







概述
称一个语言是可识别的,当且仅当存在一台识别该语言的图灵机。
称一个语言是可判定的,当且仅当存在一台识别该语言的图灵机,该图灵机一定会停机,称为判定器(decider)。
描述可判定性/可识别性的目的在于,这些性质反映了哪些问题能够通过算法求解。即在《计算理论导引》这本书开篇中所提到的那个问题:计算机的基本能力和局限性是什么?
本章的主要内容如下:
- A D F A , A N F A , A R E X , E D F A , E Q D F A A_{DFA}, A_{NFA}, A_{REX}, E_{DFA}, EQ_{DFA} ADFA,ANFA,AREX,EDFA,EQDFA的可判定性;
- A C F G , E C F G , E Q C F G A_{CFG}, E_{CFG}, EQ_{CFG} ACFG,ECFG,EQCFG的可判定性;
- A T M A_{TM} ATM不可判定证明,重点在对角化方法以及矛盾的推理;
- 补图灵可识别定义,与可判定的关系;
- 图灵不可识别语言的存在性证明。
DFA可判定性
A D F A A_{DFA} ADFA是可判定的
首先给出
A
D
F
A
A_{DFA}
ADFA的定义:
A
D
F
A
=
{
<
B
,
w
>
∣
B
为
D
F
A
,且
B
接受
w
}
A_{DFA} = \{<B, w>|B为DFA,且B接受w\}
ADFA={<B,w>∣B为DFA,且B接受w}
证明思路:要证明
A
D
F
A
A_{DFA}
ADFA,可以通过图灵机来模拟该DFA的运行,这种模拟关系在直觉上很好理解:当下所有的计算机,除了量子计算机外,都是一台图灵机,用手边的电脑编写一个DFA程序并不困难,由于可判定性只需要说明判定问题的图灵机存在,所以不妨就考虑手边的电脑是否能够模拟问题机器的运行。
证明:构造图灵机
T
T
T:
T
=
“对输入
<
B
,
w
>
,
B
为一台
D
F
A
,
w
为字符串
:
1.
在输入
w
上模拟
B
;
2.
若
B
接受
w
,则接受,否则拒绝。”
\begin{array}{l} T = \text{“对输入}<B, w>,B为一台DFA,w为字符串:\\ 1.在输入w上模拟B;\\ 2.若B接受w,则接受,否则拒绝。\text{”} \end{array}
T=“对输入<B,w>,B为一台DFA,w为字符串:1.在输入w上模拟B;2.若B接受w,则接受,否则拒绝。”
A N F A , A R E X A_{NFA}, A_{REX} ANFA,AREX是可判定的
A
N
F
A
,
A
R
E
X
A_{NFA},A_{REX}
ANFA,AREX的定义和
A
D
F
A
A_{DFA}
ADFA类似,且两者证明思路相近,故放在一起讨论:
A
N
F
A
=
{
<
B
,
w
>
∣
B
为
N
F
A
,且
B
接受
w
}
A
R
E
X
=
{
<
R
,
w
>
∣
R
为正则表达式,且
R
能够派生
w
}
A_{NFA} = \{<B, w> | B 为NFA,且B接受w\}\\ A_{REX} = \{<R, w> | R为正则表达式,且R能够派生w\}
ANFA={<B,w>∣B为NFA,且B接受w}AREX={<R,w>∣R为正则表达式,且R能够派生w}
证明思路:证明这两种问题可判定,都可以通过转换的方法:因为已知
A
D
F
A
A_{DFA}
ADFA是可判定的,所以只需要将
N
F
A
NFA
NFA和
R
E
X
REX
REX都转化为等价的
D
F
A
DFA
DFA,再进行模拟即可。
转化关系的证明可以参考有穷自动机章节,简单来说, N F A → D F A NFA \to DFA NFA→DFA的证明是通过构造特殊的状态——每个状态都包含NFA中的一个状态子集——从而构造出一台等价的 D F A DFA DFA。而 R E X → D F A REX \to DFA REX→DFA的证明则是通过验证三条基本正则的等价性,再根据正则计算封闭性来构造 N F A NFA NFA,进而可构造 D F A DFA DFA。
证明:分别构造图灵机
T
1
,
T
2
T_1, T_2
T1,T2:
T
1
=
“对输入
<
B
,
w
>
,
B
为一台
N
F
A
,
w
为字符串
:
1.
