






1. 前言
使用环境
Flink1.14.6+Centos7.9+Java8
Flink1.14.6安装部署测试参考:参考链接
2 .数据采集
2.1 信号监听
需要监听文件夹下的新文件产生,并且数据库中的值未更新时才发送消息通知后续模块开始采集数据。【后面需要重新搭建监听部分和判断部分】
2.2 数据实时采集
做不到非常实时,一次采集平均时间在4s左右。
信号监听部分获取到新数据后会将新数据对应的shotNum发送到Kafka的Topic【newFilePath】中,数据采集模块【一个是用于持久化的数据采集,不监听这个topic;另一个是实时处理的数据采集,监听newFilePath】。
3. 数据处理
实时处理部分说明【需要进一步修改完善,目前只做测试】:
- 有两个采集文件,分别处理不同目录【需要后续补充】。在其接收到newFilePath中的数据,即shotNum后,拼接文件名【三种文件名】,扫描目录并拼接完整路径,文件存在的情况下采集文件元数据【文件当前size;文件修改时间;文件名;所属子树;自定义flag】。
- 数据采集完成,通过Topic【file_info】发送到处理程序。
- 处理程序接收文件元数据,通过keyby实现按shotnum分组处理。
- 处理完成后的数据取三个值【shotnum;datasize;ctime】,并在每一个新的flag中返回上一个flag对应的差值,由此实现数据流的计算。
4. 代码
采集模块通过python构建
4.1 系统依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>ExperimentInfo-Kafka</artifactId>
<groupId>com.scali</groupId>
<version>1</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>Storage-Flink</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.14.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.6</version>
</dependency>
<!-- 欺诈检测的common依赖包,包括一些实体等内容-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-walkthrough-common_2.12</artifactId>
<version>1.14.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>1.14.6</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-bridge -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.14.6</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.14.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.14.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.14.6</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.28</version>
</dependency>
</dependencies>
</project>
4.2 监听模块
监听部分代码:
import os
import time
from kafka import KafkaProducer
from watchdog.observers import Observer
from watchdog.events import PatternMatchingEventHandler
#监听新文件产生并传输完整路径
#
import readconfig
folder_path = '/home/text' # 文件夹路径
file_info = {} # 存储文件信息的字典
patterns = ["*.data"] # 要监视的文件类型
class NewFileHandler(PatternMatchingEventHandler):
def on_created(self, event):
if not event.is_directory:
global file_info
file_path = event.src_path
file_name = os.path.basename(file_path)
list1 = file_name.split('.')[0]
shot = list1.split('_')[1]
print(shot)
def on_deleted(self, event):
if not event.is_directory:
global file_info
file_path = event.src_path
# 如果文件被删除,则从字典中删除文件信息
if file_path in file_info:
del file_info[file_path]
print(f'File deleted: {file_path}')
def sendMsg(msg):
kafkaConfig = readconfig.read_kafka()
producer = KafkaProducer(
bootstrap_servers=[kafkaConfig["host"]],
)
# 发送Kafka消息
producer.send(kafkaConfig['topic2'], msg)
print('Send message: {}'.format(msg))
if __name__ == "__main__":
event_handler = NewFileHandler(patterns)
observer = Observer()
observer.schedule(event_handler, folder_path, recursive=True)
observer.start()
try:
while True:
time.sleep(1) # 暂停1秒钟,然后再次检查文件夹中的文件
except KeyboardInterrupt:
observer.stop()
observer.join()
4.3 数据采集模块
import datetime
import os
from json import dumps
import pymysql
from kafka import KafkaProducer, KafkaConsumer
import readconfig
flag = 0
curshot = None
def callMetaFilesize(ospath,shotnum):
global flag
numdir = str(shotnum // 1000)
# ['east', 't1', 't2', 't3', 't4', 't5', 't6', 't7', 't8']
dir_list = os.listdir(ospath)
# 将传入的文件夹继续遍历到列表中
for dir in dir_list:
curdir = ospath + '/' + dir + '/' + numdir
filename1 = dir+"_"+str(shotnum)+".characteristics"
isFile = os.path.exists(curdir+"/"+filename1)
if isFile == False:
continue
filedir = []
filedir.append(filename1)
filedir.append(dir+"_"+str(shotnum)+".tree")
filedir.append(dir+"_"+str(shotnum)+".datafile")
for file in filedir:
fsize = os.path.getsize(curdir + "/" + file)
