







 文章详细阐述了多元线性回归模型的构建,包括术语解释、向量化表示以及离散特征的量化。它强调了特征缩放的重要性,介绍了Z-score标准化方法,以及在梯度下降过程中如何选择合适的学习率。通过绘制成本函数的等高线图,展示了特征缩放如何改善模型收敛性。此外,文章还探讨了如何通过特征工程选择合适的特征,例如在多项式回归中使用高阶特征,并分析了梯度下降在不同特征尺度下的表现。
文章详细阐述了多元线性回归模型的构建,包括术语解释、向量化表示以及离散特征的量化。它强调了特征缩放的重要性,介绍了Z-score标准化方法,以及在梯度下降过程中如何选择合适的学习率。通过绘制成本函数的等高线图,展示了特征缩放如何改善模型收敛性。此外,文章还探讨了如何通过特征工程选择合适的特征,例如在多项式回归中使用高阶特征,并分析了梯度下降在不同特征尺度下的表现。
文章目录
Multiple Linear Regression
在前一部分,我们研究了单个特征的线性回归,进一步,我们想要研究具有多个特征的线性回归模型。
Terminology
x j x_j xj:第j个特征
n:特征的数量
x ⃗ ( i ) \vec x^{(i)} x(i):第i个训练数据的特征集
x ⃗ j ( i ) \vec x_j^{(i)} xj(i):第i个数据的第j个特征
Model
对于多个特征的模型,其线性回归模型的表达式为
f
w
,
b
=
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
n
x
n
+
b
=
∑
j
=
1
n
w
j
x
j
+
b
f_{w, b} = w_1x_1 + w_2x_2 + ... + w_nx_n + b = \sum_{j = 1}^n w_jx_j + b
fw,b=w1x1+w2x2+...+wnxn+b=j=1∑nwjxj+b
用向量的方式表示
w
⃗
=
[
w
1
,
w
2
,
.
.
.
,
w
n
]
x
⃗
=
[
x
1
,
x
2
,
.
.
.
,
x
n
]
f
w
⃗
,
b
=
w
⃗
⋅
x
⃗
+
b
=
w
⃗
x
⃗
T
+
b
\vec w = [w_1, w_2, ..., w_n] \newline \vec x = [x_1, x_2, ..., x_n] \newline f_{\vec w, b} = \vec w \cdot \vec x + b = \vec w \vec x^T + b
w=[w1,w2,...,wn]x=[x1,x2,...,xn]fw,b=w⋅x+b=wxT+b
这种技巧称为矢量化(vectorization)。
离散特征的量化
类似“房屋面积:房屋价格”这种连续的特征关系,量化较为容易;而实际场景中,有很多特征都是离散的,在此讨论下如何量化离散特征
- 对只有“是”或“否”的离散特征,可以使用0,1来表示,称为二值离散特征
- 对于有多个离散值,且离散值之间存在顺序关系的,例如饭量“大”,“中”,“小”,可以使用有序的离散值来表示,称为有序的多值离散特征(“大”:3,“中”:2,“小”:1)
- 对有多个离散值,离散值之间不具有顺序关系,例如肤色“黄”,”白“,”黑“,不能直接分配有序的离散值,而是应该拆成多个二值离散特征进行表示(黄:[1,0,0],白:[0,1,0],黑:[0,0,1])
Vectorization
Code Implement
设有如下参数

在Numpy中,可以这样表示
import numpy as np
w = np.array([1.0, 2.5, -3.3])
b = 4
x = np.array([10, 20, 30])
通过向量化的, f w ⃗ , b f_{\vec w, b} fw,b可以实现为
f_wb = np.dot(w, x) + b
使用向量化运算有两个好处:
- 代码更加整洁可读
- Numpy底层可以并行处理,效率更快
How could vectorization run much more faster than simply loop
当采用loop实现方法的时候,程序会顺序执行每个f += w[i] * x[i]

而在向量化实现中,计算机可以同时并行计算多个w[i] * x[i]
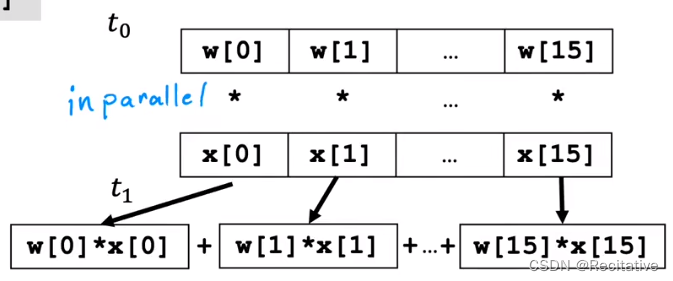
以上是使用线性代数库计算性能的直观表示
Gradient Descent
首先关注多个feature,假定b=0,此时对多个 w j w_j wj,存在同样数量的导数 d j d_j dj,同样考虑一个向量化的实现方式。
w = np.array([...])
d = np.array([...])
alpha = 0.1 # 学习率
# loop实现
for j in range(n):
w[j] = w[j] - alpha * d[j]
# 向量化实现
w = w - alpha * d
NumPy和Python补充
创建array
转换Python序列**(List, Tuple)**为NumPy Array
import numpy as np
a1 = np.array([1, 2, 3, 4]) # 创建1D array
a2 = np.array([1, 2], [3, 4]) # 创建2D array
List或Tuple的嵌套会创建高维的数组。所有的array对象在NumPy中都称为
ndarray。即n-dimensional array
你可以显式指定数组元素的数据类型,使用dtype参数;指定参数类型要注意别越界,例如
a = np.array([127, 128, 129], dtype = np.int8)
'''
array([ 127, -128, -127], dtype=int8)
'''
当使用两个不同dtype的array进行计算时,结果矩阵的数据类型会匹配为能够兼容两种dtype的类型。
内置的矩阵创建函数
NumPy包含40多个内置的函数可以创建矩阵(Array creation routines)。这些函数可以根据数组的维数,大致分为3类:
- 1D arrays
- 2D arrays
- ndarrays
这里先列出吴恩达老师提到的课程要用的那些
1D array
# np.arange((start = 0, )end(, step = 1)) # 返回从start开始,end结束,步长为step的分布数组, start和step可缺省
>>> np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.arange(2, 10, dtype = float)
array([2., 3., 4., 5., 6., 7., 8., 9.])
>>> np.arange(2, 3, 0.1)
array([2. , 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9])
# np.linspace(start, end, num) # 返回从start开始,end结束,长度为num的数组,step呈均匀分布
>>> np.linspace(1., 4., 6)
array([1. , 1.6, 2.2, 2.8, 3.4, 4. ])
nD array
# np.zeros(shape: Tuple) # 生成多维array,参数shape是一个元组,指定array的形状,填充0
>>> np.zeros((2,))
array([0., 0.])
>>> np.zeros((2, 3, 2))
array([[[0., 0.],
[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.],
[0., 0.]]])
