







文章目录
1.存储系统的价格
计算公式:
C = C 1 ∗ S 1 + C 2 ∗ S 2 S 1 + S 2 C=\frac{C_1*S_1+C_2*S_2}{S_1+S_2} C=S1+S2C1∗S1+C2∗S2
当
S
2
>
>
S
1
S_2>>S_1
S2>>S1时,
C
≈
C
2
C≈C_2
C≈C2

2.存储系统的速度
1)命中率定义:在 M 1 M_1 M1存储器中访问到的概率
H = N 1 N 1 + N 2 H=\frac{N_1}{N_1+N_2} H=N1+N2N1
其中
N
1
N_1
N1是对
M
1
M_1
M1存储器的访问次数,
N
2
N_2
N2是对
M
2
M_2
M2存储器的访问次数。
2) 访问周期:
T
=
H
∗
T
1
+
(
1
−
H
)
∗
T
2
T=H*T_1+(1-H)*T_2
T=H∗T1+(1−H)∗T2
3.存储系统的速度
1)存储系统的访问效率
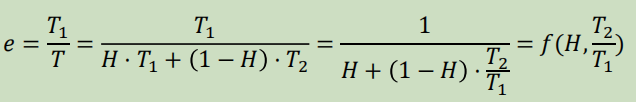
2)提高存储系统速度的两条途径
提高命中率H
使两个存储器的速度不要相差太大
3)存储器的频带平衡
没看懂。。。
3.虚拟存储器
1.段式虚拟存储器
1.地址映像方法
每个程序段都从0地址开始编址,长度可长可短,可以在程序执行过程中动态改变程序段的长度。

2.地址变换方法:
由用户号找到基址寄存器,读出段表起始地址,与虚拟地址中段号相加得到段表地址,把段表中的起始地址与段内偏移D相加就能得到主存实地址。

3.优缺点
程序的模块化性能好;便于程序和数据的共享;程序的动态链接和调度比较容易;便于实现信息保护。
两次加法使得地址变换所花费的时间长;主存储器的利用率也比较低。
2.页式虚拟存储器
1)地址映射:

2)地址变换

3.段页式虚拟存储器
用户按段写程序,每段分成几个固定大小的页
1)地址映像方法:
每个程序段在段表中占一行,在段表中给出页表长度和页表的起始地址,页表中给出每一页的主存储器中的实页号。
2)地址变换方法
先查段表,得到页表起始地址和页表长度,再查页表找到要访问的主存实页号,把实页号p与页内偏移d拼接得到主存实地址。

4.外部地址变换
每个程序有一张外爷表,每一页或每个程序段,在外页表中都有对应的一个存储字。
5.加快内部地址变换的方法
1)造成虚拟存储器速度降低的主要原因:
要访问主存储器必须先查段表或页表;当页表和段表的容量超过了一个页面的大小时,它们有可能被映像到主存不连续的页面上,使得按照地址查找主存实页号的办法无法成立。
2)解决方案:
段表和页表都放在主存中;
3)多级页表:
由页表基址寄存器指出第一级页表的基地址,再用第一级页表各单元中的地址字段指出第二级页表的基地址,如此下去,构成一个树型结构的多级页表。在最后一级页表中给出主存实页号信息。
多级页表的计算
页表级数的计算公式:
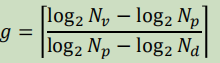
N
v
N_v
Nv为虚拟存储空间大小,
N
p
N_p
Np为页面大小,
N
d
N_d
Nd为一个页表存储字的大小
多级页表:一级页表必须驻留在主存储器中,对于二三级页表,只需要把目前正在运行中的程序的相关页表,或者把已经调入到主存中的程序的相关页表驻留在主存中,绝大部分页表可以放在磁盘存储器中。
4)目录表法
用一个容量比较小的高速存储器来存放页表,这个页表只为装入到主存中的那些页面建立虚页号与实页号之间的对应关系,即目录表。但是当主存容量增加到一定数量时,目录表的造价会低,速度也降低。

5)快慢表
用快表保存最近访问的虚页到实页的映射
快表:高速硬件实现,采用相联方式访问。
慢表:当快表中查不到时,从主存的慢表中,慢表按地址访问,用软件实现。
6)散列函数

采用散列变换实现快表按地址访问
避免散列冲突:采用相等比较器
地址变换:相等比较与访问存储器同时进行。
6.页面替换算法
1.页面替换发生的情况
当发生页面失效时,要从磁盘中调入一页到主存。如果主存储器的所有页面已经被占用,必须从主存储器淘汰一个不太常用的页面。
2.替换算法的好坏
一是命中率要高,二是算法容易实现。
3.随机算法 RAND
4.最优替换算法 OPT
选择将来最久没有被访问的页作为被替换页面。是一种理想算法,几乎不能实现。
5.近期最少使用算法 LRU
选择近期最少访问的页作为被替换的页。能够比较正确反映程序的局部性。
6.先进先出算法 FIFO
选择最早装入主存的页作为被替换的页。没有反映局部性,最先调入的页面,很可能也是要使用的页面。
7.提高主存命中率的方法
1.影响因素
程序在执行过程中的页地址流分布情况
使用的页面替换算法
页面大小
主存储器的容量
页面调度算法
2.页面大小与命中率的关系
当页面增大时,造成的浪费也要增加;当页面减小时,页表和页面在主存储器中所占的比例将增加。