# 文件最後修改時間
# ftime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime((os.path.getmtime(curdir + "/" + file))))
try:
msg = {
"id":flag,
"shotnum": shotnum,
"subtree": dir,
"filename": file,
"fsize": fsize,
# "ftime": ftime,
# "ts_1": datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
}
sendMsg(msg)
except:
print("kafka error")
# 发完一组flag自动加1,这样flink consumer能够按照flag进行分组
flag += 1
def sendMsg(msg):
producer = KafkaProducer(
bootstrap_servers=["202.127.205.60:9002"],
value_serializer=lambda x: dumps(x).encode('utf-8')
)
producer.send("file_info",value=msg)
print("send msg :",msg)
# 这部分应该要改
def getMdsMaxShot():
mdspath = readconfig.read_mdsdata()
db = pymysql.connect(host=mdspath['host'], port=mdspath['port'], user=mdspath['user'],
password=mdspath['password'], database=mdspath['database'], charset=mdspath['charset'])
sql = """ SELECT treeshot FROM `new_shot`"""
cursor = db.cursor()
cursor.execute(sql)
res = cursor.fetchone()[0]
cursor.close()
db.close()
return res
def recivemsg():
global curshot
global flag
consumer = KafkaConsumer("newFilePath",
bootstrap_servers=["202.127.205.60:9002"])
# 循环读取消息并进行处理
while True:
# 从Kafka中读取消息
msg = consumer.poll(timeout_ms=1000)
# maxMDSShot = getMdsMaxShot()
# 如果有新的消息到达
if msg:
# 从消息中提取数据
for tp, msgs in msg.items():
for msg in msgs:
data = msg.value.decode('utf-8')
curshot = data
flag = 0
#发一个新的触发事件,将计算的size和置为0,发来新的炮数据了
print("Received message: {}".format(data))
else:
# 添加结束判断
if curshot != None:
# 如果没有新的消息到达
# east和east_1下的数据都要读出来,计算时间差值
callMetaFilesize("/home/text", int(curshot))
# 度每个目录大概三秒,所以此处可能要开两个流程,east处理east下流程,east_1处理east_1,然后相加求和
# callMetaFilesize("/var/ftp/pub/eastdata/arch/east_1", int(curshot))
if __name__ == '__main__':
recivemsg()
4.4 数据处理模块
实现流程【主函数DataStreamAchieve】
package com.scali.experiment.datastream;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.scali.experiment.entity.Message;
import com.scali.experiment.flink.FraudDetector;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.util.serialization.JSONKeyValueDeserializationSchema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class DataStreamAchieve {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
/*
* 1 . 配置kafka数据接收环境
* */
Properties kafkaProps = new Properties();
kafkaProps.setProperty("bootstrap.servers", "202.127.205.60:9002");
kafkaProps.setProperty("group.id", "flink-kafka-json-processing");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
"file_info",new SimpleStringSchema(),kafkaProps);
// kafkaConsumer.setStartFromEarliest();
/*
* 2. datastream转换
* */
DataStream<String> kafkaStream = env.addSource(kafkaConsumer);
DataStream<Message> jsonStream = kafkaStream.map(new MessageMapper());
DataStream<Message> resStream = jsonStream
.keyBy(Message::getShotnum)
.process(new MessageProcessFunction());
resStream.print();
resStream.addSink(new MysqlSink());
env.execute("Flink Kafka JSON Processing");
}
public static class DataStreamDiff extends KeyedProcessFunction<Long, Message, MysqlSink> {
private transient ValueState<Double> sumState;
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Double> descriptor = new ValueStateDescriptor<>(
"sumState",
Double.class,
0.0);
sumState = getRuntimeContext().getState(descriptor);
}
@Override
public void processElement(Message value, KeyedProcessFunction<Long, Message, MysqlSink>.Context ctx, Collector<MysqlSink> out) throws Exception {
}
}
public static class MessageMapper implements MapFunction<String, Message> {
@Override
public Message map(String json) {
// Deserialize JSON to JsonMessage object using fastjson library
