






更新!!!
完整介绍参考下面这篇博客:
超详细的(视频)人脸情感特征提取教程【Python】
写这篇博客的原因
大致两个原因吧!
一个是记录一下自己前段时间所做的工作和学习到的东西,方便以后记性不好忘了能快速重拾起来;
另一个原因是因为我这么长一段时间以来,翻阅许多csdn上的博客,都没有一个是记录特征提取的完整过程的(一般都是叙述到提取出人脸坐标,没有下一步的操作记录)。
基于此,我决定花一些时间来写一下博客!
如果以下内容对你有所帮助,可以点赞关注一下表示支持哦!
特征提取的基础知识
先说一下我个人的情况啊,我目前整个大的方向其实是多模态情感分析,也就是说需要提取到的特征不仅仅是图像的,还包括音频和文本特征。而再具体一点的情况呢,是准备搞一个小语种的数据库。
那在这整篇博客当中呢,我也只讲图像方面的情感特征提取,以后有机会的话可以再补充。
在开始进行特征提取之前呢,还需要先读一些论文,找一些相似的数据集来看。不然估计自己连这个“特征提取”当中的“特征”是什么东西都不懂,又谈何提取呢?
那在这里我跟大家分享一下我看过的当中自己感觉比较有收获的数据集和论文吧。
数据集
我自己看过且相对比较了解的数据集有以下几个:
IEMOCAP: Interactive Emotional Dyadic Motion Capture Database
MOUD: Multimodal Opinion Utterances Dataset
MOSI: Multimodal Corpus of Sentiment Intensity and Subjectivity Analysis in Online Opinion Videos
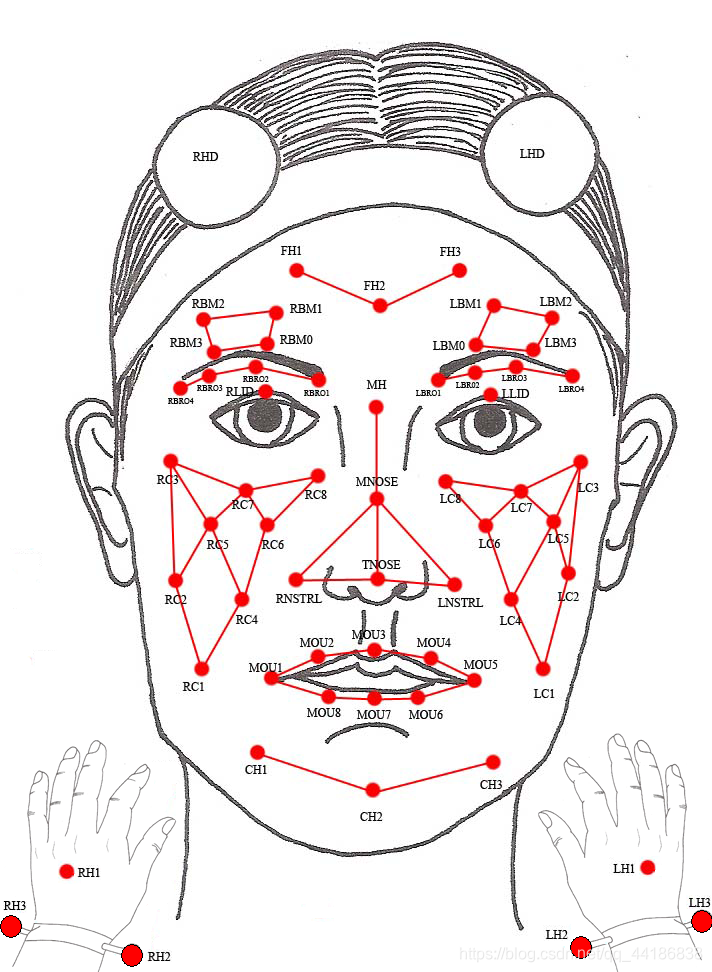
其中呢,第一个相对来说比较high-level,主要内容从数据集的名字也可以看出来,这个数据库被称为交互式情感双元动作捕捉数据库。其中有10名演员被记录在双人对话中(5个会话,每个主题2个)。他们被要求执行三个选定的脚本,明确的情感内容。除了剧本,受试者还被要求在假设场景中即兴对话,旨在引发特定的情绪(快乐、愤怒、悲伤、沮丧和中性状态)。两人中的一个参与者是在每次交互过程中一次捕捉到的运动。53个面部标记贴在被摄对象的动作上,被摄对象也分别戴着腕带和带标记的头带来捕捉手部和头部的动作(如图)。
个人认为这个数据集做的非常不错 ,但是正如上文所说,其图像情感特征采集不仅仅有面部表情,还有手部运动。如果考虑上手部动作,这将大大增加其提取的难度,后面十分不好操作。不过如果说想多看看一些数据集的朋友,建议看看这个数据集,十分的不错!

