
kernel_size=(4, 4), stride=2, padding=1, bias=False)),
nn.BatchNorm2d(discriminator_depth * 16),
nn.LeakyReLU(0.2, inplace=True)
)
self.output_layer = nn.Sequential(
nn.Conv2d(in_channels=discriminator_depth * 16, out_channels=1,
kernel_size=(4, 4), stride=1, padding=0, bias=False),
nn.Sigmoid()
)
def forward(self, input_image):
layer1 = self.layer1(input_image)
layer2 = self.layer2(layer1)
layer3 = self.layer3(layer2)
layer4 = self.layer4(layer3)
layer5 = self.layer5(layer4)
return self.output_layer(layer5)
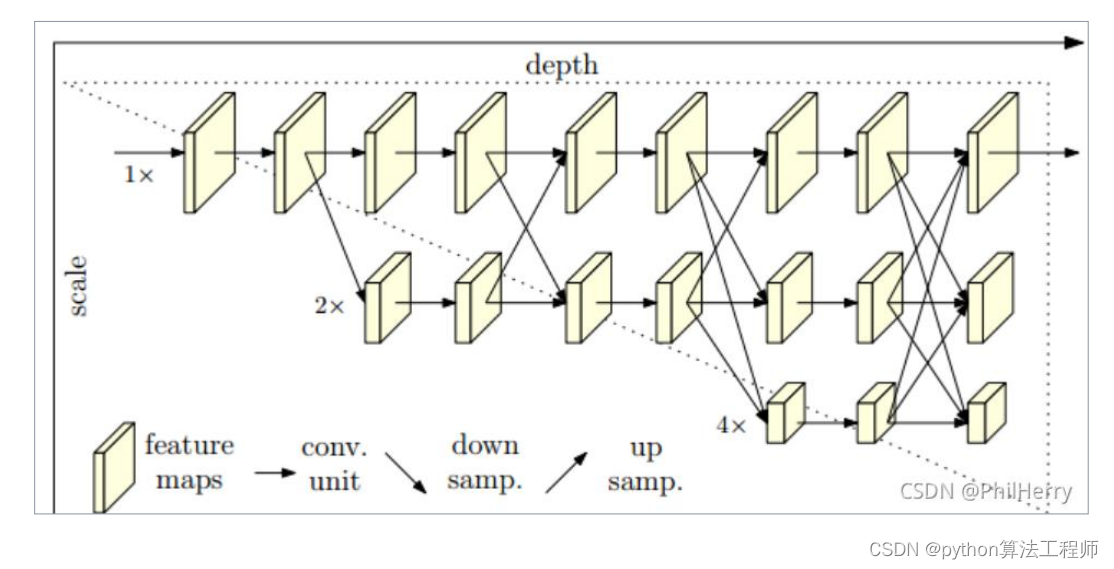
