







文章目录
前言

《Frequency-aware Discriminative Feature Learning Supervised by Single-Center Loss for Face Forgery Detection》
这篇论文来自中科大、快手的研究者针对人脸伪造,提出了基于单中心损失监督的频率感知鉴别特征学习框架FDFL,将度量学习和自适应频率特征学习应用于人脸伪造检测,实现SOTA性能。
一、背景与创新
1.背景
-
问题1:目前的检测方法大多数将伪造检测任务转化为二分类任务来处理,用softmax损失来监督网络在自然和篡改人脸的混合数据集上训练。但是在softmax损失监督下学习到的特征没有足够的分辨力,因为softmax损失没有明确的约束类内的紧凑性和类间的离散性。一些研究者也尝试使用三元组损失提取差异性特征。但是,常规的度量学习方法通常是 无差别的约束特征类内的紧凑性,忽略了不同类别 类内分布的差异性。
 这幅图是 样本在嵌入空间中的特征分布。左边是由softmax损失监督的学习特征分布,可以看出来,学习到的特征是 广义可分的,但没有足够的区别性,因为softmax损失没有明确的约束类内的紧凑性和类间的离散性。
这幅图是 样本在嵌入空间中的特征分布。左边是由softmax损失监督的学习特征分布,可以看出来,学习到的特征是 广义可分的,但没有足够的区别性,因为softmax损失没有明确的约束类内的紧凑性和类间的离散性。 -
问题2:之前研究采用的都是 固定的滤波器组和手工制作的特征,不足以从不同的输入 捕获到伪造的频率模式。