# np.ones(shape: Tuple) # 生成多维array, shape是元组,指定array的形状,填充1
>>> np.ones((2, 3, 2))
array([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
# np.random.random_sample(shape: Tuple) # 生成多维array,填充[0, 1]的浮点
>>> np.random.random_sample((2, 3, 2))
array([[[0.58886443, 0.00125135],
[0.55973185, 0.25874808],
[0.03675558, 0.7065201 ]],
[[0.72083918, 0.13066142],
[0.50732886, 0.37403505],
[0.16216774, 0.07918865]]])
copy
当需要将一个array中的数据赋给一个新的变量的时候,需要显式调用numpy.copy,执行深拷贝,否则新变量指向的是原始array的数据。
给出一个错误的例子
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> b = a[:2]
>>> b += 1
>>> print('a =', a, '; b =', b)
a = [2 3 3 4 5 6] ; b = [2 3]
在这个例子中,没有执行深拷贝,因此b指向a的原始数据,当执行b+=1的时候,会修改a中的值。或者说,这里创建的b是a的一个视图(view),视图相当于对原始数据的一个子集的索引。
正确的写法
>>> a = np.array([1, 2, 3, 4])
>>> b = a[:2].copy()
>>> b += 1
>>> print('a = ', a, 'b = ', b)
a = [1 2 3 4] b = [2 3]
operation
Index 索引
使用[]索引array中的元素,索引从0到n-1,索引不可以越界
>>> a = np.arange(10)
>>> print(a[2])
2
Slicing 切片
使用(start = 0: stop = n-1: step = 1)获取数组的一个子集,注意[start, stop)左包含右不包含
>>> a = np.arange(10)
>>> c = a[2: 7: 2]; print(c)
[2 4 6]
>>> c = a[3:]; print(c)
[3 4 5 6 7 8 9]
>>> c = a[:-1]; print(c)
[0 1 2 3 4 5 6 7 8]
>>> c = a[:]; print(c)
[0 1 2 3 4 5 6 7 8 9]
同样可以对n维数组进行切片,多个(start = 0: stop = n-1: step = 1)之间用,隔开。
>>> a = np.arange(20).reshape(-1, 10)
>>> print(a)
[[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]]
>>> #access 5 consecutive elements (start:stop:step)
... print("a[0, 2:7:1] = ", a[0, 2:7:1], ", a[0, 2:7:1].shape =", a[0, 2:7:1].shape, "a 1-D array")
a[0, 2:7:1] = [2 3 4 5 6] , a[0, 2:7:1].shape = (5,) a 1-D array
>>> #access 5 consecutive elements (start:stop:step) in two rows
... print("a[:, 2:7:1] = \n", a[:, 2:7:1], ", a[:, 2:7:1].shape =", a[:, 2:7:1].shape, "a 2-D array")
a[:, 2:7:1] =
[[ 2 3 4 5 6]
[12 13 14 15 16]] , a[:, 2:7:1].shape = (2, 5) a 2-D array
>>> # access all elements
... print("a[:,:] = \n", a[:,:], ", a[:,:].shape =", a[:,:].shape)
a[:,:] =
[[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]] , a[:,:].shape = (2, 10)
>>> # access all elements in one row (very common usage)
... print("a[1,:] = ", a[1,:], ", a[1,:].shape =", a[1,:].shape, "a 1-D array")
a[1,:] = [10 11 12 13 14 15 16 17 18 19] , a[1,:].shape = (10,) a 1-D array
>>> # same as
... print("a[1] = ", a[1], ", a[1].shape =", a[1].shape, "a 1-D array")
a[1] = [10 11 12 13 14 15 16 17 18 19] , a[1].shape = (10,) a 1-D array
Single vector
NumPy支持对向量执行sum(),mean()等操作,包括对向量中的元素执行逐元素的操作(例如倍乘,或者说数乘向量)
>>> a = np.arange(4)
>>> print(-a)
[ 0 -1 -2 -3]
>>> print(np.sum(a))
6
>>> print(np.mean(a))
1.5
>>> print(a**2)
[0 1 4 9]
>>> print(a * 5)
[ 0 5 10 15]
向量和差
NumPy支持两个等shape向量求和差,如果不同shape的话,会尝试进行向量广播(Boardcast),广播可能导致不可预知的后果。
>>> a = np.arange(4)
>>> b = np.arange(5, 9)
>>> print(a, b, a + b)
[0 1 2 3] [5 6 7 8] [ 5 7 9 11]
>>> a = np.arange(4)
>>> b = np.ones((2, 4))
>>> print(a); print(b)
[0 1 2 3]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]]
>>> print(a + b)
[[1. 2. 3. 4.]
[1. 2. 3. 4.]]
