






arXiv' 2024
paper: https://cz5waila03cyo0tux1owpyofgoryroob.aminer.cn/05/F8/C8/05F8C840C2194888F86FB07EDAA18C40.pdf
code:
Abstract
生成合成假人脸,即伪人脸,是提高DeepFake检测泛化的有效途径。现有的方法通常是通过在色彩空间中混合真实或虚假的人脸来生成这些人脸。虽然这些方法已经显示出希望,但它们忽略了伪假面部频率分布的模拟,限制了对通用伪造痕迹的深入学习。为了解决这一问题,本文介绍了一种通过混合频率知识生成伪人脸的新方法FreqBlender。具体来说,我们研究了主要的频率成分,并提出了一个频率解析网络来自适应地划分与伪造痕迹相关的频率成分。然后将伪人脸的频率知识与真实人脸进行融合,生成伪人脸。由于频率成分没有GT,我们描述了一个专门的训练策略,利用不同频率知识之间的内在相关性来指导学习过程。实验结果证明了我们的方法在增强DeepFake检测方面的有效性,使其成为其他方法的一个潜在的即插即用策略。

1 Introduction
DeepFake指的是可以操纵面部属性(如身份、表情和嘴唇运动[halassos等,2021])的人脸伪造技术。深度生成模型的最新进展[He et al ., 2021;Perov等人,2020]极大地加快了DeepFake技术的发展,使创建高度逼真和视觉上难以察觉的操作成为可能。然而,滥用这些技术可能会带来严重的安全问题[Suwajanakorn等人,2017],使DeepFake检测比以往任何时候都更加紧迫。
已经提出了许多检测DeepFakes的方法,显示了它们在公共数据集上的有效性[Rossler等人,2019;Li et al ., 2020b;Dolhansky等人,2019;Dolhansky et al, 2020;周等,2021]。然而,随着人工智能技术的不断发展,新的伪造类型不断出现,这对目前的检测器准确指出未知的伪造提出了挑战。为了应对这一挑战,最近的努力[Li和Lyu, 2018;Li et al ., 2021;yan等,2023;Wang等人,2023]专注于提高检测的泛化性,即基于已知示例检测未知伪造的能力。解决这个问题的一个有效方法是通过生成合成的假脸来增强训练数据,称为伪脸。
这种方法背后的知识是,DeepFake生成过程在混合人脸的步骤中引入了伪影,这些方法通过模拟各种混合伪影来生成伪假人脸。通过对这些伪人脸进行训练,可以驱动模型学习相应的伪影[Li et al ., 2020a;赵等,2021;Shiohara和Y amasaki, 2022]。然而,现有的方法主要集中在模拟人脸混合的空间方面。虽然他们可以使伪假脸在颜色空间上的分布类似于野生假脸,但他们没有探索在频率空间上的分布。因此,基于频率的伪造线索缺乏当前的伪假面孔,限制了模型学习通用伪造特征。
在本文中,我们将注意力从颜色空间转移到频率空间,并提出了一种名为FreqBlender的新方法,通过混合频率知识来生成伪假人脸(见图1)。我们的想法是分析频率空间的组成,准确识别伪造线索落入的范围。然后我们用相应的假脸范围替换这一范围的真实脸来生成伪假脸。然而,伪造线索在频率空间中的准确分布具有一定的挑战性,主要有两个原因:1)伪造线索对人脸内容的高度依赖性导致不同伪造人脸的频率范围不同;2)伪造线索可能不是集中在单一频率范围内,而是多个频率范围内不同部分的集合。因此,一般的低通、高通或带通滤波器不能精确地确定分布。