2.创新
- 文章为了解决这些问题,提出了一种新的频率感知鉴别特征学习框架(FDFL),这个框架采用 度量学习 和 自适应频率特征学习 用于人脸伪造检测。
- (1)提出了一种新的单中心损失SCL,它能够仅减少自然面孔的类内变化,同时增加嵌入空间的类间差异。(上面右图展示了SCL在约束自然人脸和篡改人脸类间的离散性的同时,只聚合类内差异较小的自然人脸。)
- (2)另一个创新点是开发了自适应频率特征生成模块,它能以数据驱动的方式从频域挖掘细微的伪影。
二、网络结构
2.1 基于频率感知的判别特征学习框架
- 图中是本文提出的 基于频率感知的判别特征学习框架。它是在一个基础网络中增加了 自适应频域特征生成模块(AFFGM)和 特征融合模块。AFFGM由 数据预处理 和 自适应频域信息挖掘模块AFIMB组成。
- 首先,输入图像经过AFFGM和RGB分支 分别提取空间域特征和频域特征,在融合模块中将两种特征进行融合,融合后的特征经过进一步特征提取,得到一维的特征矢量。框架最后是一个分类器,输出预测结果。 整个网络在softmax损失和本文提出的SCL的联合监督下进行端到端训练,网络能够学习一个嵌入空间,使自然人脸聚集在中心点周围,而被操纵的人脸远离中心点。
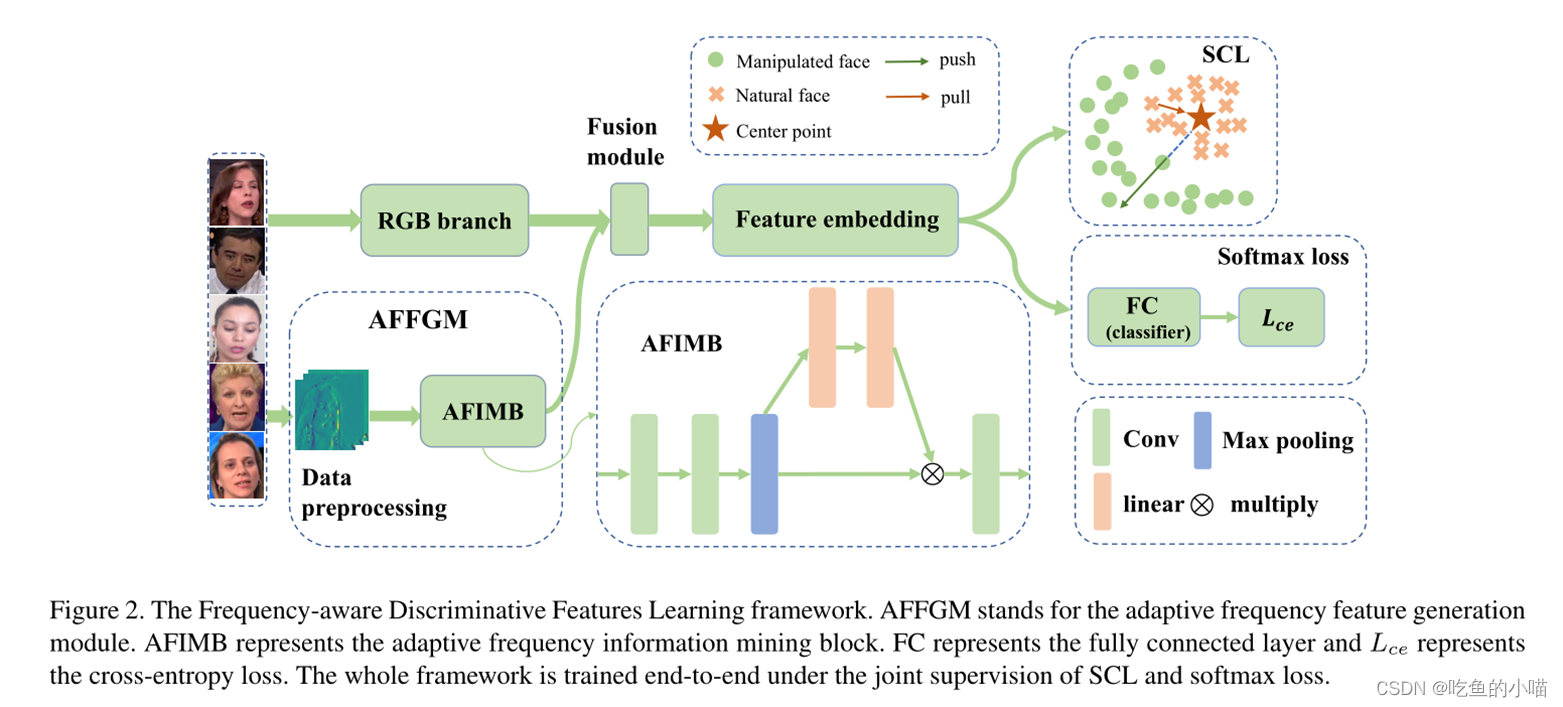
2.2 自适应频域特征生成模块(AFFGM)
-
原理:频域中的不一致性可以作为重要的伪造线索。图3右边的这一列代表 某一频带内能量分布的可视化。可以看出来,尤其是在中频段和高频段,自然人脸和伪造人脸之间的差异非常明显。