至于第二个数据集,目前来说我主要是参考这一个数据集来进行后期的工作的。
这个数据集是西班牙语的数据集,数据不多。一共有两百个视频,每一个视频时长在三十二秒左右。而视频呢,都是来自Youtube上,视频大概的主题有以下几种:mis products favoritos (my favorite products), products que no recomiendo (non recommended products), mis perfumes favoritos (my favorite perfumes), peliculas recomendadas (recommended movies), peliculas que no recomiendo (nonrecommended movies) and libros recomendados (recommended books), libros que no recomiendo (non recommended books)。(西班牙语看不懂哈哈,想知道的可以翻译一下)
这个数据集的每个视频的选择都遵循以下原则:扬声器应该在摄像机前;他或她的脸应该清晰可见,在录制过程中面部遮挡的程度最小;不应该有任何背景音乐或动画。最终的视频集包括从YouTube上检索到的80个视频中随机选择的80个视频,这些视频也符合所述的指导原则。数据集包括15名男性和65名女性演讲者,他们的年龄大约在20到60岁之间。所有的视频剪辑也经过预处理,以消除介绍性标题和广告。除此之外,每段视频都被手动剪辑,以选择包含意见的30秒片段,以确保生成的视频包含单个主题。
所以大致了解了这个数据集之后,应该不难发现,如果想要自己搞一个不大且图像特征仅限于人脸的数据集的话,可以考虑参考这个数据集。
至于第三个数据集,有想法的朋友也可以自己看一看。这里就不过多介绍了。
论文
论文的话,我这里主要记录一下对人脸特征提取帮助比较大的论文吧:
The Computer Expression Recognition Toolbox (CERT)
之所以会想看这篇介绍CERT这个工具的论文是因为我在看MOUD数据集的时候,发现该数据集里面的人脸特征提取正是由CERT这个工具来进行提取的,非常的强大,这个工具!
先介绍一下这个工具——计算机表情识别工具箱(CERT),一个用于全自动实时面部表情识别的软件工具。它可以自动编码来自FACS的19种不同的面部动作强度和6种不同的典型面部表情。它还估计了10个面部特征的位置以及头部的三维方向(偏航、俯仰、滚动)。在CK+人脸表情数据库中,CERT在分析人脸动作时的平均识别率(在一个正例子和一个负例子之间的两个强制选择(2afc)任务的正确率)为90.1%。在一个自发的面部表情数据集上,准确率接近80%。在标准双核笔记本电脑中,CERT可以以–每秒大约10帧的速度实时处理320×240个视频图像。