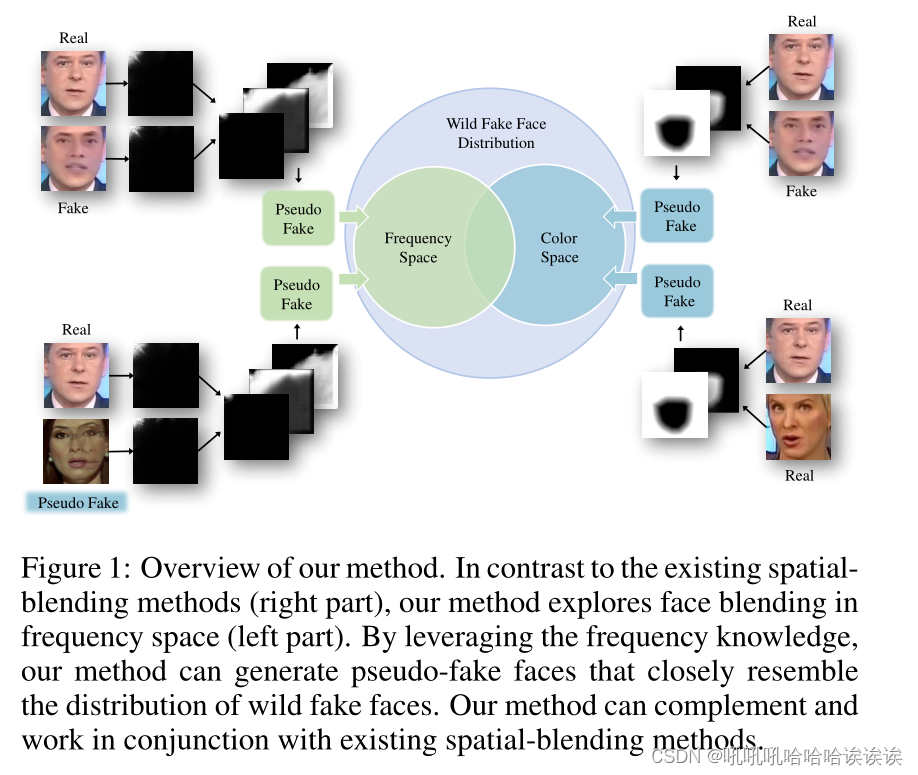
为了解决这一挑战,我们提出了一个频率解析网络(FPNet),它可以根据输入人脸自适应地划分频率空间(见图5)。具体来说,我们假设这些人脸由三种频率知识组成,分别代表语义信息、结构信息和噪声信息。这一假设在我们的初步分析中得到了验证(详见第3节)。我们认为伪造痕迹可能隐藏在结构信息中。在此基础上,我们设计了由一个共享编码器和三个共享解码器组成的网络来提取相应的频率知识。编码器将输入数据转换为潜在频率表示,而解码器则估计相应频率知识的概率图。
由于没有提供频率分布的GT,因此训练该网络是不简单的。因此,我们提出了一种新的训练策略,利用不同频率知识之间的内在相关性。具体来说,我们描述了在每个解码器输出的各种混合组合上执行的专门制作的目标,并强调了每个频率知识的属性(详细信息参见第4节)。实验结果表明,在提出的训练策略下,网络成功地解析出所需的频率知识。
一旦对网络进行训练,我们就可以解析假人脸的结构信息所对应的频率分量,并将其与真实人脸混合生成伪人脸。值得注意的是,我们的方法与现有的空间混合方法并不冲突,而是通过解决频率空间中的缺陷来补充它们。我们的方法在多个最新的DeepFake数据集上进行了验证(例如,FF++ [Rossler等人,2019],CDF [Li等人,2020b], DFDC [Dolhansky等人,2020],DFDCP [Dolhansky等人,2019],FFIW [Zhou等人,2021]),并与许多最先进的方法进行了比较,证明了我们的方法在提高检测性能方面的有效性。
本文的贡献可以概括为三个方面:
1. 据我们所知,我们是第一个通过混合频率知识来生成合成假脸的。我们的方法使合成假脸更接近野生假脸的分布,增强了DeepFake检测中对通用伪造特征的学习。
2. 我们提出了一种频率解析网络,可以自适应地分别对语义信息、结构信息和噪声信息对应的频率分量进行划分。由于没有提供GT,我们设计了专门的目标来训练这个网络。
3. 在几个DeepFake数据集上的大量实验结果证明了我们的方法的有效性,以及它作为现有方法的即插即用策略的潜力。
2 Related Works
人工智能生成模型的快速发展催生了DeepFake检测方法的发展。这些方法主要依靠深度神经网络利用各种特征来识别真假人脸之间的不一致性,包括生物信号[Zhou and Lim, 2021]、空间伪影[Bai et al ., 2023;Li et al ., 2020a;赵等,2021;Shiohara and Y amasaki, 2022],频率异常[Wang et, 2023;苗等,2022;Gu et al ., 2022],以及来自专用设计模型的自学习线索[Cao et al ., 2022;徐等,2023]。这些方法在公共数据集上显示出了令人鼓舞的结果。然而,当面对未知的DeepFake人脸时,由于有限的训练数据集导致的较大分布差异,它们的一些性能会显著下降。为了解决这个问题,已经提出了许多方法来通过学习通用的DeepFake痕迹来提高其泛化性,例如Face X-ray [Li等,2020a], I2G [Zhao等,2021],SBI [Shiohara和Y amasaki, 2022]。一种有效的方法是在训练过程中生成合成假脸,称为伪假脸。通过增加训练人脸的多样性,可以减少野生假人脸分布的差距,使模型能够学习不同分布的不变DeepFake痕迹。
