







 本文详细介绍了图像拼接技术,包括特征匹配、单应矩阵计算、动态物体影响以及与OpenCV官方stitching函数的对比。重点讨论了如何通过SIFT和FLANN进行特征点匹配,以及为何在处理动态物体时会出现鬼影现象,以及如何通过曝光补偿优化结果。
本文详细介绍了图像拼接技术,包括特征匹配、单应矩阵计算、动态物体影响以及与OpenCV官方stitching函数的对比。重点讨论了如何通过SIFT和FLANN进行特征点匹配,以及为何在处理动态物体时会出现鬼影现象,以及如何通过曝光补偿优化结果。
图像拼接算法技术报告
代码介绍
图像拼接是将多个图像按照一定的顺序和几何变换方法组合在一起,形成一个更大、更完整的图像的过程。通过图像拼接,可以将多个部分图像合并为一个整体,以展示更广阔的视野或提供更全面的信息。
我们先感性地看一组实验结果(静态场景的图像拼接):
| 左图 | 右图 | 拼接结果 |
|---|---|---|
 |  |  |
图像拼接的一般步骤:
- 特征匹配,对读入的两张图片进行特征点匹配。
- 计算右图到左图的单应矩阵,目的是将两张图片放到同一个平面坐标系下。
- 将右图乘以单应矩阵之后,便可以将左图拷贝到右图的左侧。
- 对两图重叠区域进行渐变处理。
具体是怎么提现的,我们可以直接看代码。
输入:
| 左图 | 右图 |
|---|---|
 |  |
- 特征匹配
if __name__ == '__main__':
pic1 = "./aa.png"
pic2 = "./bb.png"
img1 = cv.imread(pic1)
img2 = cv.imread(pic2)
# cv.imshow("Image1", img1)
# cv.imshow("Image2", img2)
print('img1 Dimensions : ', img1.shape)
print('img2 Dimensions : ', img2.shape)
# sift提取特征
sift = cv.SIFT_create(nfeatures=0, nOctaveLayers=3, contrastThreshold=0.04, edgeThreshold=10, sigma=1.6)
kp1, describe1 = sift.detectAndCompute(img1, None)
kp2, describe2 = sift.detectAndCompute(img2, None)
# FLANN 进行特征点匹配
FLANN_INDEX_KDTREE = 0
indexParams = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
searchParams = dict(checks=50)
flann = cv.FlannBasedMatcher(indexParams, searchParams)
match = flann.knnMatch(describe1, describe2, k=2)
good = []
for i, (m, n) in enumerate(match):
if m.distance < 0.6 * n.distance:
good.append(m)
result = cv.drawMatches(img1, kp1, img2, kp2, good, None)
# cv.imshow("matches", result)
这一段是用SIFT将左右图的特征点进行提取,然后使用FLANN进行特征点匹配,最后把好的特征点匹配放在good数组中。