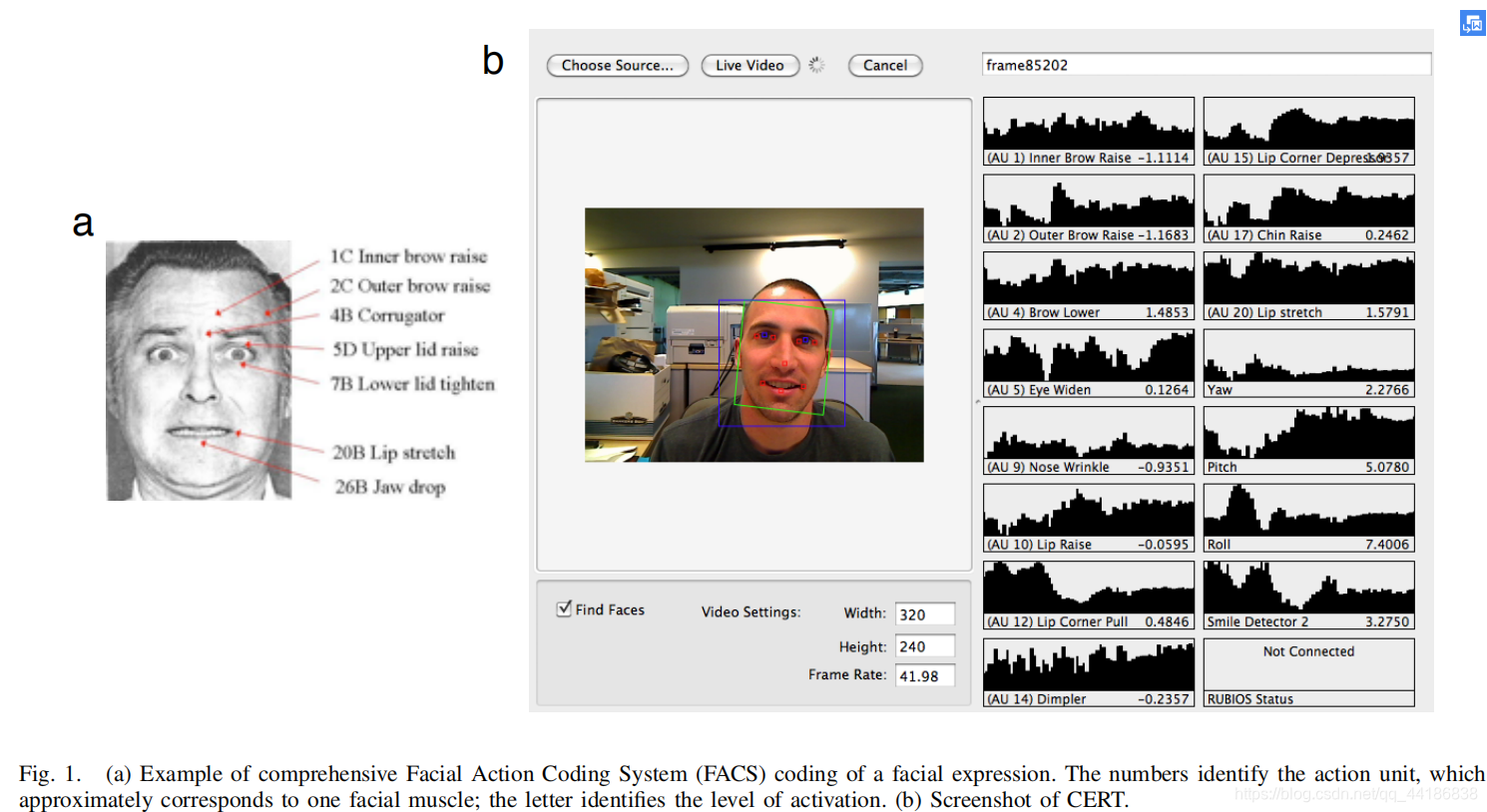
单看图片都可以感受到这个工具的强大对吧,哈哈!
所以在经历了好多个星期的煎熬下,我终于发现了这么一个可以直接提取人脸情感特征的工具,一度以为走向了光明的未来。
Facial Action Coding System(FACS)
之所以单独将FACS单独列出来作为一部分,是因为它非常的基础,但却非常的重要。
在这一篇博客最开始的时候,我提到了“特征提取”的“特征”是什么,而了解FACS后,就自然会知道。
为了客观地捕捉面部表情的丰富性和复杂性,行为科学家发现有必要制定客观的编码标准。而面部动作编码系统(FACS),就是行为科学中应用最广泛的表情编码系统之一。FACS是由Ekman和Friesen开发的一种综合的面部表情客观编码方法。训练有素的FACS编码员根据46个动作的明显强度分解面部表情,而这些动作大致对应于各个面部肌肉。这些基本动作被称为动作单位(AUs),可以看作是面部表情的“音位”。上图中的图a可以说明面部表情的FACS编码。
简单来讲,这里的AUs,就是“人脸情感特征”。
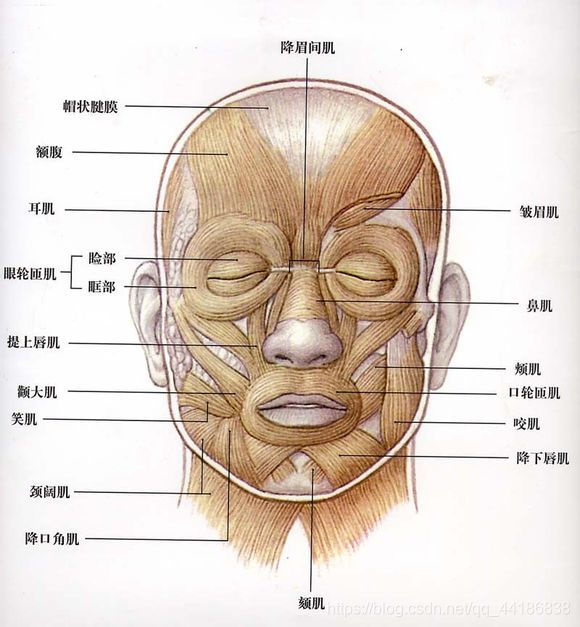
这张图里涵盖了人脸的大部分肌肉,这些肌肉也是我们在AU介绍里要提到的。为了方便下面的学习,最好一一了解下这些肌肉的名字以及在脸上出现的位置。
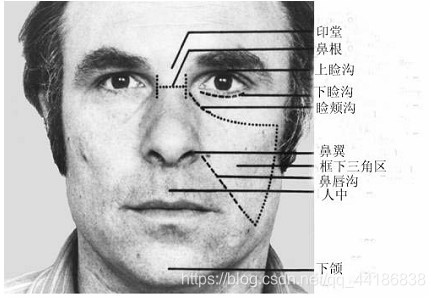



上面几张图都是介绍FACS中的一些专业术语,需要我们有一定的了解!
转折
现实永远是那么的残酷。当我根据CERT的论文当中提供的链接,试图找到并下载这个工具时,出现了以下这么个情况。

???
倒闭了???
然后我回头一想,既然最直接的方法没法实现,那联系一下作者,也许可以吧。
但最后还是不出意外地失败了。
除此之外,我也试图在网上找寻CERT的踪迹,但也没能成功。(现在想了想,估计也是因为这个工具距离现在也很久了吧,而且现在在这些领域,也很少有直接可以用的工具,大多是需要自行调试的代码)
那既然没办法直接用,那就自己实现CERT的功能吧。
于是,我开始了CERT功能实现之旅。。。
结束语
由于博主能力有限,博文中提及的信息,也难免会有疏漏之处。希望发现疏漏的朋友能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的方法也请不吝赐教。
需要文中提到的资料的朋友,也可以关注评论留下自己的邮箱,我会尽量及时发送!















 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