首先将
B
转化为等价的
D
F
A
D
;
2.
在
D
上模拟
w
的运行
;
3.
若
D
接受,则接受,否则拒绝。”
\begin{array}{l} T_1 = \text{“对输入}<B, w>,B为一台NFA,w为字符串:\\ 1.首先将B转化为等价的DFA\ D;\\ 2.在D上模拟w的运行;\\ 3.若D接受,则接受,否则拒绝。\text{”} \end{array}
T1=“对输入<B,w>,B为一台NFA,w为字符串:1.首先将B转化为等价的DFA D;2.在D上模拟w的运行;3.若D接受,则接受,否则拒绝。”
T 2 = “对输入 < R , w > , R 为正则表达式, w 为字符串 : 1. 首先将 B 转化为等价的 N F A N ; 2. 在 N 上模拟 w 的运行 ; 3. 若 N 接受,则接受,否则拒绝。 \begin{array}{l} T_2 = \text{“对输入}<R,w>,R为正则表达式,w为字符串:\\ 1.首先将B转化为等价的NFA\ N;\\ 2.在N上模拟w的运行;\\ 3.若N接受,则接受,否则拒绝。 \end{array} T2=“对输入<R,w>,R为正则表达式,w为字符串:1.首先将B转化为等价的NFA N;2.在N上模拟w的运行;3.若N接受,则接受,否则拒绝。
E D F A E_{DFA} EDFA是可判定的
首先给出
E
D
F
A
E_{DFA}
EDFA的定义:
E
D
F
A
=
{
<
A
>
∣
A
是一个
D
F
A
,且
L
(
A
)
=
∅
}
E_{DFA} = \{<A>|A是一个DFA,且L(A) = \varnothing\}
EDFA={<A>∣A是一个DFA,且L(A)=∅}
证明思路:证明图灵机不接受任何语言,即证明不存在任何一条状态序列,使得图灵机能够从
q
0
q_0
q0出发,到达任意可接受状态
q
a
c
c
∈
F
q_{acc} \in F
qacc∈F,因此可以使用标记法进行证明。
< A > <A> <A>是对有穷状态机A的描述,理解为输入就好。
证明:构造图灵机
T
T
T:
T
=
“对输入
<
A
>
,
A
为一台
D
F
A
:
1.
标记
A
的起始状态
;
2.
重复以下步骤,直到所有的可到达状态都被标记
:
a
.
如果某个未被标记的状态,存在从一个已标记状态到它的转移,则标记这个未标记状态
;
3.
如果没有接受状态被标记,则接受;否则拒绝。”
\begin{array}{l} T = \text{“对输入}<A>, A为一台DFA:\\ 1.标记A的起始状态;\\ 2.重复以下步骤,直到所有的可到达状态都被标记:\\ \space\ a.如果某个未被标记的状态,存在从一个已标记状态到它的转移,则标记这个未标记状态;\\ 3.如果没有接受状态被标记,则接受;否则拒绝。\text{”} \end{array}
T=“对输入<A>,A为一台DFA:1.标记A的起始状态;2.重复以下步骤,直到所有的可到达状态都被标记: a.如果某个未被标记的状态,存在从一个已标记状态到它的转移,则标记这个未标记状态;3.如果没有接受状态被标记,则接受;否则拒绝。”
E Q D F A EQ_{DFA} EQDFA是可判定的
首先给出
E
Q
D
F
A
EQ_{DFA}
EQDFA的定义:
E
Q
D
F
A
=
{
<
A
,
B
>
∣
A
,
B
为
D
F
A
,
L
(
A
)
=
L
(
B
)
}
EQ_{DFA} = \{<A,B>|A,B为DFA,L(A) = L(B)\}
EQDFA={<A,B>∣A,B为DFA,L(A)=L(B)}
证明思路:
E
Q
D
F
A
EQ_{DFA}
EQDFA的证明比较精巧,核心思路是将
E
Q
D
F
A
EQ_{DFA}
EQDFA归约为已知可判定的
E
D
F
A
E_{DFA}
EDFA问题,且利用的正则计算的封闭性进行构造。