dot
NumPy的.dot()在底层会通过并行计算加速运算,所以不要自己写个loop代替。
>>> a = np.array([1, 2, 3, 4])
>>> b = np.array([-1, 4, 3, 2])
>>> c = np.dot(a, b); print(c)
24
>>> c = np.dot(b, a); print(c)
24
dot的结果是一个标量(数),同时,正如你在线性代数课程上所学到的,dot满足交换律,具体可以参考3b1b《线性代数的本质》
reshape
将ndarray的shape修改,不修改内部元素。
numpy.reshape(a, newshape, order={'C', 'F', 'A'})
'''
parameters:
a: array_like # Array to be reshaped
newshape: int or tuple of ints # new shape should be compatible with the original shape.
# one shape dimension can be -1, so the value will be inferred
order: {'C','F','A'} # different index order
# 'C' means using C-like order
# 'F' means using Fortran-like order
# 'A' means auto choice
returns
reshaped_array: ndarray
'''
>>> a = np.arange(6).reshape((-1,2))
>>> print(f'{a.shape}, \n{a}')
(3, 2),
[[0 1]
[2 3]
[4 5]]
数据集初步观察
对拿到的数据集,可以先绘制每个特征与目标值之间的关系图,例如,对一个房屋价格预测模型,有4个特征(size, bedrooms, floors, age),通过matplotlib绘图
import matplotlib.pyplot as plt
# load dataset
X_train, y_train = load_house_data()
X_features = ['size(sqft)','bedrooms','floors','age']
# plotting each feature versus price
fig,ax=plt.subplots(1, 4, figsize=(12, 3), sharey=True)
for i in range(len(ax)):
ax[i].scatter(X_train[:,i],y_train)
ax[i].set_xlabel(X_features[i])
ax[0].set_ylabel("Price (1000's)")
plt.show()
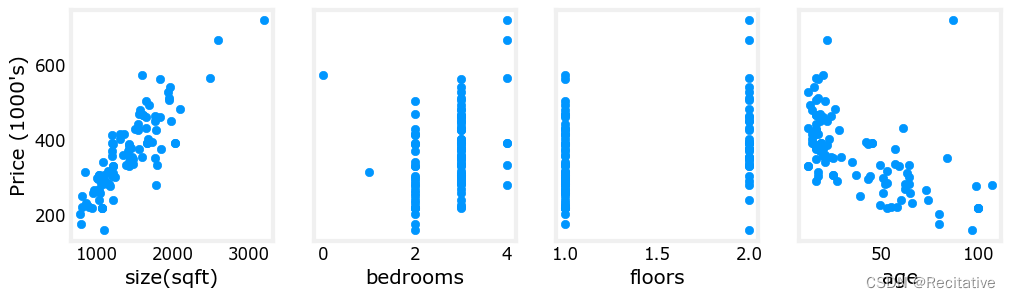
如上,可以粗略观察到,房屋的面积和价格呈正相关。新房屋通常比旧房屋价格高。而卧室数量和层数没有看出明显影响。
Gradient Descent for Multiple Regression
类似单元线性回归,多元线性回归需要迭代更新 w i w_i wi和 b b b,从而最小化损失函数
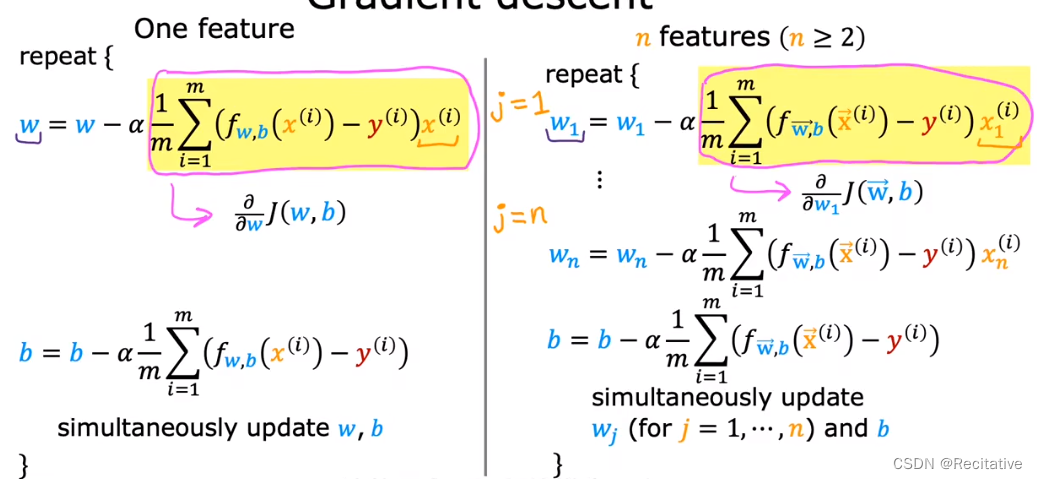
Multiple Variables Linear Prediction
多元线性模型的向量表示如下
f
w
,
b
=
w
⃗
⋅
x
⃗
+
b
f_{w, b} = \vec w \cdot \vec x + b
fw,b=w⋅x+b
在代码中的实现
import numpy as np
f_wb = np.dot(w, x) + b
Cost function
多元线性模型的损失函数可以表示为
J
(
w
⃗
,
b
)
=
1
2
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
⃗
i
)
−
y
i
)
2
=
1
2
m
∑
i
=
0
m
−
1
(
w
⃗
⋅
x
⃗
i
+
b
−
y
i
)
2
J(\vec w, b) = \frac 1 {2m} \sum_{i = 0}^{m-1} (f_{w, b}(\vec x_i) - y_i)^2 \newline = \frac 1 {2m} \sum_{i = 0}^{m-1} (\vec w \cdot \vec x_i + b - y_i)^2
J(w,b)=2m1i=0∑m−1(fw,b(xi)−yi)2=2m1i=0∑m−1(w⋅xi+b−yi)2
其中,
x
⃗
i
\vec x_i
xi代表第i行数据,是一个向量。
在代码中的实现(使用loop)
# X: 2darray, 存放数据的2D数组,每行为一个数据
# y: 1darray, 存放target,是一个1D数组
import numpy as np
def dompute_cost(X, y, w, b):
cost = 0.0f
for i in range(X.shape[0]): # 遍历每个数据
f_wb = np.dot(X[i], w) + b
cost = cost + (f_wb - y[i])**2
cost /= (2*m)
Compute Gradient
梯度的严格定义是多元函数的一阶导数。设
n
n
n元函数
f
(
x
)
f(x)
f(x)对自变量
x
=
(
x
1
,
x
2
,
.
.
.
,
x
n
)
T
x = (x_1, x_2, ..., x_n)^T
x=(x1,x2,...,xn)T各分量
x
i
x_i
xi的偏导数
∂
f
(
x
)
∂
x
i
\frac {\partial f(x)}{\partial x_i}
∂xi∂f(x)都存在,称函数
f
(
x
)
f(x)
f(x)对
x
x
x一阶可导,向量
∇
f
(
x
)
=
[
∂
f
(
x
)
∂
x
1
∂
f
(
x
)
∂
x
2
⋮
∂
f
(
x
)
∂
x
n
]
\nabla f(x) = \left[\begin{array}{} \frac {\partial f(x)}{\partial x_1}\\ \frac {\partial f(x)}{\partial x_2}\\ \vdots\\ \frac {\partial f(x)}{\partial x_n} \end{array}\right]
∇f(x)=
∂x1∂f(x)∂x2∂f(x)⋮∂xn∂f(x)
为
f
(
x
)
f(x)
f(x)对x的一阶导数或梯度。
在多元线性回归中,梯度的计算可以表示为
∂
J
(
w
⃗
,
b
)
∂
w
j
=
1
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