3.主存容量与命中率的关系

4.页面调度方式与命中率的关系
请求式:当使用到的时候,再调入主存。
预取式:在程序重新开始运行之前,把上次停止运行前一段时间内用到的页面先调入到主存储器,然后才开始运行程序。
8.cache
1.全相联映象
块冲突概率低,空间利用率高;但是存储器成本高,查表速度慢。

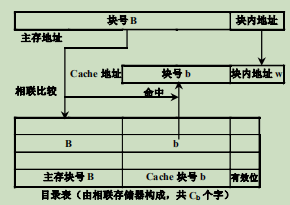
2.直接映象
映象规则:主存储器中一块只能映象到Cache的一个特定的块中。

Cache地址的计算公式:𝑏 = 𝐵 mod 𝐶𝑏
其中:𝑏为Cache块号,𝐵是主存块号, 𝐶𝑏是Cache块数。
实际上,Cache地址与主存储器地址的低位部分完全相同
用主存地址中的块号B去访问区号存储器,把读出来的区号与贮存地址中的区号E进行比较:比较结果相等且有效位为1,则cache命中,否则该块已经作废;比较结果不相等,有效位为1,说明该块有用,但是该块为空。
硬件实现简单,不需要相联访问存储器;访问速度也比较快,实际上不需要进行地址变换。但是块的冲突率比较高。
提高cache速度的一种方法:把区号存储器与cache合并成一个存储器。
3.组相联映象
映象规则:主存和cache按同样大小划分成块和组;主存和cache的组之间采用直接映象方式;在两个对应的组内部采用全相联映象方式。即把cache所有行分组,把主存块映射到cache固定组的任一行中
块的冲突率低,利用率提高,失效率降低。但是实现难度和造价较高。


用主存地址中的组号G按地址访问块表存储器。然后把访问到的一组区号和块号与主存地址中的区号和块号进行相联比较。如果有相等的,表示cache命中。
提高cache访问速度的一种方法:用多个相等比较器来代替相联访问。
9.cache替换算法
1.轮换法
1)方法一:每块一个计数器
在块表内增加一个替换计数器字段,计数器的长度与cache地址中的组内块号字段的长度相同;
管理规则:新装入或替换的块,它的计数器清0,同组其它块的计数器都加“1“。
在同组中选择计数器的值最大的块作为被替换的块。
2)方法二:每组一个计数器
本组有替换时,计数器加“1”,计数器的值就是被替换出去的块号。
实现简单,能够利用历史上的快地址流情况。但是没有利用程序局部性特点。
2.LRU算法
为每一块设置一个计数器,计数器的长度与块号字段的长度相同。
管理规则:新装入或替换的块,计数器清0,同组中其他块的计数器加1。命中块的计数器清0,同组的其他计数器中,凡计数器的值小于命中块计数器原来值的加1,其余计数器不变。需要替换时,在同组的所有计数器中选择计数值最大的计数器,它所对应的块被替换。
3.比较对法
以三个块为例,分别称为块A、块B、块C
表示方法:用
T
A
B
T_{AB}
TAB表示 B块比 A 块更久没有被访问过(A比B更近被访问过)。如果表示块 C 最久没有被访问过:
C
L
R
U
=
T
B
C
∗
T
A
C
C_{LRU}=T_{BC}*T_{AC}
CLRU=TBC∗TAC
在访问块A之后:𝑇𝐴𝐵 = 1, 𝑇𝐴𝐶 = 1
在访问块B之后: 𝑇𝐴𝐵 = 0 , 𝑇𝐵𝐶 = 1
在访问块C之后: 𝑇𝐴𝐶 = 0 , 𝑇𝐵𝐶 = 0
4.堆栈法
把本次访问的块号与堆栈中保存的所有块号进行相联比较。1)如果有相等的,则cache命中。把本次访问块号从栈顶压入,堆栈内各单元中的块号依次往下移,直至与本次访问的块号相等的那个单元位置,再往下的单元直至栈底都不变;2)如果没有相等的,则Cache块失效。本次访问的块号从栈顶压入,堆栈内各单元的块号依次往下移,直至栈底,栈底单元中的块号被移出堆栈,它就是要被替换的块号。
10.cache性能计算和影响因素
1.加速比和命中率

T
m
T_m
Tm为主存储器的访问周期
T
c
T_c
Tc为cache的访问周期
T为cache存储系统的等效访问周期
H为命中率
2.命中率的相关因素
程序执行过程中的地址流分布情况
当发生cache块失效时,所采用的的替换算法
cache容量
在组相联映象方式中,块的大小和分组的数目<\font>
cache预取算法
11.cache的一致性和更新算法
写直达法:CPU的数据写入cache时,同时也写入主存
写回法:CPU的数据只写入cache,不写入主存,仅仅当替换时,才把修改过的cache块写回主存。
可靠性:写直达优于写回
与主存的通信量:对于写直达法,每次写操作,必须写、且只写一个字到主存。
对于写回法,大多数操作只需要写Cache,不需要写主存;当发生块失效时,可能要写一个块到主存;即使是读操作,也可能要写一个块到主存。
12.cache的预取算法
- 按需取。当出现Cache不命中时,才把需要的一个块取到Cache中。
- 恒预取。无论Cache是否命中,都把下一块取到Cache中。
- 不命中预取。当出现Cache不命中,把本块和下一块都取到Cache中。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