常用主干网络–HRNet
1、以并行而非串行的方式连接不同分辨率的分支;
2、整个运算过程都保留了高分辨率表征;
3、不断地融合不同分辨率的表征,得到对位置敏感的高分辨率表征。
 常用主干网络–Hourglass
常用主干网络–Hourglass
网络结构形似沙漏状,重复使用top-down到bottom-up来推断人体的关节点位置。每一个top-down到bottom-up的结构都是一个stackedhourglass模块
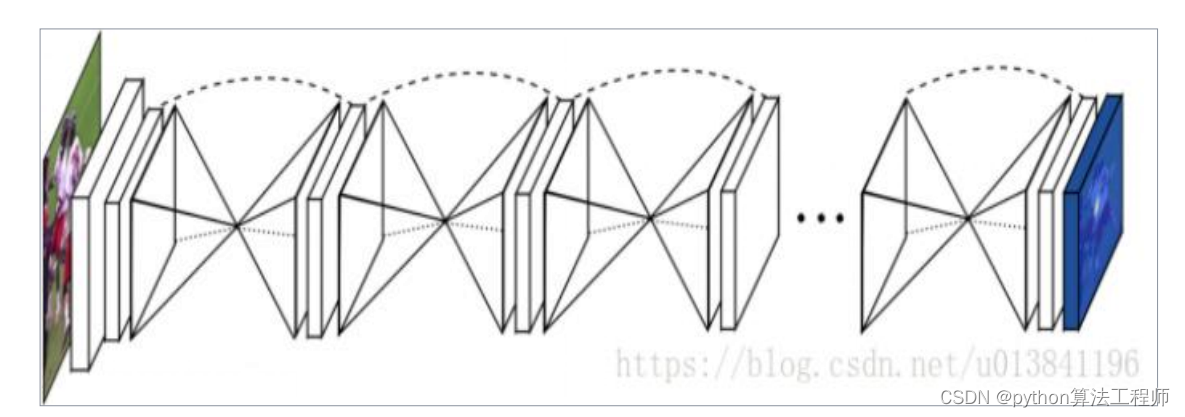
常用主干网络–DeepLabV3
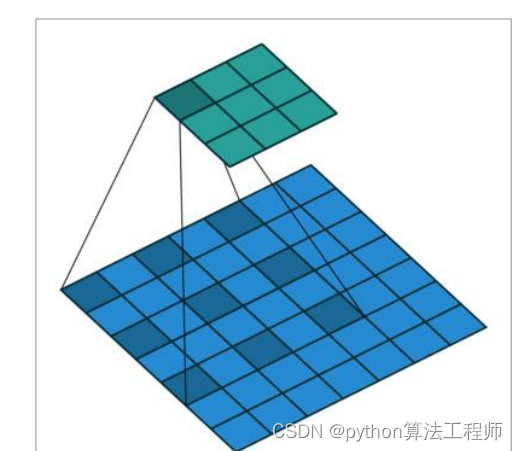
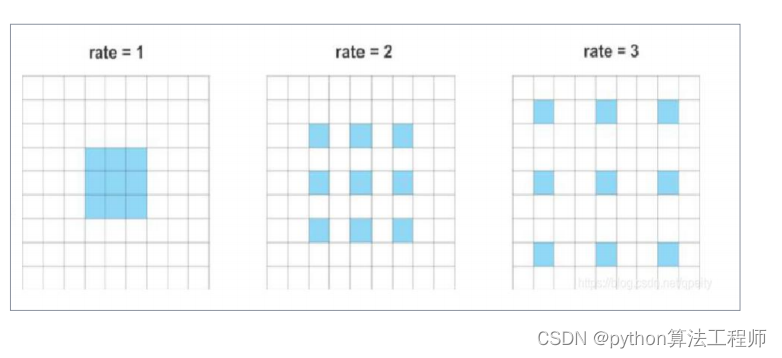
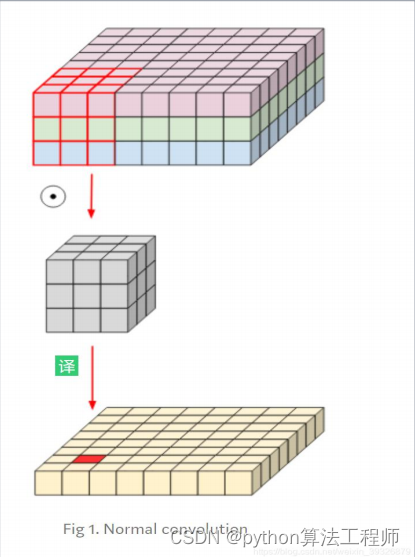
常用主干网络–普通卷积
针对一个3X8X8(channelXwidthXheight)的输入,filter为3X3X3,普通的卷积是按照如下所做的:
 常用主干网络–可分离卷积
常用主干网络–可分离卷积
但是在depth-wise卷积中,我们将图像的channel和filter的channel拆开来,分别卷积,然后stack到一起,这样子只用了三个卷积核,我们就得到了三张特征图