⃗
i
)
−
y
i
)
x
i
,
j
∂
J
(
w
⃗
,
b
)
∂
b
=
1
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
⃗
i
)
−
y
i
)
\frac {\partial J(\vec w, b)}{\partial w_j} = \frac 1 m \sum_{i = 0}^{m-1} (f_{w, b}(\vec x_i) - y_i)x_{i, j} \newline \frac {\partial J(\vec w, b)}{\partial b} = \frac 1 m \sum_{i = 0}^{m-1} (f_{w, b}(\vec x_i) - y_i)
∂wj∂J(w,b)=m1i=0∑m−1(fw,b(xi)−yi)xi,j∂b∂J(w,b)=m1i=0∑m−1(fw,b(xi)−yi)
其中
e
r
r
o
r
=
(
f
w
,
b
(
x
⃗
i
)
−
y
i
)
error = (f_{w, b}(\vec x_i) - y_i)
error=(fw,b(xi)−yi)是公共项,可以在计算每个样例的时候复用。
代码实现如下
def compute_gradient(X, y, w, b):
m, n = X.shape
dj_dw = np.zeros((n,))
dj_db = 0.0f
for i in range(m):
err = np.dot(X[i], w) + b - y[i]
# 累加每个dj_jw
for j in range(n):
dj_dw += err * x[i, j]
# 累加dj_db
dj_db += err
# 求均值
dj_dw /= m
dj_db /= m
return dj_db, dj_dw
Gradient Descent
多元梯度下降的数学表达式可以表示为
w
j
=
w
j
−
α
∂
J
(
w
⃗
,
b
)
∂
w
j
,
j
=
0
,
…
,
n
−
1
b
=
b
−
α
∂
J
(
w
⃗
,
b
)
∂
b
w_j = w_j - \alpha \frac {\partial J(\vec w, b)}{\partial w_j}, j = 0, \dots, n-1 \newline b = b - \alpha \frac {\partial J(\vec w, b)}{\partial b}
wj=wj−α∂wj∂J(w,b),j=0,…,n−1b=b−α∂b∂J(w,b)
迭代上式直到拟合。
代码实现
def gradient_descent(X, y, w_init, b_init, cost_function, gradient_function, alpha, num_iter):
w = copy.deepcopy(w_in) # 深拷贝w_in,避免修改原始变量
b = b_in
for i in range(num_iters):
dj_db, dj_dw = gradient_funciton(X, y, w, b)
w -= alpha * dj_dw
b -= alpha * dj_db
return w, b
Feature Scaling
Background
在上一个lab中,我们尝试实现了多元梯度下降,但模型的训练结果并不理想,经过1000轮迭代后,绘制cost曲线如下
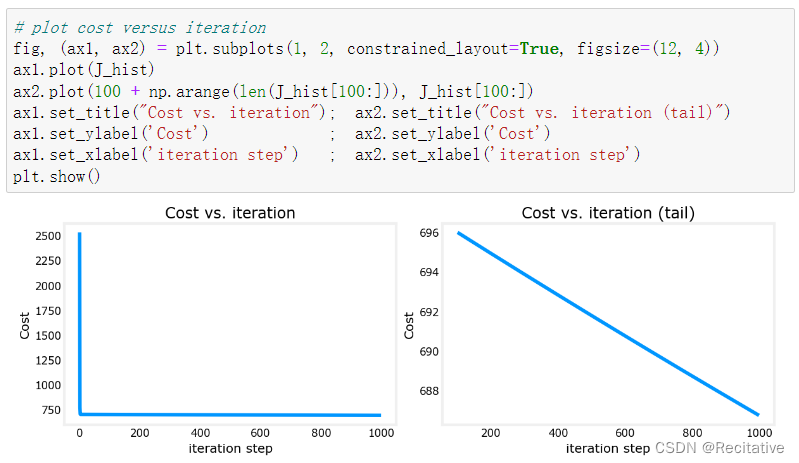
模型远没有拟合,且预测值与目标值差异很大。这是由于特征尺度不同所导致的。
对多元梯度下降,不同的特征会有不同的取值范围,例如在房屋价格预测模型中,房屋的面积范围可能是[200, 3000],而房屋的卧室数范围可能是[0, 5],两者的度量尺度存在很大的差异。
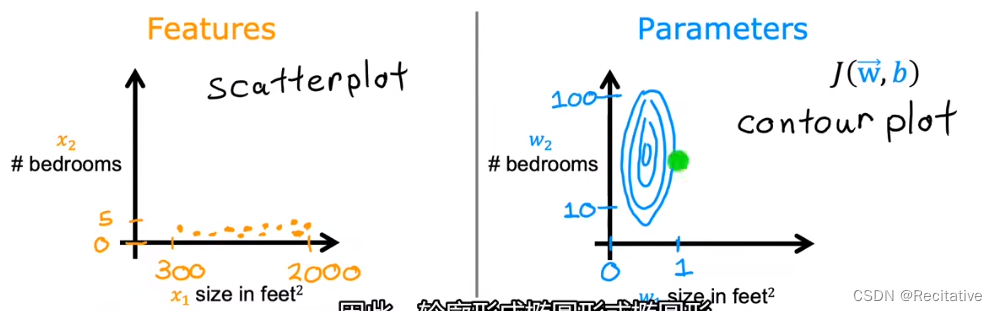
如图所示,当两个特征之间的度量尺度存在很大差异的时候,会导致两者cost函数的等高线图呈椭圆形(contour);在图中的例子里,房屋大小对应的参数 w 1 w_1 w1只需要轻微变化,就能很大程度影响预测值,而卧室数量对应的参数 w 2 w_2 w2则需要移动很大的步长才能对预测值产生明显影响。最终导致梯度下降在椭圆较瘦的方向上反复跳动,降低学习效率。
避免这种问题,可以采用特征缩放,调整(rescale)不同特征的尺度。例如全都缩放到[0, 1],使得两者在可以相互比较的度量尺度(take on comparable range of values)内,等高线图呈近乎圆形。

总结一下,之所以使用特征缩放,原因有两个:
- 防止范围过广的特征左右误差(距离)
- 加速梯度下降的收敛
下图是从数学表达式上理解为什么需要缩放特征,因为w参数的更新量需要乘对应的特征值,因此在每个参数的 α \alpha α相同的情况下,特征值较大的参数变化就更大。例如,房屋大小的特征值普遍大于1000,而床位数通常在2-4之间,房屋大小的更新速度要比床位数快得多。

Methods
实现特征缩放有很多方法,例如**除阈值(Devide range),均值标准化(Mean normalization)和Z-score 标准化(Z-score normalization)**等。
当数据存在下面几种特点的时候,应当进行缩放:
- 值域太大,例如[-1000, 1000]
- 值域太小,例如[-0.001, 0.001]
- 基太大,例如[900, 1000]
缩放后的数据范围应当接近[-1, 1]或[0, 1]。
Devide range
数学表达式如下
x
j
,
s
c
a
l
e
d
=
x
j
max
−
min
x_{j, scaled} = \frac {x_j} {\max - \min}
xj,scaled=max−minxj
Mean normalization
首先计算均值
μ
j
\mu_j
μj,然后用误差除值域
x
j
=
x
j
−
μ
j
max
−
min
x_j = \frac {x_j - \mu_j}{\max - \min}
xj=max−minxj−μj
Z-score normalization
计算标准分数(Standard Score),又称z-score,经过该变换的样本值通常在 ± 5 \pm5 ±5或 ± 6 \pm 6 ±6之间。
标准分数的计算如下
z
=
x
−
μ
σ
z = \frac {x - \mu} \sigma
z=σx−μ
其中,
μ
\mu
μ为均值,
σ
\sigma
σ为标准差。
这里其实有个挺细节的点:计算Z值需要的是总体的均值和标准差,而不是样本均值和标准差。而总体通常是没有办法度量的,因此通常会使用随机样本来评估,此时标准分数为
z = x − x ˉ S z = \frac {x - \bar x} {S} z=Sx−xˉ
另一个需要关注的点为,这里将特征值标准化为了标准正态分布,处理后的特征值,均值为0,标准差为1
