







Learning and Evaluating Contextual Embedding of Source Code
一.概述
Bert的出世是NLP领域的发展的一个里程碑,这里作者也尝试将Bert引入到source code领域。这里,作者做了以下工作:
- 创建了一个大型数据集,包括
python, java(论文中没提到java,不过github上更新了)用来进行预训练任务。 - 在6个下游任务(具体的下面提)进行
fine-tune。并于Word2Vec, BiLSTM,以及没进行预训练任务的Transformer模型进行了对比。
二.数据集
2.1.预训练数据集
从BigQuery平台中提取所有.py文件。详细参考论文
2.2.fine-tunning数据集
下游任务用的数据集是基于ETH Py150 corpus生成的数据集。
三.源代码的tokenize
对python源代码的解析采用tokenize库。tokenize是python实现的一个词法分析器。可以参考对 Python 代码使用的词语标记化器 tokenize,你懂了吗?【Python|标准库|tokenize】
解析后
- 保持代码中关键字不变,并为没有字符串表示或歧义解释的语法元素生成特殊标记。
- 我们根据常见的启发式规则(例如,snake或Camel case)分割标识符(
identifiers)
最后,我们使用启发式规则、空格字符和特殊字符拆分token序列的字符串。token字符串长度最大15。预训练语料库最终会形成一个program vocabulary。初始的python预训练语料库中包含1600万个token,之后会用子词(subword)嵌入对program vocabulary进行压缩,这里用到了Tensor2Tensor项目中的SubwordTextEncoder,压缩后的subword vocabulary包括5万个token。
这部分的总体过程如下:
- 将源代码解析为
program tokens。 - 将
tokens一个个编码到subword vocabulary中。
这种编码方案的目的是保持token的语法意义。
这里不管是CuBERT还是对比试验用的Word2Vec都采用subword vocabulary。
四.任务
4.1.预训练任务
与NLP一样,这里的预训练任务有两个
- masked language modeling
- next sentence prediction
NSP任务中,1个sentence由多行代码组成。
与CodeBert不同的是CodeBert用的第二个预训练任务是Replaced token detection。
C-BERT还提出了AST-Node-Tagging预训练任务。
4.2.下游任务
下游任务包括5个分类任务和1个multi-headed pointer任务。所有任务用到的数据集是基于ETH Py150 corpus的改版,数据集创建过程中用到了伪随机算法。
6项下游任务数据集统计信息如下:

4.2.1.Variable-Misuse Classification
软件开发过程中,出于频繁地ctrl-c,ctrl-v。开发人员可能忘记了修改变量名。因此,会导致代码中的变量误用。有时候代码中也存在许多相似的变量名容易混淆。这些错误编译器检查不出来。
这里,用到的是分类任务的版本,给定一个代码函数片段,识别其中是否存在变量误用,不用指定位置。分类器需要考虑所有的变量以及它们的使用情况。
这里假定ETH Py150 corpus中不存在变量误用的情况。因此均为正样本。则随机地用代码中已经定义好地变量名来替换某些位置的变量名以创建负样本。
4.2.2.Wrong Binary Operator
原本任务目标是给定表达式中的二元运算符是否正确。这里修改成给定函数片段,检测代码片段中是否有使用错误的二元运算符。
下表列出了python中几乎全部的二元运算符,包括Commutative(左右可呼唤)和Non-Commutative(左右不可交换)。排除了使用频次很低的运算符比如//(整形除法)

这里假定ETH Py150 corpus中所有的二元运算符都正确使用,不存在二元运算符的样本被丢弃,剩下的作正样本。随机将正样本中一些二元运算符替换成其它的可以兼容的运算符以创建负样本,比如==可能被!=替换。但是不会用+,in, and等替换。这里替换过后代码依旧可以被tokenize库解析(1==2被替换成1 is 2而不是1is2,中间会插入空格)。
4.2.3.Swapped Operand
该任务原本是在表达式中错误地使用变量或常量,不过这目标与Variable-Misuse Classification很相似,所以这里目标改成检测是否有非交换(non-commutative,比如减号,上表的Non-Commutative一栏)二元制运算符的两端操作数写反了的情况。
操作数可以是任意子表达式,并且不限于变量或常量。
ETH Py150 corpus不存在Non-Commutative的样本被丢弃,剩下作正样本。为了简化负样本生成过程,这里的样本中所有的运算符和操作数都在同一行代码内(不会有复杂的运算表达式,比如1 - (a * b)),同样不考虑a - a这种交换2边操作数后依旧一样的表达式。
4.2.4.Function-Docstring Mismatch
现在越来越多的开发者写完代码后也会写上相应的注释。
这提供了用于机器翻译,检测非信息性(informative)文档字符串,并评估其在神经代码搜索中提供监督的效用的代码和自然语言句子之间的平行语料库。
这里假定ETH Py150 corpus中所有的docstring都是和代码相匹配的,没有docstring或者docstring为空字符串的样本会被丢弃。删除掉正样本中所有函数的docstring。随机选取其它函数的docstring来替换。以此创建负样本。
4.2.5.Exception Type
python代码中捕获异常的语句except Exception越来越多。但是有着精确写出异常(比如大部分人都写except Exception,就很不精确)好习惯的人不多。这里就提出了检测异常类别的任务。
这里的异常类别包括github用到的最多的20种异常,不包括Exception。具体展示在下表