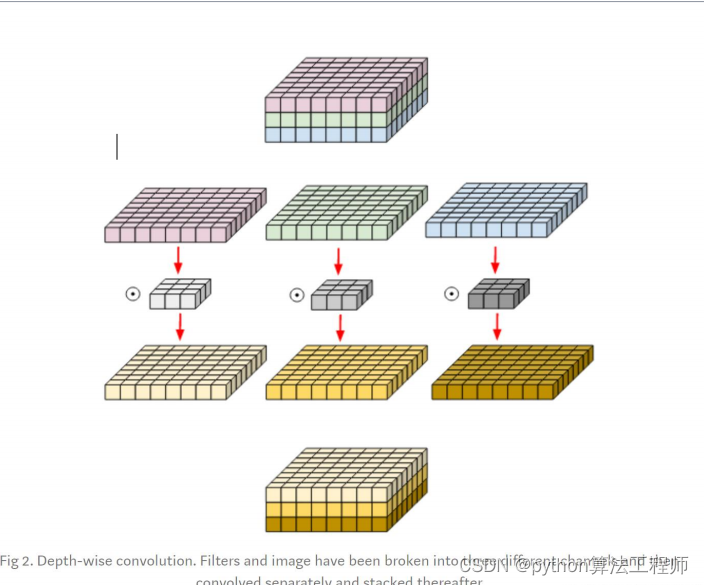
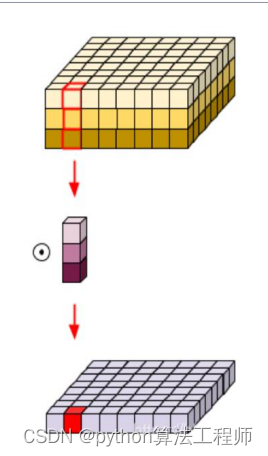
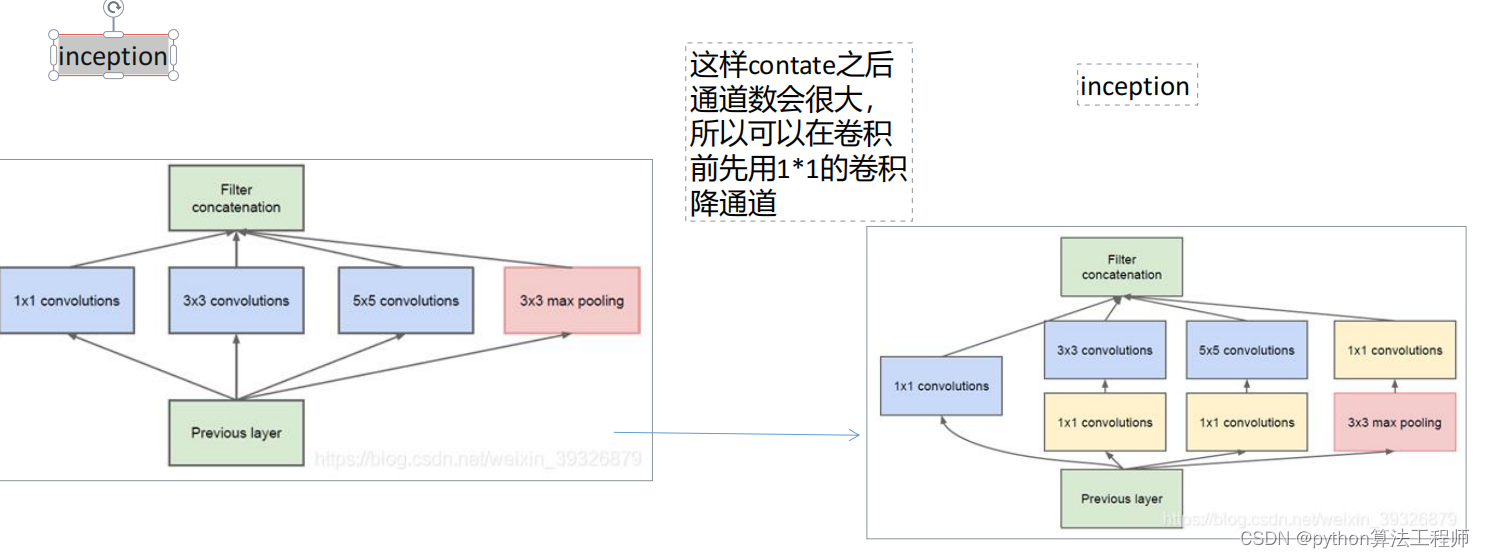
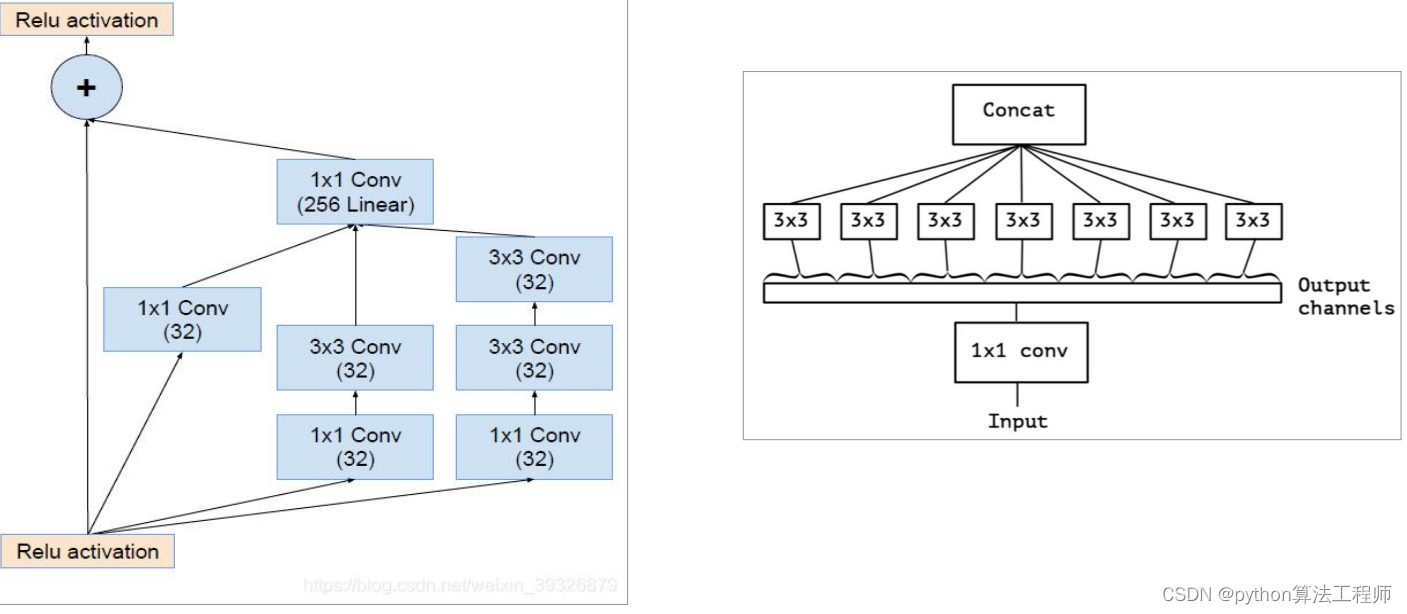
常用主干网络–iception


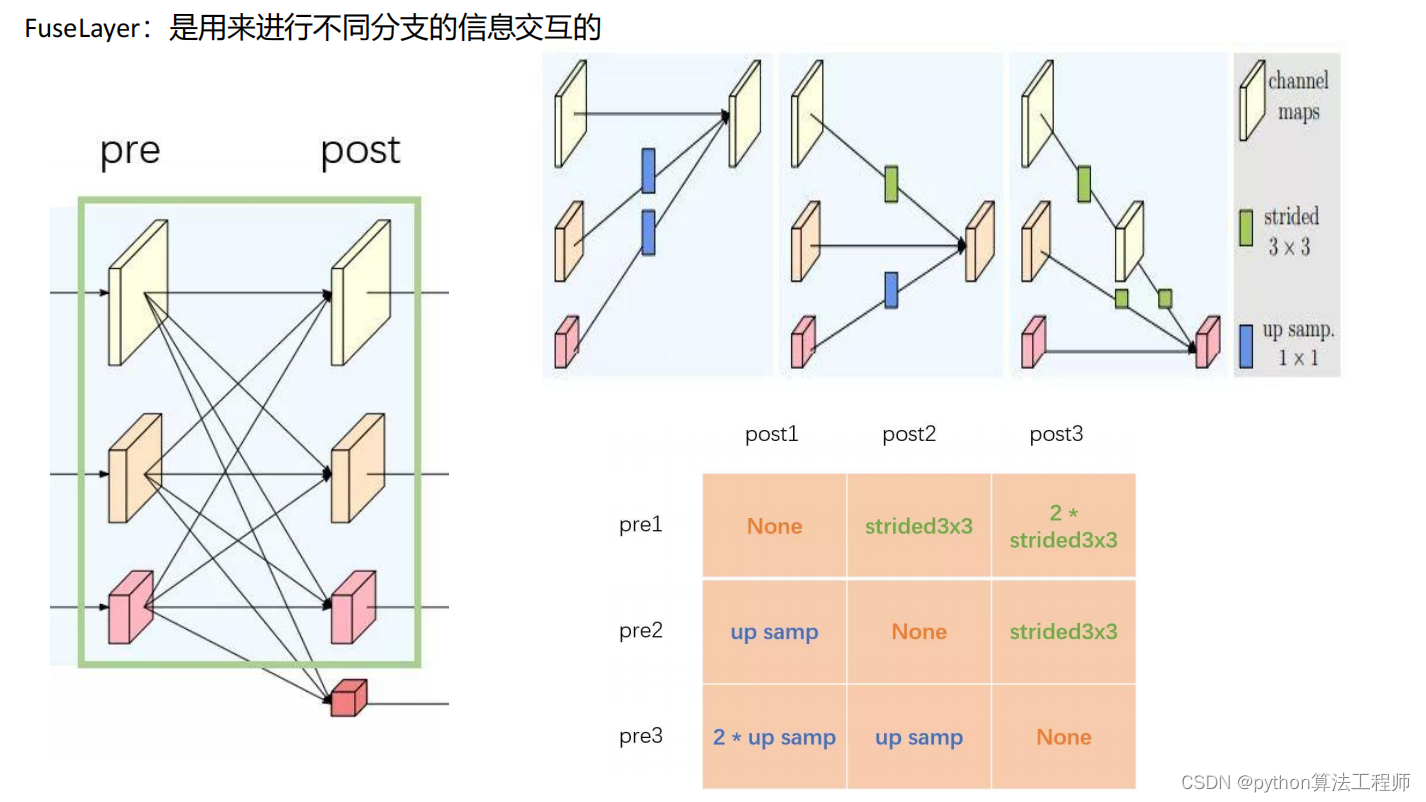
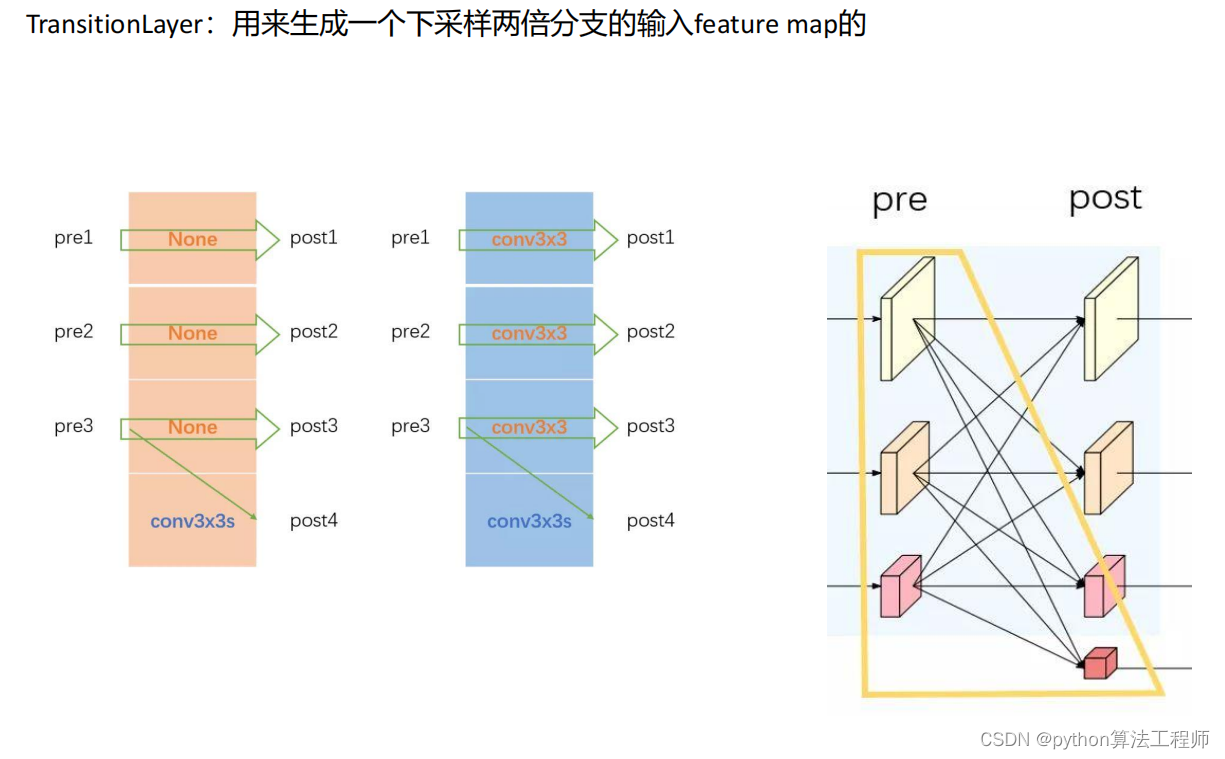
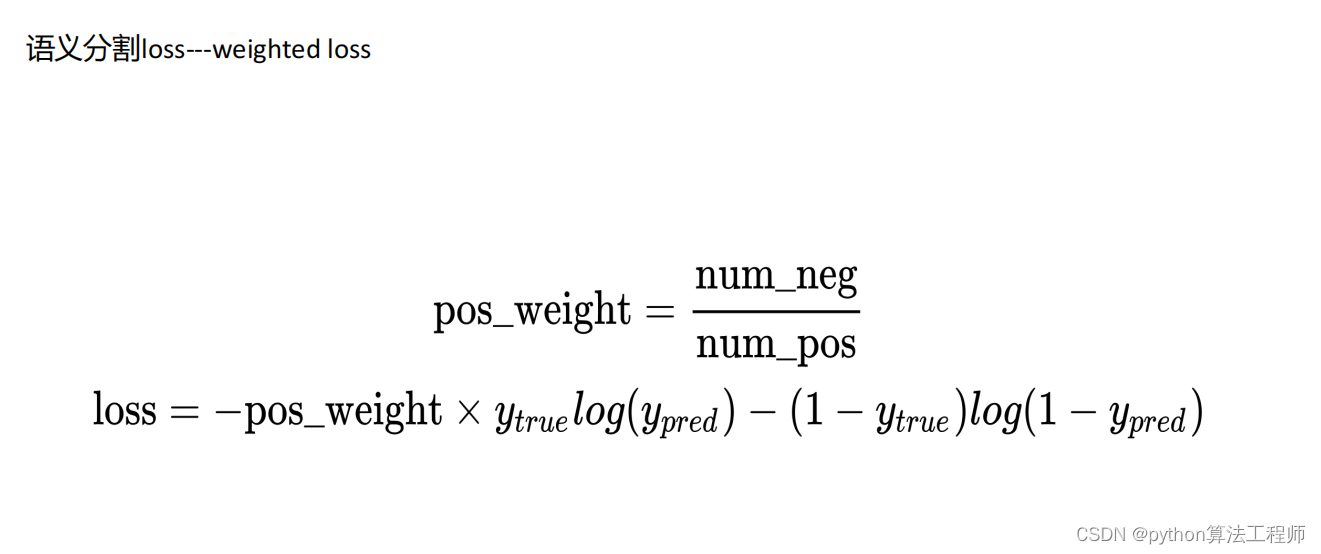
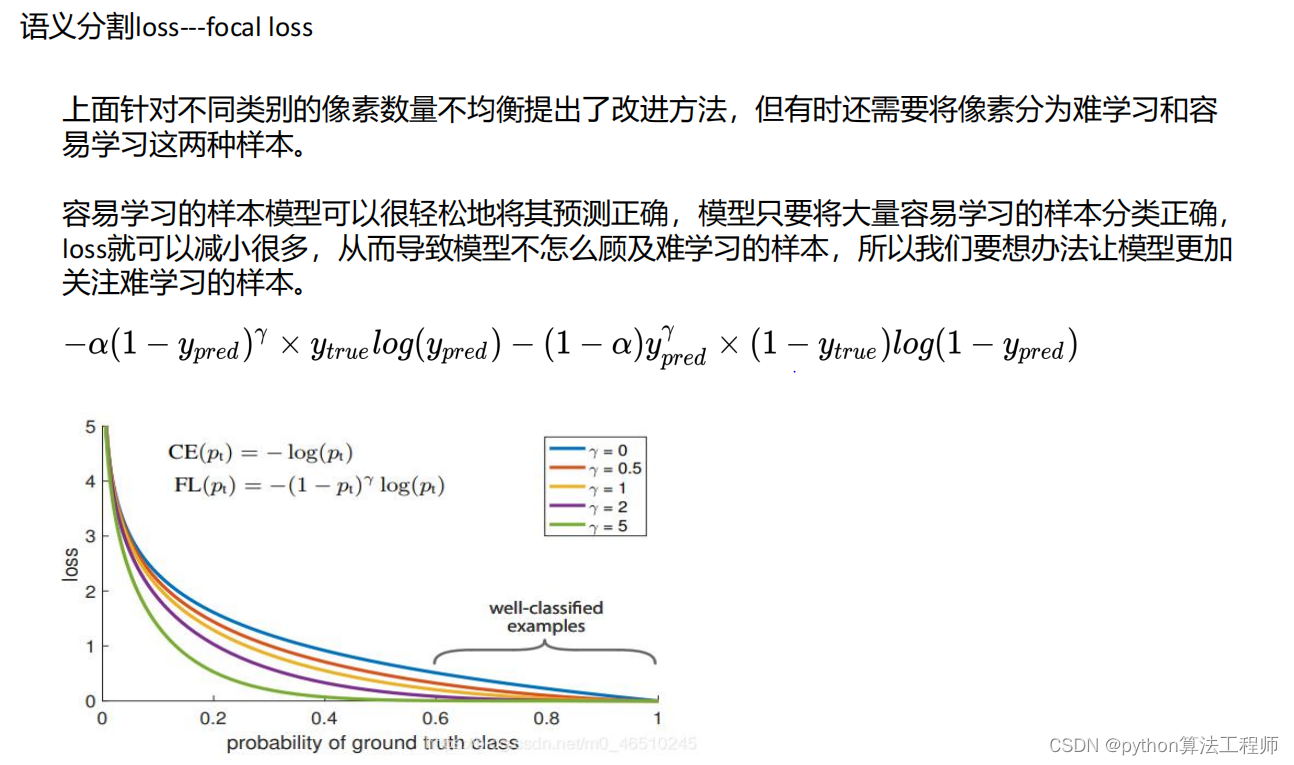
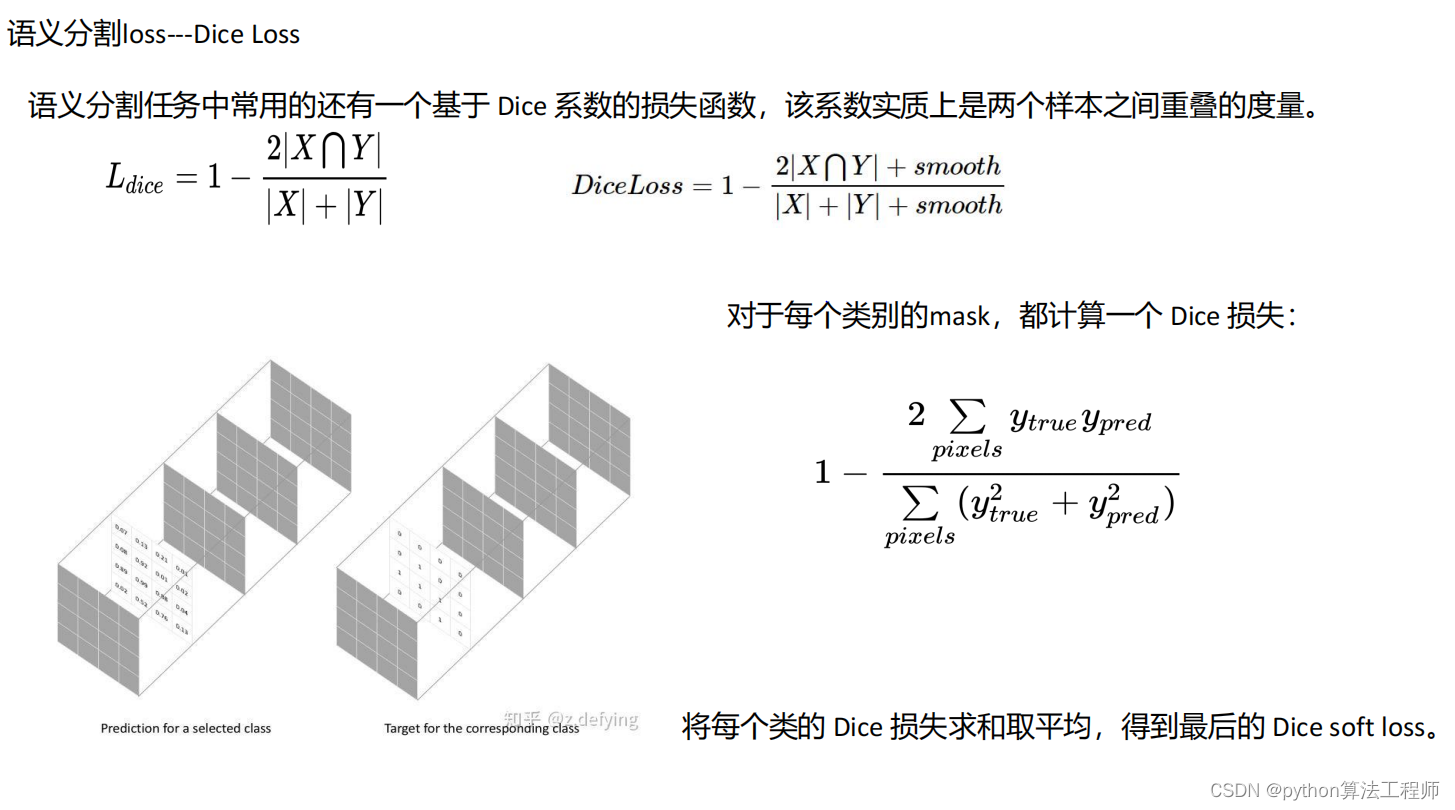
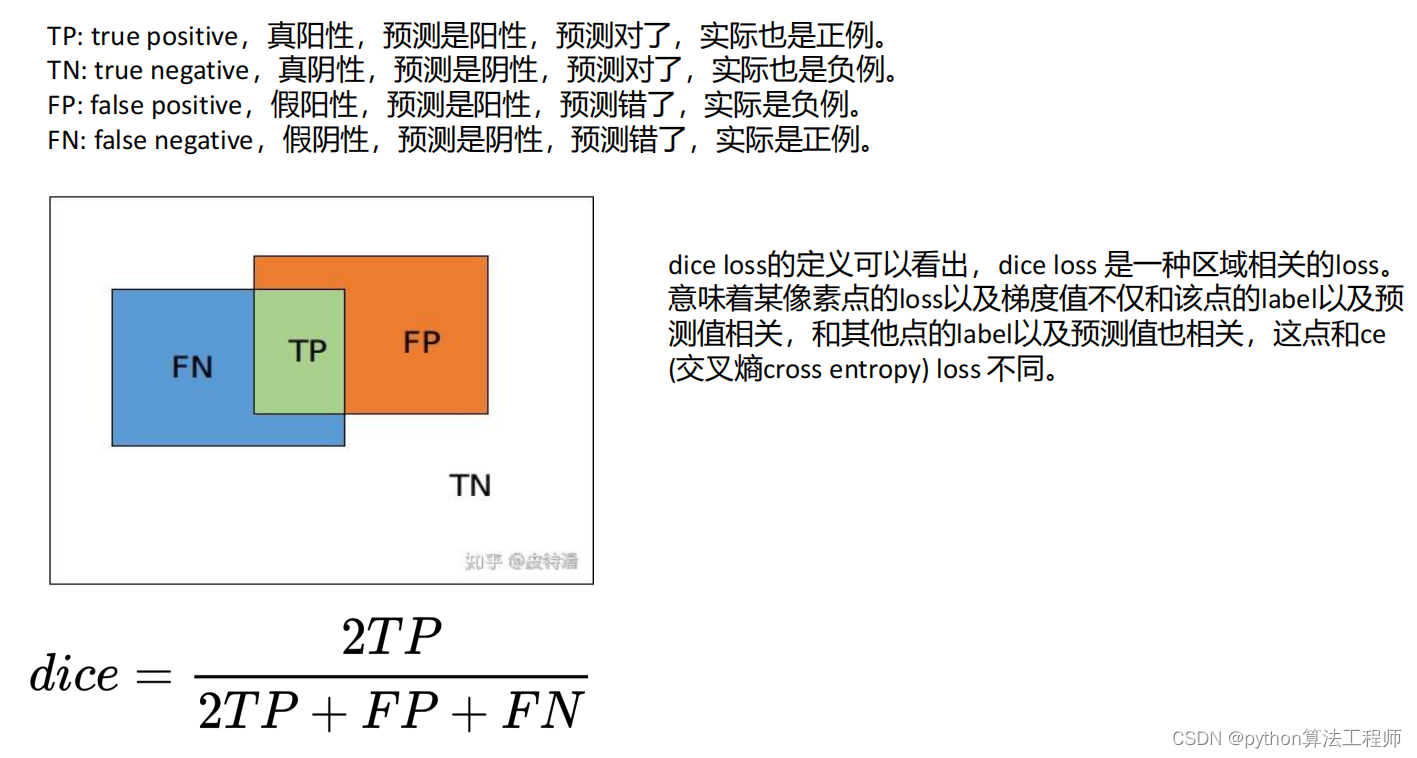
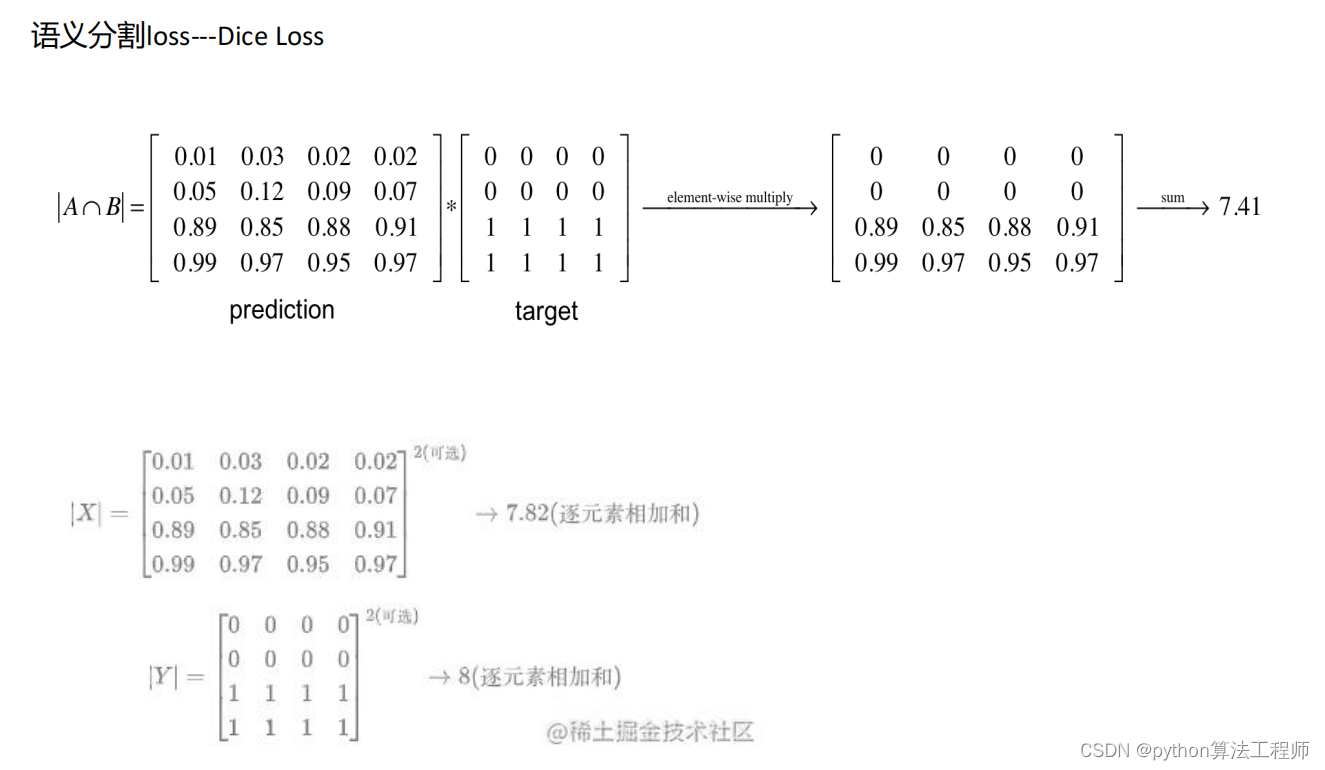

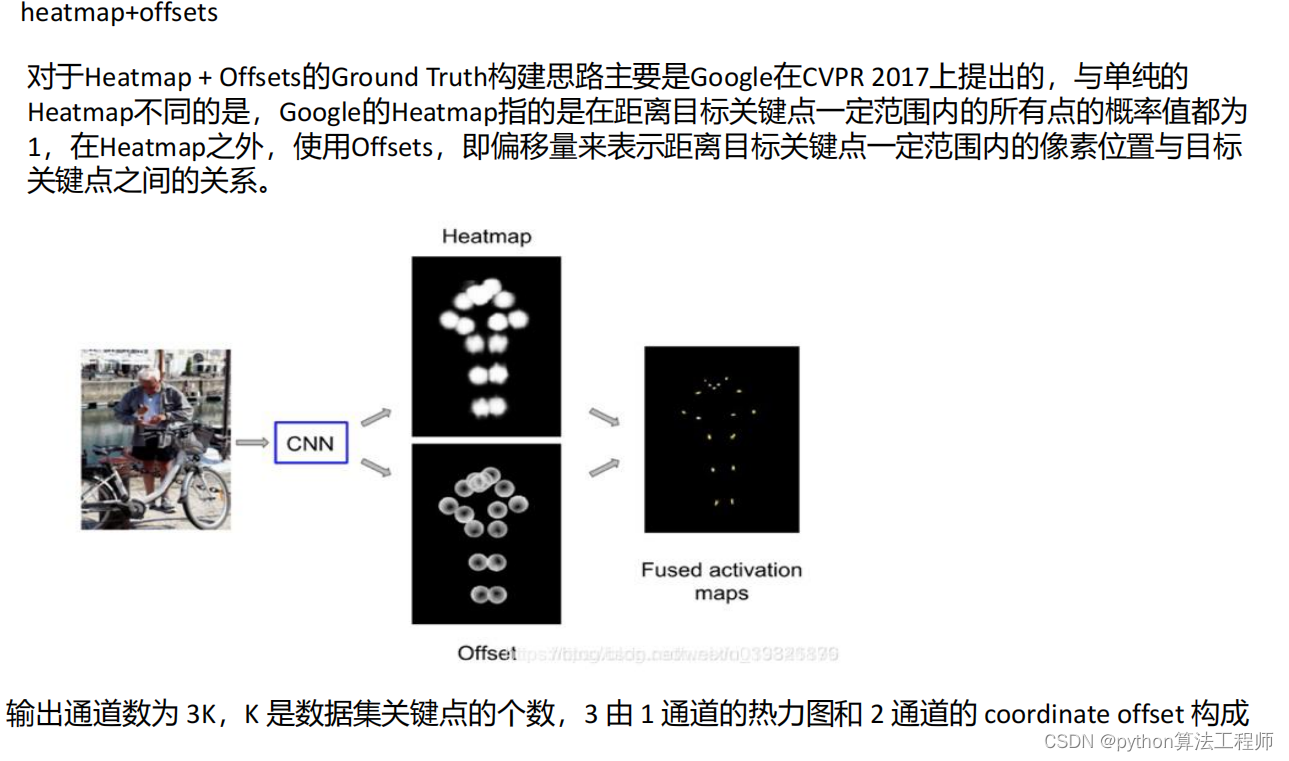
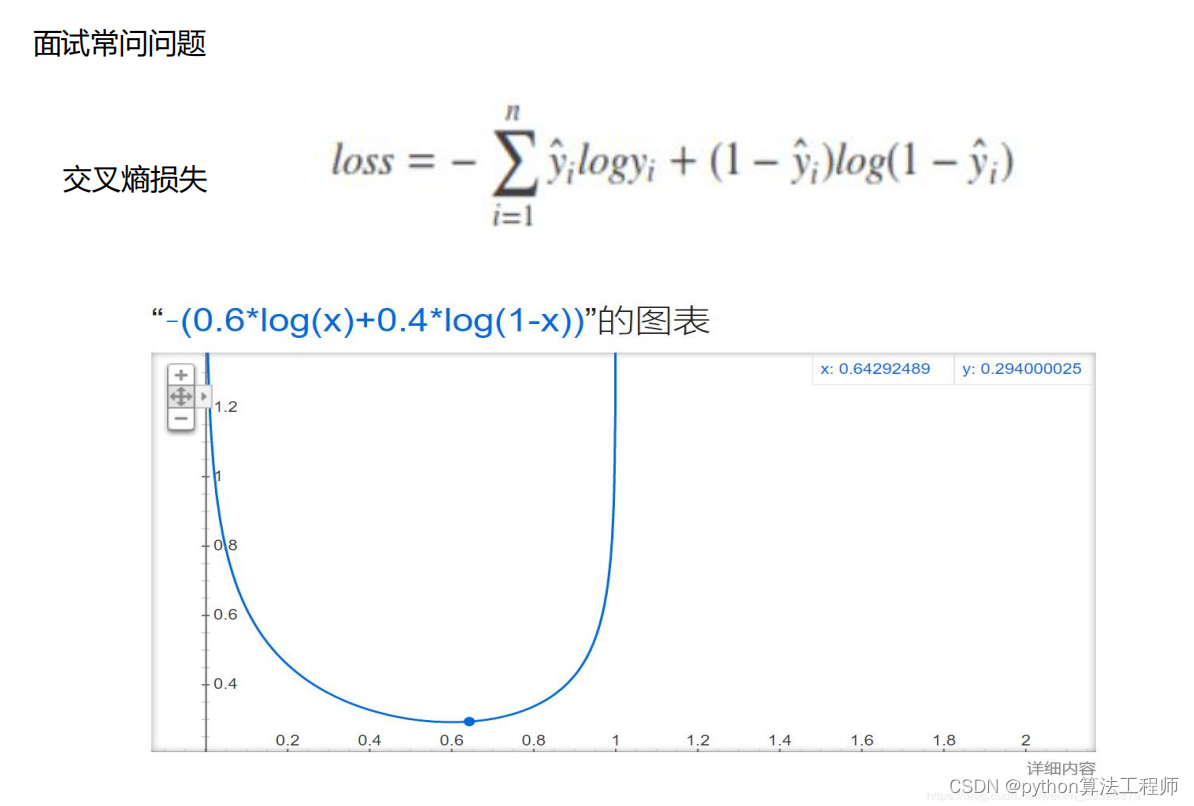