为了生成伪假人脸,最近的方法设计了混合操作来组合不同的人脸。这包括从源图像中提取人脸区域并将其混合到目标图像中。例如,DSP-FWA [Li and Lyu, 2018]是一种开创性的方法,通过自混合来模拟假脸。几种扩展变体[Li et al ., 2020a;赵等,2021;Shiohara and Y amasaki, 2022;Chen等人,2023]已经提出使用组织策略混合人脸,进一步提高检测性能。
然而,这些方法忽略了野生假人脸在频率空间中的分布。虽然合成的人脸可能类似于基于空间的分布,但缺乏对频率视角的考虑阻碍了模型学习基本的通用DeepFake痕迹。因此,本文引入了一种混合频率知识生成伪假人脸的新方法,为现有方法提供了补充。
3 Preliminary Analysis
我们对真假人脸的频率分布进行了统计分析,并分别给出了语义信息、结构信息和噪声信息对应的主要频率分量的初步结果。
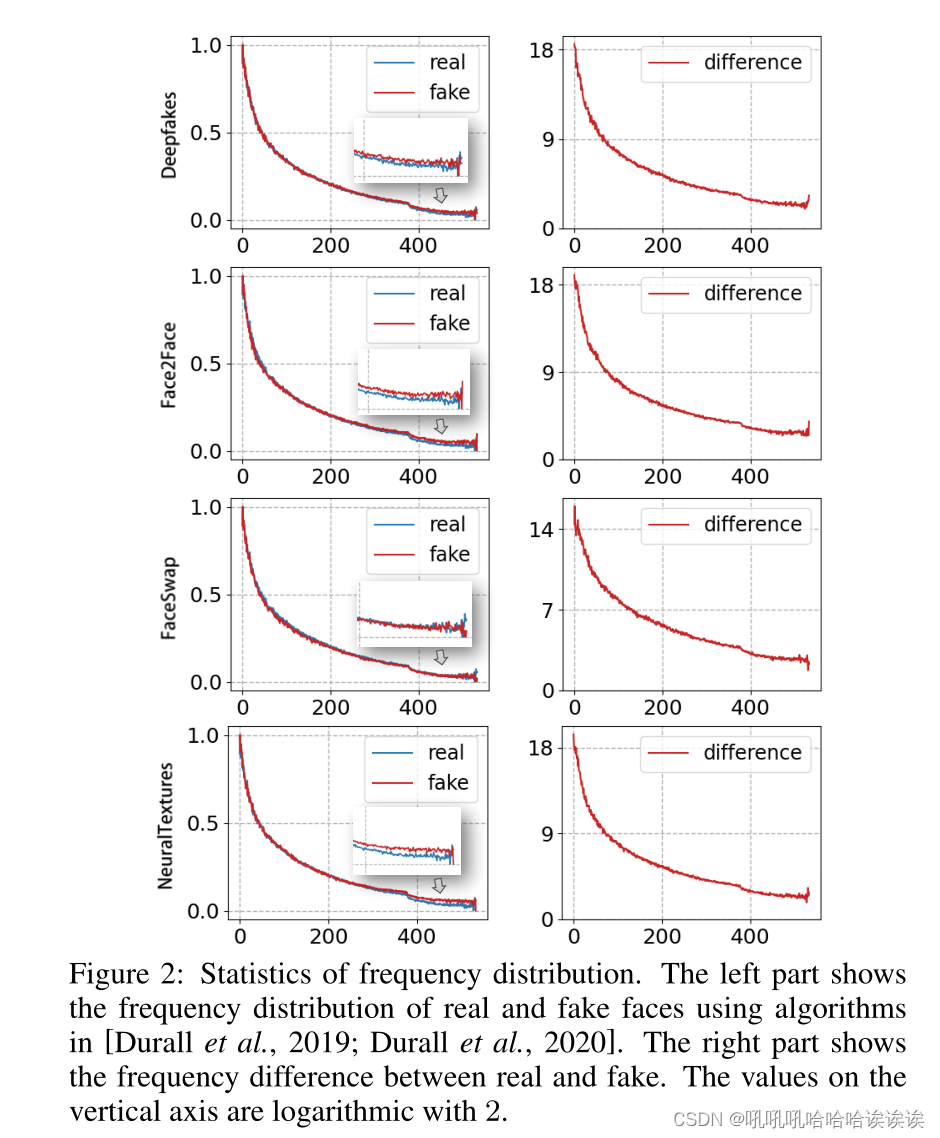
Inspiration and Verification. 灵感和验证。前期研究[Jia et al ., 2022;Durall等人[2020]指出,伪造痕迹主要存在于高频区域。然而,这些区域的精确范围并没有被描述,这促使我们重新研究伪造痕迹的频率分布。
具体来说,我们使用FaceForensics++ (FF++) [Rossler等人,2019]数据集进行验证实验。我们从所有视频中提取帧,并为每种处理方法(例如,DF, F2F, FS和NT)随机选择3,000个真实图像和3,000个假图像。然后,我们使用人脸检测器(King, 2009)裁剪出这些选定图像中的人脸区域,并应用DCT (Qian et al ., 2020)生成频率图。为了进行分析,我们将真假图像的所有频率图相加,并采用先前工作中描述的方位角平均的可视化过程[Durall et al, 2019;Durall et al ., 2020]。这一过程包括对数变换和环形孔径中方位平均通量的计算。将环形孔径的中心放置在频率图的左上角,我们可以得到表示频谱图的一维阵列。其分布的可视化结果如图2所示。可以看出,这一数字与[Jia et al ., 2022]的结果是一致的。然而,当我们直接绘制它们的分布差异时,结果与前面的图不匹配。可以看出,高频区域的差异并不像预期的那么大,而较低范围的差异变得更加明显。这是因为对数运算减轻了低频范围的差异程度,造成了一种错觉,即只有高频范围才显示出真脸和假脸之间的差异。因此,我们推测,伪造痕迹可能不仅集中在高频范围内,而且可能延伸到低频范围。
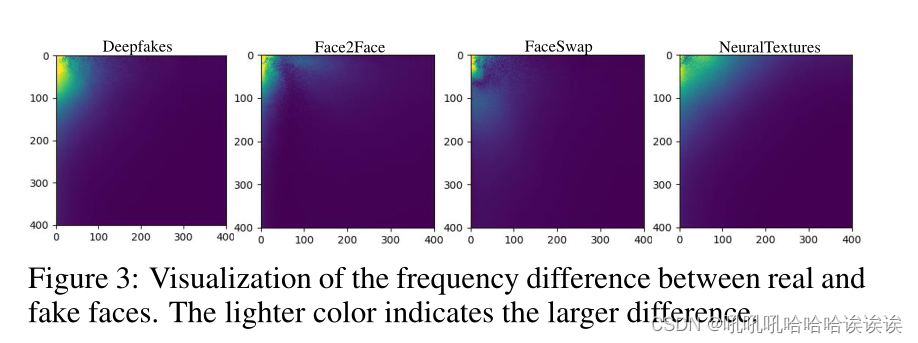
Hypothesis and Validation. 假设与验证。如图2所示,在非常低的频率范围内,可以观察到最显著的差异。鉴于真脸和假脸在外观上的显著差异,我们假设语义信息主要在这个低频波段表示。此外,我们假设中高频成分捕获了结构信息,使它们更容易包含伪造痕迹。此外,我们假设最高频率分量可能对应于各种视频预处理操作(如压缩、解压缩和编码)引入的噪声。