ETH Py150 corpus中没有except块的代码会被丢弃。给定一个函数片段,将异常替换为特殊的hole token,比如except AsserttionError as e变成except __hole__ as e。来预测__hole__位置的异常类别。
需要注意的是
- 一个函数片段可能多次
except同一种异常。 - 一个
except块可能包含多种异常,比如except (OSError, TypeError) as reason
当一个代码包含多个异常处理时所有的异常处理语句位置都会收集,不过只会mask其中一个位置,不然就不是分类任务了。
4.2.6.Variable-Misuse Localization and Repair
这项任务的目标和Variable-Misuse Classification的不同之处在于。它包括了定位,分类和修复3项工作。
给定一个函数,任务是预测2个指针(每个函数片段应该最多包含一个误用的变量)。第一个指针(称为本地化指针)来标识变量的误用位置,另一个指针(称为修复指针)来标识同一个函数中的变量,该变量是在本该在这个错误的位置使用的。
通过使指针指向函数中的一个特殊位置(可能是预测任务开始前指针指向的初始位置),该模型还训练将不包含任何变量的函数分类为正确的函数。
用到的数据集与Variable-Misuse Classification中一样。不过,样本还是需要多一些标记,毕竟不是分类任务吗。这里,除了输入token序列,输入还包括一些boolean类型的mask,包括。
-
candidate mask
token序列中所有与变量有关的token都被标记为True。所有的变量要么是一个bug位置,要么是修复的位置。第一个位置([CLS])也会被标记为True,因为该代码可能不包含bug。 -
target mask
对负样本(包含bug)来说,所有正确使用的变量标记为True,一个负样本中可能存在多个正确使用的变量,所以True标记会有多个。正样本所有的变量都标记为False。 -
error-location mask
代码中所有错误使用的变量(负样本中)被标记为True。不包含bug的样本中第一个位置([CLS])也会被标记为True。
可以看到不管是什么mask,被mask的都是变量token。不过因为用到了subtokenize,所以有的token变成了几个subtoken,对此作者只mask第一个subtoken,之后的subtoken均标记为False。
五.实验
5.1.实验的目标
作者的实验是为了探索以下问题:
- 1.在对unlabeled code corpus进行预训练时,
contextual embeddings(Word2Vec是word embedding,不属于contextual embeddings)是否有助于源代码分析任务?作者比较了CuBERT和3个版本的BiLSTM。(没有Word2Vec进行embedding,CBOW embedding,Skipgram embedding) - 2.
fine-tune真的有帮助吗?或者Transformer model本身就足够了吗?作者比较了fine-tunned CuBERT模型和从随机初始化开始训练的Transformer-based模型。 - 3.
CuBERT在分类任务上的表现与标记过的分类数据集数据量之间的关系?作者比较了33%,66%和100%的分类数据进行fine-tunned时,fine-tunned CuBERT模型的性能。 - 4.上下文大小如何影响
CuBERT的性能?我们在分类任务中比较了不同示例长度的fine-tunning性能 - 5.CuBERT应用于复杂的任务(
Variable-Misuse Localization and Repair)效果如何。作者在Variable-Misuse Localization and Repair中对该问题进行了探索。
可以看到
- 问题1,2,3,4针对5项分类任务。
- 问题5针对最后一个
multi-headed pointer预测任务。
5.2.实验结果
实验结果如下:
5.2.1.问题1和问题2