交叉熵损失
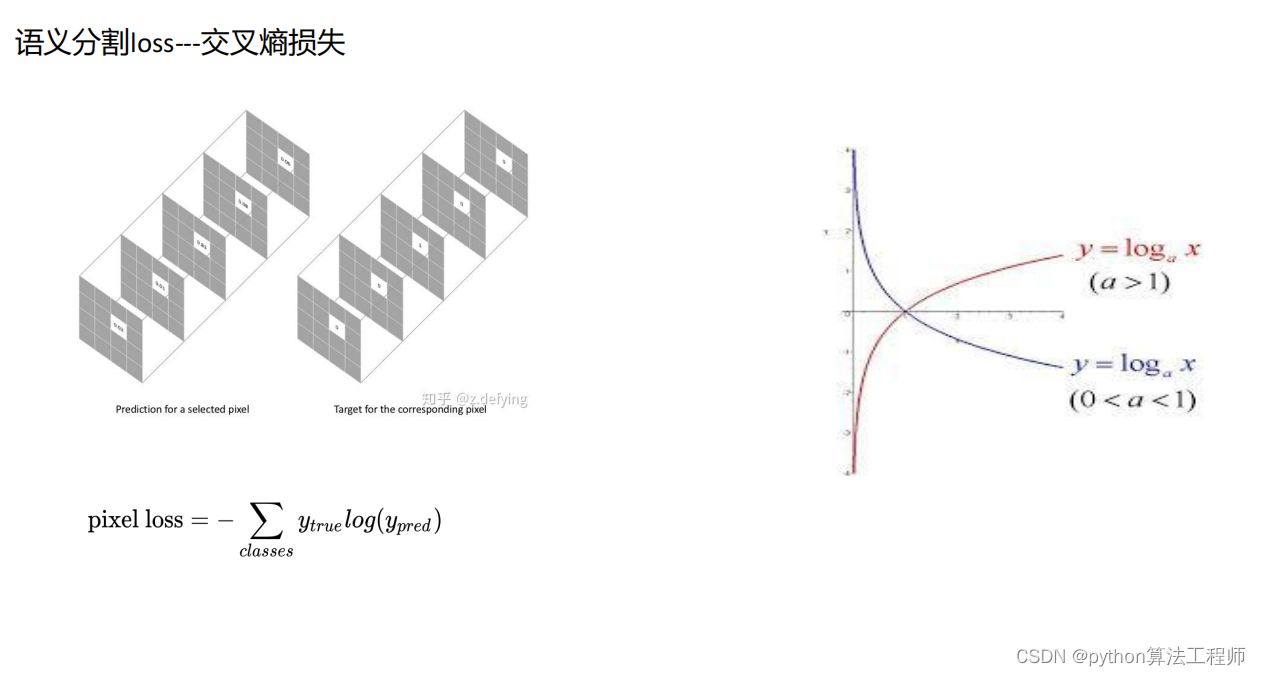
交叉熵损失是一种通用的损失函数,它在分类问题中广泛应用。在深度学习中,分类问题通常可以分为两类:二分类和多分类。对于二分类问题,交叉熵损失可以表示为:
H ( p , q ) = − p log ( q ) − ( 1 − p ) log ( 1 − q ) H(p,q) = -p\log(q) - (1-p)\log(1-q) H(p,q)=−plog(q)−(1−p)log(1−q)
其中, p p p是真实标签的概率, q q q是模型预测为正类的概率。交叉熵损失的含义是,用模型预测的概率 q q q来估计真实标签 p p p的概率,两个概率之间的差异越小,则交叉熵损失越小,表示模型的预测结果越准确。
对于多分类问题,交叉熵损失可以表示为:
H ( p , q ) = − ∑ i = 1 C p i log ( q i ) H(p,q) = -\sum_{i=1}^{C}p_i \log(q_i) H(p,q)=−∑i=1Cpilog(qi)