已知,如果 L ( A ) = L ( B ) L(A) = L(B) L(A)=L(B),意味着 L ( A ) ∩ L ( B ) ‾ = ∅ , L ( A ) ‾ ∩ L ( B ) = ∅ L(A) \cap \overline{L(B)} = \varnothing, \overline {L(A)} \cap L(B) = \varnothing L(A)∩L(B)=∅,L(A)∩L(B)=∅,因此可构造语言 L ( C ) = [ L ( A ) ∩ L ( B ) ‾ ] ∪ [ L ( A ) ‾ ∩ L ( B ) ] = ∅ L(C) = [L(A) \cap \overline{L(B)}] \cup [\overline {L(A)} \cap L(B)] = \varnothing L(C)=[L(A)∩L(B)]∪[L(A)∩L(B)]=∅,从而利用已知的 E D F A E_{DFA} EDFA
证明:构造图灵机
T
T
T:
T
=
“对输入
<
A
,
B
>
,
A
,
B
都是
D
F
A
:
1.
构造识别语言
L
(
C
)
=
[
L
(
A
)
∩
L
(
B
)
‾
]
∪
[
L
(
A
)
‾
∩
L
(
B
)
]
=
∅
的
D
F
A
C
;
2.
在输入
<
C
>
上运行判定
E
D
F
A
的图灵机
;
3.
若接受,则接受,否则拒绝。”
\begin{array}{l} T = \text{“对输入}<A,B>, A,B都是DFA:\\ 1.构造识别语言L(C) = [L(A) \cap \overline{L(B)}] \cup [\overline {L(A)} \cap L(B)] = \varnothing的DFA\ C;\\ 2.在输入<C>上运行判定E_{DFA}的图灵机;\\ 3.若接受,则接受,否则拒绝。\text{”} \end{array}
T=“对输入<A,B>,A,B都是DFA:1.构造识别语言L(C)=[L(A)∩L(B)]∪[L(A)∩L(B)]=∅的DFA C;2.在输入<C>上运行判定EDFA的图灵机;3.若接受,则接受,否则拒绝。”
2, 3两步也可以按照 E D F A E_{DFA} EDFA的格式写为:
- 标记起始状态
- 重复这一步,直到没有新的状态被标记:如果未标记状态中,存在能够从已标记状态到达的转移,则标记该未标记状态
- 若没有接受状态被标记,则接受,否则拒绝。
CFG可判定性
A C F G A_{CFG} ACFG可判定
首先给出
A
C
F
G
A_{CFG}
ACFG的定义:
A
C
F
G
=
{
<
G
,
w
>
∣
G
是
C
F
G
,
w
是串,
G
派生
w
}
A_{CFG} = \{<G,w>| G是CFG,w是串,G派生w\}
ACFG={<G,w>∣G是CFG,w是串,G派生w}
证明思路:想要证明
A
C
F
G
A_{CFG}
ACFG可判定,可以遍历所有可能的派生,检查是否能够派生w。然而,对很多带有递归规则的CFG来说,上述思路可能导致图灵机不能停机,因此如果想要采用遍历方法,应该确保需要遍历的派生是有限的。
在CFG章节中,我们曾证明过,对一个符合乔姆斯基范式的CFG,其派生长度为 n n n的字符串,最多需要 2 n − 1 2n - 1 2n−1步。
简单回顾一下,已知乔式只包含两种派生式:
A → B C A → a A \to BC\\ A \to a A→BCA→a
对长度为 n n n的字符串,由于需要 n n n个字符,因此第二种派生会有 n n n步;且由于第一种派生,每次会增加一个分支(叶子),如果需要n个字符,就需要进行 n − 1 n-1 n−1步第一种派生;因此总计 2 n − 1 2n - 1 2n−1步。
因此,可以通过遍历所有 2 n − 1 2n-1 2n−1步内的派生,得到有限的遍历集合。
证明:构造图灵机
T
T
T:
T
=
“对输入
<
G
,
w
>
,
G
是一个
C
F
G
,
w
是一个串
:
1.
