







一、人脸防欺诈简介
1.1 人脸欺骗攻击(Face Spoofing Attacks)
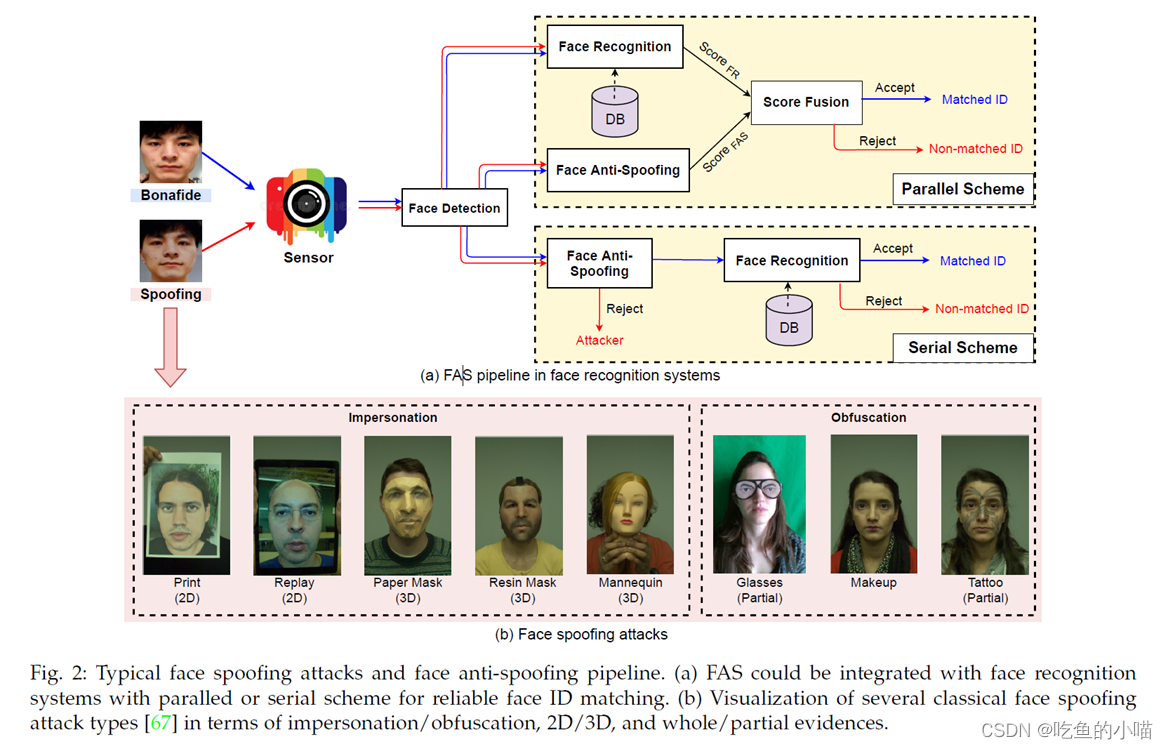
- 目前人脸识别技术已经在一些交互式智能应用中被广泛使用,比如,身份验证、移动支付、智能安防 等等。但是,现有的人脸识别系统很容易受到伪造的人脸攻击,在下面图(b)中给出了几种具有代表性的欺骗攻击类型,主要分为两种典型情况:
- 模拟impersonation:包括打印照片、电子屏幕中的人脸数字图像、3D面具(纸面具、树脂面具、人体模型)等攻击类型。
- 模糊处理obfuscation:包括眼镜、化妆、假发和纹身等攻击类型。
1.2 人脸防欺诈技术(FAS)
定义:人脸活体检测技术,也叫人脸防欺诈(FAS)或呈现攻击检测(PAD),它的任务是判断捕捉到的人脸是真实人脸,还是伪造的人脸攻击。是人脸识别系统 安全性 的重要保障之一。
- 一般来说,对人脸识别系统的攻击通常包括数字操作和物理呈现攻击两类。
上面图(a)中是人脸呈现物理攻击的检测流程,人脸防欺诈FAS与人脸识别AFR系统有两种融合方案:
(1)并行融合方案,将FAS与FR系统的预测分数融合,合并后的最终分数用于确定样本是不是来自真正的用户。
(2)串行融合方案,先经过人脸防欺诈FAS系统,再经过人脸识别系统,能够避免伪造人脸进入后续的人脸识别阶段。
二、人脸活体检测方法
2.1 基于手工特征