return JSON.parseObject(json, Message.class);
}
}
public static class DifferenceMapper implements MapFunction<Message, Message> {
private Message lastMessage;
@Override
public Message map(Message currentMessage) {
if (lastMessage != null) {
currentMessage.setDifference(currentMessage.getFsizeConverted() - lastMessage.getFsizeConverted());
} else {
currentMessage.setDifference(currentMessage.getFsizeConverted());
}
lastMessage = currentMessage;
return currentMessage;
}
}
}
数据处理【MessageProcessFunction】
package com.scali.experiment.datastream;
import com.scali.experiment.entity.Message;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
/**
* @Author:HE
* @Date:Created in 10:38 2023/7/4
* @Description:
*/
@Slf4j
public class MessageProcessFunction extends KeyedProcessFunction<Long, Message, Message> {
// 用于记录每个 shotnum 中每个 id 对应的 fsize 总和
// private Map<Long, Map<Long, Double>> idToSumMap = new HashMap<>();
private Long lastId = -1L;
private Long lastShotnum = -1L;
private Integer countSum = 0;
private Map<Long,Map<Long,Double>> shotNumMap = new HashMap<>();
@Override
public void processElement(Message message, KeyedProcessFunction<Long, Message, Message>.Context ctx, Collector<Message> out) throws Exception {
long id = message.getId();
long shotnum = message.getShotnum();
double fsize = message.getFsize() * 0.0000009537;
// 如果当前 shotnum 中还没有记录过当前 id,则初始化为 0
shotNumMap.computeIfAbsent(shotnum, k -> new HashMap<>()).putIfAbsent(id, 0.0);
// idToSumMap.computeIfAbsent(shotnum, k -> new HashMap<>()).putIfAbsent(id, 0.0);
// 更新当前 id 的 fsize 总和
double sum = shotNumMap.get(shotnum).get(id);
shotNumMap.get(shotnum).put(id, sum + fsize);
// 如果当前 id =1 输出的是id=0的那组数据
if(id != lastId){
countSum = 0;
}
if (1 == id){
if(0 == countSum){
out.collect(new Message(lastId, lastShotnum,shotNumMap.get(lastShotnum).getOrDefault(lastId, 0.0) ));
}
}else {
if(0 == countSum && -1L != lastId && -1L != lastShotnum){
out.collect(new Message(lastId, lastShotnum,shotNumMap.get(lastShotnum).getOrDefault(lastId, 0.0)-
shotNumMap.get(lastShotnum).getOrDefault(lastId - 1, 0.0) ));
}
}
countSum++;
lastId = id;
lastShotnum = shotnum;
}
}
mysql持久化部分【MysqlSink】
package com.scali.experiment.datastream;
/**
* @Author:HE
* @Date:Created in 12:32 2023/7/3
* @Description:
*/
import com.scali.experiment.entity.Message;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Timestamp;
public class MysqlSink extends RichSinkFunction<Message> {
private Connection connection;
private PreparedStatement preparedStatement;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
Class.forName("com.mysql.cj.jdbc.Driver");
connection = DriverManager.getConnection("jdbc:mysql://ip:3306/flink-datastream", "username", "password");
preparedStatement = connection.prepareStatement("INSERT INTO datastream(shotnum, fsize, ctime) VALUES (?, ?, ?)");
}
@Override
public void invoke(Message value, Context context) throws Exception {
// preparedStatement.setLong(1, value.getId());
preparedStatement.setLong(1, value.getShotnum());
preparedStatement.setDouble(2, value.getDifference());
preparedStatement.setTimestamp(3, new Timestamp(context.timestamp()));
preparedStatement.executeUpdate();
}
@Override
public void close() throws Exception {
super.close();
if (preparedStatement != null) {
preparedStatement.close();
}
if (connection != null) {
connection.close();
}
}
}
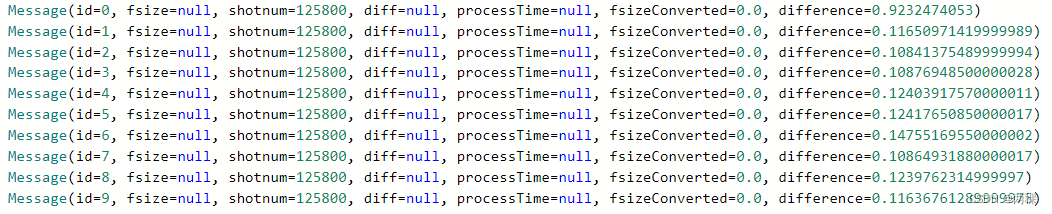
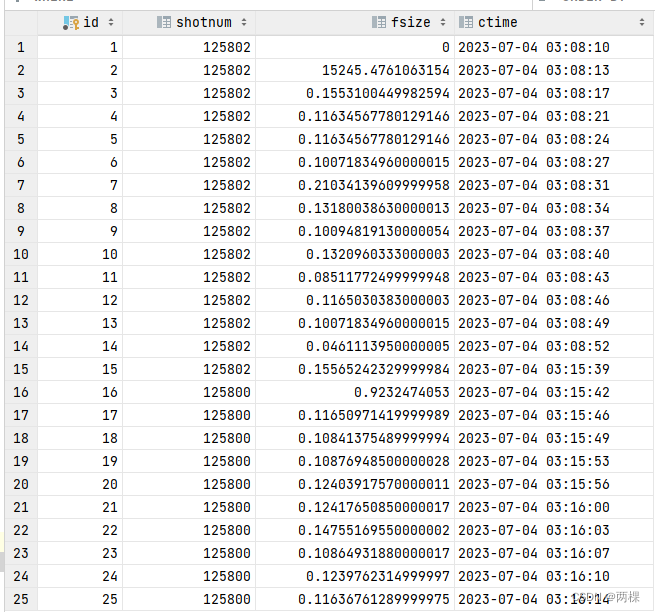
5 测试效果
目前展示一个输出和数据库截图。代码存在一定问题,后续还需要修改。















 1330
1330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