将
G
转化为的等价的乔姆斯基范式
G
′
;
2.
设
n
是
w
的长度,遍历
G
‘所有
2
n
−
1
步的派生字符串;若
n
=
0
,则列出一步以内的派生
;
3.
若能够派生出
w
,则接受,否则拒绝。”
\begin{array}{l} T = \text{“对输入}<G, w>,G是一个CFG,w是一个串:\\ 1.将G转化为的等价的乔姆斯基范式G';\\ 2.设n是w的长度,遍历G‘所有2n - 1步的派生字符串;若n = 0,则列出一步以内的派生;\\ 3.若能够派生出w,则接受,否则拒绝。\text{”} \end{array}
T=“对输入<G,w>,G是一个CFG,w是一个串:1.将G转化为的等价的乔姆斯基范式G′;2.设n是w的长度,遍历G‘所有2n−1步的派生字符串;若n=0,则列出一步以内的派生;3.若能够派生出w,则接受,否则拒绝。”
E C F G E_{CFG} ECFG可判定
给出
E
C
F
G
E_{CFG}
ECFG的定义:
E
C
F
G
=
{
<
G
>
∣
G
为
C
F
G
,且
L
(
G
)
=
∅
}
E_{CFG} = \{<G>|G为CFG,且L(G) = \varnothing\}
ECFG={<G>∣G为CFG,且L(G)=∅}
证明思路:可以像
E
D
F
A
E_{DFA}
EDFA那样,采用标记法,但与
A
C
F
G
A_{CFG}
ACFG面临的问题一样,如果从起始变元出发,可能会导致无法停机。这里采用标记终止的方式来得到有限集合。
证明:构造图灵机
T
T
T:
T
=
“对输入
<
G
>
,
G
是一个
C
F
G
:
1.
标记
G
的所有终止符
;
2.
重复以下步骤,直到没有新的变元被标记:
a
.
如果存在规则
A
→
U
1
U
2
…
U
k
,且
U
1
U
2
…
U
k
都被标记,则标记变元
A
;
3.
若起始变元被标记,则拒绝,否则接受。”
\begin{array}{l} T = \text{“对输入}<G>,G是一个CFG:\\ 1.标记G的所有终止符;\\ 2.重复以下步骤,直到没有新的变元被标记:\\ \space\ a.如果存在规则A \to U_1U_2\dots U_k,且U_1U_2\dots U_k都被标记,则标记变元A;\\ 3.若起始变元被标记,则拒绝,否则接受。\text{”} \end{array}
T=“对输入<G>,G是一个CFG:1.标记G的所有终止符;2.重复以下步骤,直到没有新的变元被标记: a.如果存在规则A→U1U2…Uk,且U1U2…Uk都被标记,则标记变元A;3.若起始变元被标记,则拒绝,否则接受。”
E Q C F G EQ_{CFG} EQCFG不可判定
给出
E
Q
C
F
G
EQ_{CFG}
EQCFG的定义:
E
Q
C
F
G
=
{
<
G
,
H
>
∣
G
,
H
都是
C
F
G
,且
L
(
G
)
=
L
(
H
)
}
EQ_{CFG} = \{<G,H>|G,H都是CFG,且L(G) = L(H)\}
EQCFG={<G,H>∣G,H都是CFG,且L(G)=L(H)}
这里先给出不严谨的说明:
E
Q
C
F
G
EQ_{CFG}
EQCFG无法像
E
Q
D
F
A
EQ_{DFA}
EQDFA那样,根据集合相等的定义来证明,因为上下文无关语言类对交运算和补运算不封闭。
严格证明在可归约部分,有机会的话写一写。
语言关系
至此,可以画出已知语言类的关系图。
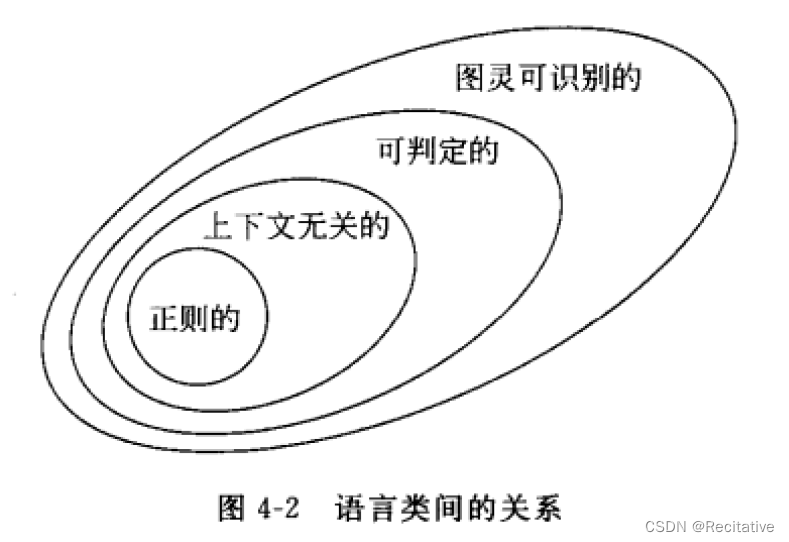
不可识别语言存在性证明
非常好之证明,使我呼呼大睡
待证:存在图灵不可识别的语言。
证明思路:
第一种证明思路基于集合的可数性,可分为两个部分,一是证明字母表上的图灵机是可数的(countable);二是证明字母表上的语言是不可数的。
故证明可分为如下步骤:
- 可数定义
- 集合 Σ ∗ \Sigma^* Σ∗可数证明