其中, C C C是类别数, p i p_i pi是真实类别为 i i i的概率, q i q_i qi是模型预测为类别 i i i的概率。交叉熵损失的含义是,用模型预测的概率 q q q来估计真实标签 p p p的概率分布,两个概率分布之间的差异越小,则交叉熵损失越小,表示模型的预测结果越准确。
在深度学习中,交叉熵损失通常作为优化目标函数进行最小化,以使得模型能够更加准确地预测类别。在反向传播过程中,交叉熵损失对模型的参数进行梯度计算,并通过随机梯度下降等优化算法来更新模型的参数。
总之,交叉熵损失是一种用于分类问题的损失函数,它可以通过比较真实标签和模型预测之间的概率分布来衡量模型的预测准确性,常用于深度学习模型的训练中。


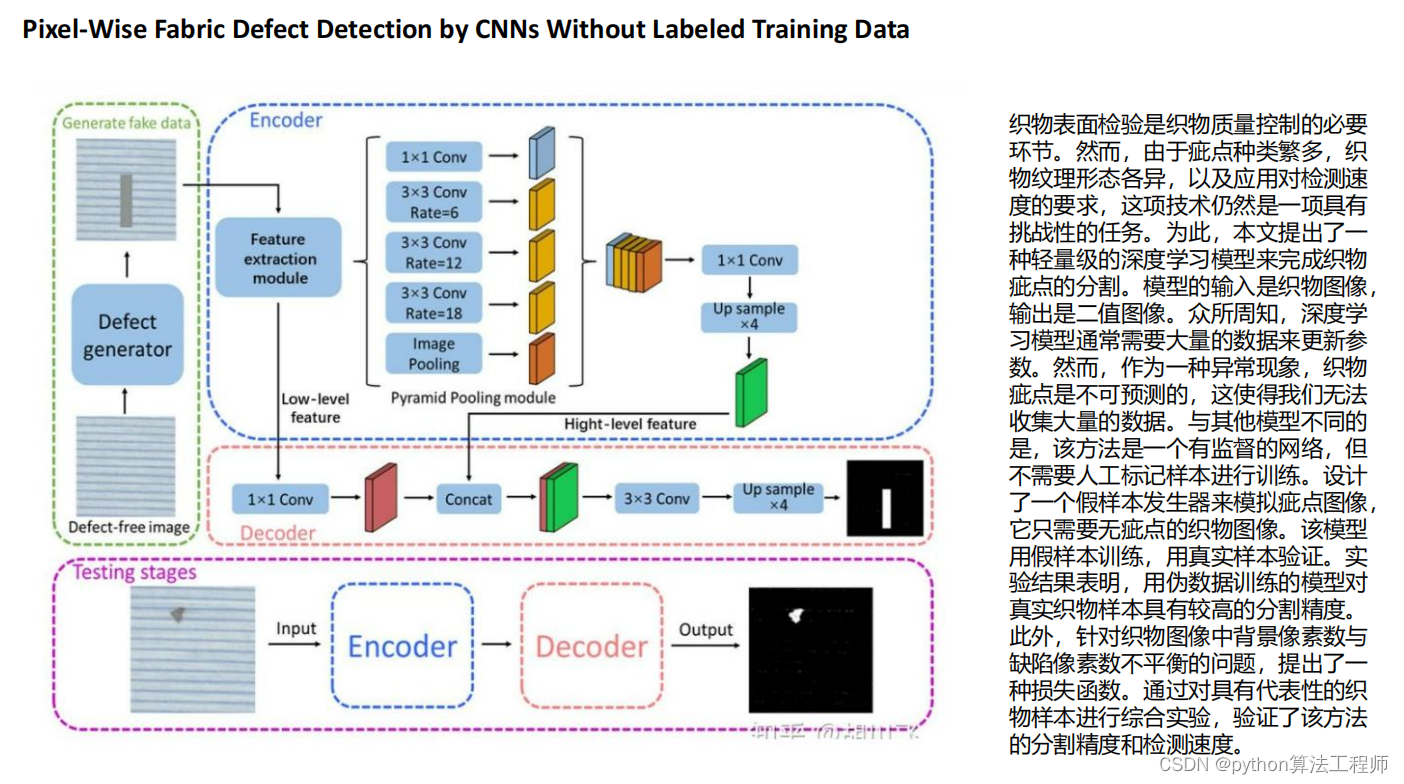
项目背景



电子换向器的质检需求

人工质检存在的问题:
1.人力成本高;
2.人容易出现视觉疲劳导致漏检;
3.招工困难,该工种重复度高强度大,大部分人不愿意从事该工种;
电子换向器的缺陷类别以及检测难点
换向器整流子视觉检测设备可检测换向器不良特征有上表面麻点、划伤、碰伤、氧化、云母破损、钩宽、下表面破损压伤、内孔直径、钩弯、钩夹角、内控划伤等缺陷。
1.产品外表面有杂斑干扰,裂纹长度、宽度不确定,位置分别也有随机性,增加检测难度。
2.工业相机拍摄的图像受光照、光强等条件影响,换向器金属表面容易反光,会导致图像成像容易不清晰;