from scratch意思是embedding层随机初始化,没有经过Word2Vec预训练。这里的Transformer指的是没有预训练过的BERT模型。
通过CuBERT于BiLSTM(+Word2Vec)之间的对比可以论证问题1。通过Transformer和CuBERT的对比可以论证问题2。
5.2.2.问题3
这里的预训练模型都是用同样的语料库进行预训练。不同的是,微调时下游任务的数据集大小分别设置为33%,66%,100%。
 可以看到,
可以看到,Docstring任务对下游数据集的减少并不敏感。然而,由于相比于其它4个任务,Exception任务的数据集少的可怜,因此Exception任务受到数据集减少的严重影响。
不过,在Misuse和Docstring任务中。用了33%的下游任务数据集fine-tunning 2个epoch的CuBERT模型依旧胜过baseline。
5.2.3.问题4
 可以看到的是输入的长度对模型分类的准确率还是有一定的影响。
可以看到的是输入的长度对模型分类的准确率还是有一定的影响。
5.2.4.问题5
这里state-of-art method就不介绍了
 C表示的是作者自己的数据集。H表示的是Hellendoorn et al的数据集。
C表示的是作者自己的数据集。H表示的是Hellendoorn et al的数据集。
六.总结
作者提出了CuBERT模型,一个python的BERT(github上也有java版了)。并在MLM和NSP 2个任务上进行了预训练,在5个分类任务和1个指针预测任务上进行了fine-tunning。
作者只使用源代码token序列,并将其留给底层的Transformer模型来推断它们之间的任何结构交互。这与C-BERT有异曲同工之妙,只不过预训练方式不一样。
相关代码用tensorflow编写,项目地址:CuBERT
七.attention可视化
用5个分类任务的示例代码和热图展示以下attention的过程,图中越白attention权重越大,越黑越小。
7.1.Variable Misuse

分类代码
def on_resize(self, event):
event.apply_zoom()
这里event.apply_zoom()本该写成self.apply_zoom()。可以看到所有的token都attend到了event,说明event有问题。
7.2.Wrong Operator Example

def__gt__(self,other):
if isinstance(other,int) and other==0:
return self.get_value() > 0
return other is not self
这里 is not 运算符用错了,本来是 <,而attention矩阵中权值最高的一列对应is
7.3.Swapped Operand

def__contains__(cls,model):
return cls._registry in model
这里return后本应写model in cls._registry。可以看到query ._registry in model 对应的attention中 in 和 model的权值很高。
7.4.Function Docstring

Docstring: ’Get form initial data.’
Function:
def__add__(self,cov):
return SumOfKernel(self,cov)
这里的docstring并不对应function。这里大部分query token都attend到了docstring的token。(most of the query tokens are attending to the tokens in the docstring)
7.5.Exception Classification
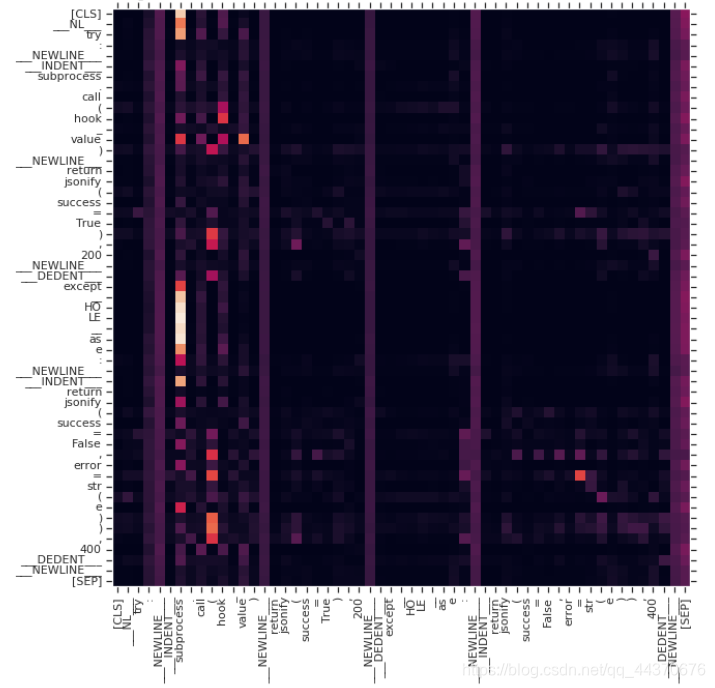
try:
subprocess.call(hook_value)
return jsonify(success=True), 200
except __HOLE__ as e:
return jsonify(success=False,error=str(e)), 400
模型最终给出__HOLE__的分类是OSError。attention矩阵中展示query __HOLE__对应的attention权值最高的token是subprocess。这就表明最终分类结果与os相关。















 1508
1508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









