







 超级会员免费看
超级会员免费看
一、论文信息
论文名称:Joint Audio-Visual Deepfake Detection
会议:ICCV2021
作者团队:

二、动机与创新
动机
Visual deepfake上有许多检测方法和数据集,而对audio deepfake以及visual-audio两种模式之间的deepfake方法较少。Audio Deepfake主要有两个任务:1)TTS: text-to-speech文本转语音;2)VC:voice conversion语音转换(将一个人语音转为另一个人的声音)。
创新
本文提出一种新的视觉-听觉Deepfake联合检测任务,利用视觉和听觉两种模式之间的内在关系可以帮助deepfake检测。
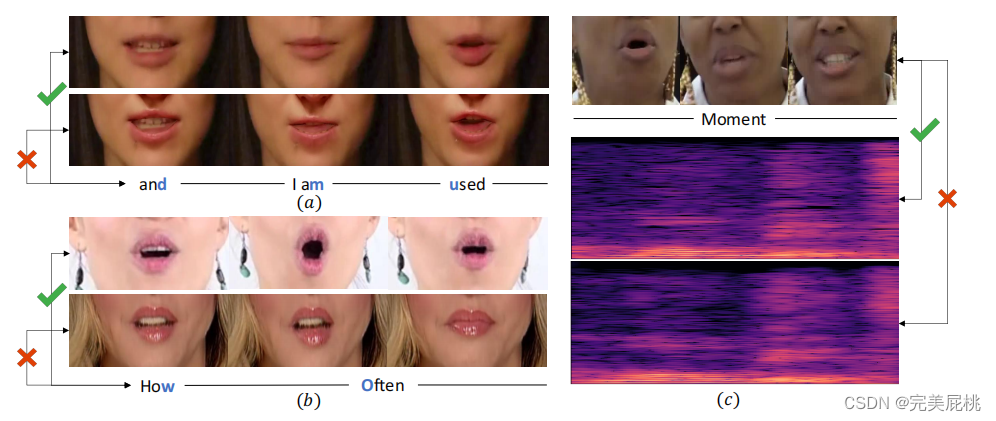
a中第一行视频帧未被修改,第二行是换脸之后的唇部图片,文字是两个视频中的话;b中第一行也是真实的,伪造视频中的唇形与发音存在较大差异。c中最上面一行是真实的视频帧,对应的真实的声谱图在第二行,TTS生成的声谱图在第三行,听起来像“wow-mount”,由第一行和第三行组成的视

 订阅专栏 解锁全文
订阅专栏 解锁全文















 4938
4938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