- 早期人脸活体检测算法 主要从人工设计的特征层面出发,算法的目标就是找到活体与非活体的之间的差异性,然后根据这些差异来设计特征,最后将提取的特征送到分类器去判断待测特征是否为活体特征。
- 一般活体与非活体差异包括:颜色纹理、非刚性运动变形、材料 (皮肤,纸质,镜面)、图像或者视频质量
下面介绍比较有代表性的两个方法:
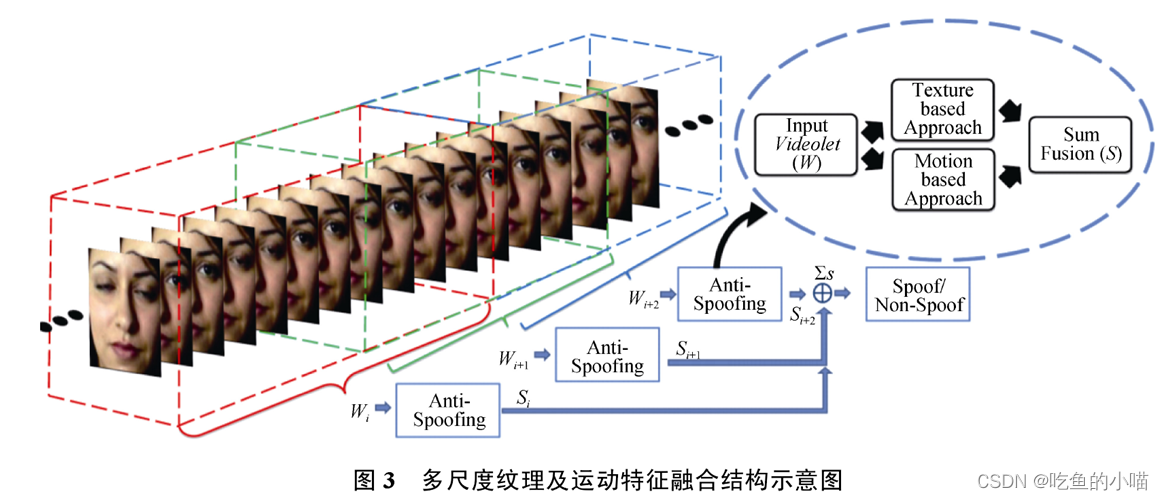
(1)Motion mag.-HOOF + LBP-TOP, 2014
- 这是2014年提出的 一种基于运动估计的新型活体检测算法,它是先对输入的多帧图像通过运动放大 来增强脸部微动作,然后使用两种特征提取算法(局部二进制模式LBP-TOP和 定向光流直方图的运动估计)分别对纹理和运动属性进行编码,最后对这两个正交的融合之后的特征 利用SVM 进行分类,输出结果是预测为活体或非活体的得分。这个算法将多种特征融合,具备有良好的鲁棒性。
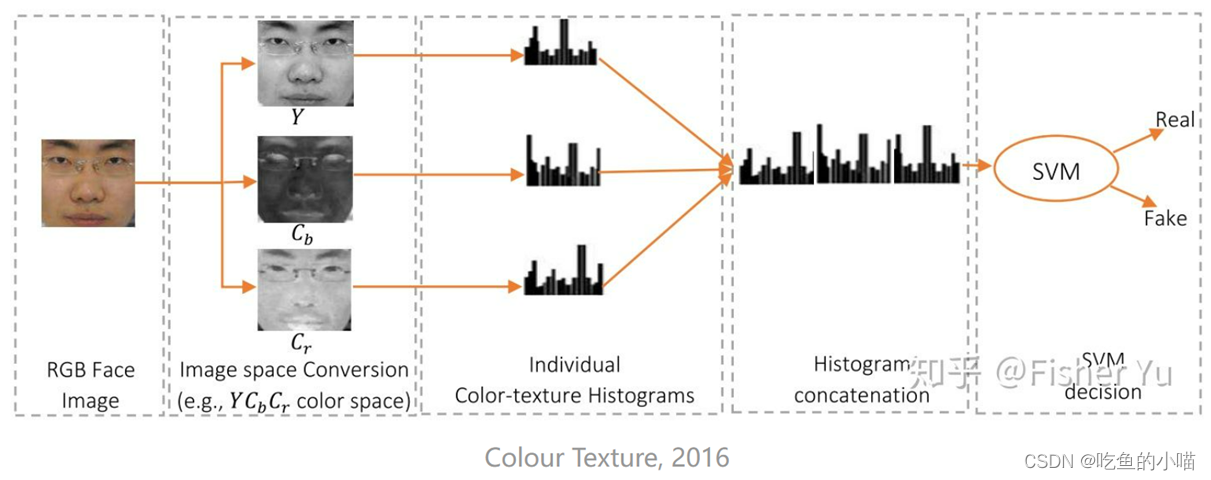
(2)Colour Texture, 2016
- 这个方法是2016年提出的,通过颜色纹理分析的方法 来检测图片是否为真实的人脸图像。具体来说,就是从不同颜色空间中提取互补的低级特征描述, 把不同亮度和色度通道中的 联合颜色纹理特征 作为待检测特征进行检测分类。在这个图中,从单个图像通道中提取 LBP 直方图,然后将这些直方图连接起来形成最终描述符。
- 在这个算法中,是通过提取HSV空间中的人脸多级LBP特征以及YCbCr空间的人脸 LPQ 特征线索进行SVM分类。