向量标准化
将特征向量整体变为单位向量(即除以向量长度)
x
=
x
∣
∣
x
∣
∣
x = \frac x {||x||}
x=∣∣x∣∣x
Implement
实现一下z-score标准化。
首先计算均值和标准差
μ
j
=
1
m
∑
i
=
0
m
−
1
x
j
(
i
)
σ
j
2
=
1
m
∑
i
=
0
m
−
1
(
x
j
(
i
)
−
μ
j
)
2
\mu_j = \frac 1 m \sum_{i = 0}^{m - 1} x_j^{(i)} \newline \sigma_j^2 = \frac 1 m \sum_{i = 0}^{m - 1} (x_j^{(i)} - \mu_j)^2
μj=m1i=0∑m−1xj(i)σj2=m1i=0∑m−1(xj(i)−μj)2
使用这两个测量值缩放输入
x
j
(
i
)
=
x
j
(
i
)
−
μ
j
σ
j
x_j^{(i)} = \frac {x_j^{(i)} - \mu_j} {\sigma_j}
xj(i)=σjxj(i)−μj
注意:应当把均值和方差也一并存储下来,后面预测新值的时候再次用来标准化。
NumPy提供了计算这些测量值的方法,可以直接调用
import numpy as np
def zscore_normalize(X):
'''
Compute zscore normalized X
Args:
X (ndarray): Shape(m, n) input data, m examples, n features
Returns:
X_norm (ndarray): Shape(m, n) normalized X
mu (ndarray): Shape(n, ) mean of each feature
sigma (ndarray): Shape(n,) standard deviation of each feature
'''
mu = np.mean(X, axis = 0) # compute mean of each column
sigma = np.std(X, axis = 0) # compute standard deviation of each column
X_norm = (X - mu) / sigma # will be broadcast to each column
return (X_norm, mu, sigma)
标准化的结果可以通过绘制散点图来观察
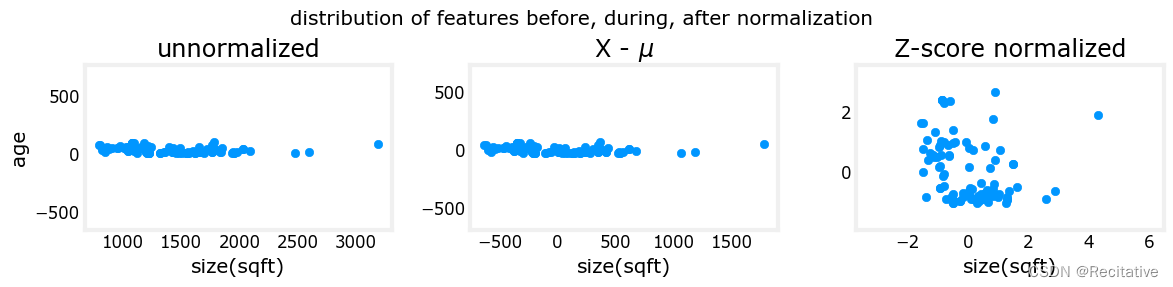
可以观察到,减去均值后,特征值会分布在0的周围;而除以标准差后,特征值会被缩放到较小的范围。
也可以通过np.ptp()来观察极差的变化,ptp是peak to peak的缩写,即从一个极值到另一个极值。
>>> # normalize the original features
>>> X_norm, X_mu, X_sigma = zscore_normalize_features(X_train)
>>> print(f"X_mu = {X_mu}, \nX_sigma = {X_sigma}")
>>> print(f"Peak to Peak range by column in Raw X:{np.ptp(X_train,axis=0)}")
>>> print(f"Peak to Peak range by column in Normalized X:{np.ptp(X_norm,axis=0)}")
X_mu = [1.42e+03 2.72e+00 1.38e+00 3.84e+01],
X_sigma = [411.62 0.65 0.49 25.78]
Peak to Peak range by column in Raw X:[2.41e+03 4.00e+00 1.00e+00 9.50e+01]
Peak to Peak range by column in Normalized X:[5.85 6.14 2.06 3.69]
Cost Contour
通过绘制成本函数的等高线图,也可以观察到不同特征的阈值是否匹配
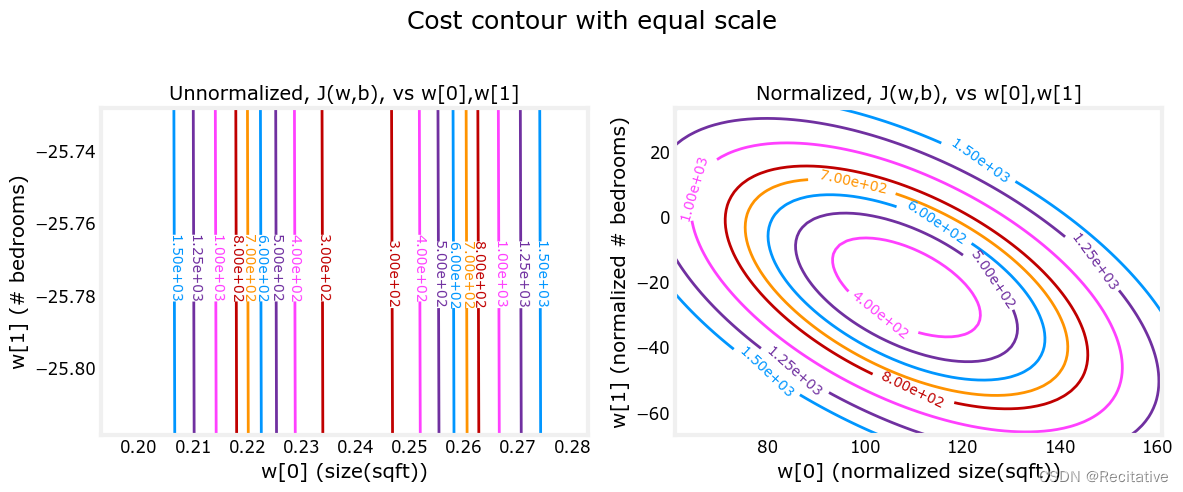
如上图所示,在对数据进行标准化之前,特征值之间的阈值差异过大,甚至无法观察出图像是一个椭圆;而在进行标准化后,两个特征值之间的阈值更为接近,这会使得梯度下降时的步长更相似。
Checking Convergence
通过学习分辨什么是运行良好的梯度下降,从而选择更好的学习率。
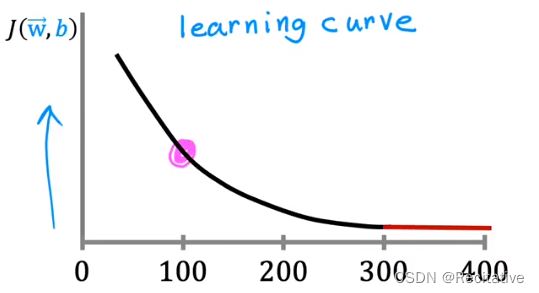
- 绘制迭代次数(iterations)/损失函数 J ( w ⃗ , b ) J(\vec w, b) J(w,b)图像,是**学习曲线(Learning curve)**的一种;如果梯度下降运行正常,损失函数应当一直下降;若出现上升,可能是因为bug或者 α \alpha α太大;同时,曲线应当逐渐变平(逐渐收敛),通过图像可以很方便地找到拟合位置,确定何时完成训练
- 使用自动收敛判断(Autimatic convergence test)。令 ε \varepsilon ε为一个极小值,例如 1 0 − 3 10^{-3} 10−3,若某一次梯度下降中成本的减少量 ≤ ε \le \varepsilon ≤ε,则认为模型收敛。当然,这种方法要求选择合适的 ε \varepsilon ε,且不如画图直观。
Choosing the Learning Rate
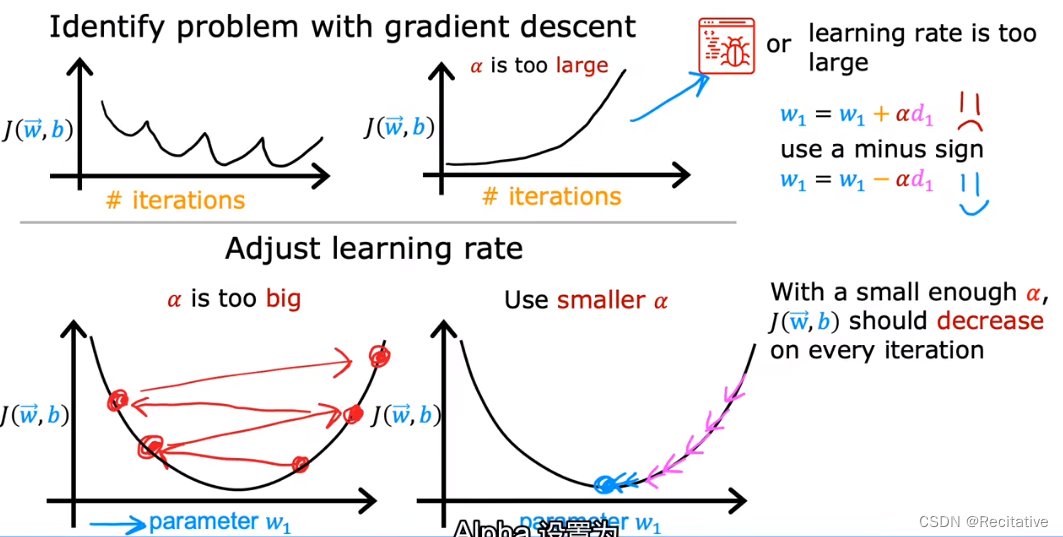
如图所示,当损失函数图像出现上下抖动,或者成本不断增高的时候(本质上是成本没有下降);可能是由于代码编写错误或者学习率过高导致的。区分究竟是 α \alpha α的问题,还是代码编写错了,可以先将 α \alpha α设为一个极小值,看看修改后损失函数会不会正常下降。如果不会的话,通常是代码编写错了。
注意:这里设一个非常非常小的 α \alpha α是为了辨别错误类型。过小的 α \alpha α也会是梯度下降过慢,增加迭代开销。
在开始训练一个新的模型的时候,可以先设置一组不同量级的学习率,例如alphas = [0.001, 0.01, 0.1, 1],使用每个学习率运行少量迭代数,并绘制成本函数。从而选择快速且始终保持下降的学习率。重点是要找到
α
\alpha
α过小和过大的边界,如图所示;并选择尽可能大的学习率。
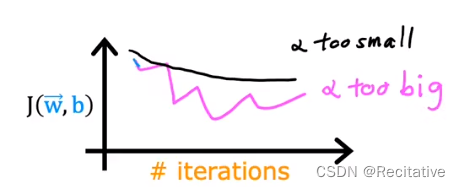
为了能够直观观察是否收敛,我们可以像前面所学的那样,绘制“成本函数-迭代次数”的变化曲线,以及在“成本-参数”曲线中,标注梯度下降点的位置
import numpy as np
import matplotlib.pyplot as plt