- 图灵机集合可数证明
- 语言集合不可数证明
- 不可识别语言存在性证明。
单射满射,双射
问题引出:对有限的两个集合 A , B A, B A,B,判断两者的大小关系非常简单,只需要对 A , B A, B A,B分别计数,然后比较谁的元素多就可以。
然而,这种计数方法不适用于判断无限集合 A , B A, B A,B的大小关系,度量两者的相对规模,应当引入映射(project)的思想。
设存在映射 f : A → B f: A \to B f:A→B,定义:
一对一映射(one to one):若对 A A A中的任意两个元素 a 1 ≠ a 2 a_1 \ne a_2 a1=a2,都能够保证 f ( a 1 ) ≠ f ( a 2 ) f(a_1) \ne f(a_2) f(a1)=f(a2),则称 A A A与 B B B是一对一映射的。
满映射(onto):若对 B B B中的任意元素 b ∈ B b \in B b∈B,都存在 a ∈ A a \in A a∈A,使得 f ( a ) → b f(a) \to b f(a)→b,则称 A → B A \to B A→B为满映射。
对应(correspondence):若 A , B A, B A,B即满足一对一映射,又满足满映射,则称 f f f为对应,又称双射(bijective)。称此时的 A , B A, B A,B具有相同的规模。
形式化表述
∀
a
1
≠
a
2
∈
A
,
f
(
a
1
)
≠
f
(
a
2
)
∀
b
∈
B
,
∃
a
∈
A
,
f
(
a
)
=
b
\forall a_1 \ne a_2 \in A, f(a_1) \ne f(a_2)\\ \forall b \in B, \exist a\in A, f(a) = b
∀a1=a2∈A,f(a1)=f(a2)∀b∈B,∃a∈A,f(a)=b
可数
定义:若集合 A A A是有限的,或者与自然数集 N N N具有相同的规模,则称集合 A A A可数。
所有串构成的集合 Σ ∗ \Sigma^* Σ∗可数
定义 Σ ∗ \Sigma^* Σ∗为字母表 Σ \Sigma Σ上所有可能的串的集合。证明该集合可数。
证明:设字母表中存在 n n n个字符,可按照串长序、字典序排列所有可能的串,从而构造可数的 Σ ∗ \Sigma^* Σ∗集合:
- 列出串长为0的字符,包含 n 0 n^0 n0个
- 列出串长为 1 1 1的字符,包含 n 1 n^1 n1个
- … \dots …
- 列出串长为 s s s的字符,包含 n s n^s ns个
所有图灵机构成的集合可数
这里黑书讲的不是很详细,因此适当做一些补充帮助理解。
首先,我们需要补充一些集合论的定义,在集合论中,可以根据可数性,将集合分为三类:
- 有限集合(finite set):集合中的元素数量是有限的,例如 { 1 , 2 , 3 } \{1,2,3\} {1,2,3}
- 可数无限集合(countably infinite set):集合中的元素是无限的,但可以对应(双射)到 N \mathcal N N,即可数。
- 不可数无限集合(uncountably infinite set):集合中的元素是无限的,且存在不能映射到 N \mathcal N N的元素,下文中 B \mathcal B B就属于这种集合。
回顾一下,已知图灵机是一个7元组 { Q , Σ , Γ , δ , q 0 , q a c c , q r e j } \{Q, \Sigma, \Gamma, \delta, q_0, q_{acc}, q_{rej}\} {Q,Σ,Γ,δ,q0,qacc,qrej}。这个7元组可以被写成一个字符串,称为图灵机的编码 < M > <M> <M>,想要证明图灵机的集合可数,也就是证明图灵机的编码可数。
在7元组中,影响可数性的关键在于 Q Q Q和 Σ \Sigma Σ。这里的证明类似 Σ ∗ \Sigma^* Σ∗的证明:
- 将图灵机按照包含 1 , 2 , 3 , … 1, 2, 3, \dots 1,2,3,…个状态的顺序进行排列,同时也按照包含 0 , 1 , … 0, 1, \dots 0,1,…个字符的顺序进行排列。这样就可以证明, Q Q Q和 Σ \Sigma Σ是可数的。
- 转移函数 δ \delta δ与带子 Γ \Gamma Γ是前两者的有限组合,也是可数的。
- 综合上述说明可知,图灵机的编码是可数的,也即所有图灵机构成的集合是可数的。
所有语言集合不可数
引证:所有无限二进制序列的集合 B \mathcal B B是不可数的。
证明:类似
R
\mathcal R
R不可数的证明(因为和不可识别证明关系不大,且思想是一样的,就不写了),构造
x
x
x,使得
∀
n
\forall\ n
∀ n,
x
x
x的第
n
n
n位,与第
n
n
n个序列的第
n
n
n位不同。
n
=
1
01000111001001
n
=
2
10110101011011
n
=
3
01010101101010
⋮
⋮
x
111.............
\begin{array}{c:c} n = 1 & 01000111001001\\ n = 2 & 10110101011011\\ n = 3 & 01010101101010\\ \vdots & \vdots\\ x & 111.............\\ \end{array}
n=1n=2n=3⋮x010001110010011011010101101101010101101010⋮111.............
从而使得构造出的
x
x
x,不能够与
N
N
N中的元素映射,不满足对应的条件,得证无限二进制序列的集合不可数。
证明:设串构成的集合 Σ ∗ = { s 1 , s 2 , … } \Sigma^* = \{s_1, s_2, \dots\} Σ∗={s1,s2,…},设 L \mathcal L L为字母表上所有语言的集合,将每个语言转化成一个二进制序列:若语言中存在字符串 s i s_i si,则标记对应二进制序列的 i i i位为 1 1 1,否则标记 0 0 0。从而构建出 L \mathcal L L与 B \mathcal B B的对应。
因为 f : L → B f:\mathcal L \to \mathcal B f:L→B,且 B \mathcal B B是不可数的,所以 L \mathcal L L也不可数,得证字母表上所有语言的集合不可数。
结论
综上,因为图灵机构成的集合是可数的,而字母表上所有的语言构成的集合是不可数的,两者不能对应;可知一定存在不能被任何图灵机识别的语言。
不可识别存在性的另一种思路
另一种证明思路是利用补图灵可识别,即构造 A T M ‾ \overline {A_{TM}} ATM。
证明思路:
- A T M A_{TM} ATM是不可判定的;
- 对任意语言A,如果语言A可判定,则A与 A ‾ \overline A A都可识别;
- A T M A_{TM} ATM是图灵可识别的(构造模拟机)
- 由于 A T M A_{TM} ATM可识别,但 A T M A_{TM} ATM不可判定,故 A T M ‾ \overline {A_{TM}} ATM不可识别。这样就找到了一个不可被识别的语言。
A T M A_{TM} ATM不可判定
给定
A
T
M
A_{TM}
ATM的定义:
A
T
M
=
{
<
M
,
w
>
∣
M
为一台图灵机,
M
接受
w
}
A_{TM} = \{<M, w> | M为一台图灵机,M接受w\}
ATM={<M,w>∣M为一台图灵机,M接受w}
证明:采用反证法,假设
A
T
M
A_{TM}
ATM是可判定的,定义判定器
H
H
H,判定
A
T
M
A_{TM}
ATM:
H
=
“对输入
<
M
,
w
>
,
M
为一台图灵机
,
w
为字符串
:
1.