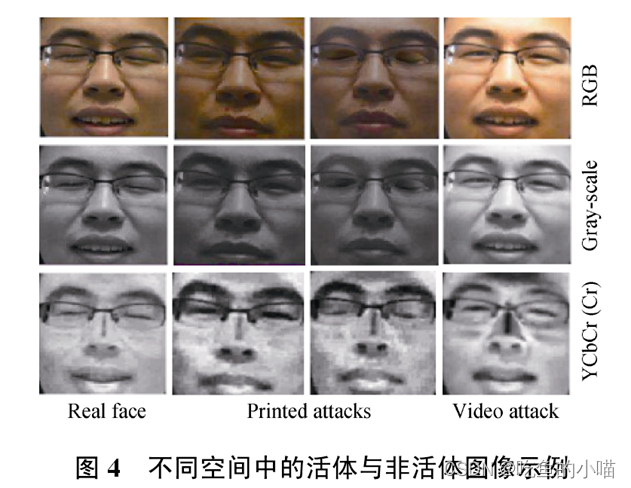
- 算法的原理:作者认为在RGB空间中很难区别活体与非活体,但在其他颜色空间里 纹理差异比较明显.(比如图4是不同空间中活体与非活体的比较,在 RGB 图像或者灰度图像中这种细微的差异 肉眼很难观察到,但在其他空间中活体与非活体的差异非常明显)
2.2 基于深度学习
- 传统的人脸活体检测一般从人工设计的纹理、颜色等特征入手,提取图片和视频中的统计特征,使用SVM进行分类,但是这类方法的特征提取的能力非常有限,分类器很多时候不能很好的区分输入的细微差别,尤其是对视频重放攻击,视频中的人脸和真实人脸十分相似。
- 后期随着卷积神经网络,循环神经网络等特征提取器的逐渐流行,主流的方法变成了通过设计一些特定的网络结构,从图片中直接提取可识别信息,然后利用训练好的模型直接区分活体与非活体。
下面介绍两个比较有代表性的方法:
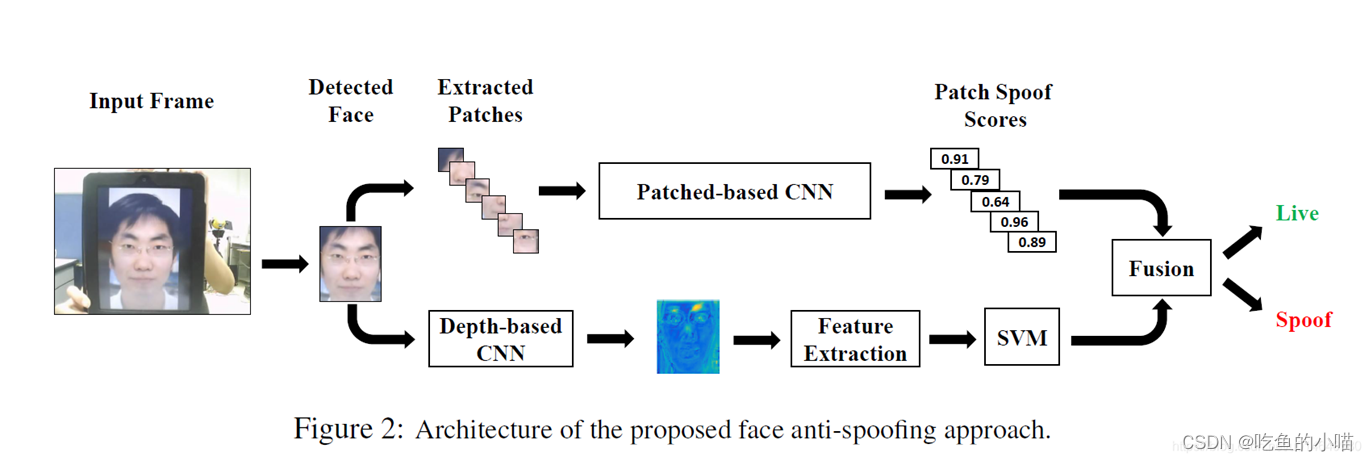
(1)2017年提出了一种基于两流CNN的人脸反欺骗方法,用于照片和视频攻击检测。
- 如图所示,该方法创新点主要是提出了两种卷积网络用于人脸活体检测,上面这个CNN用于提取局部的人脸特征,给每个随机提取的图像块分配一个分数,然后用分数的平均值来计算整个人脸图像;下面这个CNN利用深度信息来判断图片是否具有真实的人脸应有深度信息,然后根据估计的深度图为人脸图像提供一个真实性评分。最后将这两个 CNN 的分数融合给出最终真假人脸的判断。