- 计算右图
img2到左图img1的单应矩阵,目的是将两张图片放到同一个平面坐标系下。
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
ano_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
M, mask = cv.findHomography(ano_pts, src_pts, cv.RANSAC, 5.0)
#把img2变到img1的坐标系下,放在一张大图上。
warpImg = cv.warpPerspective(img2, M, (img1.shape[1] + img2.shape[1], max(img2.shape[0], img1.shape[0])))
这段代码使用右图的特征点ano_pts和左图的特征点src_pts的对应关系计算出二者的单应矩阵M。然后我们对右图进行单应矩阵变换,(放在一张大图上进行变换)。
得到的结果warpImg可视化是这样:
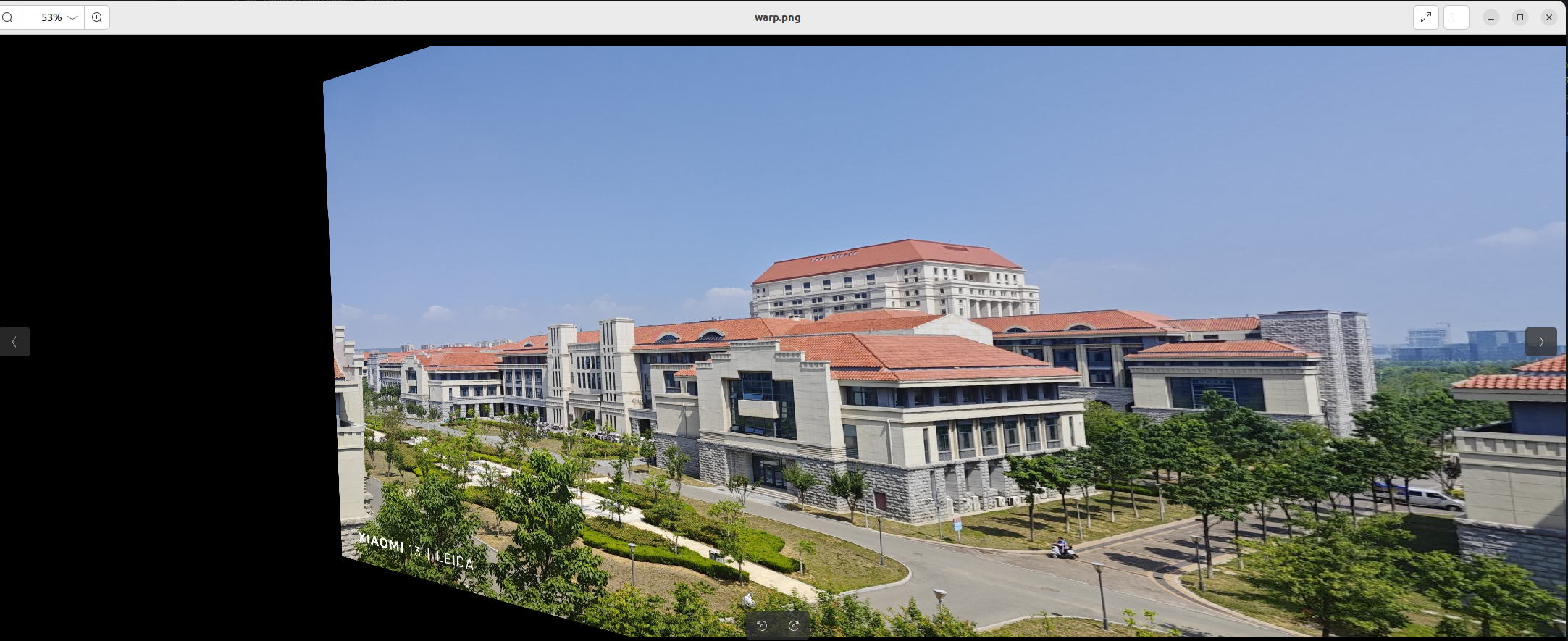
之后我们可以将左图img1直接覆盖到warpImg的左区域。(覆盖这个概念下文还会提到,这里也可以对两张图片进行曝光补偿,然后再进行覆盖。使得看起来更加协调)
def direct_stiching(warpImg, img1):
direct = warpImg.copy()
direct[0:img1.shape[0], 0:img1.shape[1]] = img1 # 左区域赋值为img
return direct
direct结果可视化是这样:

但是由于一些光线的变化等因素,两张图的色调不一致,导致左图的右边界显得很突兀。
因此我们也可以处理两张图片的重叠区域,本质上是两张图像重叠像素根据距离的一个加权融合。
def optimize_stiching(warpImg, img1):
# 重叠部分进行过渡处理。
rows, cols = img1.shape[:2]
left = 0 # 开始重叠的最左端
right = cols # 开始重叠的最右端,默认就是img1的最右端
for col in range(0, cols): # 找到重叠的最左端
if img1[:, col].any() and warpImg[:, col].any():
left = col
break
res = np.zeros([rows, cols, 3], np.uint8)
for row in range(0, rows):
for col in range(left, right):
# 如果左图没有像素点,就赋值为右图像素点
if not img1[row, col].any():
res[row, col] = warpImg[row, col]
# 如果右图没有像素点就赋值为左图像素点
elif not warpImg[row, col].any():
res[row, col] = img1[row, col]
# 如果都有像素点,就进行二者的权融合,alpha代表距离谁更近,谁的权重更大
else:
srcImgLen = float(abs(col - left))
testImgLen = float(abs(col - right))
alpha = srcImgLen / (srcImgLen + testImgLen)
res[row, col] = np.clip(img1[row, col] * (1 - alpha) + warpImg[row, col] * (alpha), 0, 255)
warpImg[0:img1.shape[0], 0:img1.shape[1]] = res
return warpImg
可视化

动态物体
当重叠区域存在动态物体时,由于重叠区域的加权融合,所以动态物体会出现“鬼影”:

与opencv Image Stich官方函数对比
静态物体
| 左图 | 右图 | My_result | Opencv_result |
|---|---|---|---|
 |  |  |  |
 |  |  |  |
 |  |  |  |
结果看起来相差不大,但是我的代码还是在某些情况下出现一些鬼影(比如第三张图),初步怀疑是加权那里做的不够好。然后我的代码速度还很慢。
动态物体
当场景中存在动态物体时,前面分析过,我的算法很明显会出现鬼影,但是opencv的代码却没有。
| 左图 | 右图 |
|---|---|
 |  |
| My_result(有鬼影) | Opencv_result |
 |  |
探索
为了解决我代码的鬼影问题,阅读了一下opencv的Stich源码,本来是想着debug一行行地去看的,但是不知道为什么没法进入opencv内部的函数,点击 step into就直接跳到下一行了,查了一下,好像在编译opencv的时候得加上debug参数,还不一定能成功。
核心代码应该是在stich.cpp的第322行:
“Compensate exposure”(曝光补偿)是指对图像进行调整以实现曝光一致性的过程。在拼接全景图像时,不同输入图像可能具有不同的曝光水平,这可能会导致最终拼接结果中出现不连贯或明显的亮度差异。为了解决这个问题,代码中的"Compensate exposure"部分对每个图像进行曝光补偿,以使其在全景图中的曝光水平更加一致。
// Compensate exposure
exposure_comp_->apply((int)img_idx, corners[img_idx], img_warped, mask_warped);
LOGLN(" compensate exposure: " << ((getTickCount() - pt) / getTickFrequency()) << " sec");
继续深入看了一下,不求甚解。大概是计算了一些东西,然后把这个东西应用在每个输入图像上,使得他们的曝光是一致的,然后使用曝光补偿的图片进行拼接。(实在看不懂啊 )
)
其实说到这也就解释了为什么我的算法会有鬼影,而opencv不会。因为我的是加权平均,所以重叠区域的两张图片都会起作用;但是opencv的是曝光补偿,因此拼接后,重叠区域的像素会直接选择某一张图片的全部像素。
拿这个demo举个例子:
 |  |
|---|
左图有一个黑笔涂抹的水印,而右图有一个 Beutiful school的水印。(可能需要放大才能看清)