在
w
上模拟
M
的运行
;
2.
若
M
接受,则接受,否则拒绝。”
\begin{array}{l} H = \text{“对输入}<M,w>, M为一台图灵机,w为字符串:\\ 1.在w上模拟M的运行;\\ 2.若M接受,则接受,否则拒绝。\text{”} \end{array}
H=“对输入<M,w>,M为一台图灵机,w为字符串:1.在w上模拟M的运行;2.若M接受,则接受,否则拒绝。”
这里注意下,与后面证明可识别的时候不同,两者在步1的表述都是模拟,但在步2,判定器要求一定停机,故 M M M的结果被分为接受/不接受两种。
绘制出
H
H
H的对角化矩阵,假设存在以下判定关系(这里的accept, reject是随意取值的,不用太在意,关注
H
H
H矩阵和
D
D
D矩阵之间的关系即可):
<
M
1
>
<
M
2
>
<
M
3
>
…
M
1
a
c
c
e
p
t
r
e
j
e
c
t
r
e
j
e
c
t
…
M
2
r
e
j
e
c
t
r
e
j
e
c
t
r
e
j
e
c
t
…
M
3
a
c
c
e
p
t
r
e
j
e
c
t
a
c
c
e
p
t
…
⋮
⋮
⋮
⋮
\begin{array}{c|cccc} & <M_1> & <M_2> & <M_3> & \dots\\\hline M_1 & accept & reject & reject& \dots\\ M_2 & reject & reject & reject& \dots\\ M_3 & accept & reject & accept& \dots\\ \vdots & \vdots & \vdots & \vdots \end{array}
M1M2M3⋮<M1>acceptrejectaccept⋮<M2>rejectrejectreject⋮<M3>rejectrejectaccept⋮…………
定义判定器 D D D,调用 H H H,在** M M M的描述 < M > <M> <M>上运行 M M M**,并输出相反的结论:
这里比较绕,黑书给的例子是:编程语言的编译器可能就是使用该种语言编写的,在这里,编译器的源码就相当于描述字符串 < M > <M> <M>,而编译器本身就是 M M M。
这里的所有假设,目标都是为了推导出判定器 H H H存在矛盾,即说明 H H H可能无法给出确定的结果。
D = “对输入 < M > , M 为图灵机 : 1. 在输入 < M , < M > > 上运行判定器 H ; 2. 若 H 接受,则拒绝,若 H 拒绝,则接受。” \begin{array}{l} D = \text{“对输入}<M>, M为图灵机:\\ 1.在输入<M, <M>>上运行判定器H;\\ 2.若H接受,则拒绝,若H拒绝,则接受。\text{”} \end{array} D=“对输入<M>,M为图灵机:1.在输入<M,<M>>上运行判定器H;2.若H接受,则拒绝,若H拒绝,则接受。”
根据 D D D的定义,参考 H H H给出 D D D的对角化矩阵,并考察 D D D判定它自己的描述 < D > <D> <D>时的结果(会产生矛盾):
< M 1 > < M 2 > < M 3 > … < D > … M 1 r e j e c t ‾ … … M 2 a c c e p t ‾ … … M 3 r e j e c t ‾ … … ⋮ ⋮ ⋮ ⋮ ⋱ D ? ‾ … ⋮ ⋮ ⋮ ⋮ ⋮ ⋱ \begin{array}{c|ccccccc} & <M_1> & <M_2> & <M_3>&\dots & <D> & \dots \\\hline M_1 & \underline{reject} & & & \dots & &\dots\\ M_2 & & \underline{accept} & & \dots && \dots\\ M_3 & & & \underline{reject} & \dots && \dots\\ \vdots & \vdots & \vdots & \vdots & \ddots\\ D & & & & & \underline{?