为了验证我们的假设,我们在图3中直接可视化了真实人脸和假人脸在频率图上的差异。通过观察这些结果,我们经验地将频率图分成三个不重叠的波段。拆分操作遵循一般的带通滤波器。表示频率图中的位置为(x, y),其中(0,0),(1,1)表示左上角和右下角。具体来说,我们将x + y≤1/16的区域识别为包含语义信息的区域,将1/16 < x + y≤1/2的区域识别为包含结构信息的区域,将x + y > 1/2的区域识别为包含噪声信息的区域。相应的结果显示在图4中,验证了这三个范围提供了与我们的频率分布假设一致的经验证据。


4 FreqBlender
本文描述了一种通过混合特定频率知识来生成伪假脸的新方法。其动机是现有的方法只关注色彩空间的混合,而忽略了真假人脸在频率空间上的差异。通过对频率分布的考虑,伪人脸可以与假人脸非常接近。为了实现这一目标,我们提出了一个频率解析网络(FPNet),将频率空间划分为三个分量,分别对应于语义信息、结构信息和噪声信息。然后,我们将假人脸的结构信息与真实人脸混合以生成假人脸。频率解析网络的细节将在4.1节中详细阐述,该网络的目标和训练过程将在4.2节中描述。然后在第4.3节中介绍我们的方法与现有方法的部署。
4.1 Frequency Parsing Network
Overview. 频率解析网络(FPNet)由一个共享编码器和三个独立的解码器组成。编码器将输入人脸转换为频率关键特征,解码器的目的是对编码器的特征进行分解并提取相应的频率分量。
将编码器表示为E,三个解码器分别表示为Dsem, Dstr, Dnoi。给定一个输入人脸图像x∈x∈{0,255}h×w×3,我们首先将该人脸转换为频率映射ϕ (x)∈Rh×w×3,其中ϕ表示离散余弦变换(DCT)的操作。然后将该频率图送入模型,生成三个分布图,分别为Dsem(E(ϕ (x)))∈[0,1]h×w, Dstr(E(ϕ (x)))∈[0,1]h×w, Dnoi(E(ϕ (x)))∈[0,1]h×w。每个分布图表示对应的频率分量分布在该频率分布图中的概率。根据这些分布图,我们可以方便地选择相应的频率分量。例如,与语义信息相对应的频率分量可以采用:ϕsem(x) = ϕ(x)Dsem(E(ϕ(x)),其他两个频率分量也可以采用同样的方法,即:ϕstr(x) = ϕ (x)Dstr(E(ϕ(x)))和ϕnoi(x) = ϕ (x)Dnoi(E(ϕ(x)))。FPNet的概述如图5(左)所示。

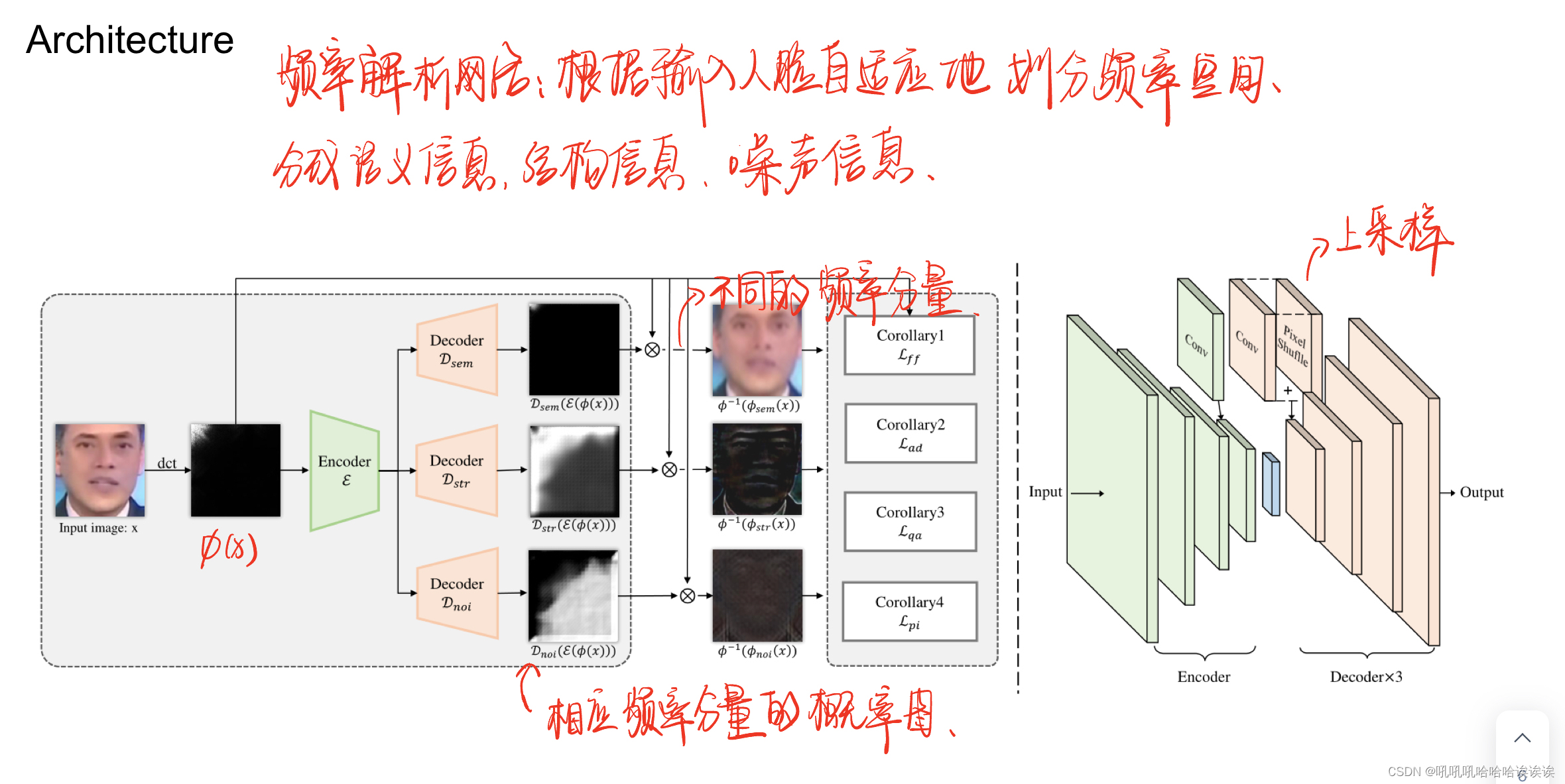

Network Architecture. 编码器由四个卷积层组成,内核大小为3 × 3,步幅为2,填充为1。每个解码器也由四层组成,每层是卷积层和PixelShuffle操作[Shi等人,2016]的组合(见图5(右))。
4.2 Objectives for Training Frequency Parsing Network 训练频率解析网络的目标
我们的方法中最具挑战性和最关键的方面是训练网络进行频率解析,因为对于不同的频率成分没有可用的GT。
值得注意的是,训练中唯一可用的监督资源是我们在第3节中初步分析的结果。然而,这些结果不准确,对不同的输入不适应,这对模型的训练是不够的。因此,我们精心设计了一些辅助目标来指导网络的学习,允许网络的自我完善。
这些目标是基于以下命题设计的。
Proposition 1。 命题1。每个频率分量都具有以下特性:
1. 语义信息可以反映面部身份。
2. 结构信息是伪造痕迹的载体。
3. 噪声信息对视觉质量的影响最小。
4. 初步分析结果普遍适用。