def plot_cost(X, y, hist):
'''
plot cost-iteration and cost-w[0] fig
Arguments:
X: np.ndarray: train examples in 2D array
y: np.ndarray: target values in 1D array
hist: dict: dict of iteration history
hist["cost"] = []; hist["params"] = []; hist["grads"]=[]; hist["iter"]=[];
Returns: nothing
'''
ws = np.array(p[0] for p in hist["params"]) # get w[0]s
rng = max(abs(ws[:, 0].min()), abs(ws[:,0].max())) # get range of ws
wr = np.linspace(-rng+0.27, rng+0.27, 20) # x axis for plot
cst = [compute_cost(X, y, np.array([wr[i], -32, -67, -1.46]), 221) for i in range(len(wr))] # compute cost of in wr range, with fixed parameters w_1, w_2, w_3
fig, ax = plt.subplots(1, 2, figsize = (12, 3))
ax[0].plot(hist["iter"], hist["cost"]);
ax[0].set_title("Cost vs Iteration")
ax[0].set_xlabel("iteration"); ax[0].set_ylabel("Cost") # plot cost vs iteration
ax[1].plot(wr, cst); ax[1].set_title("Cost vs w[0]") # plot gradient descent direction
ax[1].set_xlabel("w[0]"); ax[1].set_ylabel("Cost")
ax[1].plot(ws[:0], hist["Cost"]) # plot cost vs w[0] bowl curve
因为这个函数只关注了4个特征中的一个,而其他的3个特征取了最优固定值,因此绘制出来的图像可能会有些错位。
下面是一些不同学习率下的绘图结果
α = 9.9 e − 7 \alpha = 9.9e-7 α=9.9e−7
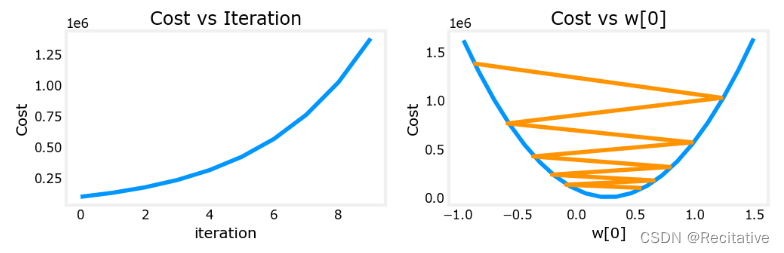
成本不降反增,且参数会越过(overshoot)最优值,不断上升。
α = 9 e − 7 \alpha = 9e-7 α=9e−7
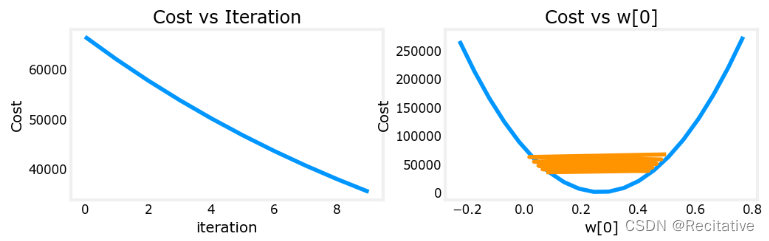
成本能够正常下降,但参数仍然在震荡,虽然最终可以收敛,但效率会很差
α = 1 e − 7 \alpha = 1e-7 α=1e−7
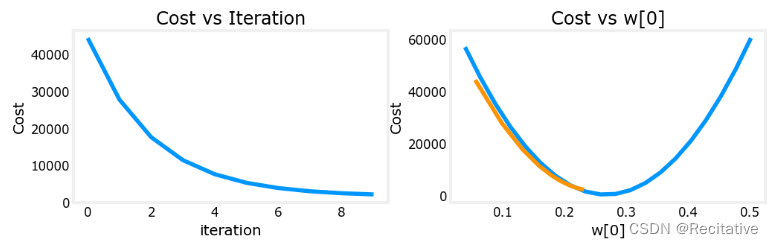
成本能够正常下降,且参数不会越过最小值,这样收敛速度会快得多
Feature Engineering - Choosing right features
特征设计(Feature Engineering)就是根据对模型的理解和直觉,设计新的特征,通常使用转换(transform)或者组合(combine)原始特征的方法。进行特征设计的目的是获得更利于模型做出准确预测的特征。
以预测房价为例,房屋可以有长和宽两个特征,你可以选择将两个特征分别作为特征值分配参数
f
w
⃗
,
b
(
x
⃗
)
=
w
1
x
1
+
w
2
x
2
+
b
f_{\vec w, b}(\vec x) = w_1x_1 + w_2x_2 + b
fw,b(x)=w1x1+w2x2+b
也可以考虑使用长和宽计算出房屋的面积,使用面积作为特征值
x
3
=
x
1
x
2
f
w
⃗
,
b
(
x
⃗
)
=
w
3
x
3
+
b
x_3 = x_1 x_2 \newline f_{\vec w, b}(\vec x) = w_3x_3 + b
x3=x1x2fw,b(x)=w3x3+b
直觉上来说,后者更符合现实生活中的购房情况,更利于训练准确的模型。
Polynomial regression
在某些情况下,线性模型可能不能完美地拟合我们的数据,例如下图的情况。

也许更高阶的函数能够更好地拟合这个数据(这部分有点数字信号处理的内容了,总之更高阶的函数能够更好拟合复杂图像).
需要注意的是,当使用更高阶的函数时,特征的缩放就显得更为重要,因为高阶函数会进一步放大不同特征值之间的极差差距,导致下降步长不一致。
Simple quadratic
首先考虑一个简单的非线性场景,设 y = 1 + x 2 y = 1 + x^2 y=1+x2
使用前面的线性回归模型进行拟合
# create target data
x = np.arange(0, 20, 1)
y = 1 + x**2
X = x.reshape(-1, 1)
model_w,model_b = run_gradient_descent_feng(X,y,iterations=1000, alpha = 1e-2)
plt.scatter(x, y, marker='x', c='r', label="Actual Value"); plt.title("no feature engineering")
plt.plot(x,X@model_w + model_b, label="Predicted Value"); plt.xlabel("X"); plt.ylabel("y"); plt.legend(); plt.show()
w,b found by gradient descent: w: [18.7], b: -52.0834
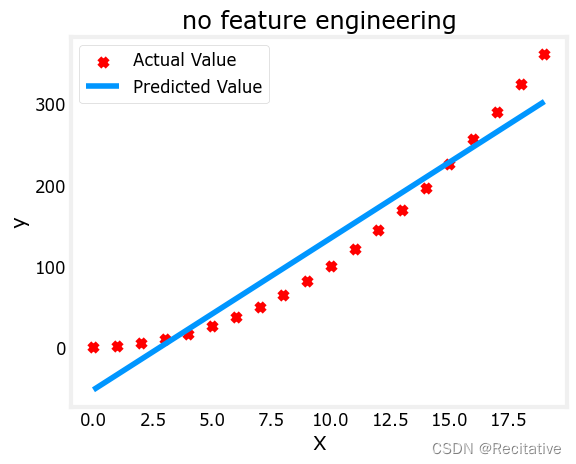
很明显,函数不能很好地拟合,我们需要设计更为有效的特征值,例如尝试将x取平方
# create target data
x = np.arange(0, 20, 1)
y = 1 + x**2
# Engineer features
X = x**2 #<-- added engineered feature
X = X.reshape(-1, 1) #X should be a 2-D Matrix
model_w,model_b = run_gradient_descent_feng(X, y, iterations=10000, alpha = 1e-5)