} & \dots\\ \vdots &\vdots & \vdots & \vdots && \vdots & \ddots \end{array} M1M2M3⋮D⋮<M1>reject⋮⋮<M2>accept⋮⋮<M3>reject⋮⋮…………⋱<D>?⋮……………⋱
从 D D D的对角化矩阵可以看出,由于对任何图灵机 M M M, D D D会使用 H H H判定 < M , < M > > <M,<M>> <M,<M>>,并给出相反的结果。但对图灵机 D D D本身,却无法判定 D D D是否能够接受 < D > <D> <D>,产生矛盾。因此,拒绝 A T M A_{TM} ATM可判定的原假设。
理解 A T M A_{TM} ATM不可判定的关键在于,意识到图灵机可以模拟其他机器(包括图灵机本身)运行,并进一步构造出矛盾的判定器 D D D,反证存在不能够被判定的图灵机。
补图灵可识别与可判定的关系
定理:对任意语言A,该语言可判定,当且仅当 A A A与 A ‾ \overline A A都可识别。
证明:充分必要条件,因此要证明两边。
-
正向很好证明,如果语言 A A A可判定,语言 A A A自然可识别。同时,只需要将判定语言A的图灵机的 q a c c q_{acc} qacc和 q r e j q_{rej} qrej互换,就可以得到判定 A ‾ \overline A A的图灵机。
-
反向采用构造的方法进行证明,构造判定A的判定器:
T = “对输入 < M 1 , M 2 , w > , M 1 , M 2 是图灵机, w 为字符串 : 1. 在 M 1 , M 2 上并行模拟 w ; 2. 若 M 1 接受,则接受;若 M 2 接受,则拒绝。” \begin{array}{l} T = \text{“对输入}<M_1, M_2, w>, M_1, M_2是图灵机,w为字符串:\\ 1.在M_1, M_2上并行模拟w;\\ 2.若M_1接受,则接受;若M_2接受,则拒绝。\text{”} \end{array} T=“对输入<M1,M2,w>,M1,M2是图灵机,w为字符串:1.在M1,M2上并行模拟w;2.若M1接受,则接受;若M2接受,则拒绝。”
A T M A_{TM} ATM可识别
证明:构造
A
T
M
A_{TM}
ATM的模拟器即可:
T
=
“对输入
<
M
,
w
>
,
M
为图灵机,
w
为字符串
:
1.
在
w
上模拟
M
的运行
;
2.
若
M
接受,则接受;若
M
拒绝,则拒绝。”
\begin{array}{l} T = \text{“对输入}<M, w>, M为图灵机,w为字符串:\\ 1.在w上模拟M的运行;\\ 2.若M接受,则接受;若M拒绝,则拒绝。\text{”} \end{array}
T=“对输入<M,w>,M为图灵机,w为字符串:1.在w上模拟M的运行;2.若M接受,则接受;若M拒绝,则拒绝。”
结论
综上,由于 A T M A_{TM} ATM可识别、不可判定,且可判定语言 A A A与其补 A ‾ \overline A A都是可识别的,可知 A T M ‾ \overline {A_{TM}} ATM不可识别,得证存在不可被图灵机识别的语言。
参考
- 《计算理论导引》第二版,机械工业出版社


















 3316
3316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











