







设计类型题目
一定要注意阅读题意,并且有意识地思考去使用现的数据结构,而不是自己硬解。一定要阅读题意,这种题还挺难的,考试的时候也不知道咋调试。。。
1500.设计文件分享系统
注意理解题意,申请那里特别容易误会,第一遍做就误会了,并且我是硬做的,没有想到要使用小根堆和set,对数组的删除也是通过遍历得到迭代器从而进行删除的。。。。显然容易犯错,下面的图片主要是看一下题意解析,代码我并不建议这样写。能不能养成使用数据结构的思维啊 ! ! ! 自己硬写,耗时间又容易出错还又臭又长。
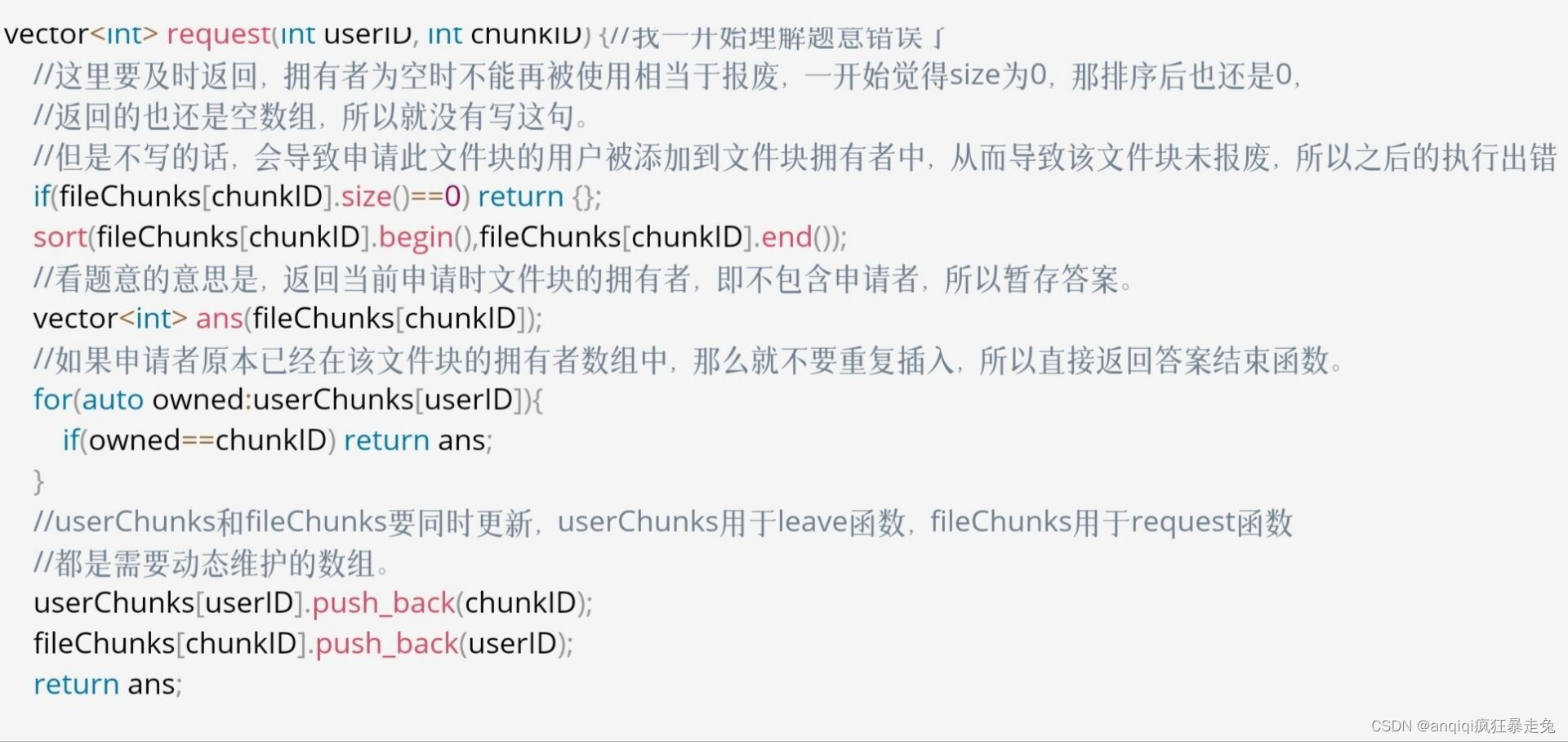
改正:分配ID可以用小根队,用户最多为10e4,所以我们将1到10e4入队,之后用户join后,占用掉一个ID就将ID pop,用户离开时候,再将该ID push。
用户拥有的文件可以用unordered_map<int,vector<int>>,用于用户leave时,我们便于找到其拥有的文件块,并从这些文件块的拥有者中删去这个即将离开的用户,也可以用set也可以用vector,但是其实这里没必要去重,去重set带来的性能消耗蛮大的。
文件块的拥有者可以用 vector<set<int>>,用于计算request结果,所以需要对文件拥有者去重储存,便于多次申请已经拥有的文件块时引起的文件块拥有者重复。
改正后的性能效率没有我硬写的效果好,但是改正后的思想巧妙运用了已封装好的数据结构,使得编写代码更简洁已经不容易犯错。
1166 设计文件系统
用hash,map<string path,int value>。每次创建路径时,首先判断路径是否已经存在以及父路径是否存在,存在即false,不存在即创建。注意这里的初始化是对根目录“/”赋了初值,这样做是为了处理一级目录(形如/leet)的父目录。