Corollary 1。推论1。对于给定的人脸x,基于其语义信息的转换后的人脸将保留与x相同的面部身份,即∀x∈x∈{0,255}h×w×3, F(ϕ - 1(ϕsem(x))) = F(x),其中F表示人脸识别模型,而ϕ - 1表示逆离散余弦变换(IDCT)。
Facial Fidelity Loss. 面部保真度损失。我们引入了面部保真度损失Lfid来补偿输入的人脸图像与语义信息表示的空间内容之间的身份差异。为了测量身份差异,我们采用MobileNet [Howard等人,2017]作为我们的人脸识别模型,并使用ArcFace [Deng等人,2021;梁等,2022]进行训练。我们选择MobileNet是因为它在计算效率和识别精度之间取得了平衡。设F为MobleNet, Ff (x)为从人脸图像x中提取的人脸特征,人脸保真度损失可定义为
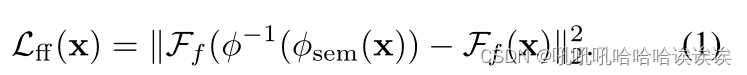
请注意,输入的人脸x可以是真实的,也可以是假的,因为在这两种情况下都存在身份信息。
Corollary 2. 推论2。对于给定的真实人脸Xr,当且仅当它插入了假人脸Xf的结构信息,即D(Xr) = 0 iff Xr←Xr⊕ϕstr(Xf),其中D表示在{0,1}中标记为fake和real的Deepfake检测器,⊕表示插入操作。
Authenticity-determinative Loss. Authenticity-determinative损失。这种损失是为了强调结构信息的决定性作用。为了评估人脸的真实性,我们开发了一个DeepFake检测器D,该检测器使用ResNet-34 [He et al ., 2016]对真实和虚假的人脸进行了训练。然后通过混合频率分量构造两组人脸。
第一组包含三种类型的人脸,由对应的频率分量变换而成,分别是:1)真实人脸的语义信息,2)假人脸的语义信息,3)真实人脸的语义信息与真实人脸的结构信息混合。我们这组记为Cr ={ϕ−1(ϕsem (xr)),ϕ−1(ϕsem (xf)),ϕ−1(ϕsem (xr) +ϕstr (xr))}。因为在这个集合中没有假人脸的结构信息,所以所有的人脸都应该被检测为真实的。
同样,第二组包含两种类型的脸:1)将假脸的语义信息与假脸的结构信息混合,2)将真脸的语义信息与假脸的结构信息混合。我们这组记为Cf ={ϕ−1(ϕsem (xf) +ϕstr (xf)),ϕ−1(ϕsem (xr) +ϕstr (xf))}。由于该集合中所有的混合人脸都包含假人脸的结构信息,因此它们应该被检测为假人脸。因此,确定真实性的损失Lad可以写成
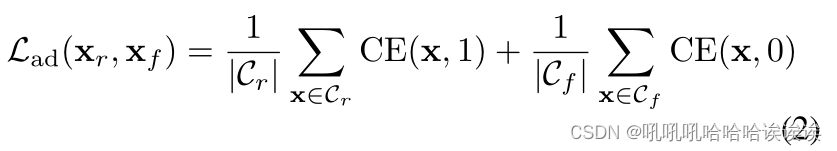
其中CE为交叉熵损失。

Corollary 3. 推论3。如果去除噪声信息的频率成分,则人脸应该没有明显的变化,即∀x∈x∈{0,255}h×w×3, x≈x ⊖ϕnoi(xf),其中⊖表示去除操作。
Quality-agnostic Loss. Quality-agnostic损失。由于噪声信息不包含图像整体描述的决定性细节,因此期望人脸图像与使用语义和结构信息的频率分量变换的人脸图像相似。这种相似性可以使用与质量无关的损失Lqa来量化,定义为
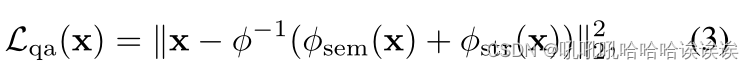
脸x可以是真的也可以是假的。
Corollary 4. 推论4。每个频率分量都受初步结果的约束,即预测的频率分量与初步分析的近似频率分布之间不存在显著偏差。