3.换向器缺陷种类多,形态多样,缺陷特征有细微的、线状的和块状,形态复杂。
4.产线上良品率高,次品率低,可收集带有缺陷的数据仅有52张;
以上三点严重制约着换向器缺陷检测的准确率、效率、泛化能力。
针对换向器金属表面容易反光的问题:
我们采用条形光源+线阵相机+匀速转台的方式进行图片的采集其中条形光源大小为30*20cm;
电子换向器的高度为5cm;
线阵相机的型号是:Basler线阵相机(宝视纳视觉)
转台直径为20cm,
转速为10rad/s

针对缺陷样本少的问题:

针对标签难标注的问题:
我们采用预标签的方式进行标签的标注
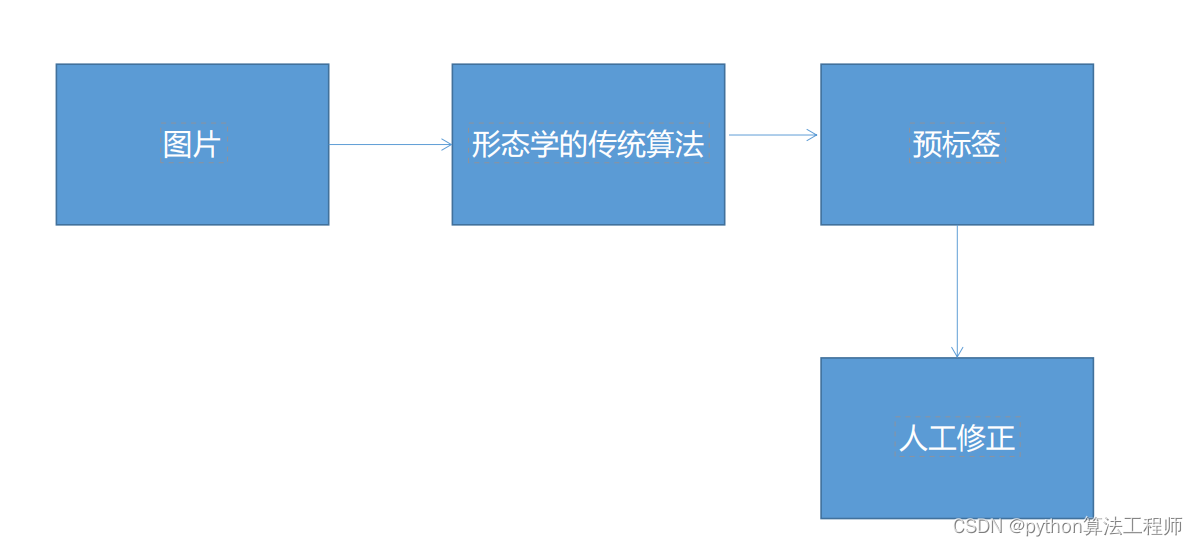
针对缺陷小的问题:
我们尝试了HRNet和Hourglass
针对正负样本不均衡的问题:
我们尝试Diceloss和focalloss
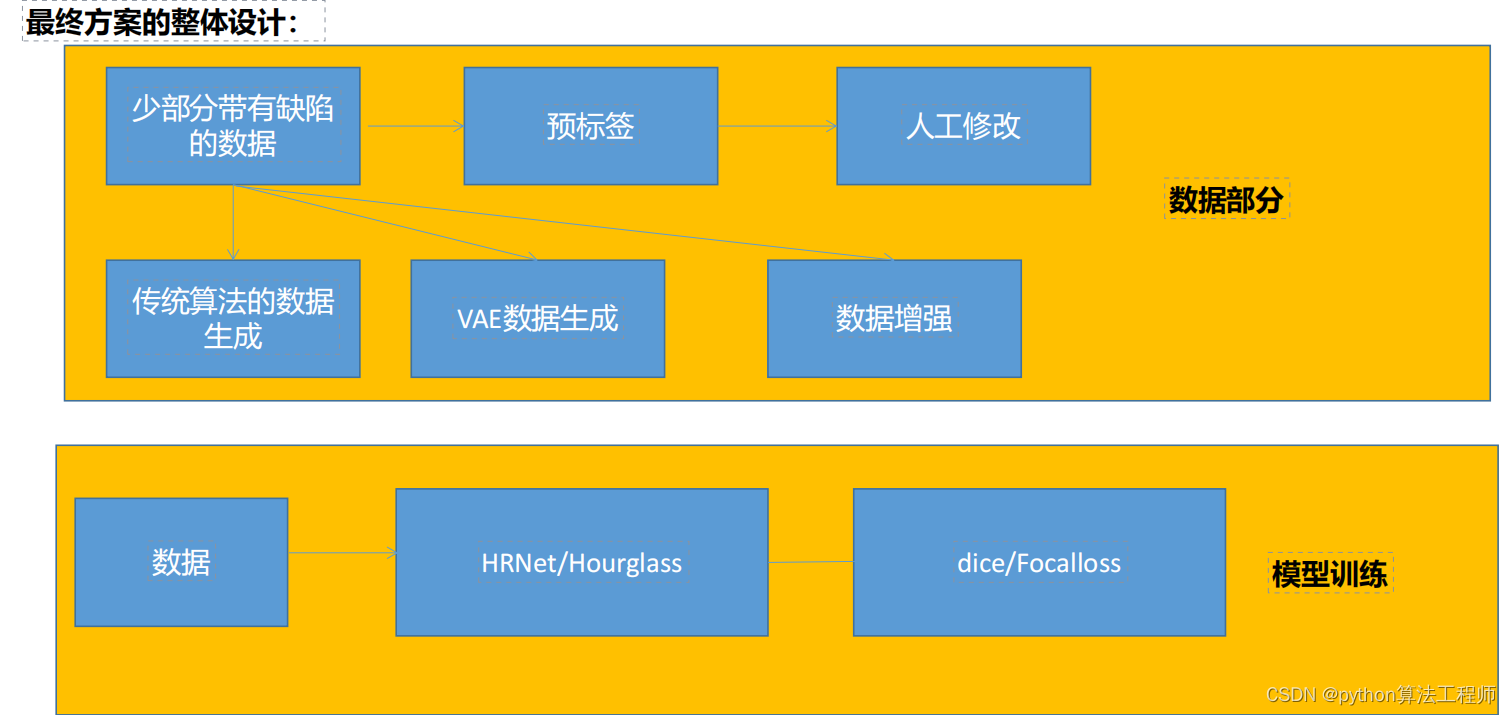

我们取得的结果:
最终,我们在电子换向器的测试中取得了mIou=0.98的;
在实际产线上,有缺陷的产品的检出率为99%,检测速度20-30个每秒,检测精度可达0.01mm。有效帮助需要换向器整流子检测的企业提高检测速度、提高产品质量、保障每批出场产品实现0退货。
