







 RSOT是一种过采样技术,通过生成符合正态分布的随机偏度来合成新数据,以解决样本不平衡问题。与SMOTE相比,RSOT具有高度泛化、低时间及空间复杂度,并允许人为控制数据分布。通过实验对比,RSOT在维持数据分布状态和计算效率方面表现出优势。
RSOT是一种过采样技术,通过生成符合正态分布的随机偏度来合成新数据,以解决样本不平衡问题。与SMOTE相比,RSOT具有高度泛化、低时间及空间复杂度,并允许人为控制数据分布。通过实验对比,RSOT在维持数据分布状态和计算效率方面表现出优势。
摘 要
随机偏度过采样技术RSOT是在给定原样本数据的均值及标准差的条件下,随机生成近似符合标准正态分布的随机偏度,再人工合成新数据集的过采样技术。其具有高度泛化,运算时间及空间复杂度低的优点,而且可以人为控制生成的随机偏度来干预数据的集中度及数据的偏度,从而达到干预数据的分布状态。
关键词:样本平衡;smote过采样;随机偏度;随机偏距;拟合正态分布;人工合成数据
目录
一、引言
对于样本数据类别比例失衡,又不想剔除类别偏多的部分数据,而想通过过采样技术生成新数据来平衡样本数据。过采样技术的代表算法SMOTE(Synthetic Minority Oversampling Technique),其基本思想是基于k近邻,利用插值法对少数类样本进行分析计算并根据少数类样本,人工合成新数据的技术。而这种思想生成的数据集是在原样本范畴内的,即新生成样本数据的最小最大值所确定的值域是原样本数据最小最大值所确定值域的子集,其不够泛化,新生数据的标准差较原始样本数据标准差有所下降。
二、RSOT原理:
1、获得原样本某个标签的均值mean, 及标准差std
2、随机生成一个符合正态分布的随机偏度rs
3、生成随机样本偏距 ![]()
4、生成新的样本数据![]()
而在以上过程中,随机生成一个符合正态分布的随机偏度是该技术的关键
注:可以使用Random.nextGaussian()方法生成随机偏度(![]() , 生成一对x*s、y*s, x、y均属于(0,1))
, 生成一对x*s、y*s, x、y均属于(0,1))
三、生成符合正态分布的随机偏度
以标准正态分布为基准来拟合正态分布,从而获取随机偏度,其步骤如下:
- 通过柱状图来拟合标准正态分布图,柱状条形图拟合步长0.01,或者0.001。以0.01为例:要求随机生成0.00偏距的概率要同-0.005到0.005的标准正太分布概率近似相等,随机生成0.01偏距的概率要同0.005到0.015的标准正太分布概率近似相等,依次类推。
- 以给定步长下生成相应的概率分布,再生成对应的整数分布,见附件fitSND.txt
- 生成随机数,依据fitSND.txt找到偏度值,即可得到随机偏度rs
- 验证:(
随机生成偏度集1000万条,并对该数据集做常规统计与分组统计,如图3.1与图3.2所示;
随机生成偏度集100条做常规统计,如图3.3所示;
) - 可以看到均值mean趋于0, 标准差趋于1,与故而拟合的标准正太分布式可以使用的
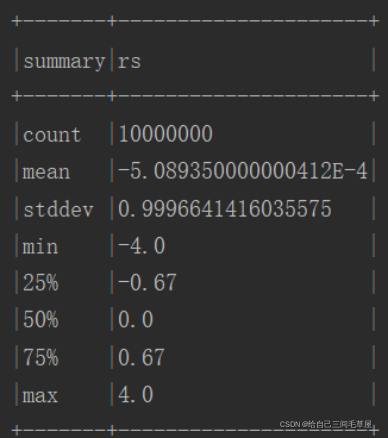
图3.1 1000万条随机偏度集常规统计
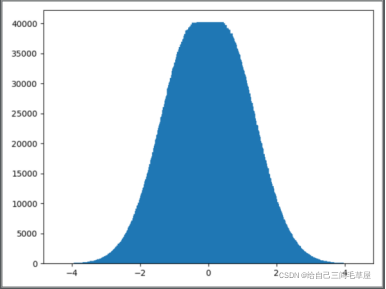
图3.2 1000万条随机偏度集分组统计
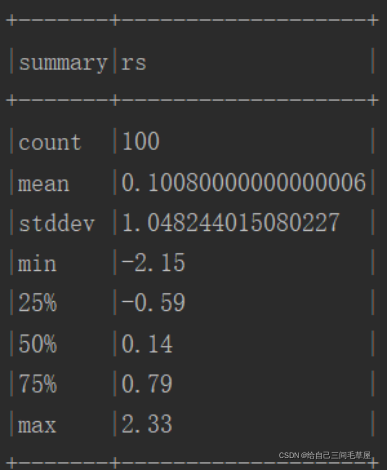
图3.3 100条随机偏度集常规统计
四、与Smote对比
以鸢尾花数据iris做原样本,分别采用Smote、Rsot技术进行过采样,人工合成smote.txt与rsot.txt(见附件),各450条数据。分别对iris、smote、rsot进行label标签分组统计其均值mean, 标准差std, 最小最大值min,max。分别见下图4.1、图4.2、图4.3。

图4.1 iris数据分组统计

图4.2 smote数据分组统计
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