我们可以看到,拼接图片重叠区域中左图的黑笔涂抹被右图的beautiful school完全覆盖了,也就是说重叠区域完全选用了右图的像素,结合下方的AOMI水印也能证明这一点。这个实验也解释了为什么opencv没有鬼影的出现。
总结
本篇博客先是介绍了图像拼接的一般流程:
- 特征匹配,对读入的两张图片进行特征点匹配。
- 计算右图到左图的单应矩阵,目的是将两张图片放到同一个平面坐标系下。
- 将右图乘以单应矩阵之后,便可以将左图拷贝到右图的左侧。
- 对两图重叠区域进行渐变处理。
然后给出了自己手写方法和opencv官方代码的对比。
| 我的方法 | 官方方法 |
|---|---|
| 静态场景效果好 | 静态场景效果好 |
| 速度非常慢 | 速度很快 |
| 动态物体会有鬼影 | 无鬼影 |
然后在探索小节通过阅读opencv的源码解释了为什么动态物体出现时我的会有鬼影,而opencv stich不会,本质上是算法的思想不同。
我的代码慢的主要原因有两个:
- 使用Python写的,而官方方法我用的C++
- 加权处理重叠区域代码,是一个个像素处理的,但其实这里是可以并行的。
Refer
[1]https://www.cnblogs.com/skyfsm/p/7411961.html
[2]https://www.cnblogs.com/empolder-minoz/p/14772234.html
[3]https://docs.opencv.org/4.x/d1/d46/group__stitching.html
附录
my_code.py
# 图像拼接
import cv2 as cv
import numpy as np
MIN = 10
def direct_stiching(warpImg, img1):
direct = warpImg.copy()
direct[0:img1.shape[0], 0:img1.shape[1]] = img1
return direct
def optimize_stiching(warpImg, img1):
# 重叠部分进行过渡处理。
rows, cols = img1.shape[:2]
left = 0 # 开始重叠的最左端
right = cols # 开始重叠的最右端,默认就是img1的最右端
for col in range(0, cols): # 找到重叠的最左端
if img1[:, col].any() and warpImg[:, col].any():
left = col
break
res = np.zeros([rows, cols, 3], np.uint8)
for row in range(0, rows):
for col in range(0, right):
# 如果左图没有像素点,就赋值为右图像素点
if not img1[row, col].any():
res[row, col] = warpImg[row, col]
# 如果右图没有像素点就赋值为左图像素点
elif not warpImg[row, col].any():
res[row, col] = img1[row, col]
# 如果都有像素点,就进行二者的权融合,alpha代表距离谁更近,谁的权重更大
else:
srcImgLen = float(abs(col - left))
testImgLen = float(abs(col - right))
alpha = srcImgLen / (srcImgLen + testImgLen)
res[row, col] = np.clip(img1[row, col] * (1 - alpha) + warpImg[row, col] * (alpha), 0, 255)
warpImg[0:img1.shape[0], 0:img1.shape[1]] = res
return warpImg
if __name__ == '__main__':
pic1 = "./dong1.png"
pic2 = "./dong2.png"
img1 = cv.imread(pic1)
img2 = cv.imread(pic2)
# cv.imshow("Image1", img1)
# cv.imshow("Image2", img2)
print('img1 Dimensions : ', img1.shape)
print('img2 Dimensions : ', img2.shape)
# sift提取特征
sift = cv.SIFT_create(nfeatures=0, nOctaveLayers=3, contrastThreshold=0.04, edgeThreshold=10, sigma=1.6)
kp1, describe1 = sift.detectAndCompute(img1, None)
kp2, describe2 = sift.detectAndCompute(img2, None)
# FLANN 进行特征点匹配
FLANN_INDEX_KDTREE = 0
indexParams = dict(algorithm=FLANN_INDEX_KDTREE, trees=4)
searchParams = dict(checks=32)
flann = cv.FlannBasedMatcher(indexParams, searchParams)
match = flann.knnMatch(describe1, describe2, k=2)
good = []
for i, (m, n) in enumerate(match):
if m.distance < 0.6 * n.distance:
good.append(m)
result = cv.drawMatches(img1, kp1, img2, kp2, good, None)
# cv.imshow("matches", result)
# RANSAC:findhomography
if len(good) > MIN:
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
ano_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
M, mask = cv.findHomography(ano_pts, src_pts, cv.RANSAC, 5.0)
warpImg = cv.warpPerspective(img2, M, (img1.shape[1] + img2.shape[1], max(img2.shape[0], img1.shape[0]))) #把img2变到img1的坐标系下,放在一张大图上。
direct = direct_stiching(warpImg, img1) # 直接将左图覆盖warpImg的左区域
optimize = optimize_stiching(warpImg, img1) # 左图和右图的重叠区域进行加权融合
# cv.imshow("direct_main", direct)
# cv.imshow("optimize_main", optimize)
cv.imwrite(pic1.split(".png")[0] + "direct.png", direct)
cv.imwrite(pic1.split(".png")[0] + "optmize.png", warpImg)
print("result saved!")
cv.waitKey()
cv.destroyAllWindows()
else:
print("not enough matches!")
opnecv_stich.cpp
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/stitching.hpp"
#include <iostream>
using namespace std;
using namespace cv;
bool divide_images = false;
Stitcher::Mode mode = Stitcher::PANORAMA;
vector<Mat> imgs;
string result_name = "result.jpg";
void printUsage(char** argv);
int parseCmdArgs(int argc, char** argv);
int main(int argc, char* argv[])
{
int retval = parseCmdArgs(argc, argv);
if (retval) return EXIT_FAILURE;
Mat pano;
Ptr<Stitcher> stitcher = Stitcher::create(mode);
Stitcher::Status status = stitcher->stitch(imgs, pano);
if (status != Stitcher::OK)
{
cout << "Can't stitch images, error code = " << int(status) << endl;
return EXIT_FAILURE;
}
imwrite(result_name, pano);
cout << "stitching completed successfully\n" << result_name << " saved!";
return EXIT_SUCCESS;
}
void printUsage(char** argv)
{
cout <<
"Images stitcher.\n\n" << "Usage :\n" << argv[0] <<" [Flags] img1 img2 [...imgN]\n\n"
"Flags:\n"
" --d3\n"
" internally creates three chunks of each image to increase stitching success\n"
" --mode (panorama|scans)\n"
" Determines configuration of stitcher. The default is 'panorama',\n"
" mode suitable for creating photo panoramas. Option 'scans' is suitable\n"
" for stitching materials under affine transformation, such as scans.\n"
" --output <result_img>\n"
" The default is 'result34.jpg'.\n\n"
"Example usage :\n" << argv[0] << " --d3 --mode scans img1.jpg img2.jpg\n";
}
int parseCmdArgs(int argc, char** argv)
{
if (argc == 1)
{
printUsage(argv);
return EXIT_FAILURE;
}
for (int i = 1; i < argc; ++i)
{
if (string(argv[i]) == "--help" || string(argv[i]) == "/?")
{
printUsage(argv);
return EXIT_FAILURE;
}
else if (string(argv[i]) == "--d3")
{
divide_images = true;
}
else if (string(argv[i]) == "--output")
{
result_name = argv[i + 1];
i++;
}
else if (string(argv[i]) == "--mode")
{
if (string(argv[i + 1]) == "panorama")
mode = Stitcher::PANORAMA;
else if (string(argv[i + 1]) == "scans")
mode = Stitcher::SCANS;
else
{
cout << "Bad --mode flag value\n";
return EXIT_FAILURE;
}
i++;
}
else
{
Mat img = imread(samples::findFile(argv[i]));
if (img.empty())
{
cout << "Can't read image '" << argv[i] << "'\n";
return EXIT_FAILURE;
}
if (divide_images)
{
Rect rect(0, 0, img.cols / 2, img.rows);
imgs.push_back(img(rect).clone());
rect.x = img.cols / 3;
imgs.push_back(img(rect).clone());
rect.x = img.cols / 2;
imgs.push_back(img(rect).clone());
}
else
imgs.push_back(img);
}
}
return EXIT_SUCCESS;
}


















 2431
2431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