Prior and Integrity Loss. 先验和完整性损失。根据我们在初步分析一节中的分析,我们对近似频率分布有了初步的了解。将语义、结构和噪声信息的初始频率映射分别表示为msem、mstr、mnoi。这些映射被用来加速模型向期望方向的收敛。此外,我们增加了对它们分布完整性的约束,以确保它们的组合覆盖频率映射的所有元素。这个损失Lpi可以表示为

其中1表示所有元素都为1的掩码。
Overall Objectives。总体目标。总目标是所有这些损失项的总和,即
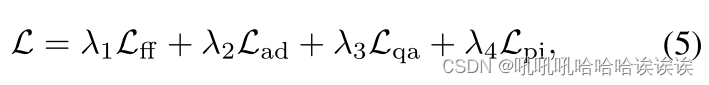 其中λ1 λ2 λ3 λ4是不同损失项的权值。
其中λ1 λ2 λ3 λ4是不同损失项的权值。

4.3 Deployment of FreqBlender
给定一张假脸xr和一张真脸xf,我们可以通过以下生成伪假脸
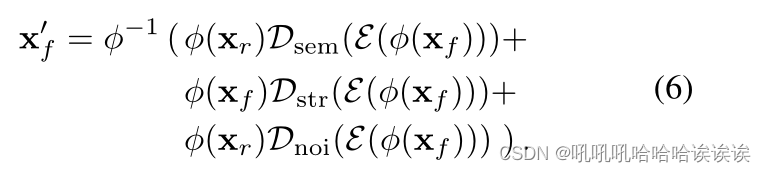
请注意,在我们的方法中,没有必要使用野生假脸执行混合。取而代之的是,我们可以巧妙地用现有空间人脸混合方法生成的伪假人脸代替野生假人脸。它使我们能够克服现有伪假人脸频率分布的限制。此外,图1的左下角显示了一个这样的例子。
5 Experiments
5.1 Experimental Setups
DataSets. 数据集。我们的方法使用了几个标准数据集进行评估,包括FaceForensics ++ [Rossler等人,2019](FF++)、Celeb-DF (CDF) [Li等人,2020b]、DeepFake检测挑战(DFDC) [Dolhansky等人,2020]、DeepFake检测挑战预览(DFDCP) [Dolhansky等人,2019]和FFIW-10k (FFIW) [Zhou等人,2021]数据集。具体来说,FF++数据集由1000个原始视频和4000个处理过的视频组成,对应于四种不同的处理方法,即Deepfakes (DF)、Face2Face (F2F)、FaceSwap (FS)和NeuralTextures(NT)。CDF数据集包括590个原始视频和5639个高质量的假视频,这些视频是由DeepFake对youtube上可用的名人视频进行修改而创建的。DFDC是一个大规模的deepfake数据集,由10万个视频片段组成,DFDCP是DFDC的预览版本,也广泛用于评估。FFIW数据集包含8250个原始视频和8250个带有多人脸场景的DeepFake视频。我们按照数据集提供的原始训练和测试分割进行实验。
Compared Methods. 比较的方法。我们的方法与四种基于视频的检测方法进行了比较,包括Two-branch [Masi等人,2020]、DAM [Zhou等人,2021]、LipForensics [Haliassos等人,2021]和FTCN [Zheng等人,2021]。此外,我们还采用了七种帧级最先进的方法进行比较,分别是DSP-FWA [Li and Lyu, 2018]、Face X-ray[Li et al, 2020a]、LRL [Chen et al, 2021]、FRDM [Luo et al, 2021]、PCL [Zhao et al, 2021]、DCL [Sun et al, 2022]、SBI [Shiohara and Y amasaki, 2022]。