学完缺陷检测阶段的项目课后可以在个人技能页添加:
熟悉VAE、CVAE、GAN等网络;
熟悉HRNet\Hourglass\DeepLabV3等主干网络;
熟悉缺陷预标注;
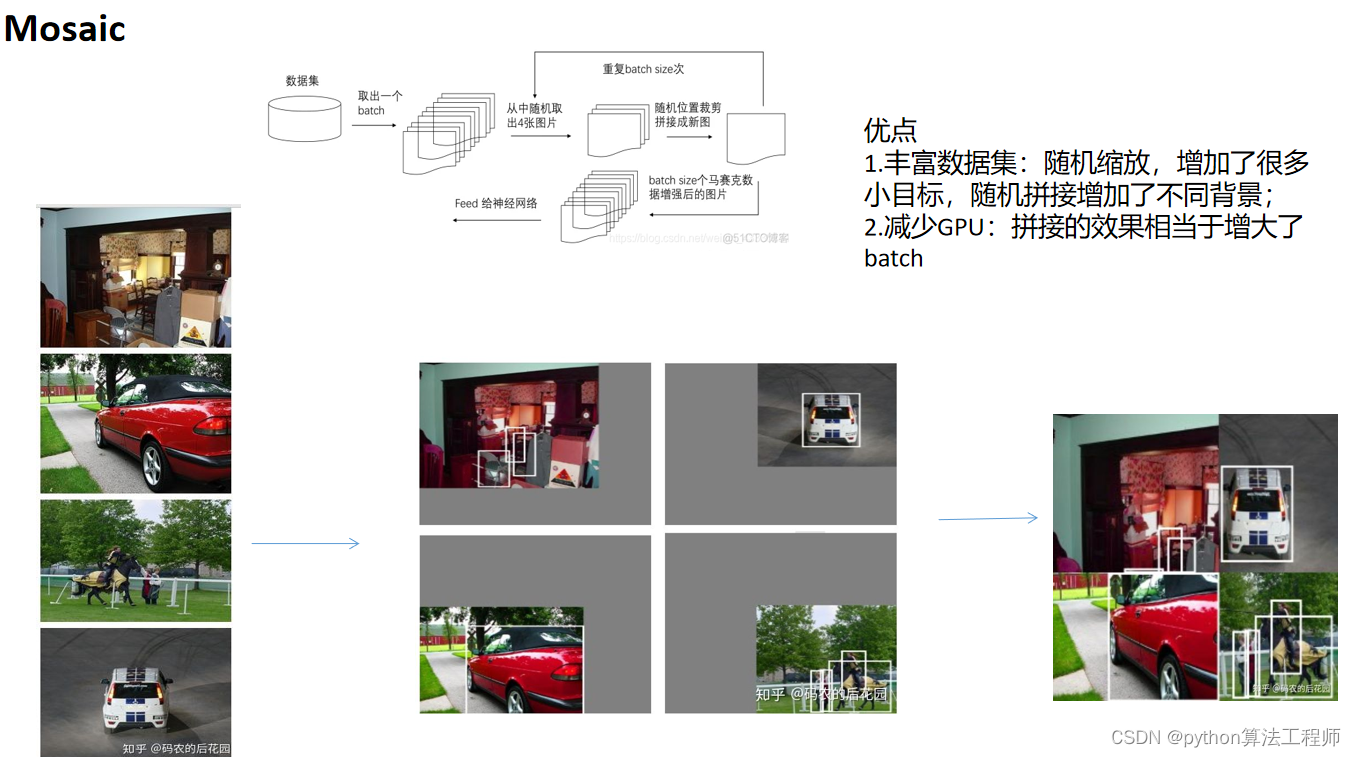
熟悉mixup\cutmix\镜像翻转等数据增强;
熟悉交叉熵损失\IOUloss\Diceloss\weightloss\focalloss\L1\L2\smoothL1等损失函数;熟悉工业面阵相机、线阵相机的特点和选型;
熟悉条形光源、面板光源、环形光源等常用的工业光源;
简历建议:
1.不要有错别字!!中英文都要检查~
2.逻辑清晰,言简意赅;
3.突出重点,可以通过放大加粗的方式,引导面试官询问自己
4.把自己最熟悉最有把握的项目写在最前面;
5.简历上涉及到的点一定都要准备到~;
6.少说无法量化的话,比如谦虚好学,尽量数字去验证自己的这些点,比如每个月读几本书,几篇paper 7.简历不宜果断,简历排版要好看,至少让人觉得你在制作这份简历上花了功夫
8.专业技能要作为一个模块写上,因为方便HR初筛
9.照片最好P的好看点放上去