635 设计日志存储系统
用有序map存储,key为string:时间戳,value为int: id。
存储每个粒度应该截取的长度,注意日志的时间戳和start,end都需要截取粒度长度,一开始忘记substr start和end,导致错误了。
348 设计井字棋
unordered_map(int,pair<int,int>),依次表示该行/列/左对角线/右对角线(0到sz-1存行,sz到2sz-1存列,2sz存左对角线,2*sz+1存右对角线),占位玩家,该玩家占位多少次。
用户下棋时,先判断该行/列/左对角线/右对角线是否已经被占位,若已占位且占位者是自己,那么只需要累加pair的second,若占位者是另一个玩家,则pair的first置为-1,表示废弃,因为该行/列/左对角线/右对角线上两个玩家都有下过棋,在该行/列/左对角线/右对角线上不会有赢家出现。
若没有被占位,则当前玩家占位,first置为自己,second累加。
之后判断该行/列/左对角线/右对角线的pair的second是否=sz,是就诞生赢家。

622 设计循环队列
队首指针(索引)和队尾指针(索引)分别指向0和-1。判满和判空这两个地方要细心一点,q[frontPos]等于-1时候,说明为空。
rearPos!=-1并且q[rearPos]!=-1并且q[frontPos]!=-1并且frontPos=(rearPos+1)%queueSz(即队尾索引和队首索引收尾相邻)时,说明为满。
1188 设计有限阻塞队列
会使用到信号量。

1396.设计地铁系统
一开始做题时候,忽略了一个题意要求:平均时间是从起点站直接到终点站的行程中计算,即这两站应该相邻,中间不得有中转。
数据结构:1.记录无中转的两站之间的信息,key为pair表示起点站和终点站。vector表示该段行程的乘客所用的时间,unordered_map<pair<string,string>,vector<int>>,hash_pair>。hash_pair是我自己写的构造函数,因为unordered_map没有key为pair的构造函数。
2.乘客最新的进站信息,key为乘客id,value为pair形式的站名和进站时间,unordered_map<int,pair<string,int>>。只记录乘客最近的一次进站信息即可。
乘客进站,更新第2个。
乘客出站station2,更新第1个,即从第2个的乘客信息中找到该乘客最近的一次进站记录station1,和当前station2组合为pair,作为第一个数据结构的key,并将该此行程耗用的时间插入该pair对应的vector中。

2349 设计数字容器系统
change(pos,number):对容器指定位置上放值
find(number):返回该数的最小位置
解析:一开始只是用了一个map<int pos,int number>container,实现find函数时,就是对整个map进行遍历,这样会超时。
之后想到了用小根堆。添加了unordered_map<int number,priority_queue<int pos>>numPos。对于每次查找,只需要去numPos[number]中找,这是一个小根堆,只需要判断堆顶元素对应的container位置是否还是number(即判断这个位置是否有被其他值覆盖)。如果已经不是number了,就pop掉,如果仍然是number,就return。















 2500
2500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