Implementation Details. 实现细节。我们使用普通的EfficientNet-b4 [Tan and Le, 2019]作为我们的检测模型。在训练阶段,将图像大小设置为400 × 400。批大小设置为4,使用Adam优化器,初始学习率为1e−4。训练epoch设置为200。在训练过程中,我们实时制作假脸。我们首先使用空间混合方法SBI生成合成人脸,然后使用我们的方法以α的概率决定它们是否与真实人脸混合。在主实验中,我们将其设置为0.2(更多分析见补充)。Eq.(5)中目标函数的超参数设为:λ1 = 1/12, λ2 = 1, λ3 = 1e−3,λ4 = 1/4。在训练和测试阶段,我们根据[Shiohara和Y amasaki, 2022]在每个视频中随机选择8帧。
5.2 Results
为了展示我们方法的有效性,我们只在FF++数据集上训练我们的方法,并在其他不同的数据集上测试它。根据之前的工作[Shiohara and Y amasaki, 2022;Bai等人,2023],我们采用帧级接收器工作特性曲线下面积(AUC)作为评估指标。
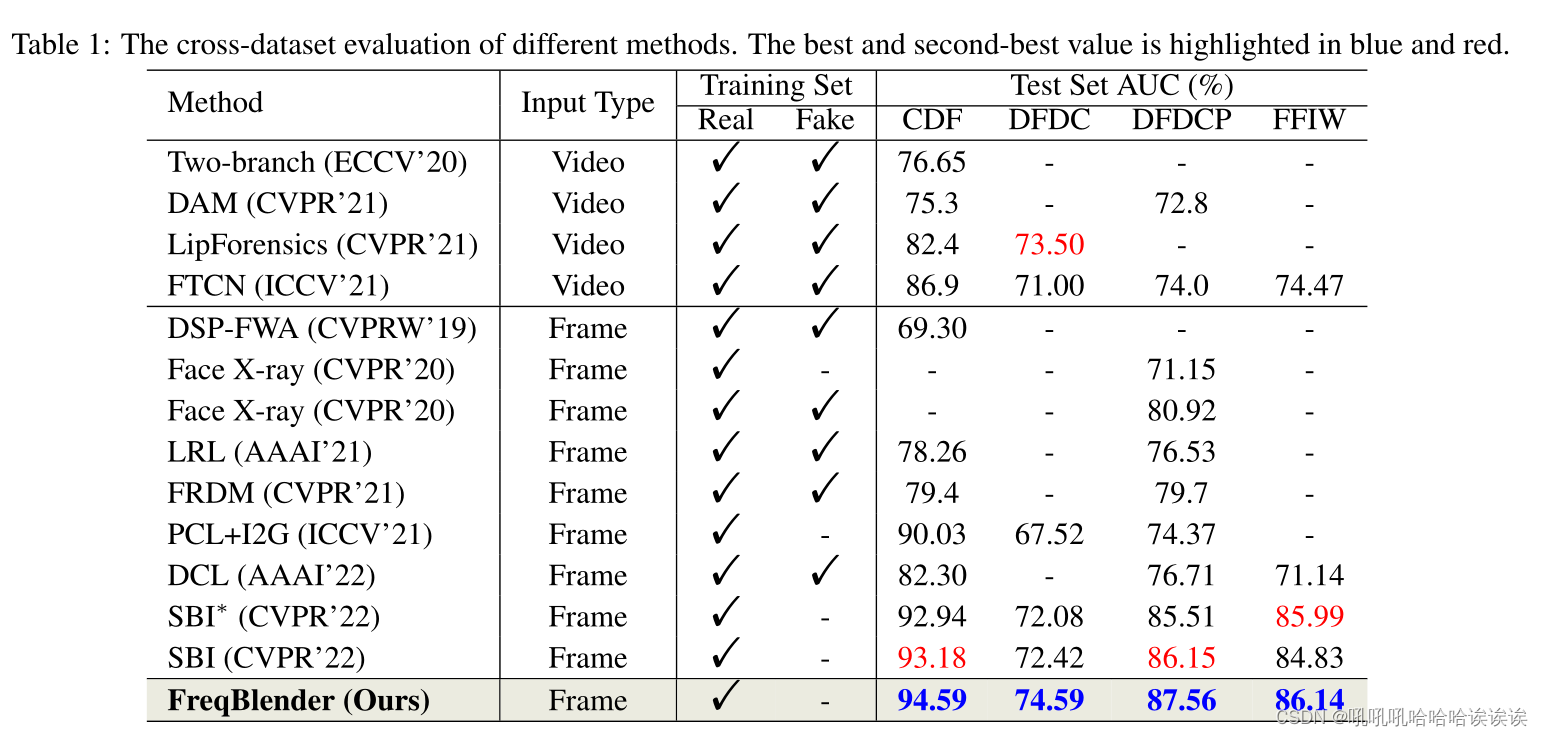
Cross-dataset Evaluation. Cross-dataset评估。与表1中的其他方法相比,我们评估了我们方法的跨数据集性能。最好的成绩用蓝色标出,第二好的用红色标出。需要注意的是,我们的方法是在SBI生成的伪假人脸上操作的,因此我们不需要假人脸。与视频级方法相比,我们的方法达到了最好的性能,大大优于所有方法。具体来说,我们的方法在CDF、DFDC、DFDCP和FFIW数据集上分别比最先进的FTCN方法高出7.69%、3.59%、14.41%、11.67%。
与帧级方法相比,我们的方法仍然优于其他方法。例如,我们的方法在CDF, DFDC, DFDCP, FFIW上的性能分别比最先进的SBI方法提高了1.41%,2.17%,1.41%,1.31%。这种改进可归因于伪假人脸中加入了频率知识,增强了检测模型的泛化。注:SBI*表示使用官方发布的代码获得的性能。结果与报告的分数密切一致,这验证了我们对其代码配置的正确性。在随后的实验中,我们使用它们的发布的代码进行比较。
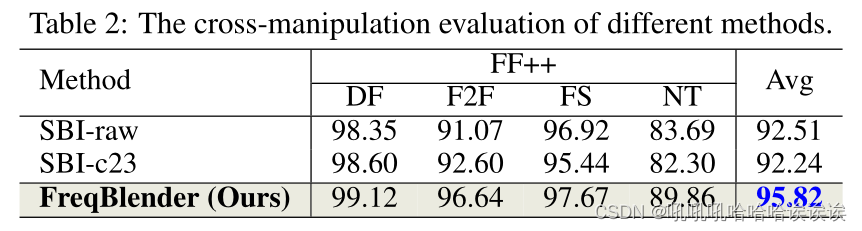
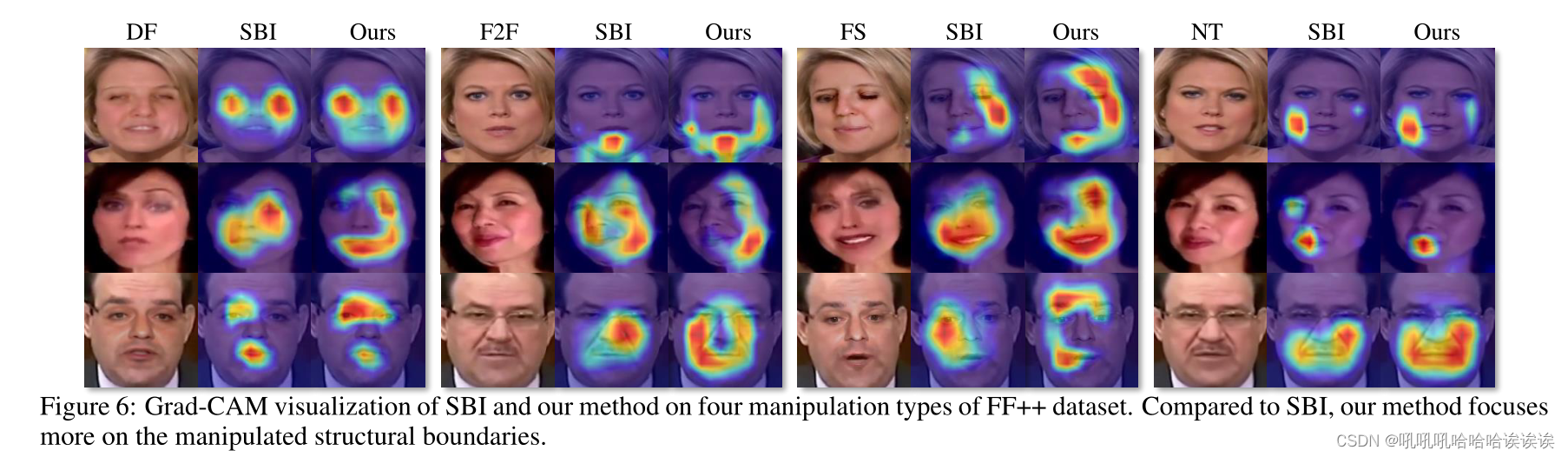
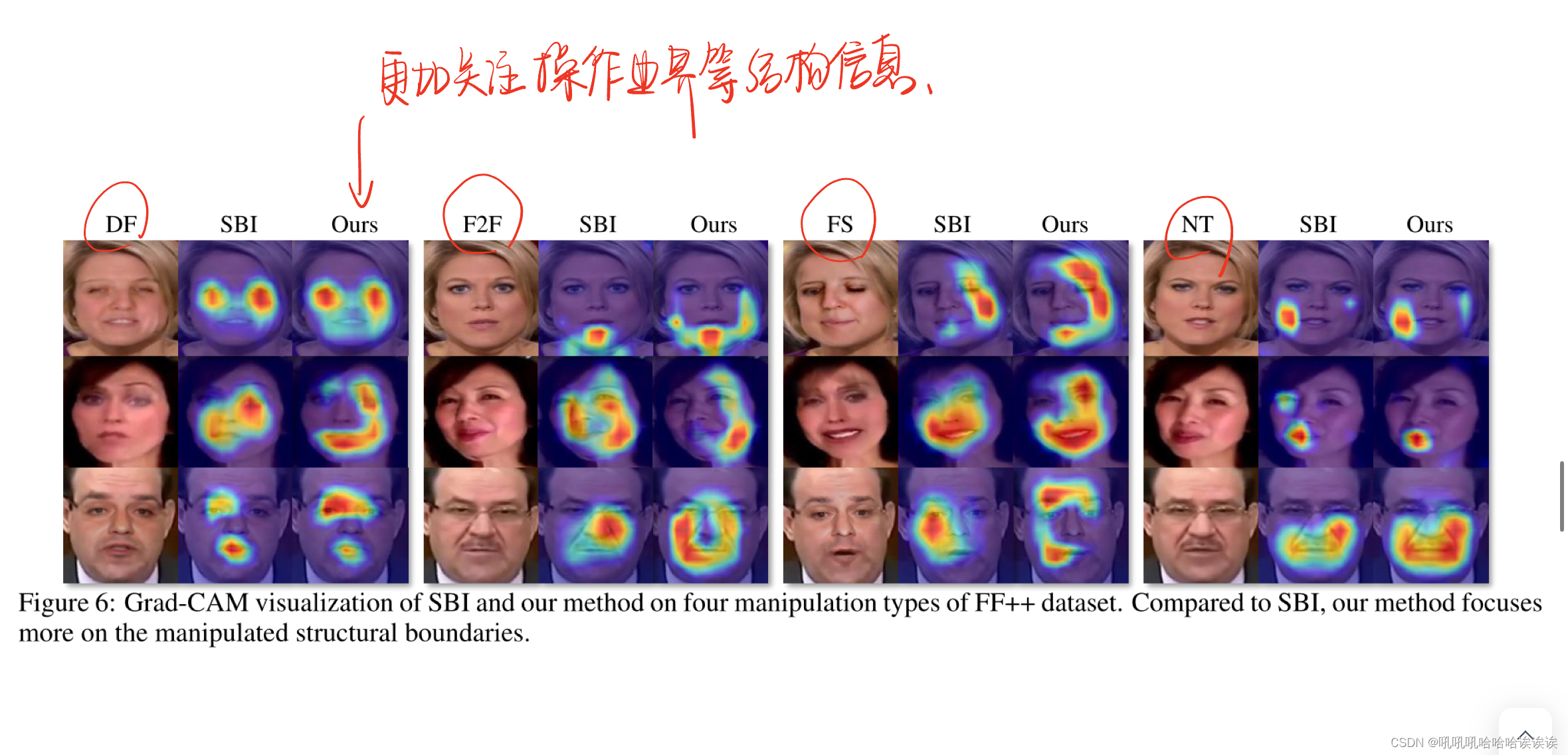
Cross-manipulation Evaluation. Cross-manipulation评估。由于SBI是最新和最有效的方法,我们将我们的方法与它进行比较以进行演示。具体来说,我们将我们的方法与SBI方法的两种变体进行了比较。第一个是使用FF++数据集中的真实视频的原始集进行训练,而第二个是使用c23集进行训练。根据标准协议,所有方法都在c23视频上进行了测试。结果如表2所示。可以看出,我们的方法比SBI-raw和SBI-c23分别高出3.31%和3.58%,证明了我们的方法在交叉操作场景显著性可视化上的有效性。我们使用Grad-CAM [Selvaraju等人,2020]来可视化我们的方法与SBI在FF++数据集中的四种操作上的注意力。相对于SBI,我们的方法更关注操作边界等结构信息。例如,我们的方法在DF、F2F和FS中突出面部轮廓,而在NT中重点突出嘴巴轮廓。
5.3 Ablation Study