10.按照STAR法则去叙述项目:STAR法则是情境(situation)、任务(task)、行动(action)、结果(result)四项的缩写。STAR法则是一种常常被面试官使用的工具,用来收集面试者与工作相关的具体信息和能力。
面试建议:
1.切勿态度傲慢,骄傲自满,或者表现出藐视、不耐烦;
2.尽量表现的谦虚,不卑不亢;
3.真诚,对于不会不清楚的问题,如实回答,并积极告知自己知道的部分;切勿通过逻辑混乱的表述蒙混过关
4.禁止作弊,比如笔试的时候偷偷搜索答案;
5.面试结束的时候,向面试官询问对方团队的业务情况,对面试官表达青睐和兴趣;
6.表现出乐观、抗压、对于生活和技术的热爱;
7.面试前可模拟面试三遍,让自己的语言表达更加通畅;
8.每次面试都记录自己没有回答好的地方,查好答案,让自己下一次表现更好;
9.如果感觉自己在面试中表现不佳,可以在面试快结束的时候,表达出自己知道自己这次没有表现好,仍然希望有机会加入贵团队;(不一定有用,但是不会有害);
10.每次面试也要记录面试官的相关信息,记录你对面试官的看法和感受,因为他很可能是你将来的领导或者同事,如果最终拿了多个offer进行抉择的时候,面试官的表现也是要着重考量的点;

















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