plt.scatter(x, y, marker='x', c='r', label="Actual Value"); plt.title("Added x**2 feature")
plt.plot(x, np.dot(X,model_w) + model_b, label="Predicted Value"); plt.xlabel("x"); plt.ylabel("y"); plt.legend(); plt.show()
w,b found by gradient descent: w: [1.], b: 0.0490
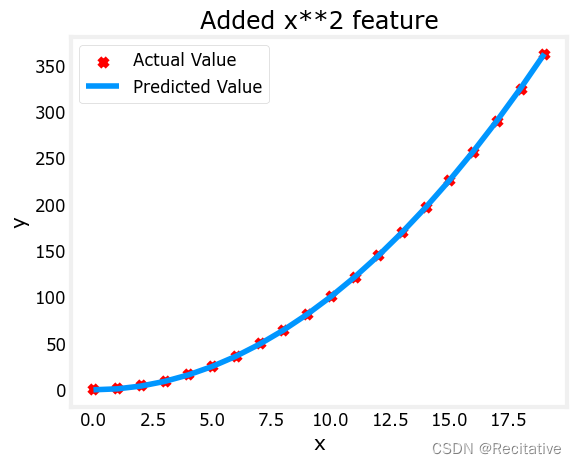
这一次,获得了十分接近target的拟合: y = 0.0490 + x 2 y = 0.0490 + x^2 y=0.0490+x2。
Selecting Features
在前面,我们讨论了一个简单的非线性模型的例子,接下来,我们要讨论如何选择合适的特征,因为很多时候,我们不能直观推断怎样的多项式特征更符合数据。
选择特征的一种方法是利用梯度下降对权重的分配,根据权重的大小,可以判断出该特征对拟合的影响程度,从而选择合适的特征。
我们以 y = w 0 x 0 + w 1 x 1 2 + w 2 x 2 3 + b y = w_0x_0 + w_1 x_1^2 + w_2 x_2^3 + b y=w0x0+w1x12+w2x23+b和上面的数据集为例,分析使用梯度下降法选取特征的细节。
Feature scaling
在进行梯度下降之前,我们需要先进行特征缩放,因为 x 0 , x 1 2 x_0, x_1^2 x0,x12和 x 2 3 x_2^3 x23明显具有不同的阈值,我们可以进行比较:
# create target data
x = np.arange(0,20,1)
X = np.c_[x, x**2, x**3]
print(f"Peak to Peak range by column in Raw X:{np.ptp(X,axis=0)}")
# add mean_normalization
X = zscore_normalize_features(X)
print(f"Peak to Peak range by column in Normalized X:{np.ptp(X,axis=0)}")
Peak to Peak range by column in Raw X:[ 19 361 6859]
Peak to Peak range by column in Normalized X:[3.3 3.18 3.28]
进行缩放后,特征阈值更加一致,梯度下降的效果会更好。
np.c_[..]用来将不同的列串联,或者按照NumPy手册的说法,根据第二个轴(along the second axis)。这个方法是
np.r_['-1, 2, 0', index expression]的快捷写法,numpy.r_方法可以将切片对象转换为沿第一个轴的串联(c和r分别是column和row的简写)。两者都是用于快速构建数组的方法。在底层,它们都调用self.concatenate(tuple(objs), axis = axis)所谓”串联“,实际上是将用逗号隔开的元素,按照指定的坐标轴,合并到同一个数组内,例如
>>> np.r_[np.array([1,2,3]), 0, 0, np.array([4,5,6])] array([1, 2, 3, ..., 4, 5, 6]) >>> np.c_[np.array([1,2,3]), np.array([4,5,6])] array([[1, 4], [2, 5], [3, 6]])需要注意的是,串联的对应轴必须等长,例如将第二个改为
>>> np.c_[np.array([1,2,3]),0 , np.array([4,5,6])] # 错误的写法,一定会报错 '''ValueError: all the input array dimensions except for the concatenation axis must match exactly'''
np.r_可以通过指定string integers来指定串联效果,这个字符串由三个逗号分隔的整数组成,分别指示要连接的轴,强制将输入转换的最小维度(即维度要大于等于该值,但这个值必须大于等于连接后的维度),以及哪个轴将包含数组的起始(这个数字必须低于维度);例如>>> np.r_['0,2,0', [1,2,3], [4,5,6]] array([[1], [2], [3], [4], [5], [6]]) >>> np.r_['0,1,0', [1,2,3], [4,5,6]] array([1, 2, 3, 4, 5, 6]) >>> np.r_['1,2,0', [1,2,3], [4,5,6]] array([[1, 4], [2, 5], [3, 6]]) >>> np.r_['1,2,1', [1,2,3], [4,5,6]] array([[1, 2, 3, 4, 5, 6]])
Gradient descent with non-linear feature
使用缩放后的特征,执行梯度下降。因为已经经过了特征缩放,所以alpha可以设大一些。
x = np.arange(0,20,1)
y = x**2
X = np.c_[x, x**2, x**3]
X = zscore_normalize_features(X)
model_w, model_b = run_gradient_descent_feng(X, y, iterations=100000, alpha=1e-1)
plt.scatter(x, y, marker='x', c='r', label="Actual Value"); plt.title("Normalized x x**2, x**3 feature")
plt.plot(x,X@model_w + model_b, label="Predicted Value"); plt.xlabel("x"); plt.ylabel("y"); plt.legend(); plt.show()
@做的是矩阵乘法运算
w,b found by gradient descent: w: [5.27e-05 1.13e+02 8.43e-05], b: 123.5000
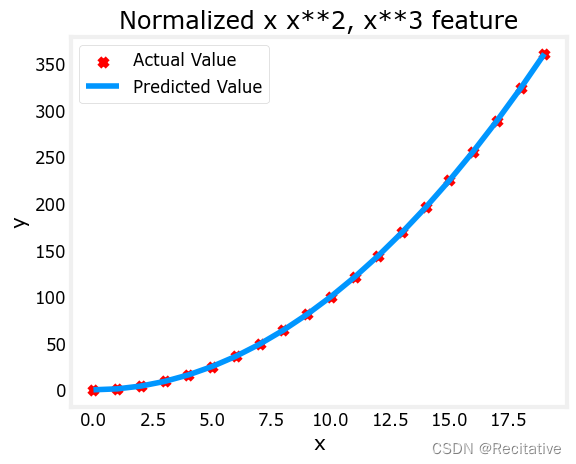
从权重的结果来看, x 2 x^2 x2的影响比其他两个特征大得多,可以视为其他两个特征被淘汰。
An Alternate View
从另一个视角来看特征选取,虽然我们使用了更高阶的特征,但抛开特征设计,我们使用的梯度下降方法仍然是线性回归的梯度下降方法,因此,当一个经过设计的特征适合数据的时候,该特征应当与目标值线性相关
# create target data
x = np.arange(0, 20, 1)