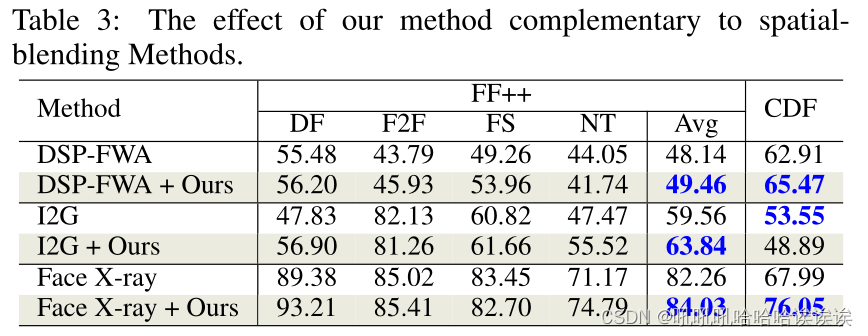
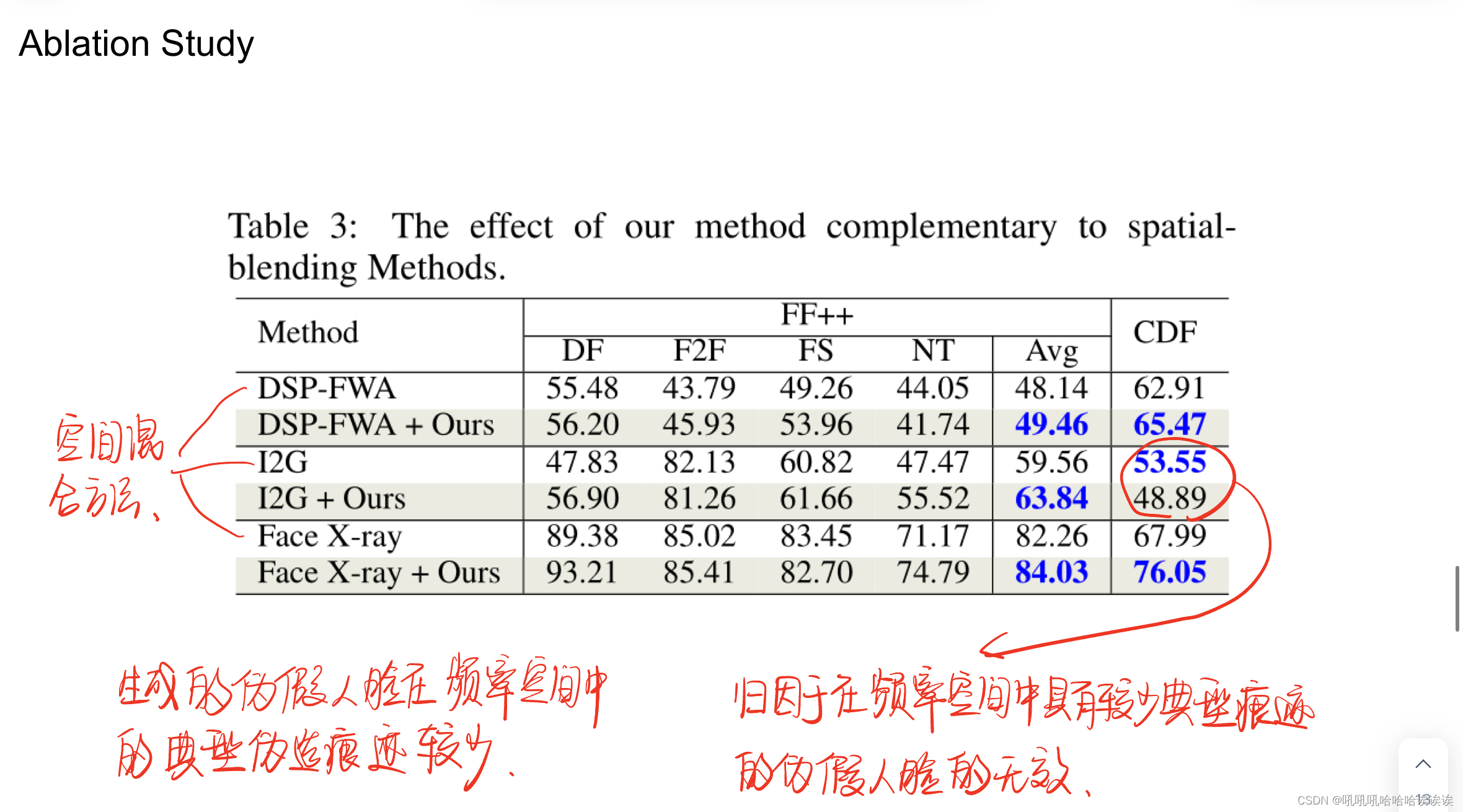
Complementary to Spatial-blending Methods. 补充空间混合方法。为了验证该方法的互补性,我们将SBI方法替换为其他空间混合方法,并研究其性能是否有所提高。具体来说,我们在DSP-FW A、I2G和face X-ray中重现了伪假人脸生成操作,并将它们与我们的方法结合起来。请注意,I2G和Face X-ray并没有发布它们的代码,我们严格按照它们的原始设置重新实现它们。FF++和CDF数据集的结果如表3所示。可以看出,结合DSP-FWA,我们的方法在FF++上平均提高1.31%,在CDF上平均提高2.56%。在Face X-ray中也观察到类似的趋势,在FF++上平均提高1.78%,在CDF上平均提高8.06%。对于I2G,我们在FF++上提高了4.28%的性能,但在CDF上下降了。我们将其归因于在频率空间中具有较少典型痕迹的伪假人脸的无效。这些结果表明,我们的方法可以弥补空间混合方法中频率知识的不足,并与它们协同改进。
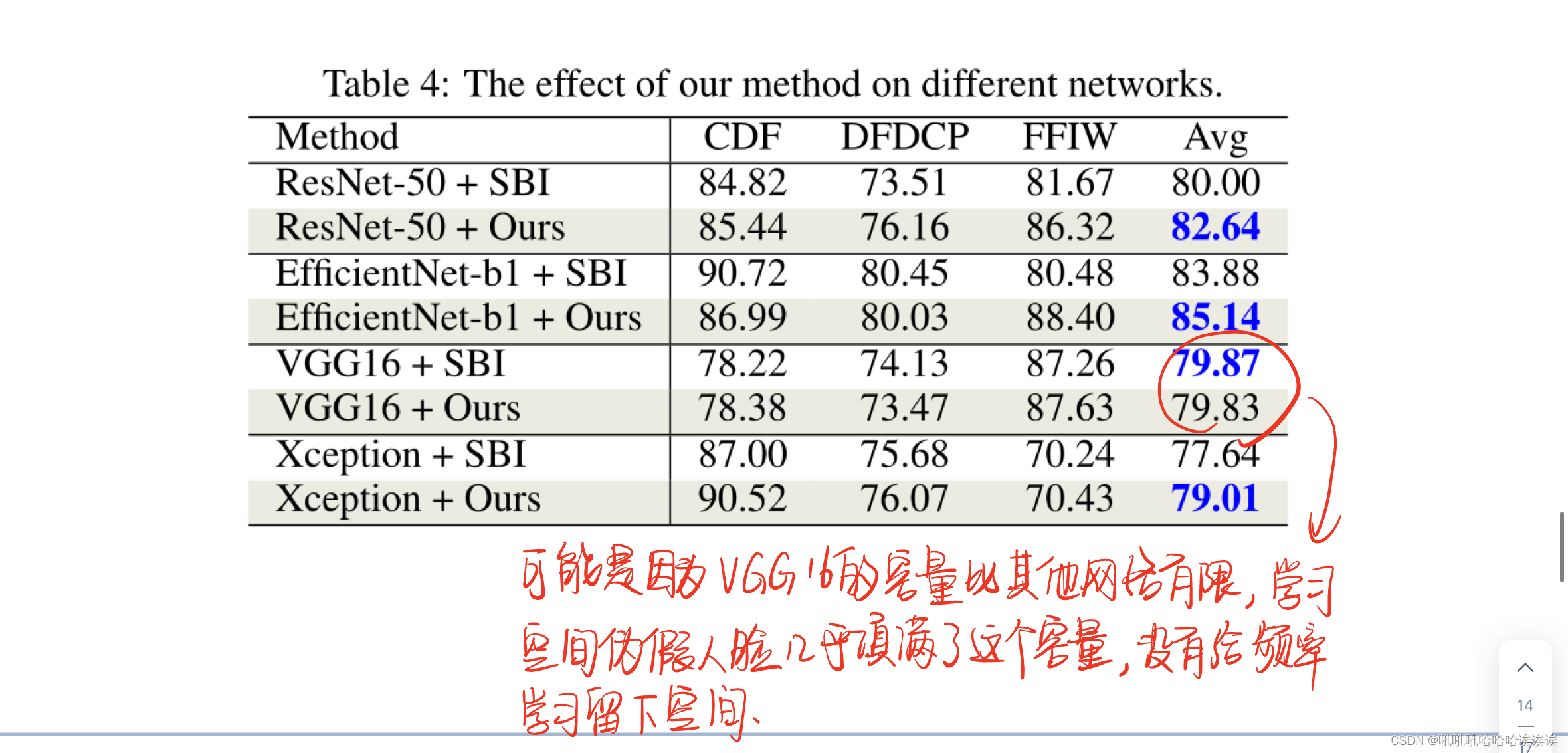
Different Network Architectures. 不同的网络架构。这一部分验证了我们的方法在不同网络上的有效性,包括ResNet-50 [He et al ., 2016], EfficientNet-b1 [Tan and Le, 2019], VGG16 [Simonyan and Zisserman, 2014]和Xception [Chollet, 2017]。我们将我们的方法与SBI在这些网络上进行了比较,并在CDF、DFDCP和FFIW数据集上进行了测试。结果如表4所示。可以观察到,我们的方法在ResNet-50、EfficientNet-b1和Xception网络上的平均性能分别提高了2.64%、1.26%和1.37%。值得注意的是,我们的方法略微降低了VGG16的性能0.04%。这可能是因为VGG16的容量比其他网络有限,学习空间伪假脸几乎填满了这个容量,没有给频率知识的学习留下空间。

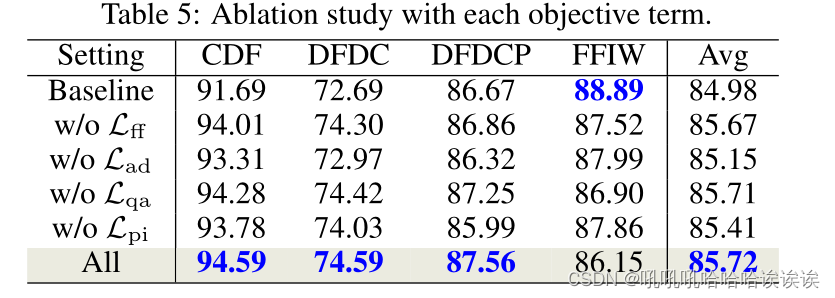
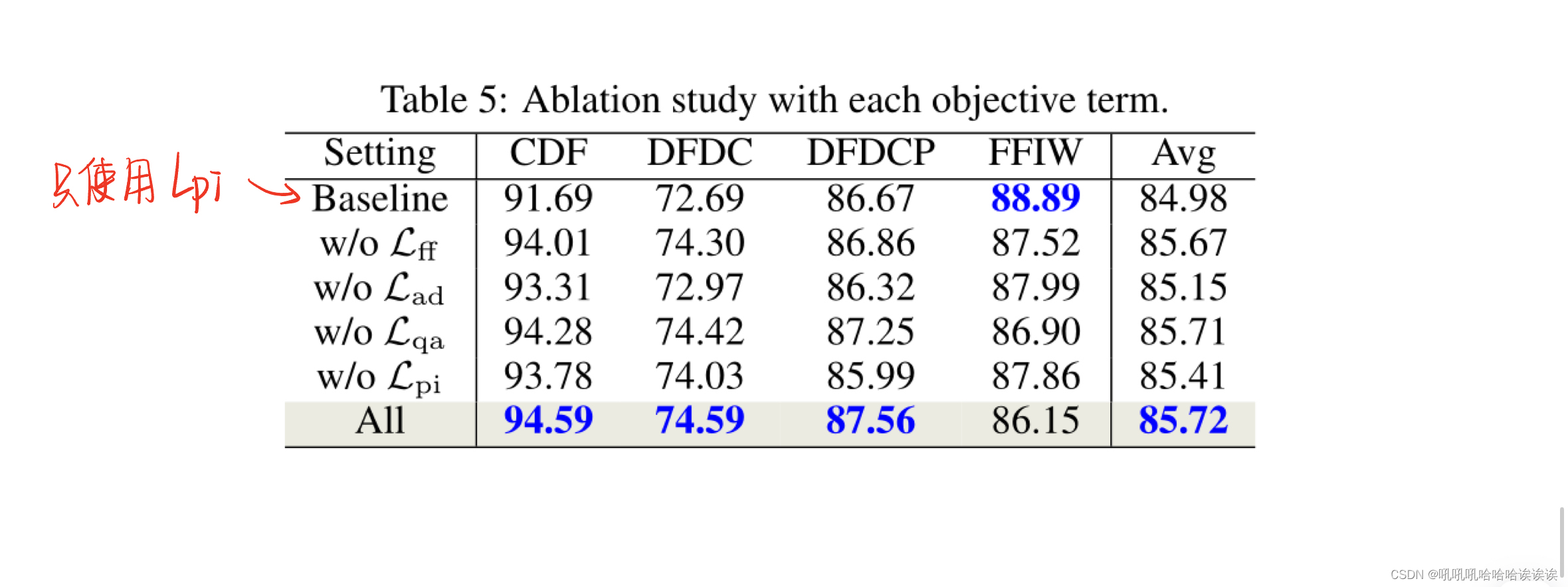
Effect of Each Objective Term.每个目标项的效果。本部分研究了各目标项对CDF和DFDCP数据集的影响。结果如表5所示。注意,Baseline表示只使用先验和完整性损失Lpi,而“w/o”表示不使用。可以看出,没有特定的目标项,在CDF或DFDCP数据集上的性能都会下降,这表明不同的目标项有不同的影响,它们的集体对我们的方法贡献最大。
6 Conclusion
本文介绍了一种通过混合频率知识生成伪人脸的新方法——FreqBlender。为了实现这一目标,我们提出了一种自适应提取与结构信息相对应的频率分量的频率解析网络。然后我们可以将这些假脸的信息混合到真实的脸中来创建假脸。大量的实验证明了该方法的有效性,可以作为现有空间混合方法的补充模块。

















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