-
AFFGM由 数据预处理 和 AFIMB 组成。
(1)图4是数据预处理的流程:
- 首先,将输入的RGB图像转换为YCbCr颜色空间。然后对每个8×8块图像进行 二维DCT变换(这两步类似jpeg压缩)。 DCT变换后,所有图像块中 同一频段的系数 按照原图像块的位置 组合成一个通道。最后把所有的通道组合在一起,正则化后作为AFIMB的输入。
- 经过预处理后的频域图像,既保留了所有频段的信息,也保留了原图像的结构信息,所以可以使用现有的神经网络直接从频域图像中提取特征。

(2)图5是自适应频率信息挖掘块AFIMB
- 作者根据经验设计了一个简单的网络 提取频率特征,经过图4预处理后的数据首先通过一层具有三组3x3卷积 ,将来自Y、Cb、Cr三个不同通道的数据分别进行处理,然后再通过一个普通的3x3的卷积块和一个最大池层。之后为了增强特征,采用了一个通道注意块,由最大池层和两个线性层组成的,最后使用普通1x1卷积进一步提取与频率相关的特征。
- 文中提出的AFIMB以数据驱动的方法从不同的频段中提取差异性特征,避免了使用太多不全面的先验知识。跟固定滤波器组和手工特征相比,能够在频域更灵活地捕捉伪造线索。

2.3 单中心损失(SCL)
- 常规的度量学习方法 它没有考虑不同类别类内分布的差异性,为了解决这个问题,本文提出的SCL在约束自然人脸和篡改人脸 类间离散性的同时,只聚合类内差异较小的自然人脸。SCL不仅最小化了从自然人脸到中心点的距离,同时约束了 篡改人脸到中心点的距离 至少比 自然脸到中心点的距离 大一个界限。公式1是SCL的定义:

Mnat是自然样本到中心点的欧式距离,
Mman是篡改样本到中心点的欧式距离,
由于欧氏距离与特征维数的算术平方根有关,所以为了便于设置超参数,距离的阈值设置为m(根号D)。与中心损失类似,中心点C在每步迭代中不断更新。
- 由于SCL的参数中心是基于小批量而不是整个数据集随机初始化和更新的,会导致不稳定的训练,所以又引入了带有全局信息的softmax损失来指导中心点的更新。
Softmax损失专注于将样本映射到离散标签,SCL主要是将度量学习直接应用于 学习到的嵌入。公式6是总的损失,其中λ是控制SCL和softmax损失之间 权衡的超参数。

三、实验
3.1 数据集
- 本文的实验在FF++数据集上进行的。这是一个面部伪造数据集,包含1000个原始视频,由四种面部操作方法进行了处理。根据不同的压缩因素,数据集有c0(原始)、c23(轻压缩)和c40(重压缩)三个版本。本文实验主要是在c40版本上进行的。
3.2 损失函数对比
为了验证SCL损失,研究人员对各种损失进行了对比:
- 表1是在数据集c40版本上几种损失函数的对比,包括softmax、三元组损失、中心损失、SCL。从表中可以看出,本文的SCL+softmax损失表现最好。而且,与只使用softmax损失相比,使用softmax损失的 三元组损失 和 中心损失 都有细微的改善。

- 图6是在 不同损失函数监督下 特征的可视化。是在数据集c40版本的训练数据集中随机选取5000张自然面孔,分别进行处理。红点代表自然面孔,绿点代表篡改的面孔。
(a)图是在softmax损失监督下 学习到的特征,表现为两个相邻边界的簇。
(b)图是三元组 +softmax损失,跟(a)对比可以看出来,三元组损失对特征分布影响不大。
(c)图是中心损失+softmax损失,特征的分布改变比较明显。但是,限制篡改人脸的类内紧凑性会在一定程度上导致过拟合。因此,性能增益非常小。
(d)图是 SCL + softmax损失,能够将自然人脸紧密地聚集起来,将分布不紧密的篡改人脸分离出来。通过与其他损失函数的对比,证明了本文的SCL优于其他损失。

3.3消融实验
- 第二个实验是消融实验,为了评估每个组件的性能改进。由表3可以看出,SCL和AFFGM在AUC和pAUC0.1 这两个评价指标上都能提高性能。 当分别单独使用SCL和AFFGM组件时,评估指标都有提高。当SCL和AFFGM同时使用形成完整的框架时,效果最好。这充分验证了本文的SCL监督网络 学习更多鉴别特性的能力。

3.4与其他方法对比
- 在FF++数据集三个版本上,本文方法和之前人脸伪造检测方法的比较:
Xception和face-X射线是目前比较先进的基于图像的检测方法。在FF++数据集各种版本上,本文的方法在各个评估指标上都优于它们。而且还超越了,基于视频的双分支(two-branch)检测方法。通过对比表明了该框架的有效性和优越性。
















 4146
4146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