- 尽管卷积和全卷积等网络结构有很强的特征提取能力,但是在复杂多变的真实场景中,往往会面临数据量欠缺、过拟合等问题,直到2018年提出了一种利用空间和时间辅助信息的方法,才超过了传统的算法。
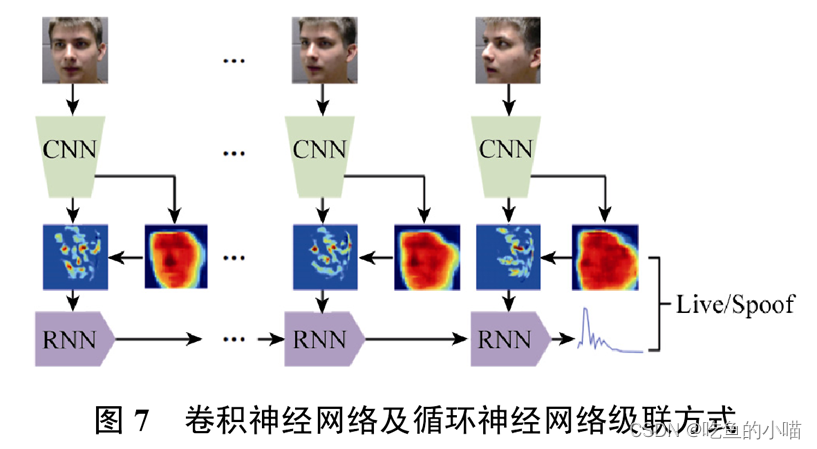
(2)2018年提出了一种利用空间和时间辅助信息的方法
- 这个算法的作者指出以前的深度学习方法将活体检测看成二分类问题,直接让DNN去学习,这样学出来的特征信息缺乏普遍性和判别性。文中将二分类问题转换成带目标性的特征监督问题,设计了一种新型网络架构CNN-RNN,利用深度图和rPPG信号这两种辅助信息作为监督。在图1中可以看出来 真实人脸与欺骗人脸在深度图像和rPPG信号方面有明显的差异。

- 在这个算法中CNN部分利用深度图监督来发现细微的纹理属性,从而对真假脸的识别带来不同的深度。然后,它将估计的深度和特征映射 喂入到新的 非刚性配准层以创建对齐的特征图。RNN部分使用对齐的特征图 和 检查视频帧间变化的rPPG作为监督进行训练。
- 实验结果表明,这个CNN-RNN方法在常用数据集上,超过了传统算法中表现最好的颜色纹理分析Color Texture方法。















 6379
6379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