y = x**2
# engineer features .
X = np.c_[x, x**2, x**3] #<-- added engineered feature
X_features = ['x','x^2','x^3']
fig,ax=plt.subplots(1, 3, figsize=(12, 3), sharey=True)
for i in range(len(ax)):
ax[i].scatter(X[:,i],y)
ax[i].set_xlabel(X_features[i])
ax[0].set_ylabel("y")
plt.show()
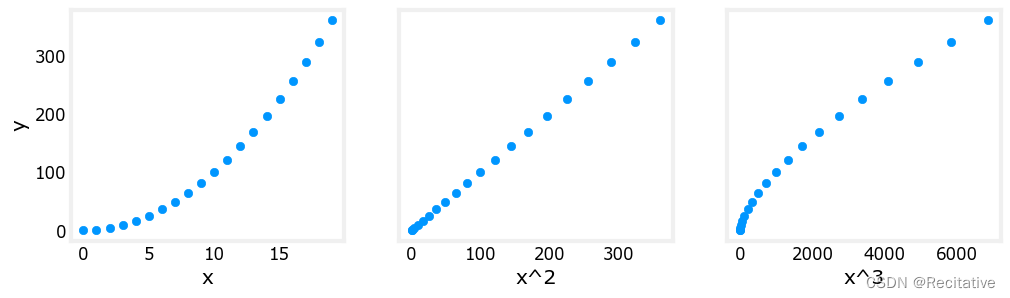
如图所示,可见特征 x 2 x^2 x2与目标值线性相关,因此应当选择该特征。
西瓜书内容补充
多元闭式解
已知在一元线性回归中,有
f
(
x
i
)
=
w
x
i
+
b
(
w
∗
,
b
∗
)
=
arg
min
(
w
,
b
)
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
f(x_i) = w x_i + b\newline (w^*, b^*) = \arg \min_{(w, b)} \sum_{i = 1}^m (f(x_i) - y_i)^2
f(xi)=wxi+b(w∗,b∗)=arg(w,b)mini=1∑m(f(xi)−yi)2
w
∗
,
b
∗
w^*, b^*
w∗,b∗为
w
,
b
w, b
w,b的解,对于多元线性回归,我们试图获得
f
(
x
⃗
i
)
=
w
⃗
T
x
⃗
i
+
b
,使得
f
(
x
⃗
i
)
≃
y
i
f(\vec x_i) = \vec w^T \vec x_i + b,使得f(\vec x_i)\simeq y_i
f(xi)=wTxi+b,使得f(xi)≃yi
类似的,我们可以写出解的形式
(
w
⃗
∗
,
b
∗
)
=
arg
min
(
w
⃗
,
b
)
∑
i
=
1
m
(
f
(
x
⃗
i
)
−
y
i
)
2
=
arg
min
(
w
⃗
,
b
)
∑
i
=
1
m
(
w
⃗
T
x
⃗
i
+
b
−
y
i
)
2
(\vec w^*, b^*) = \arg \min_{(\vec w, b)} \sum_{i = 1}^m (f(\vec x_i) - y_i)^2 \newline = \arg \min_{(\vec w, b)} \sum_{i = 1}^m (\vec w^T \vec x_i + b - y_i)^2
(w∗,b∗)=arg(w,b)mini=1∑m(f(xi)−yi)2=arg(w,b)mini=1∑m(wTxi+b−yi)2
为了使计算更加简便,可以令
w
⃗
^
=
(
w
⃗
;
b
)
=
(
w
1
,
w
2
,
…
,
w
n
,
b
)
对应的
,
X
=
(
x
11
x
12
⋯
x
1
n
1
x
21
x
22
⋯
x
2
n
1
⋮
⋮
⋱
⋮
⋮
x
m
1
x
m
2
⋯
x
m
n
1
)
\hat {\vec w} = (\vec w; b) = (w_1, w_2, \dots, w_n, b) \newline 对应的, X = \left( \begin{array}{} x_{11} & x_{12} & \cdots & x_{1n} & 1 \\ x_{21} & x_{22} & \cdots & x_{2n} & 1 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ x_{m1} & x_{m2} & \cdots & x_{mn} & 1 \end{array} \right)
w^=(w;b)=(w1,w2,…,wn,b)对应的,X=
x11x21⋮xm1x12x22⋮xm2⋯⋯⋱⋯x1nx2n⋮xmn11⋮1
则有
w
⃗
^
∗
=
arg
min
w
⃗
^
(
X
w
⃗
^
−
y
⃗
)
T
(
X
w
⃗
^
−
y
⃗
)
\hat {\vec w}^* = \arg\min_{\hat {\vec w}} ( X \hat {\vec w} - \vec y)^T( X \hat {\vec w} - \vec y)
w^∗=argw^min(Xw^−y)T(Xw^−y)
令
E
w
⃗
^
=
(
X
w
⃗
^
−
y
⃗
)
T
(
X
w
⃗
^
−
y
⃗
)
E_{\hat {\vec w}} = ( X \hat {\vec w} - \vec y)^T( X \hat {\vec w} - \vec y)
Ew^=(Xw^−y)T(Xw^−y),则对
w
⃗
^
\hat {\vec w}
w^求导
∂
E
w
⃗
^
∂
w
⃗
^
=
∂
y
⃗
T
y
⃗
∂
w
⃗
^
−
∂
y
⃗
T
X
w
⃗
^
∂
w
⃗
^
−
∂
w
⃗
^
T
X
T
y
⃗
∂
w
⃗
^
+
∂
w
⃗
^
T
X
T
X
w
⃗
^
∂
w
⃗
^
∵
∂
α
T
x
⃗
∂
x
⃗
=
∂
x
⃗
T
α
∂
x
⃗
=
α
∂
x
⃗
T
A
x
⃗
∂
x
⃗
=
(
A
+
A
T
)
x
⃗
∴
∂
E
w
⃗
^
∂
w
⃗
^
=
0
−
X
T
y
⃗
−
X
T
y
⃗
+
(
X
T
X
+
X
T
X
)
w
⃗
^
=
2
X
T
(
X
w
⃗
^
−
y
⃗
)
\frac {\partial E_{\hat {\vec w}}}{\partial \hat {\vec w}} = \frac {\partial \vec y^T \vec y}{\partial \hat {\vec w}} - \frac {\partial \vec y^T X \hat {\vec w}}{\partial \hat {\vec w}} - \frac {\partial \hat {\vec w}^T X^T \vec y }{\partial \hat {\vec w}} + \frac {\partial \hat {\vec w}^T X^T X \hat {\vec w} }{\partial \hat {\vec w}} \newline \because \frac {\partial \alpha^T \vec x}{\partial \vec x} = \frac {\partial \vec x^T \alpha}{\partial \vec x} = \alpha \newline \frac {\partial \vec x^T A \vec x}{\partial \vec x} = ( A + A^T)\vec x \newline \therefore \frac {\partial E_{\hat {\vec w}}}{\partial \hat {\vec w}} = 0 - X^T \vec y - X^T \vec y + ( X^T X + X^T X)\hat {\vec w} \newline = 2 X^T( X \hat {\vec w} - \vec y)
∂w^∂Ew^=∂w^∂yTy−∂w^∂yTXw^−∂w^∂w^TXTy+∂w^∂w^TXTXw^∵∂x∂αTx=∂x∂xTα=α∂x∂xTAx=(A+AT)x∴∂w^∂Ew^=0−XTy−XTy+(XTX+XTX)w^=2XT(Xw^−y)
令该式为0,可得
w
⃗
^
∗
\hat {\vec w}^*
w^∗的闭式解。
广义线性模型(generalized linear model)
通常的线性模型可以简写为
y
=
w
⃗
T
x
⃗
+
b
y = \vec w^T \vec x + b
y=wTx+b
如果让线性模型逼近y的衍生函数,例如,让y呈指数变化,可以写为
ln
y
=
w
⃗
T
x
⃗
+
b
\ln y = \vec w^T \vec x + b
lny=wTx+b
即让
e
w
⃗
T
x
⃗
+
b
e^{\vec w^T \vec x + b}
ewTx+b逼近
y
y
y,上面这种回归称为对数线性回归(log-linear regression),类似这样的,考虑单调可微的联系函数(link function)
g
(
⋅
)
g(\cdot)
g(⋅),使得
y
=
g
−
1
(
w
⃗
T
x
⃗
+
b
)
y = g^{-1}(\vec w^T \vec x + b)
y=g−1(wTx+b)
这样的模型称为广义线性模型(generalized linear model)
或者按照吴恩达老师所讲的理解思路,广义线性模型就是我们试图寻找一个 g ( ⋅ ) g(\cdot) g(⋅),使得 y y y与 g ( w ⃗ T x ⃗ + b ) g(\vec w^T \vec x + b) g(wTx+b)线性相关。
参考
- 2022吴恩达机器学习
- 《机器学习》周志华(西瓜书)
- 南瓜书


















 3516
3516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











